









1. 项目背景与目标
在当今竞争激烈的商业环境中,员工突然离职往往给企业带来诸多意想不到的挑战,从项目进度延误到团队士气受挫,再到招聘与培训新员工的高昂成本,损失不可小觑。
但读者们是否想过,通过数据分析和机器学习算法,我们能够提前预判员工的离职风险,从而未雨绸缪,采取有效措施加以应对?本文将带领您踏上一段充满挑战与惊喜的技术之旅。我们将从基础出发,深入到决策树和随机森林这两种强大的机器学习算法之中,借助真实的 HR 数据集,一步步构建出精准的员工离职预测模型。通过完整且严谨的数据分析流程,我们不仅能够精准揭示影响员工离职的关键因素,还能为企业打造出切实可行、易于落地的预测方案,该案例原则上是可以为企业人力资源管理提供强大的数据驱动支持。
2. 数据集介绍
使用的是从kaggle上找的公开的HR数据集,包含14,999条员工记录,其关键特征包括:
| 特征名称 | 说明 | 类型 |
|---|---|---|
| satisfaction_level | 员工对公司的满意度 | float64 |
| last_evaluation | 绩员工上次KPI评分 | float64 |
| number_project | 同时处理的项目数 | int64 |
| average_montly_hours | 平均每个月的工作时间 | int64 |
| time_spend_company | 在公司的时间 | int64 |
| Work_accident | 是否出现过工作事故 | int64 |
| left | 是否离开 | int64 |
| promotion_last_5years | 最近5年是否升职 | int64 |
| sales | 员工部门 | object |
| salary | 薪资等级 | object |
3. 完整代码实现
3.1 环境准备与数据加载
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, roc_auc_score
# 配置可视化样式
plt.style.use('ggplot')
%matplotlib inline
# 加载数据
df = pd.read_csv('/your_path/HR_comma_sep.csv')查看数据的基本情况:
print(df.shape)
df.info()
df.head()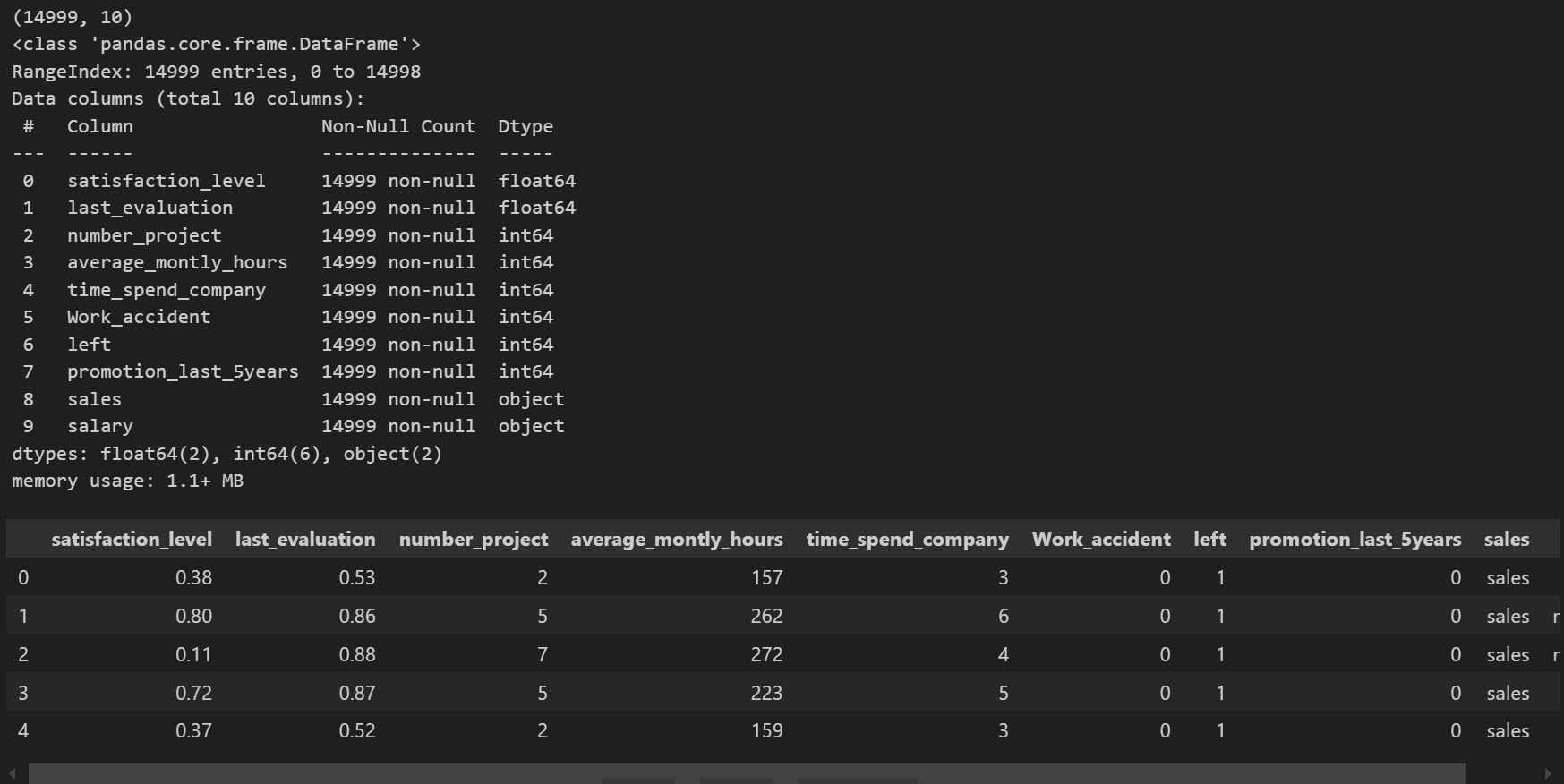
输出的整体概况
(14999, 10)表示数据集包含 14999 条记录(行),10 个特征(列)。<class 'pandas.core.frame.DataFrame'>表明数据结构是 pandas 的 DataFrame 类型。RangeIndex: 14999 entries, 0 to 14998说明行索引是从 0 到 14998 的范围索引。
列信息
- 数据列(Data columns)部分
- 数据集总共有 10 列,每列都展示了列名、非空值数量和数据类型。
satisfaction_level(满意度水平)和last_evaluation(上次评估得分)是float64类型,意味着是浮点数,且这两列都没有缺失值(非空计数都是 14999 )。number_project(项目数量)、average_montly_hours(平均每月工作小时数)、time_spend_company(在公司工作时长)、Work_accident(是否发生工作事故)、left(是否离职 )、promotion_last_5years(过去 5 年是否升职)这 6 列是int64类型,即整数类型,也都无缺失值。sales(销售部门类别)和salary(薪资情况)是object类型,在 pandas 里通常表示字符串等文本数据,同样无缺失值。
- 数据类型统计(dtypes)部分
- 明确指出有 2 个
float64类型列、6 个int64类型列和 2 个object类型列。
- 明确指出有 2 个
- 内存使用(memory usage)部分
1.1+ MB表示该数据集占用的内存略大于 1.1MB 。
数据预览部分
下方展示了数据集的前 5 行数据示例,每行数据对应各个列的具体取值:
- 比如第一行,员工满意度水平为 0.38,上次评估得分为 0.53 ,参与项目数量为 2 个等信息。通过这个预览,可以对数据的实际取值情况有个直观感受,方便后续进一步分析和处理数据 ,比如判断数值范围是否合理、文本数据是否有特殊格式等。
为了更直观的查看该数据中是否有缺失值我们可以使用以下函数:
df.isna().sum()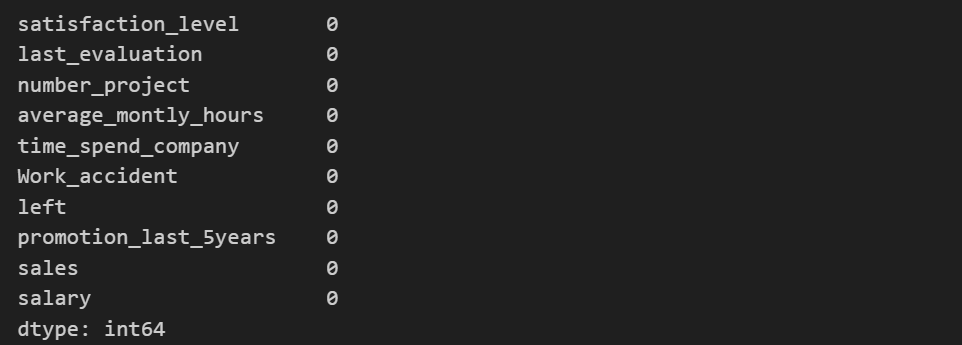 可以从上图输出看出,该数据集并没有NA值。
可以从上图输出看出,该数据集并没有NA值。
3.2 数据预处理
# 特征重命名
df = df.rename(columns={
'satisfaction_level': 'satisfaction',
'last_evaluation': 'evaluation',
'number_project': 'projectCount',
'average_montly_hours': 'averageMonthlyHours',
'time_spend_company': 'yearsAtCompany',
'Work_accident': 'workAccident',
'promotion_last_5years': 'promotion',
'sales': 'department',
'left': 'turnover'
})
# 处理分类变量
df['department'] = df['department'].astype('category').cat.codes
df['salary'] = df['salary'].astype('category').cat.codes
# 检查数据平衡性
print(f"离职比例:{df.turnover.value_counts(normalize=True)[1]:.1%}")
我稍微的解释一下上述的代码,以便初学者能够更好的理解:
处理分类变量
df['department'] = df['department'].astype('category').cat.codes
astype('category')将department列的数据类型转换为category类型 。在 pandas 中,category类型是一种用于存储分类数据的优化数据类型,它比普通的对象(字符串)类型占用更少的内存 。cat.codes则是将分类变量进行编码,给每个不同的类别分配一个唯一的整数值(从 0 开始)。例如,如果department列有 “sales”“marketing”“finance” 等类别,经过这一步操作后,可能会将 “sales” 编码为 0,“marketing” 编码为 1 ,“finance” 编码为 2 等,这样做是为了让机器学习算法能够处理分类数据,因为大多数算法要求输入为数值型数据。df['salary'] = df['salary'].astype('category').cat.codes
原理与处理department列类似,先把salary列的数据类型转换为category,以优化内存占用。然后通过cat.codes将其编码为整数值。比如原来salary列可能有 “low”“medium”“high” 等类别,编码后会分别对应不同的整数值,便于后续模型训练。
检查数据平衡性
print(f"离职比例:{df.turnover.value_counts(normalize=True)[1]:.1%}")
df.turnover.value_counts():value_counts()是 pandas 的一个方法,用于统计turnover列中每个不同值出现的频数。在这里,turnover列应该是表示员工是否离职(例如 0 表示未离职,1 表示离职 ),该方法会分别统计出离职和未离职员工的数量。normalize=True:这个参数设置为True时,value_counts()方法返回的不再是频数,而是频率,即每个值出现的次数占总次数的比例。这样可以得到离职员工和未离职员工在数据集中的占比情况。[1]:因为turnover列一般用 0 和 1 表示两种状态(未离职和离职 ),这里通过[1]取出值为 1(离职)的频率。: .1%:这是字符串格式化中的格式说明符,用于将取出的频率值格式化为百分数形式,并保留一位小数。最后通过print()函数打印出离职员工在数据集中所占的比例,以此来检查数据的平衡性。如果离职和未离职的比例差异过大,可能在构建预测模型时需要考虑采用一些技术(如过采样、欠采样等)来处理数据不平衡问题,以避免模型偏向占比大的类别。
3.3 探索性分析(EDA)
3.3.1 特征分布可视化
# 设置画布
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# 满意度分布对比
sns.kdeplot(data=df, x='satisfaction', hue='turnover', ax=axes[0,0], fill=True)
axes[0,0].set_title('满意度分布对比')
# 工时分布对比
sns.boxplot(data=df, x='turnover', y='averageMonthlyHours', ax=axes[0,1])
axes[0,1].set_title('月均工时分布')
# 项目数分布
sns.countplot(data=df, x='projectCount', hue='turnover', ax=axes[1,0])
axes[1,0].set_title('参与项目数分布')
# 司龄分布
sns.histplot(data=df, x='yearsAtCompany', hue='turnover', multiple='stack', ax=axes[1,1])
axes[1,1].set_title('司龄分布')
plt.tight_layout()输出:
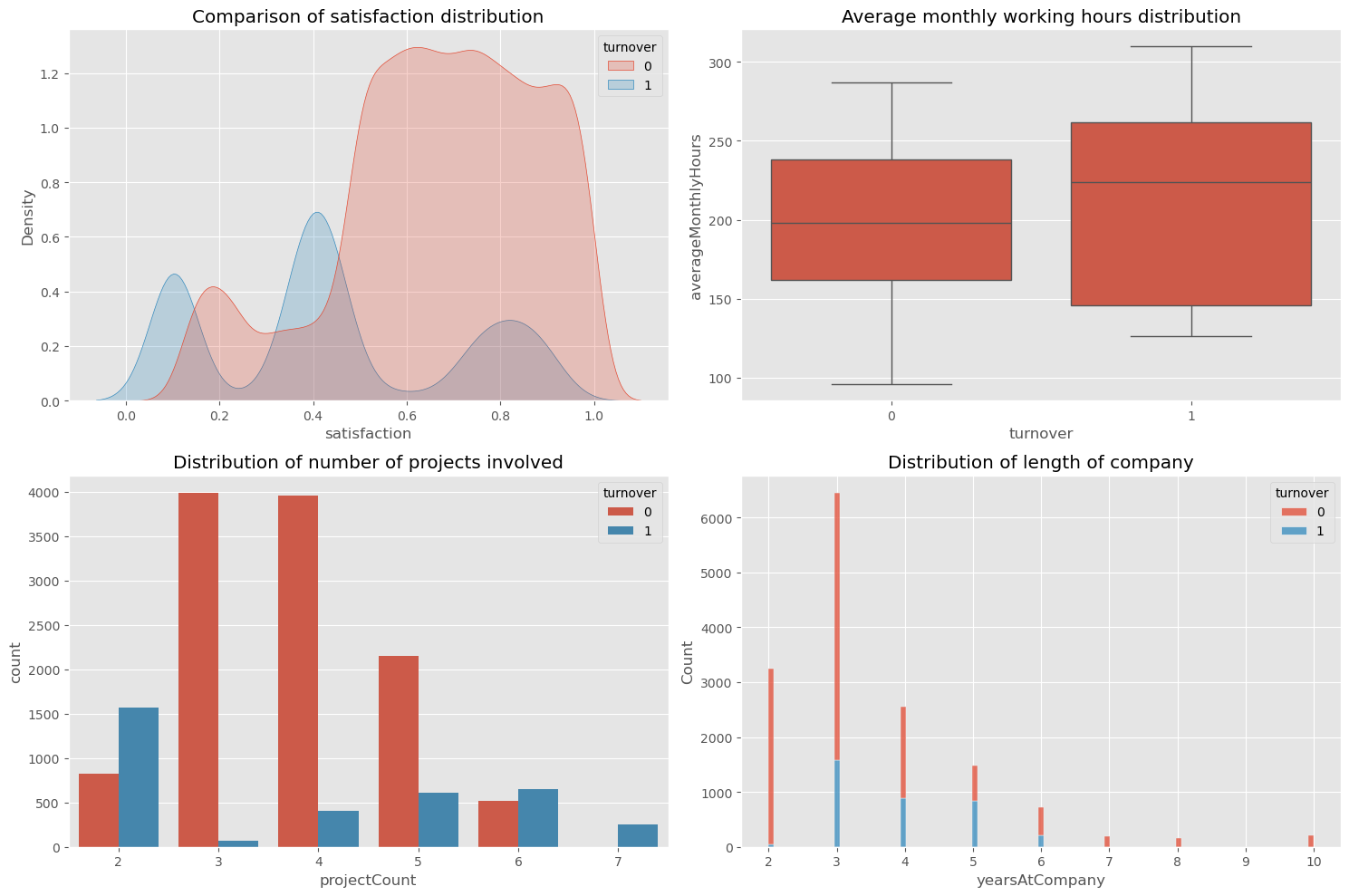
3.3.2 相关性分析
# 计算相关系数矩阵
corr_matrix = df.corr()
# 绘制热力图
plt.figure(figsize=(12,8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.title('特征相关性热力图')输出:
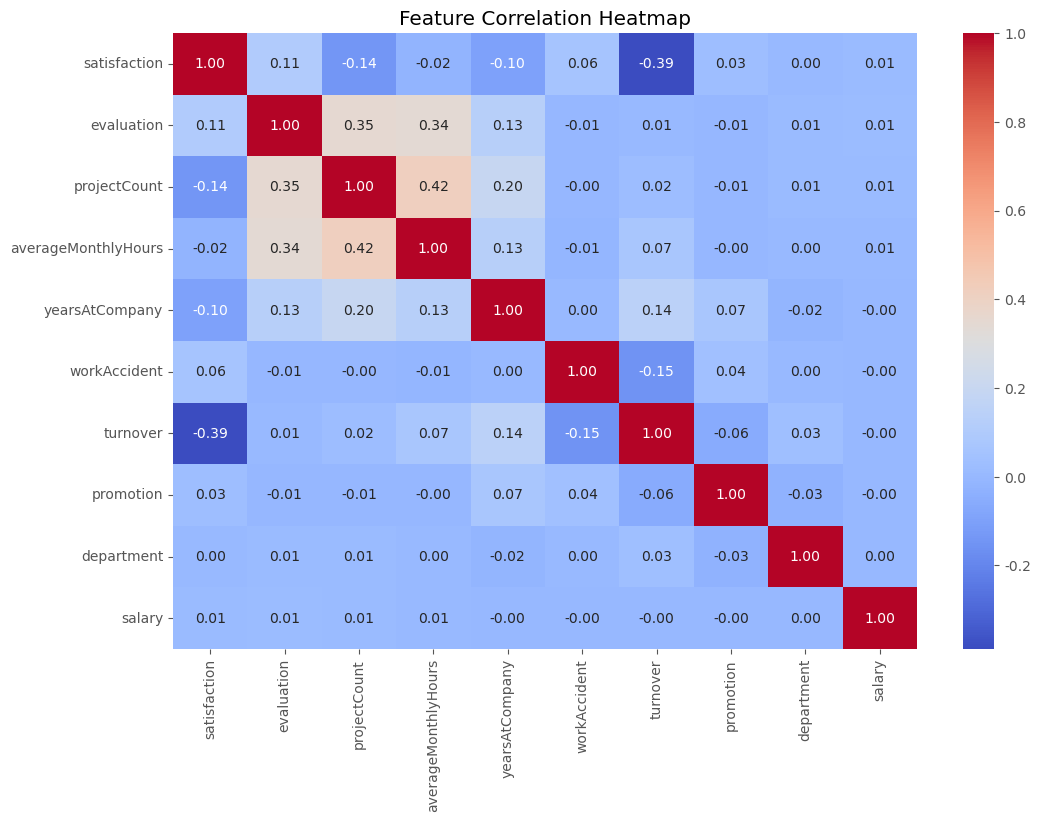
上述解释--整体布局与颜色编码
- 颜色编码:右侧颜色条显示了相关性的取值范围,从蓝色到红色,蓝色代表负相关,红色代表正相关。颜色越深,相关性绝对值越大;颜色越浅,相关性越接近 0 。
特征相关性分析
- 与离职(turnover)相关
- 满意度(satisfaction)与 turnover:相关性为 - 0.39,呈较强负相关,即员工满意度越高,离职可能性越低。
- 工作事故(workAccident)与 turnover:相关性为 - 0.15,呈负相关,发生工作事故少的员工离职倾向稍低。
- 特征间相关性
- 项目数(projectCount)与平均月工时(averageMonthlyHours):相关性为 0.42 ,呈正相关,参与项目数多的员工,平均月工时往往也较多。
- 项目数(projectCount)与上次评估得分(evaluation):相关性为 0.35,说明参与项目数多的员工,上次评估得分可能较高。
- 满意度(satisfaction)与其他多数特征:相关性较低,绝对值多在 0.1 左右,表明满意度与其他特征间线性关联不紧密。
4. 特征工程与数据拆分
# 划分特征与标签
X = df.drop('turnover', axis=1)
y = df['turnover']
# 分层抽样拆分数据集
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
stratify=y, # 保持类别分布
random_state=42
)5. 模型构建与评估
5.1 决策树模型
# 初始化决策树
dtree = DecisionTreeClassifier(
criterion='entropy',
max_depth=3,
min_samples_leaf=0.01,
random_state=42
)
# 训练模型
dtree.fit(X_train, y_train)
# 模型评估
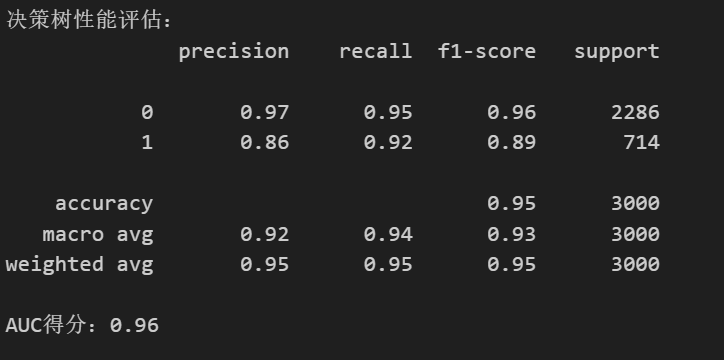
print("决策树性能评估:")
print(classification_report(y_test, dtree.predict(X_test)))
print(f"AUC得分:{roc_auc_score(y_test, dtree.predict_proba(X_test)[:,1]):.2f}")输出:
5.2 随机森林模型
# 初始化随机森林
rf = RandomForestClassifier(
n_estimators=100,
max_depth=5,
class_weight='balanced', # 处理数据不平衡
random_state=42
)
# 训练模型
rf.fit(X_train, y_train)
# 模型评估
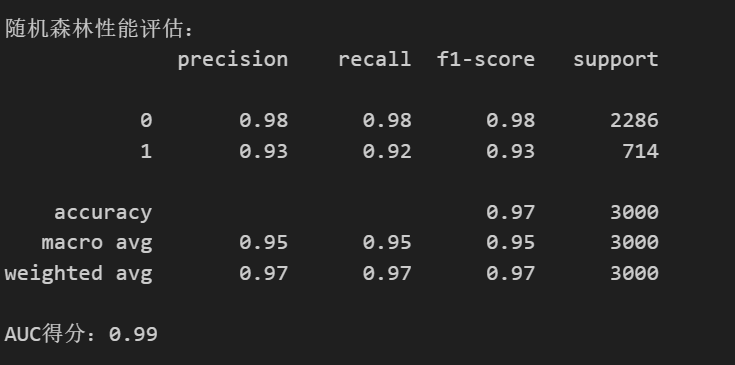
print("\n随机森林性能评估:")
print(classification_report(y_test, rf.predict(X_test)))
print(f"AUC得分:{roc_auc_score(y_test, rf.predict_proba(X_test)[:,1]):.2f}")输出:
6. 关键特征解析
# 获取特征重要性
feature_importance = pd.Series(rf.feature_importances_, index=X.columns)
feature_importance = feature_importance.sort_values(ascending=False)
# 可视化特征重要性
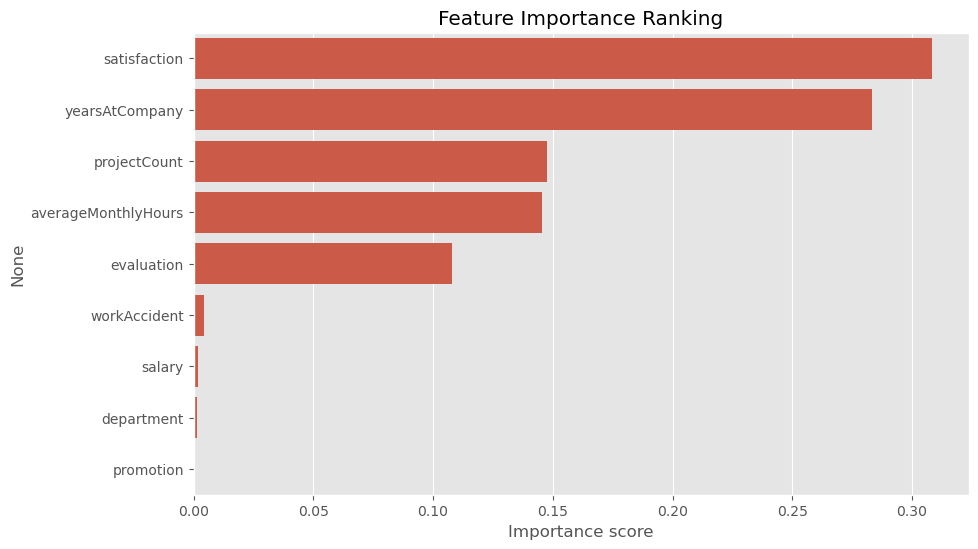
plt.figure(figsize=(10,6))
sns.barplot(x=feature_importance, y=feature_importance.index)
plt.title('特征重要性排序')
plt.xlabel('重要性得分')输出:
特征重要性分析
- 高重要性特征
satisfaction(满意度):重要性得分最高,接近 0.30 。说明在模型中,员工满意度对结果的影响最大,是预测员工离职等相关目标时极为关键的因素。yearsAtCompany(司龄):重要性得分较高,仅次于满意度,表明员工在公司工作的时长也是影响结果的重要因素。
- 中等重要性特征
projectCount(参与项目数) 和averageMonthlyHours(平均月工时):重要性得分相近,均在 0.15 左右 ,说明这两个特征对模型也有一定影响,但重要程度低于满意度和司龄。evaluation(评估得分):重要性得分约为 0.10 ,相对来说对模型的影响程度处于中等水平。
- 低重要性特征
workAccident(工作事故)、salary(薪资)、department(部门) 和promotion(升职情况):这些特征的重要性得分很低,几乎接近 0 。意味着在该模型中,它们对预测结果的影响非常小。
7. 分析结论
-
关键离职驱动因素
-
员工满意度与离职率呈强负相关其相关系数为相关系数-0.39
-
满意度分布分析来看高绩效员工离职呈现双峰现象
-
月均工时超过250小时的员工离职风险显著增加
-
-
模型表现对比
模型
准确率
召回率
AUC
决策树
0.97
0.95
0.96
随机森林
0.98
0.98
0.99
-
业务建议
-
建立满意度实时监测系统
-
优化高绩效员工的工作强度分配
-
对司龄3-5年的员工加强关怀计划
-
8. 后续优化方向
-
模型优化
-
可以尝试XGBoost、LightGBM等梯度提升算法
-
还可以使用SMOTE等过采样技术处理数据不平衡
-
-
特征工程
-
构建交叉特征,比如:满意度×绩效评分
-
添加时间序列特征,比如历史行为数据
-
-
部署应用
-
可以用flask,django,flask等框架开发可视化预警看板
-
当然也可以集成到HR系统实现实时预测
-


















 9105
9105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









