






 本文详细介绍了使用Pandas在Python中进行数据处理,包括Series和DataFrame的基本操作,如创建、去重、统计值出现次数、查找空值、切片、计算(如求和、平均值等)、数据框的合并、排序、读取文本文件以及滚动计算函数的使用。
本文详细介绍了使用Pandas在Python中进行数据处理,包括Series和DataFrame的基本操作,如创建、去重、统计值出现次数、查找空值、切片、计算(如求和、平均值等)、数据框的合并、排序、读取文本文件以及滚动计算函数的使用。
基本函数:
S1 = pd.Series([1,2,3.5,'he']) # 创建序列S1
va1 = s1.values # 获取s1 值
in1 = s1.index # 获取s1 索引
s1 = s1.unique() # 去重复函数:
序列空值
s2 = s1.isin([0,'he']) # 寻找是否存在0,he,有返回turn 没有返回false
c1 = s1.value_counts() # value_counts()统计序列元素值出现的次数
null1 = s1.notnull() # 查找非空值,空值返回false 非空返回turn
null2 = s1.isnull() # 查找空值,空值返回turn非空返回false
KillNull = s1.dropna() # 清除空值
null_S_1 = null_S.fillna('kill') #空值填充 # 将va2 通过list命令转换为列表的形式
va2 = list(va1)
in2 = list(in1)
序列切片
s22 = s2[['a','d']] # 取索引找出目标元素值
s11 = s1[0:4] # 索引为连续的数组
s12 = s1[[0,1,3]] # 索引为不连续的数组
s44 = s4[s4>2] # 索引逻辑如满足则返回序列的计算
s1 = pd.Series([1,2,3,4,5,6,7,8,9,10])
sum_s1 = s1.sum() # 求和
avg_s1 = s1.mean() # 平均值
sstd = s1.std() # 标准差
max_s1 = s1.max() # 最大值
min_s1 = s1.min() # 最小值
SV = s1.var # 方差数据框
data = {'a':[2,2,np.nan,5,6],
'b':['k1','k1','k1',np.nan,'k1'],
'c':[4,6,5,np.nan,6],
'd':[7,9,np.nan,9,8]}
Df = pd.DataFrame(data) # 将字典转换为数据框,键转换为列标题,索引从零开始数据框的水平合并
df1 = pd.concat([df1,df2],axis=1) # 水平合并
df2 = pd.concat([df1,df2],axis=0) # 垂直合并,有相同的列名,index属性不改变
df2.index = range(6) # 重新设置index属性Df1 = Df.dropna() # 去掉数据集的空值行
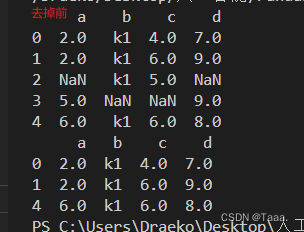
Df2 = Df.sort_values('a',ascending=False) # 数据集排序默认为升序 False 为降序
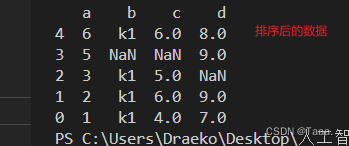
Df3 = Df2.sort_index(ascending=False) # 索引排序 默认为升序 False 为降序
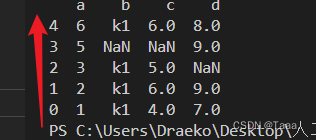
Df4 = Df3.head(4) # head(n)取前n行的数据 这里写的4
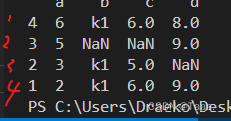
Dp = Df3.drop('b',axis=1) # 删除b列 axis代表指定轴数

Df4 = Df.join(Dftwo) # 数据框水平连接
list1 = ['a','b','c','d','e','f']
list2 = [1.1,1.2,1.3,1.4,1.4,1.6]
list3 = [1,2,3,4,5,6]
D = {'M1':list1,'M2':list2,'M3':list3,}
Dfd = pd.DataFrame(D)
print(Dfd)
G1 = Dfd.to_numpy() # 将数据框转换为Numpy数组
print(G1)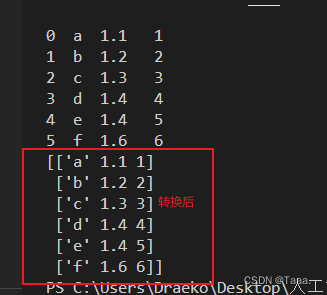
注意:转换纯数组转换Numpy数组,使用起来更加方便
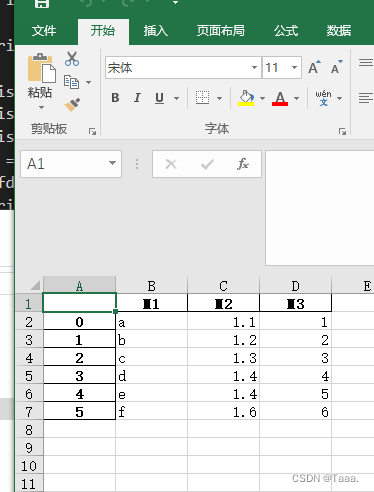
Dfd.to_excel('Dfd.xlsx') # 将数据框导出为excel文件
此处需要安装openpyxl模块
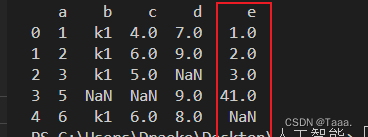
SumDt = Dt.sum() # 各项求和
AvgDt = Dt.mean() # 各项求平均值
ConDt = Dt.describe() # 各项做描述性统计

数据框的切片
c1 = df1.iloc[1:3,2] # 第①项代表元素索引,0开始,第②项代表列数,0开始
c2 = df1.iloc[1:3,0:2] # 这①里表示1-3索引(行)不包括3 ②表示列不包括2
c3 = df1.iloc[1:4,:] # :表示所有列
c4 = df1.iloc[[1,3,4],[1,2]] #指定行指定列
TF = [True,False,False,False,True]
c5 = df1.iloc[TF,[1]] # 是True就显示数据loc切片
c6 = df2.loc[df2['b']=='k1',:] # 等于k1的所有行
c7 = df2.loc[df2['b']=='k1',:].head(3) #.head表示前n项
c8 = df2.loc[df2['b']=='k1',['a','c']] # 指定ac列数据读取
excel
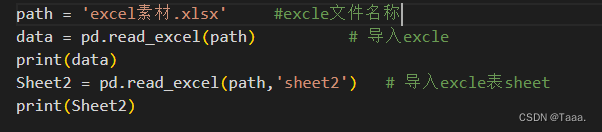
有时可加入属性 header=None 表示无表头
text
dat1 = pd.read_table('txt素材.txt',header=None,sep=' ') # sep=指定分割符csv
dat2 = pd.read_csv('123.csv',sep=' ',chunksize=5000,usecols=[3,4,10])
# chunksize表示读取记录数 usecols指定读取的列
k = 0
for A in dat2: # 遍历查看每次读取的规模
k += 1
print('第' + str(k) + '次' + '读取规模为',len(A))滚动计算函数
A = pd.Series([1,2,3,4,5,6,7])
B = np.array([1,2,3,4,5,6,7])
B_Df = pd.DataFrame(B) # 数组型需要转换为数据框
a_rol = A.rolling(window=5).mean() # window 表示滚动计算长度 这里计算的是平均值mean
b_rol = B_Df.rolling(window=5).mean()
print(a_rol)
print(b_rol)














 1836
1836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









