






 文章介绍了如何使用Python的requests库获取网页数据,通过设置headers模拟浏览器行为避免被封禁。接着,讲解了BeautifulSoup库解析网页,通过find_all和特定属性提取所需信息。
文章介绍了如何使用Python的requests库获取网页数据,通过设置headers模拟浏览器行为避免被封禁。接着,讲解了BeautifulSoup库解析网页,通过find_all和特定属性提取所需信息。
随便你会一丢丢python就可以灵活运用python爬虫
1、requests使用:(抓取数据)
requests 的作用是用网址,去获取网页的数据。
一般的小网页可以使用:
import requests
url = 'http://www.baidu.com' #url是变量,装的网址,是字符串类型
soup = requests.get(url=url) #这就是获取数据的方法,你就能把整个网页数据拿下来较正常的网页:
就是为了防止电脑用代码恶意爬取此网址,电脑代码的巨额量访问有可能导致网址崩溃。所以直接封禁了不是人为的操作。
所以我们上面的代码就不起作用了,反而反之爬虫也学会了模仿人的操作,把自己包装成例如人在使用浏览器访问它网页的意思。
下图就是可以把电脑代码包装成为真人在用浏览器访问的神奇魔法!!它就是 headers
import requests #调用包进来进行使用
url = 'http://www.baidu.com'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.37"
}
soup = requests.get(url=url,haders=headers)在此不要迷茫我会教你怎么弄headers 里面的内容
1、打开浏览器
2、把你要爬取的网址输入进去后,按回车
3、按一下键盘上的F12
4、下图所示
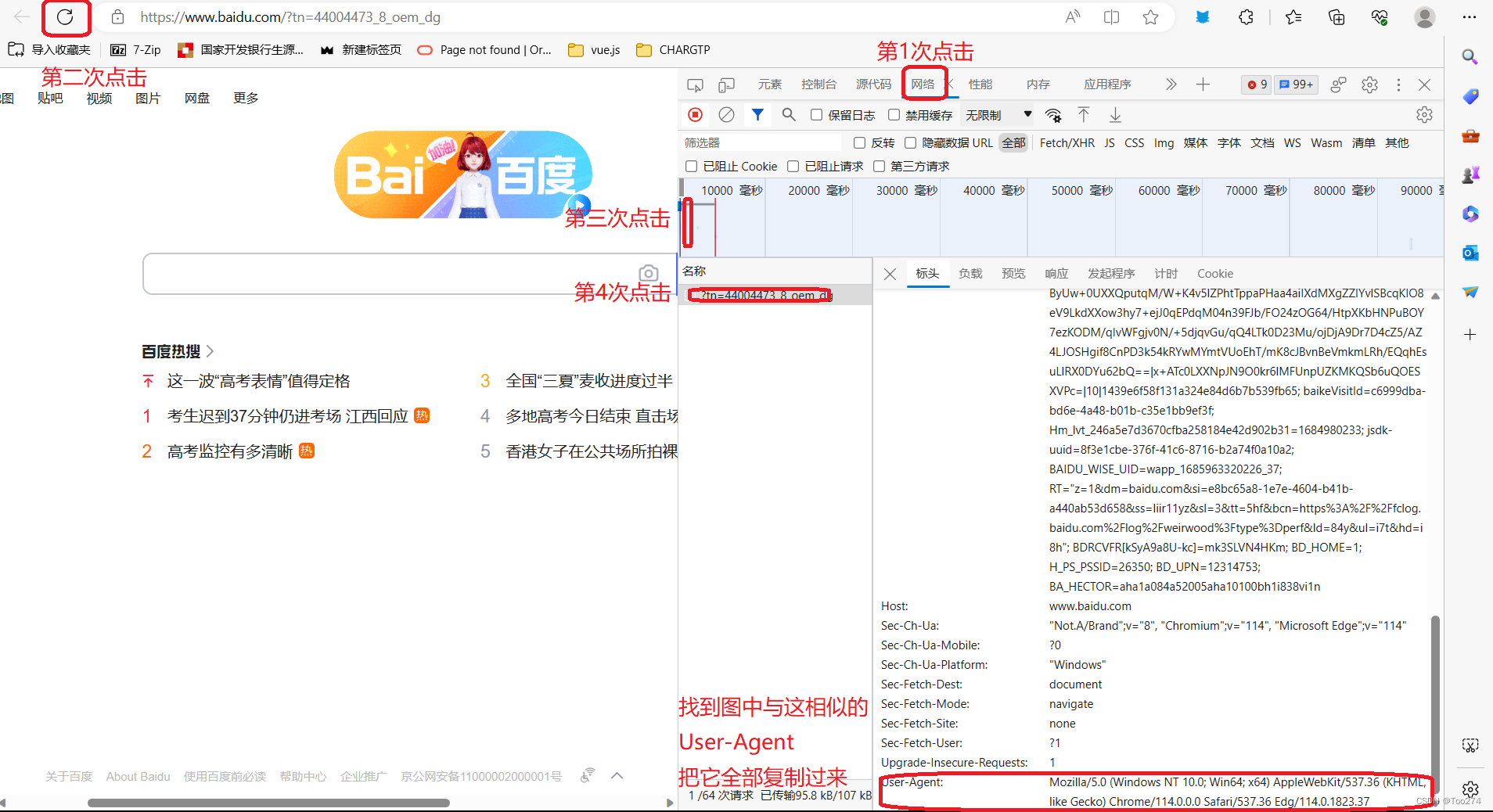
5、如我第二块代码区域在两侧添加上 双引号(一共两对双引号),中间用 冒号(:) 隔开!!
好了现在数据你可以随便拿了
2、BeautifulSoup的使用(解析网页用的)
网页数据你拿了下来并不是直接就可以使用,还需要解析一下我们才可以拿到自己想要的数据。
import requests #调用包进来进行使用
url = 'http://www.baidu.com'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.37"
}
response = requests.get(url=url,haders=headers)
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, "lxml") #response.text 把网页拿下来的数据提取出来
#用lxml来进行解析,还有其他的解析方法可以自行去了解
for i in soup.find_all(): #find_all解析过的所有数据,可以拿来遍历。
print(i) #就可以输出遍历出来的数据了接下来就讲解该如何提取数据(下面一黑一白图表,壹壹对应)自行理解:(看完不懂可以跳过 两图 先往下看再返回理解)
#通过以上代码我们到了遍历的阶段。连接此图和下图自行理解。
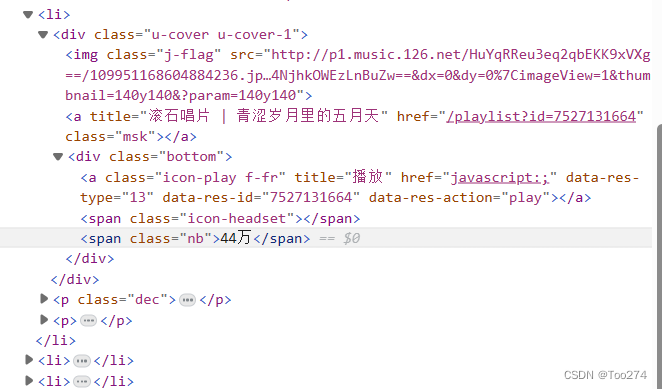
for i in soup.find_all(name='li'):
print(i.find(attrs={'class':'msk'}))
print(i.find(attrs={'class':'msk'})['title'])
print(i.find(attrs={'class':'nb'}))
print(i.find(attrs={'class':'nb'}).string)
soup.find_all()里面的name='li', li是一个标签,因为我们要抓取的数据都在li标签里面,所以name='li'。以此理解可以举一反三。下图展示的是自己需要的数据在li标签内。所以需要name='li'。!!!!!!
然后就拿到你心仪的数据啦,希望能帮到各位码友。😘😘

















 1305
1305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









