







*严正声明:本文仅限于技术讨论与分享,严禁用于非法途径。
目录
*谨慎使用爬虫,切勿违法使用
工具储备:
一个待爬的网站url;
Python3环境;
自己熟悉的编辑器,如:Vscode,IDLE,PyCharm 等.
安装requests库和beautifulsoup库(正常安装Python时自带的);
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple #使用国内镜像源下载查看库是否可以使用
import requests #验证requests库是否能够正常使用,不报错表示正常.
from bs4 import BeautifulSoup #验证BeautifulSoup*注意大小写*.

库的简述:
调用两个库
# 调用requests库和BeautifulSoup库
import requests
from bs4 import BeautifulSoup
# 如果正常get请求无法访问,使用headers模拟浏览器请求
# headers = {"User-Agent":" Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:102.0) Gecko/20100101 Firefox/102.0"}
# 将需要爬取的网站url存入url函数
url = 'http://www.gxcdncp.com/'
# 调用requests.get模块导入url,如果https需要证书,使用verify=Fale在get()中绕过证书
response = requests.get(url)
# 调用response.text 显示内容
text = response.text
# 使用BeautifulSoup库中的html.parser解释器将网站内容解析成html格式
# BeautifulSoup库还有lxml和tml5lib解释器,根据需求自行选择
soup = BeautifulSoup(text,'html.parser')爬虫代码解析:
使用浏览器访问需要爬取网站,f12进行检查,可以获取需要的标签,属性信息
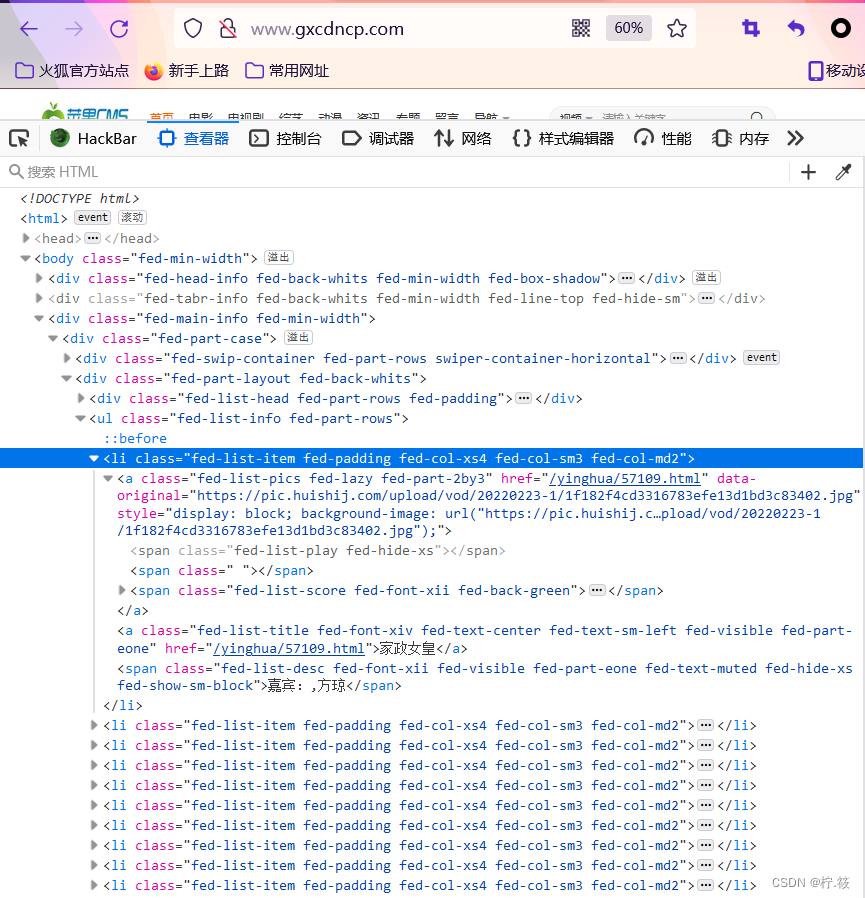
使用.find_all查询网站内容(具体信息可以自行学习BeautifulSoup库的使用)
.find_all('标签名',{'属性':'属性内容'}) # .find_all查找全部数据
.find('标签名',{'属性':'属性内容'}) # .find查找一条数据
将.find放入.find_all循环中获取精准信息,*find内标签需要属于find_all内标签,find_all包含find*
.find().text # 获取标签内文本
.find().get('') # 获取标签内指定属性内容
print()将其输出
video = soup.find_all('li',{'class':'fed-list-item fed-padding fed-col-xs4 fed-col-sm3 fed-col-md2'})
for d in video :
videotitle = d.find('a',{'class':'fed-list-title fed-font-xiv fed-text-center fed-text-sm-left fed-visible fed-part-eone'}).text
videourl = d.find('a', {'class':'fed-list-title fed-font-xiv fed-text-center fed-text-sm-left fed-visible fed-part-eone'}).get('href')
videoactor = d.find('span',{'class':'fed-list-desc fed-font-xii fed-visible fed-part-eone fed-text-muted fed-hide-xs fed-show-sm-block'}).text
videopicture = d.find('a',{'class':'fed-list-pics fed-lazy fed-part-2by3'}).get('data-original')
print ('视频标题-',videotitle)
print ('视频链接-',videourl)
print ('视频演员-',videoactor)
print ('视频图片-',videopicture)如果遇到AttributeError: 'NoneType' object has no attribute 'text'报错
是因为find搜索中遇到了空值,所以会报错
需要将find循环判断是否为空值
for c in first :
if c.find('a',{'class':'fed-menu-title fed-show-kind fed-font-xvi fed-hide fed-show-lg-block'}):
firsttitle = c.find('a',{'class':'fed-menu-title fed-show-kind fed-font-xvi fed-hide fed-show-lg-block'}).text
firsturl = c.find('a',{'class':'fed-menu-title fed-show-kind fed-font-xvi fed-hide fed-show-lg-block'}).get('href')
print ('首页标题-',firsttitle)
print ('首页链接-',firsturl)
else:
firsttitle = 0
firsturl = 0完整代码:
爬取内容为:
网站首页导航标题和链接;
网站首页视频标题,链接,分类和封面图片
# 如果需要将其保存出来,可以调用csv库将其放入列表保存为表格形式
import requests
from bs4 import BeautifulSoup
# headers = {"User-Agent":" Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:102.0) Gecko/20100101 Firefox/102.0"}
url = 'http://www.gxcdncp.com/'
response = requests.get(url)
text = response.text
soup = BeautifulSoup(text,'html.parser')
first = soup.find_all('li',{'class':'fed-pull-left'})
for c in first :
if c.find('a',{'class':'fed-menu-title fed-show-kind fed-font-xvi fed-hide fed-show-lg-block'}):
firsttitle = c.find('a',{'class':'fed-menu-title fed-show-kind fed-font-xvi fed-hide fed-show-lg-block'}).text
firsturl = c.find('a',{'class':'fed-menu-title fed-show-kind fed-font-xvi fed-hide fed-show-lg-block'}).get('href')
print ('首页标题-',firsttitle)
print ('首页链接-',firsturl)
else:
firsttitle = 0
firsturl = 0
if c.find('a',{'class':'fed-menu-title fed-show-kind fed-font-xvi fed-hide fed-show-md-block'}):
ftitle = c.find('a',{'class':'fed-menu-title fed-show-kind fed-font-xvi fed-hide fed-show-md-block'}).text
furl = c.find('a',{'class':'fed-menu-title fed-show-kind fed-font-xvi fed-hide fed-show-md-block'}).get('href')
print ('首页标题-',ftitle)
print ('首页链接-',furl)
else:
ftitle = 0
furl = 0
video = soup.find_all('li',{'class':'fed-list-item fed-padding fed-col-xs4 fed-col-sm3 fed-col-md2'})
for d in video :
videotitle = d.find('a',{'class':'fed-list-title fed-font-xiv fed-text-center fed-text-sm-left fed-visible fed-part-eone'}).text
videourl = d.find('a', {'class':'fed-list-title fed-font-xiv fed-text-center fed-text-sm-left fed-visible fed-part-eone'}).get('href')
videoactor = d.find('span',{'class':'fed-list-desc fed-font-xii fed-visible fed-part-eone fed-text-muted fed-hide-xs fed-show-sm-block'}).text
videopicture = d.find('a',{'class':'fed-list-pics fed-lazy fed-part-2by3'}).get('data-original')
print ('视频标题-',videotitle)
print ('视频链接-',videourl)
print ('视频演员-',videoactor)
print ('视频图片-',videopicture)
video2 = soup.find_all('li',{'class':'fed-list-item fed-padding fed-col-xs4 fed-col-sm3 fed-col-md2 fed-hide-sm fed-show-md-block'})
for e in video2:
videotitle2 = e.find('a',{'class':'fed-list-title fed-font-xiv fed-text-center fed-text-sm-left fed-visible fed-part-eone'}).text
videourl2 = e.find('a', {'class':'fed-list-title fed-font-xiv fed-text-center fed-text-sm-left fed-visible fed-part-eone'}).get('href')
videoactor2 = e.find('span',{'class':'fed-list-desc fed-font-xii fed-visible fed-part-eone fed-text-muted fed-hide-xs fed-show-sm-block'}).text
videopicture2 = e.find('a',{'class':'fed-list-pics fed-lazy fed-part-2by3'}).get('data-original')
print ('视频标题-',videotitle2)
print ('视频链接-',videourl2)
print ('视频演员-',videoactor2)
print ('视频图片-',videopicture2)
family = soup.find_all('li',{'class':'fed-hide-xs'})
for f in family :
familytitle = f.find('a').text
familyurl = f.find('a').get('href')
print ('视频分类-',familytitle)
print ('分类链接-',familyurl)















 7308
7308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











