






 本文详细介绍了YOLOv4的原理,以及其在无人驾驶、智能安防和移动端应用中的实际应用。重点讲述了数据集的准备、划分、预处理,以及模型的训练、测试和性能优化过程。
本文详细介绍了YOLOv4的原理,以及其在无人驾驶、智能安防和移动端应用中的实际应用。重点讲述了数据集的准备、划分、预处理,以及模型的训练、测试和性能优化过程。
一、YOLOv4的原理
YOLOv4的原理是基于深度学习的目标检测算法,它采用卷积神经网络(CNN)构建一个端到端的物体检测模型。其核心思想在于将输入图片作为一个整体,通过CNN通道进行预测输出,从而实现了速度快、准确度高的目标检测。
二、YOLOv4在目标检测的应用
一、YOLOv4在无人驾驶领域具有关键作用:它可以实时识别道路障碍物和交通标志,助力安全驾驶。通过对图像中的目标进行检测,车辆可以识别行人、车辆、交通信号灯等关键元素,从而做出正确的驾驶决策,避免潜在的危险。
二、在智能安防领域,YOLOv4也发挥着重要作用。它可以在商业场所或公共场所进行实时监控,检测异常情况并及时报警。通过对视频流的实时分析,系统能够及时发现潜在的安全隐患,提高安全性。
三、YOLOv4还可以应用于移动端应用开发。经过优化的模型可以在手机或平板电脑上实现高效的图像识别功能,为用户提供便捷的目标检测体验。
总的来说,YOLOv4以其高效准确的性能,在目标检测领域具有广泛的应用前景。无论是无人驾驶、智能安防还是移动端应用开发,YOLOv4都能为相关应用提供强大的支持。
三、数据集的准备
通过各种途径,收集本次实验所需的数据,将其保存到本地文件并命名,均设为jpg格式。(如下图)
四、数据集的划分
为了更好地反映数据集中的不同类别和特征,也可以采用分层划分的方法。首先,根据数据集中的不同类别(猫、狗、游客)进行分层,然后在每个类别内部按照一定比例进行划分。这样可以确保每个集合中都包含有足够数量的各类样本,有助于模型更好地学习各类目标的特征。在划分数据集时,还需要注意避免数据集的偏斜和重复问题。偏斜可能会导致模型对某些类别的识别能力较弱,而重复则可能导致模型过拟合。因此,在划分过程中需要仔细检查数据,确保数据的多样性和质量。
五、数据预处理
对于划分好的数据集,还需要进行预处理,如图像缩放、归一化等,以适应YOLOv4模型的输入要求。同时,还需要制作相应的标签文件,用于模型训练时的监督学习。
六、模型训练
使用准备好的数据集和配置参数开始训练YOLOv4模型。在训练过程中,模型将学习如何识别和定位数据集中的目标。训练时间可能较长,具体取决于数据集的大小和模型的复杂度。(结果如图)

七、模型测试
运行predict.py文件得到想要的实验结果。(结果如图)
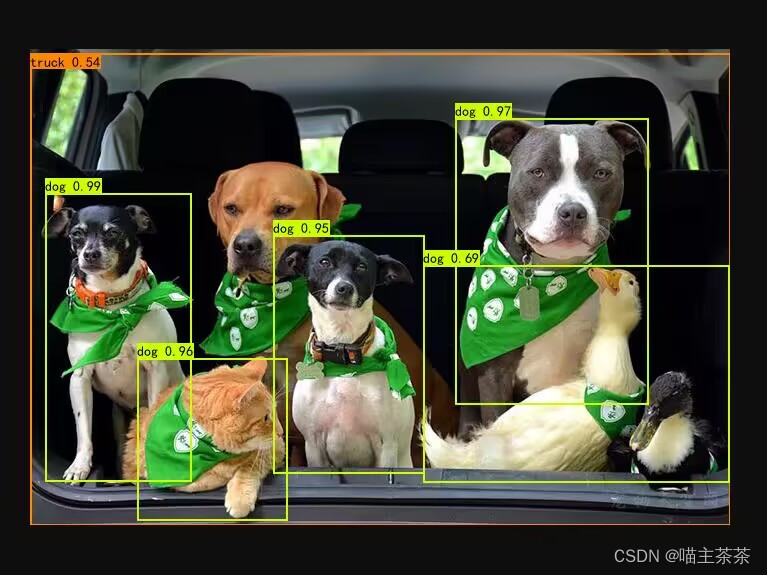
- 小结
根据评估指标的结果,对模型的性能进行分析。如果性能不佳,可以尝试调整模型参数、优化模型结构或改进数据预处理方式等方法来提高性能。同时,也可以通过对误检和漏检的样本进行分析,找出模型存在的问题并进行针对性的优化。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









