







爬虫的概念:
模拟浏览器,发送请求,获取响应
- 原则上,只要是客户端(浏览器)能做的事情,爬虫都能做
- 爬虫也只能获取客户端(浏览器)所展示出来的数据
爬虫的作用:
- 数据采集(数据分析、挖掘)
- 软件测试(自动化测试)
- 抢票
- 网站上的投票
- 网络安全(web漏洞扫描)
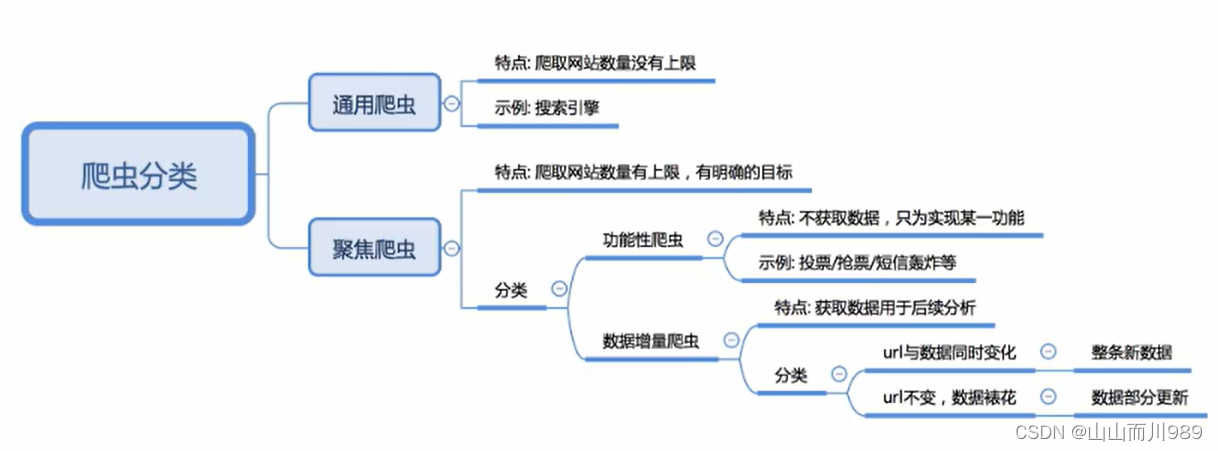
爬虫的分类:
根据被爬取网站的数量不同,分为
- 通用爬虫 :爬取目标网站没有上限 ,如搜素引擎
- 聚焦爬虫 :目标网站是有上限的 ,专门爬取某一个或某一类网站的数据
根据是否以获取数据为目的,分为:
- 功能性爬虫 :只以实现某个功能为目的(并不获取数据) ,如给喜欢的明星投票、点赞
- 数据增量爬虫 :以获取数据为目的 ,会把获得的数据存入数据库以便之后的分析
根据url地址和对应的页面内容是否改变,数据增量爬虫可分为:
- 基于url地址变化、内容也随之变化的数据增量爬虫
- url地址不变、内容变化的数控增量爬虫
爬虫的流程:
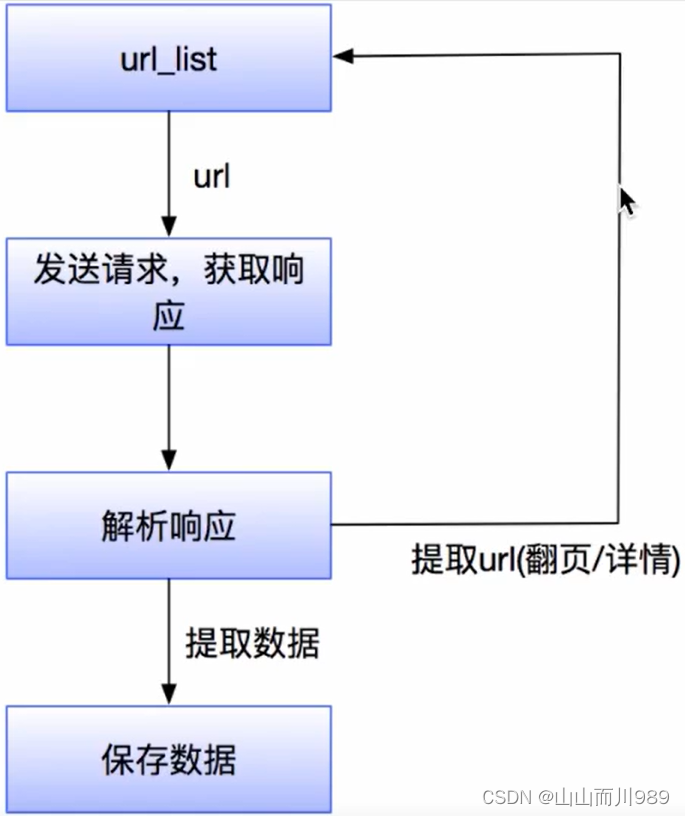
- 获取一个url
- 向url发送请求,并获取响应(需要http协议)
- 如果从响应中提取url,则继续发送请求获取响应
- 如果从响应中提取数据,则将数据进行保存
http以及https概念和区别:
HTTPS比HTTP更安全,但是性能更低
1.HTTP:超文本传输协议,默认端口号:80 缺点:明文的方式传输,不安全
- 超文本:是指超过文本,不仅限于文本,还包括图片、音频、视频等文件
- 传输协议:是指使用共用约定的固定格式来传递转换成字符串的超文本内容
2.HTTPS:HTTP + SSL(安全套接字层),即带来安全套接字层的超文本传输协议,默认端口号:443
- SSL对传输的内容(超文本,也就是请求或响应体)进行加密
3.可以打开浏览器访问一个url,右键检查,点击net work, 点选一个url,查看http协议的形式















 870
870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









