






 本文介绍了一种使用Python爬虫技术从豆瓣读书Top250页面抓取书籍名称、作者、译者、评分、出版社等信息,并将数据保存为CSV文件的方法,涉及正则表达式和网络请求库的使用。
本文介绍了一种使用Python爬虫技术从豆瓣读书Top250页面抓取书籍名称、作者、译者、评分、出版社等信息,并将数据保存为CSV文件的方法,涉及正则表达式和网络请求库的使用。
一、准备
1.豆瓣网址TOP250网址:豆瓣读书 Top 250
2.必要的库:
import re
import requests # 发送请求
from bs4 import BeautifulSoup # 解析网页
import pandas as pd # 存取csv
from time import sleep # 等待时间二、了解和明白目标
1.需要和准备提取的信息
book_name = [] # 书籍名称
book_url = [] # 书籍链接
book_contry = [] #国家
book_author = [] #作者
book_translator = [] #译者
book_year = [] # 上映年份
book_publisher = [] # 出版社
book_price = [] #价格
book_star = [] #书籍评分
book_star_people = [] # 评分人数
book_comment = [] #评论
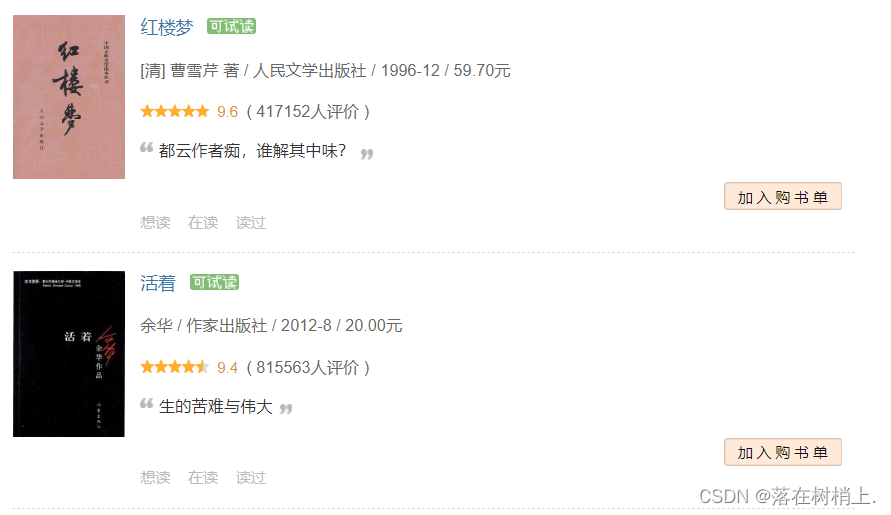
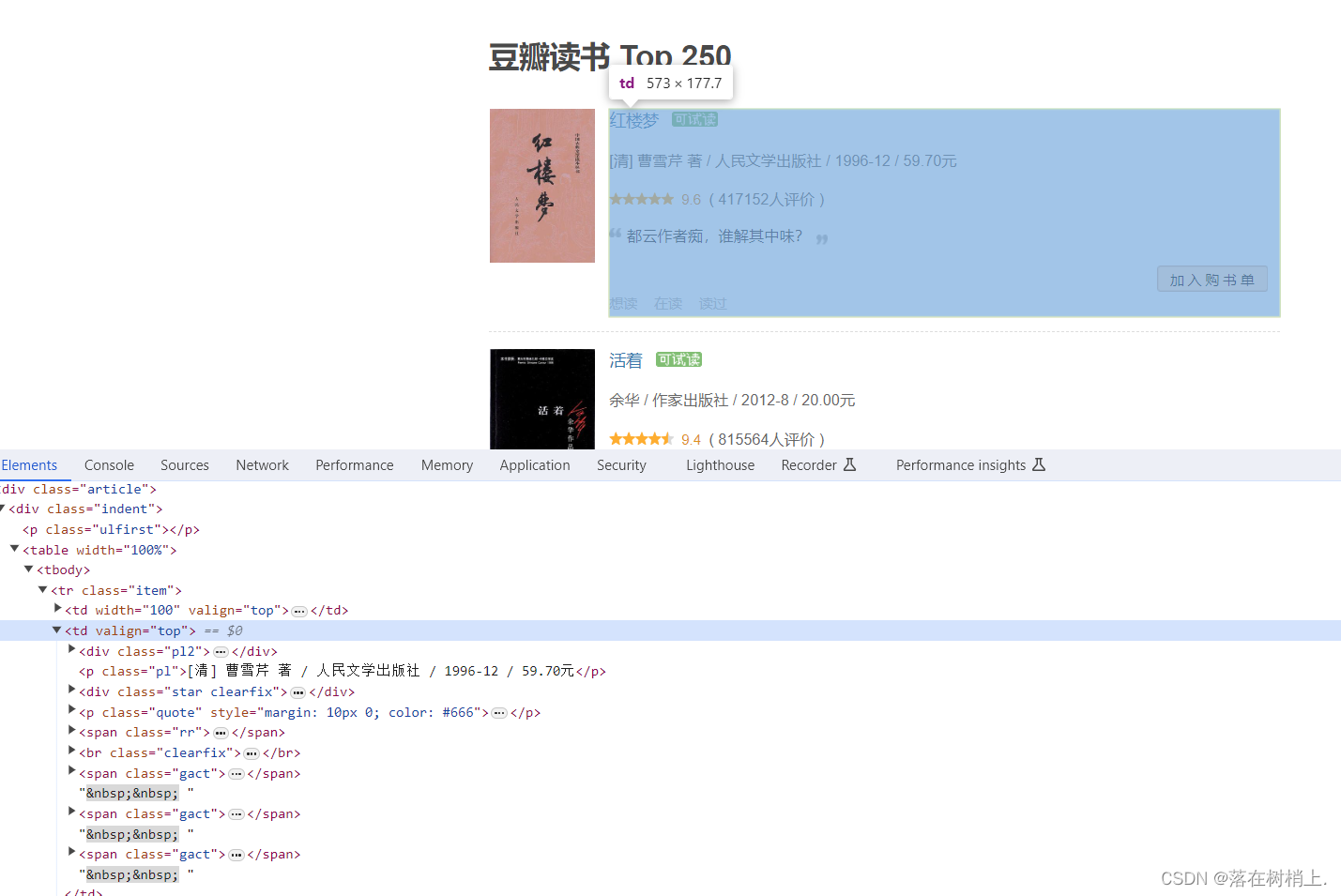
2.网页的位置信息(检查或者快捷键F12,可以找的到)
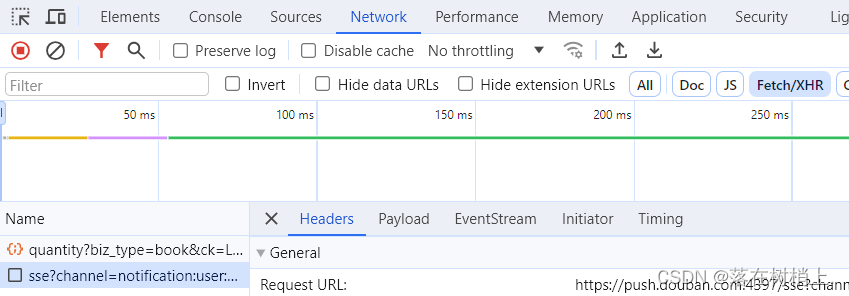
3.网页的Headers头信息(检查后,Network中Fetch/XHR,加上Ctrl+R,即可看见)
三、具体操作实现
1.提取数据实现(由于可能缺少国家和译者)
<p class="pl">[清] 曹雪芹 著 / 人民文学出版社 / 1996-12 / 59.70元</p><p class="pl">J.K.罗琳 (J.K.Rowling) / 苏农 / 人民文学出版社 / 2008-12-1 / 498.00元</p>采用正则化方式
# 使用正则表达式提取信息
pattern = re.compile(r'(?:\[(.*?)\] )?(.*?)(?: \/ (.*?))?(?: \/ (.*?)) \/ (.*?) \/ (.*?)元')
matches = pattern.match(book_info_text)
# 提取信息并插入列表,如果为空则插入 None
country = matches.group(1) if matches and matches.group(1) else None
# 处理作者信息,去除额外字符串
raw_author = matches.group(2) if matches and matches.group(2) else None
author = raw_author.replace(' 著', '') if raw_author else None
translator = matches.group(3) if matches and matches.group(3) else None
publisher = matches.group(4) if matches and matches.group(4) else None
year = matches.group(5) if matches and matches.group(5) else None
price = matches.group(6) if matches and matches.group(6) else None其他代码较为正常,易寻找
2.保存实现
def save_to_csv(csv_name):
"""
数据保存到csv
:return: None
"""
df = pd.DataFrame() # 初始化一个DataFrame对象
df['书籍名称'] = book_name
df['书籍链接'] = book_url
df['国家'] = book_contry
df['作者'] = book_author
df['译者'] = book_translator
df['上映年份'] = book_year
df['出版社'] = book_publisher
df['价格'] = book_price
df['评论'] = book_comment
df['书籍评分'] = book_star
df['评分人数'] = book_star_people
df.to_csv(csv_name, encoding='utf_8_sig') # 将数据保存到csv文件四、总代码实现 {使用需增加来源,支持原创}
1.要点:Headers最好需要改为自己的。
2.其中有注释。
3.最后的数据是.csv格式。
import re
import requests # 发送请求
from bs4 import BeautifulSoup # 解析网页
import pandas as pd # 存取csv
from time import sleep # 等待时间
book_name = [] # 书籍名称
book_url = [] # 书籍链接
book_contry = [] #国家
book_author = [] #作者
book_translator = [] #译者
book_year = [] # 上映年份
book_publisher = [] # 出版社
book_price = [] #价格
book_star = [] #书籍评分
book_star_people = [] # 评分人数
book_comment = [] #评论
def get_book_info(url, headers):
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, 'html.parser')
for book in soup.select('table'):
name = book.find('div', class_='pl2').a.text.strip().replace('"', '') # 书籍名称
book_name.append(name)
url = book.find('div', class_='pl2').a['href'] # 书籍链接
book_url.append(url)
star = book.find('div', class_='star').find('span', class_='rating_nums').text # 书籍评分
book_star.append(star)
# star_people = book.find('div', class_='star').find('span', class_='pl').text.strip().replace('人评价', '').replace("(",'').replace(")",'') # 评分人数
# book_star_people.append(star_people)
star_people_element = book.find('div', class_='star').find('span', class_='pl')
star_people_text = star_people_element.text.strip()
star_people = re.search(r'\d+', star_people_text).group() if re.search(r'\d+', star_people_text) else None
book_star_people.append(star_people)
try:
comment = book.find('p', class_='quote').span.text.strip() #评论
book_comment.append(comment)
except:
book_comment.append(None)
book_info_text = book.find('p', class_='pl').text.strip()
# 使用正则表达式提取信息
pattern = re.compile(r'(?:\[(.*?)\] )?(.*?)(?: \/ (.*?))?(?: \/ (.*?)) \/ (.*?) \/ (.*?)元')
matches = pattern.match(book_info_text)
# 提取信息并插入列表,如果为空则插入 None
country = matches.group(1) if matches and matches.group(1) else None
# 处理作者信息,去除额外字符串
raw_author = matches.group(2) if matches and matches.group(2) else None
author = raw_author.replace(' 著', '') if raw_author else None
translator = matches.group(3) if matches and matches.group(3) else None
publisher = matches.group(4) if matches and matches.group(4) else None
year = matches.group(5) if matches and matches.group(5) else None
price = matches.group(6) if matches and matches.group(6) else None
book_contry.append(country)
book_author.append(author)
book_translator.append(translator)
book_publisher.append(publisher)
book_year.append(year)
book_price.append(price)
def save_to_csv(csv_name):
"""
数据保存到csv
:return: None
"""
df = pd.DataFrame() # 初始化一个DataFrame对象
df['书籍名称'] = book_name
df['书籍链接'] = book_url
df['国家'] = book_contry
df['作者'] = book_author
df['译者'] = book_translator
df['上映年份'] = book_year
df['出版社'] = book_publisher
df['价格'] = book_price
df['评论'] = book_comment
df['书籍评分'] = book_star
df['评分人数'] = book_star_people
df.to_csv(csv_name, encoding='utf_8_sig') # 将数据保存到csv文件
if __name__ == "__main__":
# 定义一个请求头(防止反爬)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36' }
# 开始爬取豆瓣数据
for i in range(10): # 爬取共10页,每页25条数据
page_url = 'https://book.douban.com/top250?start={}'.format(str(i *25))
print('开始爬取第{}页,地址是:{}'.format(str(i + 1), page_url))
get_book_info(page_url, headers)
sleep(2) # 等待1秒(防止反爬)
# 保存到csv文件
save_to_csv(csv_name="BookDouban250.csv")


















 1002
1002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









