






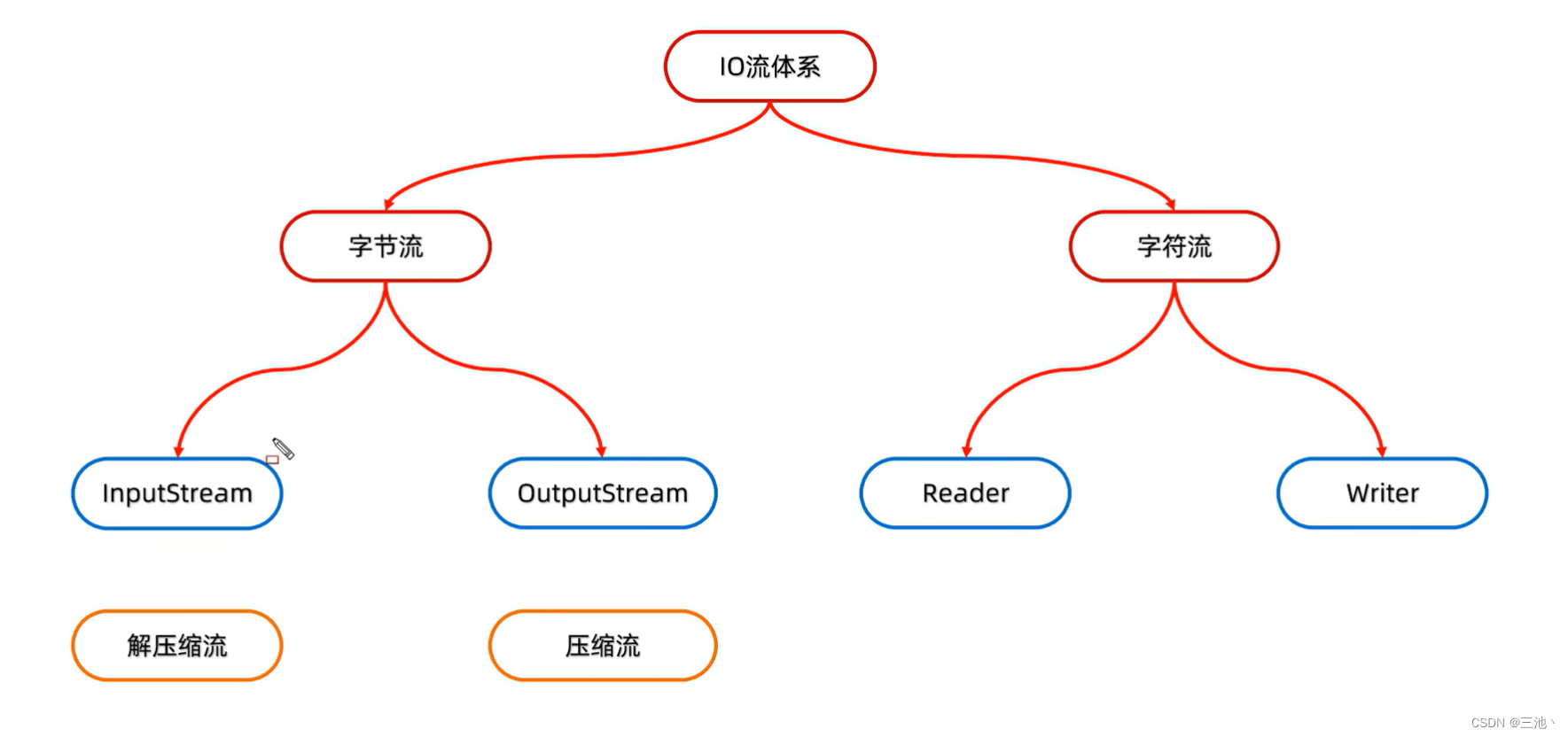
io流的概述和分类
在使用IO流时,什么时候用就什么时候创建,什么时候不用就什么时候关闭
IO流:存储和读取数据的解决方案
就比如游戏的存档,需要两个知识点:文件的位置,信息的传输
注意,File类只能对文件本身进行操作,不能读写文件里的数据,所以需要学习io流,用于读写文件中的数据(可以读写文件,或网络中的数据)
io流可以把程序中的数据保存到文件中,也就是写出(output)数据,还可以把文件中的数据加载到程序中,就是读取(input)数据。

以程序为参照物看读写的方向,是程序在读取或写出数据
- io流的分类
cao以流的方向分类可以分为:输入流和输出流。
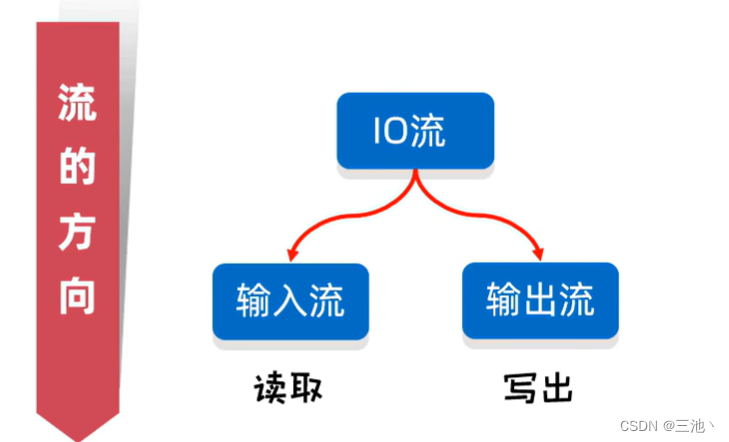
以操作文件类型分类可以分为:
字节流和字符流。
字节流可以操作所有类型的文件,字符流只能操作文本类型的文件
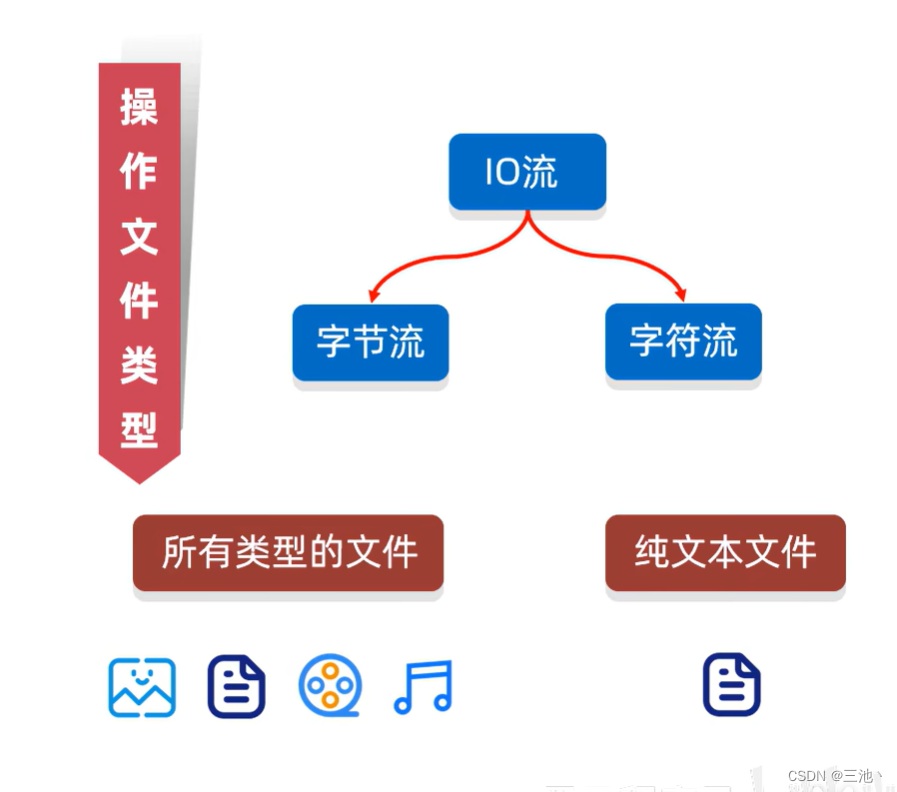
纯文本文件:用记事本能看懂的文件
- 小结

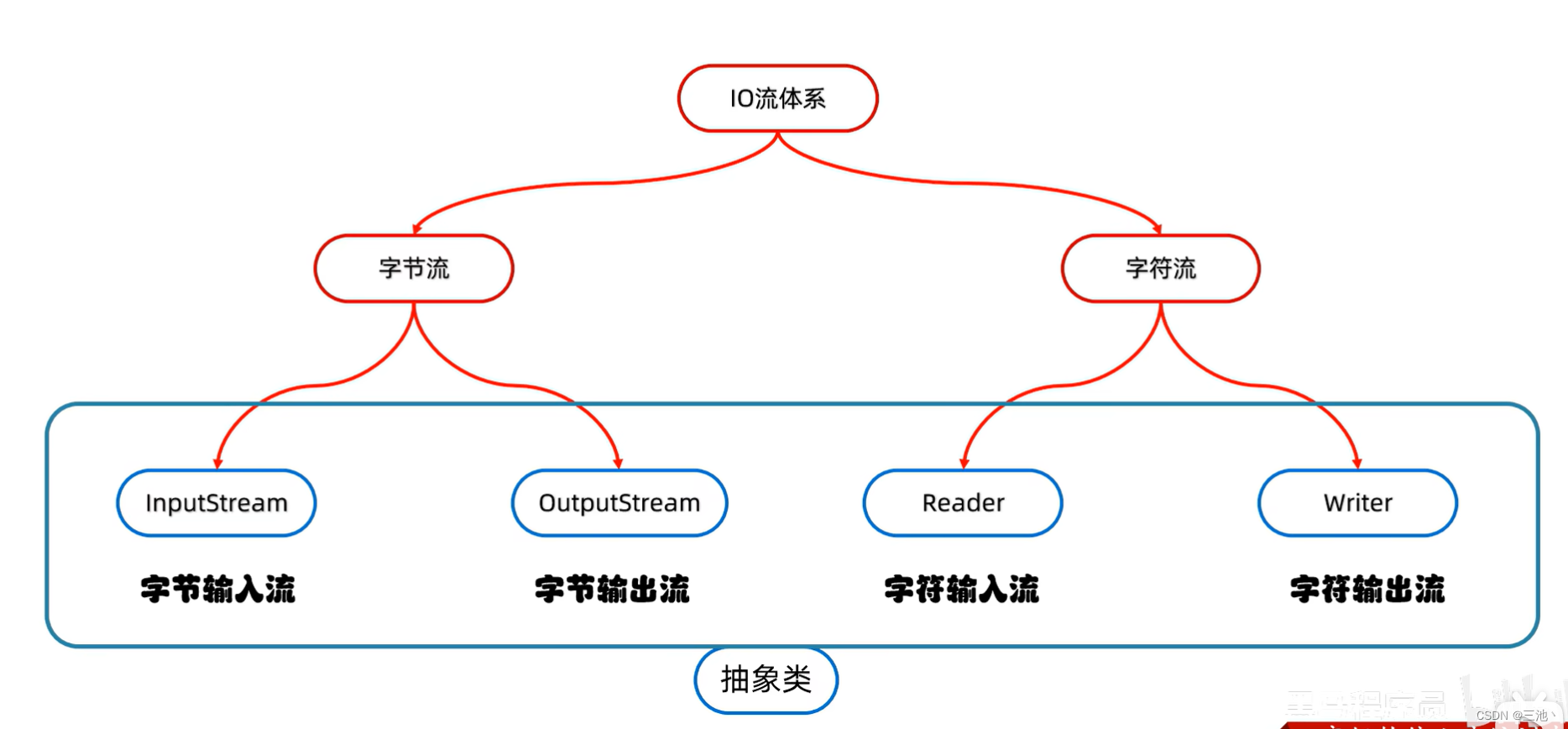
io流的体系
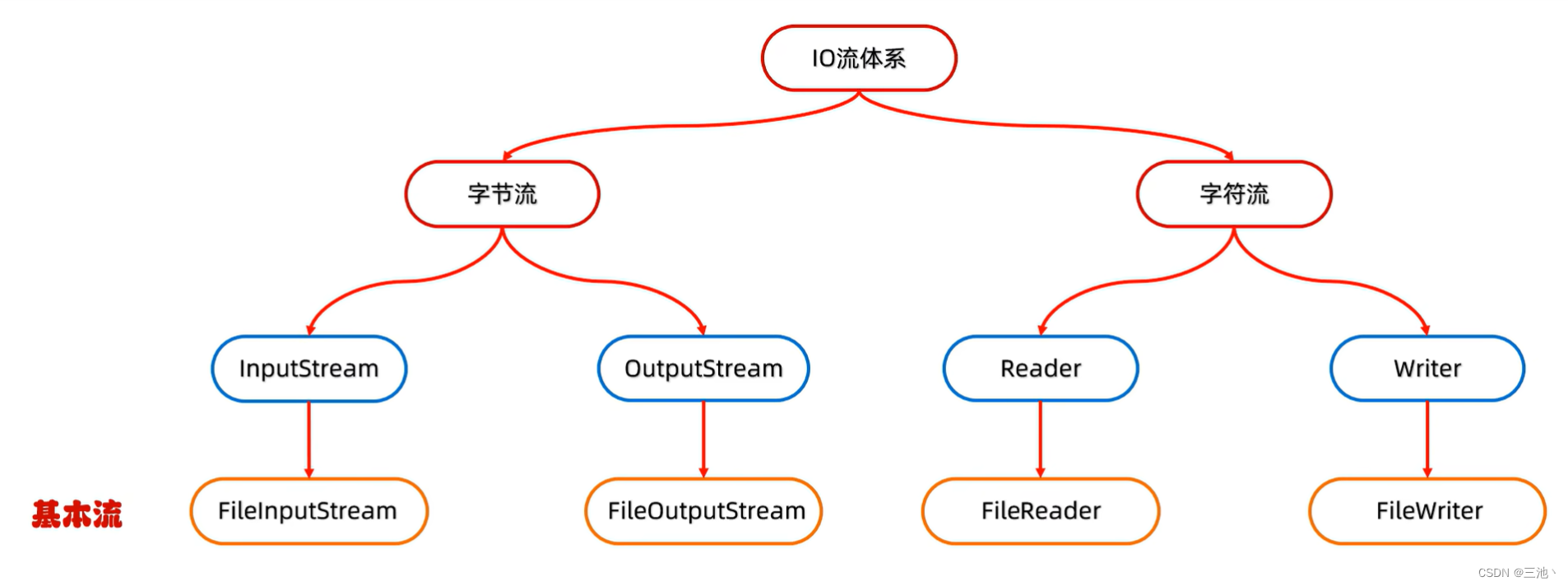
基本流
字节流
- 字节流的细分
字节输出流基本用法(FileOutputStream)
-
字节输出流的基本用法(FileOutputStream)
FileOutputStream:
操作本地文件的字节输出流,可以把程序中的数据写到本地中书写步骤:
1.创建字节输出流对象(创建对象时还要指定文件的路径)
2.写数据
3.释放资源(先创建的流最后在释放(关闭))

public static void main(String[] args) throws IOException { //创建对象,同时指定路径 FileOutputStream fos=new FileOutputStream("D:\\我的世界\\a1.txt"); //写数据 fos.write(98); //释放数据 fos.close(); //a1.txt 里出现一个 b } -
FileOutputStream原理
创建对象时指定的路径会让程序和相应的文件产生一个通道,然后通过这个通道写出数据,最后的close释放资源就是把通道清理掉了
字节输出流写出数据的细节
-
创建字节输出流对象的细节:
1.参数可以是字符串表示的路径或者是相应的File对象
2.指定的如果文件不存在会创建一个新的文件,但是要保证指定文件的父级路径是存在的
3.如果指定的文件已经存在,则会清空文件的内容(可以传递第二个参数来控制是否清空)。
-
写出数据
1.write方法的参数是整数,但是实际上写到本地文件上是整数在ASCII表所对应的字符
例如:
我想在文件中写97,那么可以把97分别看成两个单独的字符97 -
释放资源
每次使用完io流之后,都要释放资源
作用:可以接触java对文件的占用 -
小结

字节输出流写出数据的三种方式
| 方法名 | 说明 |
|---|---|
| void write(int b) | 一次写一个字节数据 |
| void write(byte[ ] b) | 一次写一个字节数组数据 |
| void write(byte[ ] b,int off,int len) | 一次写一个字节数组的部分数据 |
public static void main(String[] args) throws IOException {
FileOutputStream fos=new FileOutputStream("D:\\我的世界\\a1.txt");
//一次写一个
fos.write(97);//a
//一次写多个
byte[]arr={97,98,99,100,101};//aabcde
fos.write(arr);
//一次写一个数组的一部分
// void write(byte[ ] b,int off,int len)
//这里的三个参数分别表示为:
//参数1:代表数组
//参数2:代表截取的起始索引,截取时包括起始索引
//参数3:代表截取元素的个数
fos.write(arr,2,2);
//释放资源
fos.close();
}
字节输出流写出数据的两个问题
写之前先了解一个字符串的方法
getBytes,可以把字符串转化为一个byte类型的数组
使用这个方法可以很方便的把一些文字写入文件中
public static void main(String[] args) throws IOException {
FileOutputStream fos=new FileOutputStream("D:\\我的世界\\a1.txt");
String s="laoyangzuihaokan";
byte[] bytes = s.getBytes();
fos.write(bytes);
}
换行写和续写
- 换行写
在想要换行的两句中间写入一个换行符就行了
在window中,换行符是:\r\n
在Linux中,换行符是:\n
在Mac中,换行符是:\r
在java中写单独的\r或\n也是可以的,java会自动补全,但是不推荐单独写
public static void main(String[] args) throws IOException {
FileOutputStream fos=new FileOutputStream("D:\\我的世界\\a1.txt");
String s1="laoyangzuihaokan";
byte[] bytes1 = s1.getBytes();
fos.write(bytes1);
String s2="\r\n";
byte[] bytes2 = s2.getBytes();
fos.write(bytes2);
String s3="olhhg";
byte[] bytes3 = s3.getBytes();
fos.write(bytes3);
fos.close();
//laoyangzuihaokan
//olhhg
}
- 续写,即不清空原文件内容的情况下再写
FileOutputStream有两个参数,第一个是指定路径,第二个就是续写开关,true为开,可以续写,false为关,不能续写,且默认为false
public static void main(String[] args) throws IOException {
FileOutputStream fos=new FileOutputStream("D:\\我的世界\\a1.txt",true);
String s1="laoyangzuihaokan";
byte[] bytes1 = s1.getBytes();
fos.write(bytes1);
String s2="\r\n";
byte[] bytes2 = s2.getBytes();
fos.write(bytes2);
String s3="olhhg";
byte[] bytes3 = s3.getBytes();
fos.write(bytes3);
fos.close();
//运行两次后
//laoyangzuihaokan
//olhhglaoyangzuihaokan
//olhhg
}
- 小结

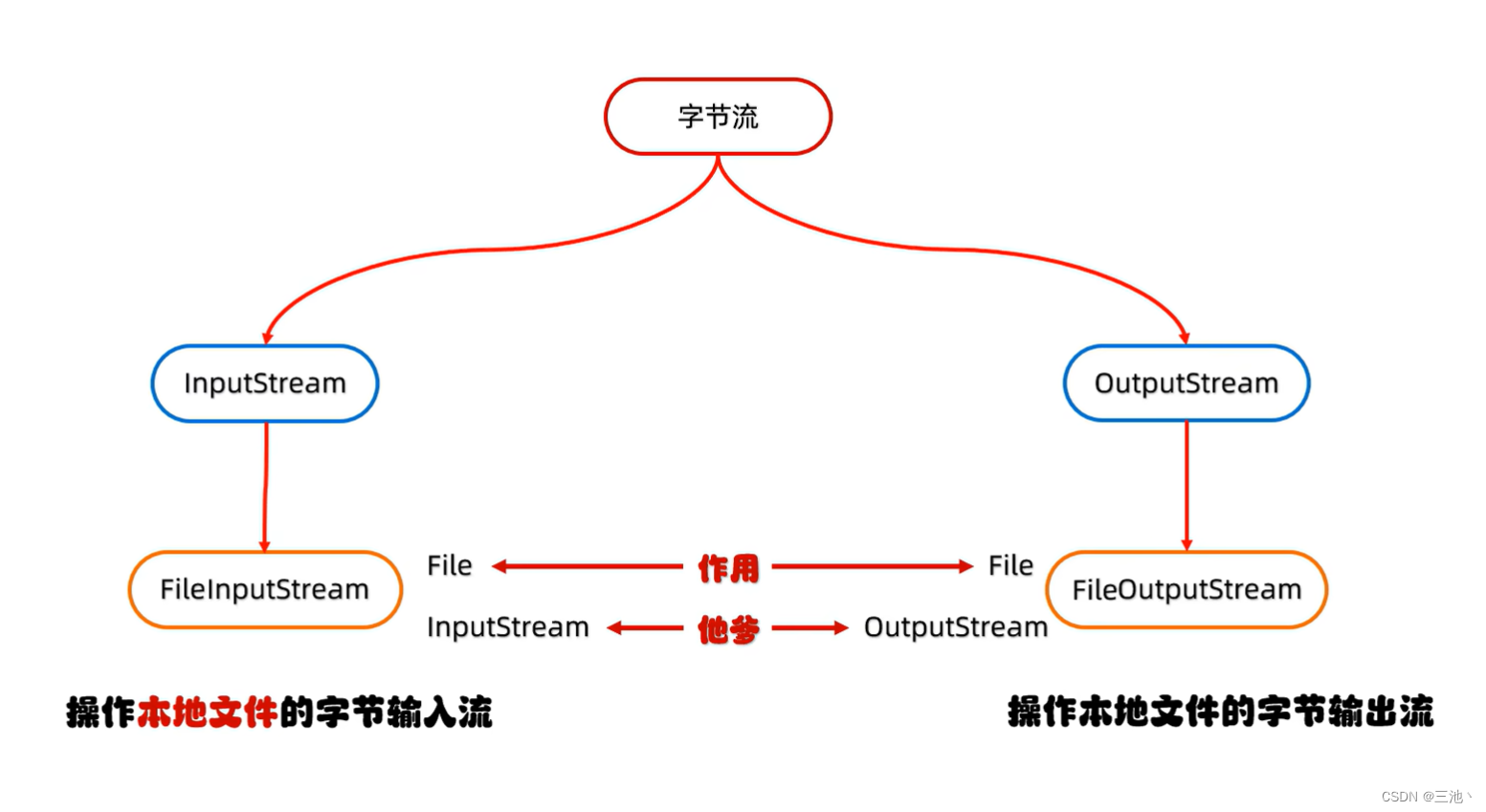
字节输入流的基本用法(FileInputStream)
-
FileInputStream
操作本地文件的字节输入流,可以把本地文件的数据读取到程序中来 -
书写步骤
1.创建字节输入流的对象
2.读取数据
3.释放资源
public static void main(String[] args) throws IOException { //创建对象 //这里a1.txt的数据是abcde FileInputStream fis=new FileInputStream("D:\\我的世界\\a1.txt"); //读取 //这里的read会依次读取数据并返回数据所对应的ASCII表上的数字 int i1 = fis.read(); System.out.println(i1);//97 int i2 = fis.read(); System.out.println(i1);//98 int i3 = fis.read(); System.out.println(i1);//99 int i4 = fis.read(); System.out.println(i1);//100 int i5 = fis.read(); System.out.println(i1);//101 int i5 = fis.read();//如果读不到数据了,就会返回-1 System.out.println(i1);//-1 //释放资源 fis.close(); }
字节输入流读取数据的细节
-
创建对象
1.如果文件不存在,直接报错
java这样设计的原因:
如果文件不存在创建文件的话,创建出来的文件是没有数据的,没有任何意义 -
读取数据
1.一次读一个字节,读出来的是数据再ASCII表上对应的数据
2.读到文件末尾,read方法就会返回-1 -
释放资源
每次使用完流后,必须释放资源
字节输入流循环读取
public static void main(String[] args) throws IOException {
//创建对象
//a1.txt的数据abcdeaadsadhasdbajhvabdbaiy
FileInputStream fis=new FileInputStream("D:\\我的世界\\a1.txt");
//循环读取
int b;// 赋值很重要,可以用它读取数据
while ((b=fis.read())!=-1){//这一步判断数据是否读到末尾
System.out.print((char) b);
}
//abcdeaadsadhasdbajhvabdbaiy
}
练习-文件拷贝
注意,这次是小文件的拷贝
public static void main(String[] args) throws IOException {
//负责原文件的读取
FileInputStream fis=new FileInputStream("D:\\我的世界\\a1.txt");
//负责copy文件的写出
FileOutputStream fos=new FileOutputStream("D:\\我的世界\\copy.txt");
int b;//记录读取内容
//边读边写
while ((b=fis.read())!=-1){
fos.write(b);
}
fos.close();
fis.close();
}

public static void main(String[] args) throws IOException {
//负责原文件的读取
FileInputStream fis=new FileInputStream("D:\\我的世界\\页面返回顶部.mp4");
//负责copy文件的写出
FileOutputStream fos=new FileOutputStream("D:\\我的世界\\copy.mp4");
int b;//记录读取内容
//边读边写
long l1 = System.currentTimeMillis();
while ((b=fis.read())!=-1){
fos.write(b);
}
fos.close();
fis.close();
long l2=System.currentTimeMillis();
System.out.println(l2-l1);
}
- 问题:如果拷贝文件过大,上述方法拷贝的速度就会很慢
原因:一次只读一个字节
字节输入流一次读取多个字节
| 方法名 | 说明 |
|---|---|
| public int read() | 一次读取一个字节数据 |
| public int read(byte[ ] buffer) | 一次读取一个字节数组数据 |
注意:一次读取一个字节数组的数据,每次读取会尽可能把数组装满
所以,在创建字节数组时,一般会用1024的整数倍
1024 * 1024 * 5就是5M
- public int read(byte[ ] buffer)方法演示
public static void main(String[] args) throws IOException {
//a1.txt:abcde
FileInputStream fis=new FileInputStream("D:\\我的世界\\a1.txt");
byte[] arr=new byte[2];//长度为2的数组,用read读取时一次可以读取两个
//读取的返回值:本次读取到了多少个字节数据
int read = fis.read(arr);
System.out.println(read);
//而且,read用数组读取会把本次读取到的数据放到数组中
String str=new String(arr);
System.out.println(str);
//2
//ab
fis.close();
//第二次读取便会依次向后读取两个数据,跟read没有参数时一样
//结果是
//2
//cd
//第三次读取的结果是
//1
//ed,因为第三次读取的时候只剩一个数据未读取,
//而read方法在读取时会把数据放到数组中,每次读取都会覆盖原本的数据
//所以第三次读取时只读取一个,也就只覆盖一个数据,第二个没有覆盖
//也就是 ed
}
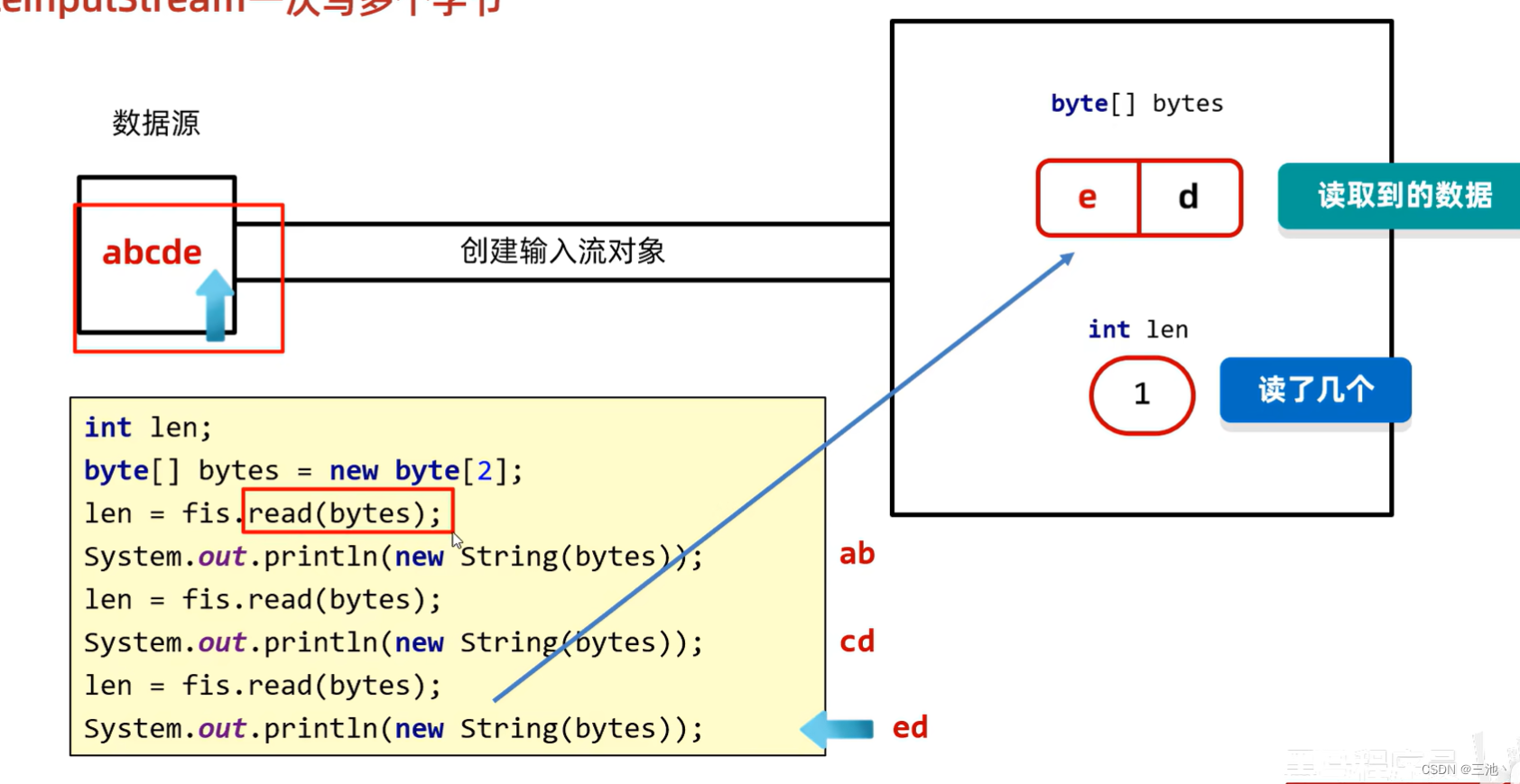
e覆盖掉c,后面没有数据,所以d没有被覆盖
解决方案:
使用new String时,传递三个参数,第一个表示数组,第二个表示起始索引,第三个表示结束索引,然后会起始索引截取到结束索引
new String(arr,0,len)
- 改进
public static void main(String[] args) throws IOException {
//a1.txt:abcde
FileInputStream fis=new FileInputStream("D:\\我的世界\\a1.txt");
byte[] arr=new byte[2];//长度为2的数组,用read读取时一次可以读取两个
//读取的返回值:本次读取到了多少个字节数据
int read1 = fis.read(arr);
System.out.println(read1);
//而且,read用数组读取会把本次读取到的数据放到数组中
String str1=new String(arr,0,read1);
System.out.println(str1);
//2
//ab
//第二次读取便会依次向后读取两个数据,跟read没有参数时一样
int read2 = fis.read(arr);
System.out.println(read2);
String str2=new String(arr,0,read2);
System.out.println(str2);
//结果是
//2
//cd
//第三次读取的结果是
int read3 = fis.read(arr);
System.out.println(read3);
String str3=new String(arr,0,read3);
System.out.println(str3);
//1
//ed,因为第三次读取的时候只剩一个数据未读取,
//而read方法在读取时会把数据放到数组中,每次读取都会覆盖原本的数据
//所以第三次读取时只读取一个,也就只覆盖一个数据,第二个没有覆盖
//也就是 ed
fis.close();
}
- 文件拷贝改写
public static void main(String[] args) throws IOException {
//负责原文件的读取
FileInputStream fis=new FileInputStream("D:\\我的世界\\页面返回顶部.mp4");
//负责copy文件的写出
FileOutputStream fos=new FileOutputStream("D:\\我的世界\\copy.mp4");
int b;//记录读取长度
//边读边写
long l1 = System.currentTimeMillis();
byte[]arr=new byte[1024*1024];
while ((b=fis.read(arr))!=-1){//此时每一次读取的数据在数组中
fos.write(arr,0,b);//这里最后一次读取可以装不满数组,
// 所以要用三个参数,表示上面有多少,就写入多少
}
fos.close();
fis.close();
long l2=System.currentTimeMillis();
System.out.println(l2-l1);
}
io流中不同JDK版本捕获异常的方式(了解)
捕获异常的新格式:
try{
语句..
}catch{
语句..
}finally{
语句..(这里的代码一定会执行,除非虚拟机停止)
}
finally的特点:finally的代码一定被执行,除非虚拟机停止
比如说:
try里的代码没有异常,那么try执行后就会执行finally的代码,但是try里出现了异常,try停止执行,catch执行后,finally里的代码执行
这样可以使io流一定能够释放资源
异常在以后的开发中都是抛出处理的
public static void main(String[] args) {
FileInputStream fis=null;
FileOutputStream fos=null;
try {
//负责原文件的读取
fis=new FileInputStream("D:\\我的世界\\页面返回顶部.mp4");
//负责copy文件的写出
fos=new FileOutputStream("D:\\我的世界\\copy.mp4");
int b;//记录读取内容
//边读边写
byte[]arr=new byte[1024*1024];
while ((b=fis.read(arr))!=-1){//此时每一次读取的数据在数组中
fos.write(arr,0,b);//这里最后一次读取可以装不满数组,
// 所以要用三个参数,表示上面都多少,就写入多少
}
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
//由于fos和fis都是try大括号里的局部变量,
//所以fos和fis的定义要放在try的外面
if(fos!=null){
try {
fos.close();//这里的close还是有异常,用try catch包裹
} catch (IOException e) {
throw new RuntimeException(e);
}
}
if (fis!=null) {
try {
fis.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}
-
上述代码的简化方案
在jdk7的时候,java提出了一个接口,AutoCloseable,只要实现这个接口,在特定情况下,可以自动释放资源 -
jdk7的方案
try(创建流对象1;创建流对象2){//只有实现AutoCloseable接口的类才能这样写
可能出现的异常代码;
}catch(异常类名 变量名){
异常的处理代码;
}
当catch执行完毕后,小括号里的流就会自动释放资源
- jdk9的方案
创建流对象1;
创建流对象2;
try(流1;流2){
可能出现的异常代码;
}catch(异常类名 变量名){
异常的处理代码;
}
例子:
//jdk7
public static void main(String[] args) {
try (FileInputStream fis=new FileInputStream("D:\\我的世界\\页面返回顶部.mp4");
FileOutputStream fos=new FileOutputStream("D:\\我的世界\\copy.mp4")){
int b;//记录读取内容
//边读边写
byte[]arr=new byte[1024*1024];
while ((b=fis.read(arr))!=-1){//此时每一次读取的数据在数组中
fos.write(arr,0,b);//这里最后一次读取可以装不满数组,
// 所以要用三个参数,表示上面都多少,就写入多少
}
} catch (IOException e) {
e.printStackTrace();
}
}
//jdk9
public static void main(String[] args) throws FileNotFoundException {
FileOutputStream fos=new FileOutputStream("D:\\我的世界\\copy.mp4");
FileInputStream fis=new FileInputStream("D:\\我的世界\\页面返回顶部.mp4");
try (fis;fos){
int b;//记录读取内容
//边读边写
byte[]arr=new byte[1024*1024];
while ((b=fis.read(arr))!=-1){//此时每一次读取的数据在数组中
fos.write(arr,0,b);//这里最后一次读取可以装不满数组,
// 所以要用三个参数,表示上面都多少,就写入多少
}
} catch (IOException e) {
e.printStackTrace();
}
}
字符集详解
字节流读取中文会出现乱码
- 计算机的存储规则
在计算机中,任意数据都是以二进制的形式存储的
计算机在存储英文时,一个字节就可以存储
ASCII字符集
0-127,一共128个字符
例如,存英文a时,先查询对应的ASCII表,得到对应值,然后转化为数字
a->97->110 0001,在前面加一个0就是八位二进制,就代表一个字节(这步是编码)
0110 0001,然后存这个二进制值存进电脑

ASCII的解码规则:
直接把二进制数转成10进制

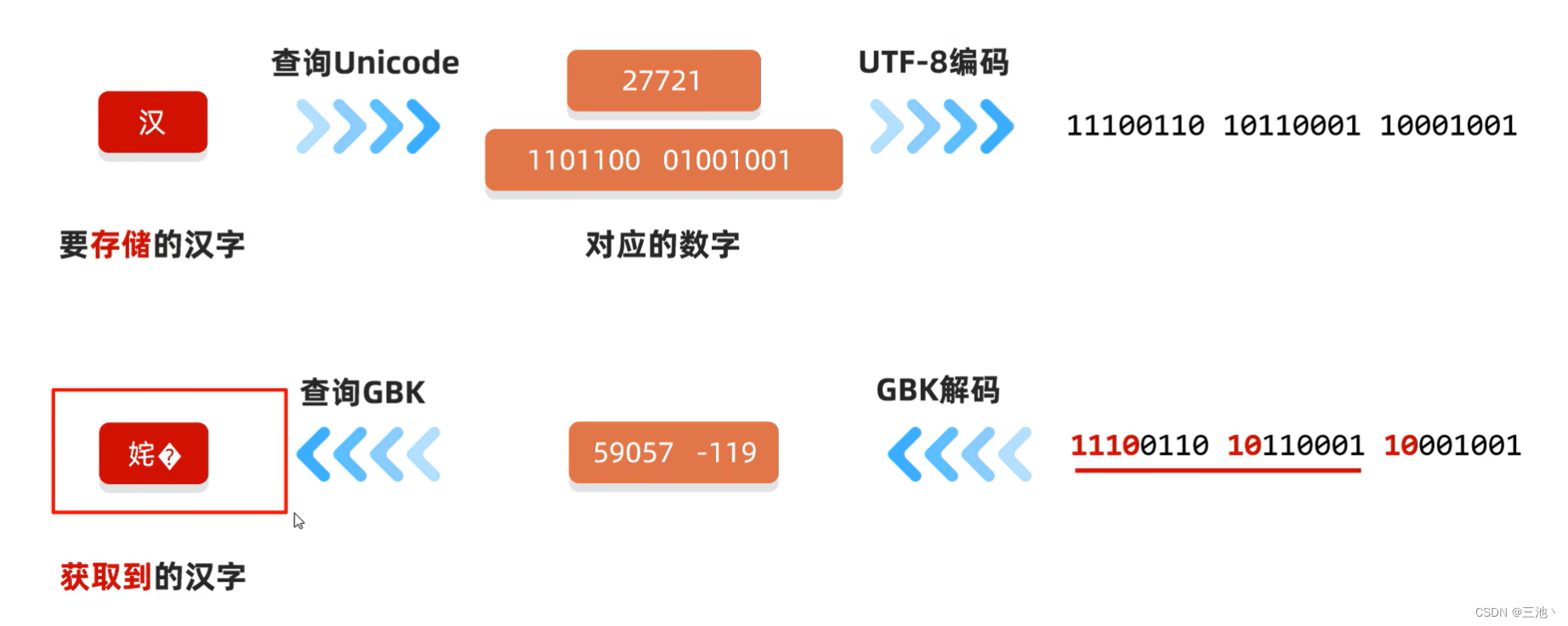
GBK字符集

系统显示为ANSI
如果查询英文,可以直接按照ASCII来查,因为GBK完全兼容ASCII
-
汉字的存储
在编码的时候,二进制不需要添加改动,直接存到计算机中一个汉字用两个字节存储
第一个字节为高位字节,第二个字节为低位字节高位字节二进制一定以1开头,转成10进制后是一个负数
-
汉字的读取
跟ASCII一样,直接转成10进制,然后再转成汉字

-
小结

Unicode
Unicode:万国码

-
英文的存储方式(Unicode)
也是先将字母(例如a)转换成对应的数字(97,Unicode也是兼容ASCII的),然后进行编码,但是,Unicode编码时有很多种方式1.UTF-16编码规则:用2-4个字节保存
上述的a->97->00000000 01100001(UTF-16)2.UTF-32编码规则:固定用4个字节保存
a->00000000 00000000 00000000 011000013.UTF-8编码规则:用1-4个字节保存(最常见)
在UTF-8中,ASCII里的统一用1个字节保存,简体中文统一用三个字节保存,且中文第一个字节的首位是1
即ASCII编码时前面加0,简体中文字节前加1110 10 10,剩余的x都是用Unicode中查询到的二进制进行填补


-
小结

为什么会有乱码?
- 原因:
1.读取数据时未读完整个汉字
2.编码和解码的方式不统一
原因1:因为字节流一次只能读取一个字节,而一个中文由三个字节组成,所以读取时会产生乱码
原因2:比如说,在编码时用Unicode,但在解码时可能用的是GBK
-
如何不产生乱码
1.不用字节流读取文本文件
2.编码解码时使用同一个编码表,同一个编码方式 -
扩展

拷贝时,数据没有丢失,与原数据一样,然后记事本本身在读取文件时使用的字符集和编码方式与原数据一致,所以不会出现乱码
Java中编码和解码的代码实现
- Java中编码的方法
| 方法名 | 说明 |
|---|---|
| public byte[ ] getBytes() | 使用默认方式进行编码(ieda默认用UTF-8,eclipse默认使用gbk) |
| public byte[ ] getBytes(String charseName) | 使用指定方式进行编码 |
- Java中解码的方法
| 方法名 | 说明 |
|---|---|
| String(byte[ ] bytes) | 使用默认方式进行解码 |
| String(byte[ ] bytes,String charseName) | 使用指定方式进行解码 |
public static void main(String[] args) throws UnsupportedEncodingException {
//编码
String str="ox欧肖";
//默认方式
byte[] bytes1 = str.getBytes();
//指定方式
byte[] bytes2 = str.getBytes("GBK");
System.out.println(Arrays.toString(bytes1));
System.out.println(Arrays.toString(bytes2));
//[111, 120, -26, -84, -89, -24, -126, -106]
//[111, 120, -59, -73, -48, -92]
//解码
//默认方式解码
String str2=new String(bytes1);
//使用指定方式解码,如果编码与解码不同,就会出现乱码
String str3=new String(bytes1,"GBK");
String str4=new String(bytes2,"GBK");
System.out.println(str2);
System.out.println(str3);
System.out.println(str4);
//ox欧肖
//ox娆ц倴
//ox欧肖
}
字符流
字符流的底层就是字节流
字符流=字节流+字符集
- 特点:
输入流:一次读一个字节,遇到中文时,一次读多个字节(这里读取多个字节的个数跟字符流里的字符集有关)
输出流:底层会把底层的数据按照指定的方式编码,变成字节再写到文件中
字符流使用场景:对于纯文本文件进行读写操作
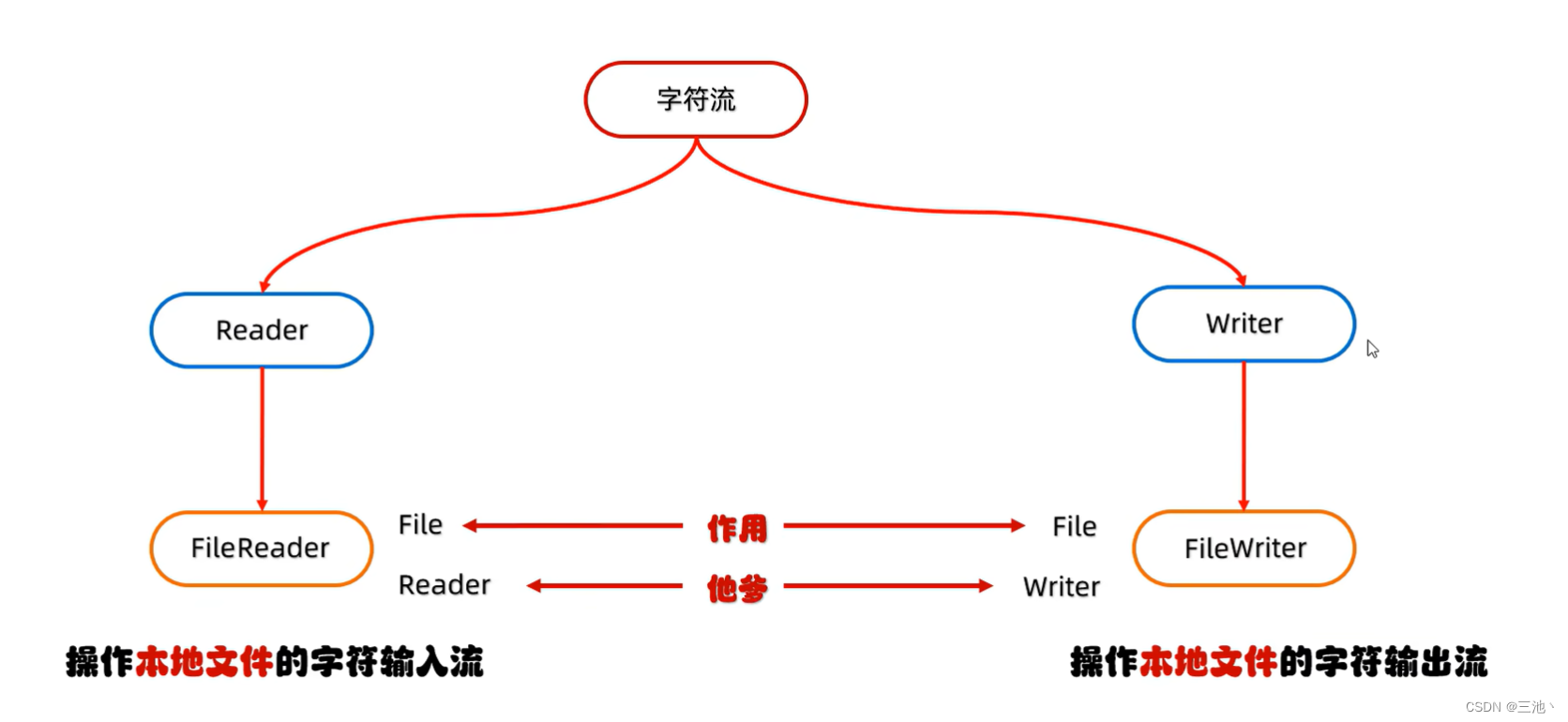
FileReader(字符输入流)
- 三步:
1.创建字符输入流对象(构造方法)
| 方法名 | 说明 |
|---|---|
| public FileReader(File file) | 创建字符输入流关联本地文件 |
| public FileReader(String pathname) | 创建字符输入流关联本地文件 |
注意:读取的文件不存在会直接报错
2.读取数据(成员方法)
| 方法名 | 说明 |
|---|---|
| public int read() | 读取数据,读到末尾返回-1 |
| public int read(char[ ] buffer) | 读取多个数据,读到末尾返回-1 |
注意:
1.按字节进行读取,遇到中文,一次读多个字节,读取后编码,返回一个整数
2. 读到文件末尾了,read方法返回-1
3.释放资源
还是close方法
public static void main(String[] args) throws IOException {
//空参的read方法
File file=new File("D:\\我的世界\\a1.txt");
FileReader reader1=new FileReader(file);//file对象的形式传递
FileReader reader2=new FileReader("D:\\我的世界\\a1.txt");//字符串的形式传递
int ch ;
//字符流的read方法也是一个一个的读取字节,遇到中文一次读取多个
//在底层会进行解码把读取到的数据转成10进制并且返回
//这个返回的数据就是字符集上对应的10进制数字
//如果想看到中文就用(char)强转就行了
while ((ch=reader1.read())!=-1){
System.out.print((char)ch);
}
reader1.close();
//殷勤昨夜三更雨,又得浮生一日凉。——《鹧鸪天·林断山明竹隐墙》
//带参的read方法 read(char[] buffer)
//带参的read方法将读取数据,解码,强转数据进行合并
//将强转得到的字符都放到数组中
//带参的返回值还是读取的元素个数
char[]arr=new char[2];//表示一次读取两个数据
int len;//表示当前读到了第几个
while((len=reader2.read(arr))!=-1){
//这里的new String可以把数组里的元素转成字符串
//第二个参数是要开始转化的起始索引,第三个参数就是终止索引
System.out.print(new String(arr,0,len));
}
//殷勤昨夜三更雨,又得浮生一日凉。——《鹧鸪天·林断山明竹隐墙》
}
FileWriter(字符输出流)
- 创建字符输出流对象(构造方法)
| 方法名 | 说明 |
|---|---|
| public FileWriter(File file) | 创建字符输出流关联本地文件 |
| public FileWriter(String pathname) | 创建字符输出流关联本地文件 |
| public FileWriter(File file,boolen append) | 创建字符输出流关联本地文件,续写 |
| public FileWriter(String pathname,boolen append) | 创建字符输出流关联本地文件,续写 |
前两种方式是默认关闭续写的,即如果在创建对象时文件内存在数据,会先清空文件内的数据再写,
后面的方式可以打开续写开关,true就是打开续写开关
- 写出数据(成员方法)
| 方法名 | 说明 |
|---|---|
| void write(int c) | 写出一个字符 |
| void | 写出一个字符串 |
| void write(String str,int off,int len) | 写出一个字符串的一部分 |
| void write(char[ ] cbuf) | 写出一个字符数组 |
| void write(char[ ] cbuf,int off,int len) | 写出字符数组的一部分 |
注意:

public static void main(String[] args) throws IOException {
//参数为true,表示打开续写,默认为false,即关闭续写
//殷勤昨夜三更雨,又得浮生一日凉。——《鹧鸪天·林断山明竹隐墙》是a1.txt文件的内容
FileWriter f1=new FileWriter("D:\\我的世界\\a1.txt",true);
FileWriter f2=new FileWriter(new File("D:\\我的世界\\a1.txt"),true);
//write(int c)
//注意字节输出流和字符输出流的区别
//字节输出流一次只能写入一个字节
//字符输出流一次可以写入多个字节
//写入到文件里的是字符集上对应的整数
f1.write(25105);//这里是汉字 我 ,在Unicode中三个字节,所以在字节输出流中写不了
//write(String str)
f1.write("\r\n何日功成名遂了,还乡,醉笑陪公三万场。");
//write(String str,int off,int len)
f1.write("\r\n何日功成名遂了,还乡,醉笑陪公三万场。",0,9);
//write(char[ ] cbuf)
char []chars={'\r','\n','1','2','3','4','5'};
f1.write(chars);
//write(char[ ] cbuf,int off,int len)
f1.write(chars,0,5);
f1.close();
//殷勤昨夜三更雨,又得浮生一日凉。——《鹧鸪天·林断山明竹隐墙》我//
//何日功成名遂了,还乡,醉笑陪公三万场。
//何日功成名遂了
//12345
//123
}
字符输入流原理解析
字符流读取数据时
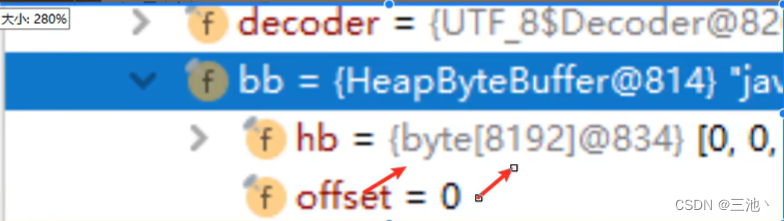
数据源和内存先建立流通道,然后内存里会创建一个长度为8192的缓冲区

开始读取时,read方法会先从缓冲区寻找数据,会先判断缓冲区是否有数据,如果缓冲区没有数据,就从文件中读取数据,尽可能装满缓冲区,如果有数据,就直接从缓冲区读取数据,如果文件中也没有数据,就会返回-1
- 小结

这个bb就是缓冲区
- 扩展
当数据超过8192也就是超过缓冲区的长度后,在读取超过的这部分数据时会把新数据存入缓冲区开头
读取的数据存入缓冲区后,如果下面用FileWriter清空文件,那么再次读取时只能读取到缓冲区的数据,未存入缓冲区的数据不能再读取
字符输出流底层原理
字符流写出数据时
数据源和内存先建立流通道,然后内存里会创建一个长度为8192的缓冲区
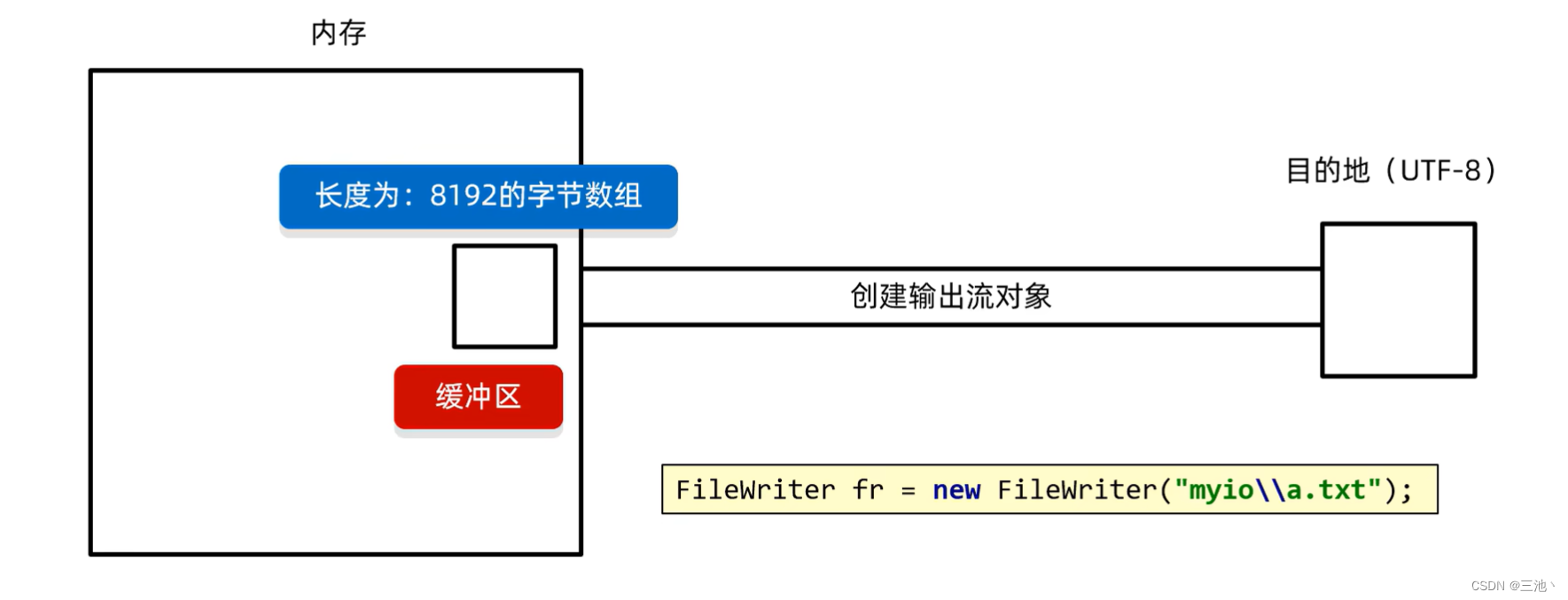
有两种方式可以让缓冲区的数据存储到目的地
1.缓冲区装满了
2.手动刷新(flush)
3.close方法
flush刷新完成后,还可以继续往文件中写入数据


字节流和字符流的使用场景
字节流:可以拷贝任意类型的文件
字符流:读取纯文本文件中的数据,往纯文本文件中写出数据
综合练习

public static void main(String[] args) throws IOException {
File fu=new File("D:\\我的世界\\three");
File f1=new File("D:\\我的世界\\one");
CopyFolder(fu,f1);
}
public static void CopyFolder(File copyFile,File file) throws IOException {
if(file.isDirectory()){
File[] files = file.listFiles();
for (File file1 : files) {
if(file1.isFile()){
//文件的copy
String name = file1.getName();
File newFile=new File(copyFile,name);
FileOutputStream fos=new FileOutputStream(newFile);
FileInputStream fis=new FileInputStream(file1);
byte[]bytes=new byte[1024*1024];
int len;
while ((len=fis.read(bytes))!=-1){
fos.write(bytes,0,len);
}
fis.close();
fos.close();
} else{
String name = file1.getName();
File newFile=new File(copyFile,name);
newFile.mkdirs();
//子文件夹的copy
CopyFolder(newFile,file1);
}
}
}
}

异或^计算符,两边相同为false,两边不同为true
一个数异或另外一个数两次,这个数还会变为原来的数
例如:
sout(false^false);//false
sout(true^true);//false
sout(false^true);//true
sout(true^false);//true
sout(100^10)//110
sout(100^10)//100
在加密的时候可以拿着字节数据去异或一个数字,解密的时候再异或回来
public static void main(String[] args) throws IOException {
File file=new File("D:\\我的世界\\a1.txt");
File file1=new File("D:\\我的世界\\a4.txt");
decrypt(file,file1);
}
public static void encrypt(File file,File file1) throws IOException {
if(file.isFile()){
FileInputStream fis=new FileInputStream(file);
FileOutputStream fos=new FileOutputStream(file1);
int b;
while ((b=fis.read())!=-1){
fos.write(b^2);
}
fos.close();
fis.close();
}
}
public static void decrypt(File file,File file1) throws IOException {
if(file.isFile()){
FileInputStream fis=new FileInputStream(file1);
FileOutputStream fos=new FileOutputStream(file);
int b;
while ((b=fis.read())!=-1){
fos.write(b^2);
}
fos.close();
fis.close();
}
}

第一种解法:
public static void main(String[] args) throws IOException {
//读取数据
FileReader fdr=new FileReader("D:\\我的世界\\b1.txt");
StringBuilder sb=new StringBuilder();
int ch;
while ((ch=fdr.read())!=-1){
sb.append((char)ch);
}
fdr.close();
System.out.println(sb);
//排序
String str=sb.toString();
String[] split = str.split("-");
ArrayList<Integer>list=new ArrayList<>();
for (int i = 0; i < split.length; i++) {
list.add(Integer.parseInt(split[i]));
}
Collections.sort(list);
//写出
FileWriter fw=new FileWriter("D:\\我的世界\\b1.txt");
for (int i = 0; i < list.size(); i++) {
if(i==list.size()-1){
fw.write(list.get(i)+"");
}else{
fw.write(list.get(i)+"-");
}
}
fw.close();
}
第二种解法:
public static void main(String[] args) throws IOException {
//读取数据
FileReader fdr=new FileReader("D:\\我的世界\\b1.txt");
StringBuilder sb=new StringBuilder();
int ch;
while ((ch=fdr.read())!=-1){
sb.append((char)ch);
}
fdr.close();
System.out.println(sb);
//排序
String[] arr = sb.toString().split("-");
Integer[] array = Arrays.stream(arr).map(new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return Integer.parseInt(s);
}
}).sorted().toArray(new IntFunction<Integer[]>() {
@Override
public Integer[] apply(int value) {
return new Integer[value];
}
});
//写出
FileWriter fw=new FileWriter("D:\\我的世界\\b1.txt");
String s=Arrays.toString(array).replace(",","-");
String result=s.substring(1,s.length()-1);
fw.write(result);
fw.close();
}
高级流
所谓高级流,就是把基本流做了一个封装,额外添加了一些功能

缓冲流
缓冲流可以提高读写的效率
缓冲流的体系结构
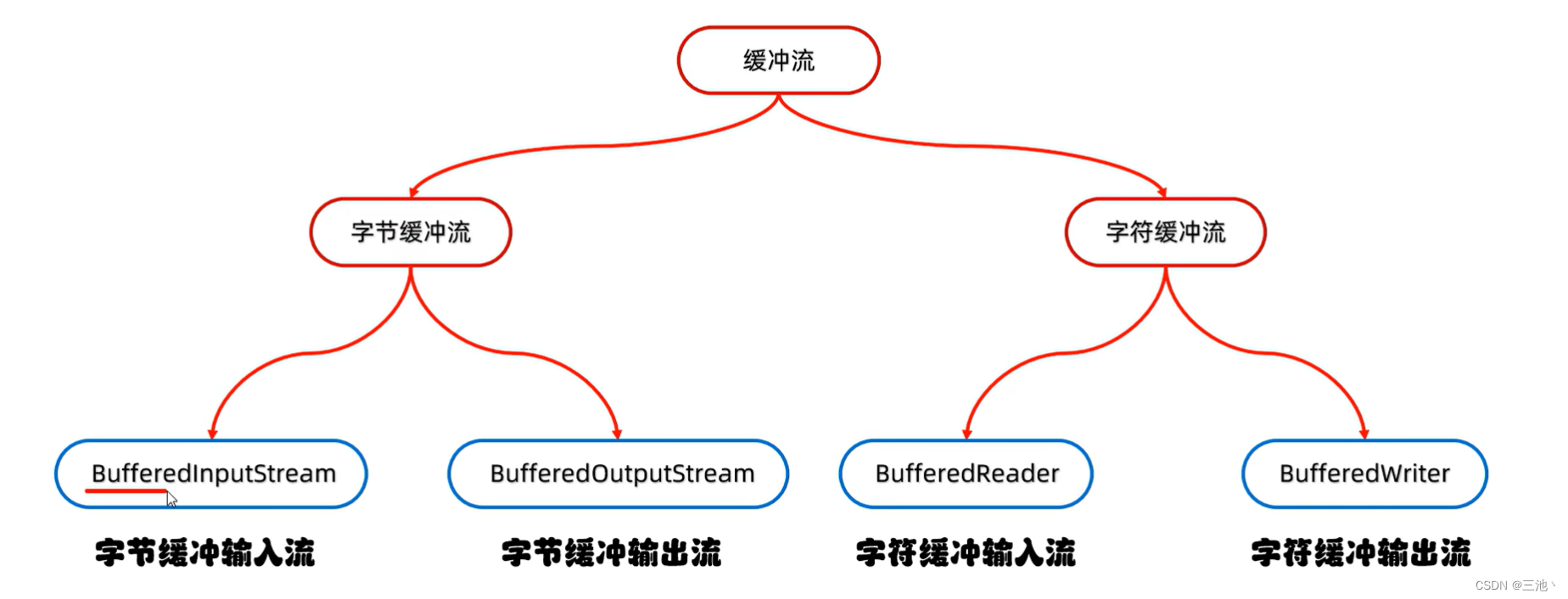
上面的Buffered就表示缓冲区
字节缓冲流
除了构造方法(创建对象的时候)有所不同其他的使用基本都类似
提高效率的原理:
底层自带了长度8192的缓冲区提高性能
- 缓冲流的创建
| 方法名 | 说明 |
|---|---|
| public BufferedInputStream(InputStream is) | 把基本流包装成高级流,提高读取数据性能 |
| public BufferedOutputStream(OutputStream os) | 把基本流包装成高级流,提高读取数据性能 |
在底层,真正读写数据的还是缓冲流包装的基本流
- 练习

- 一次读取一个字节
public static void main(String[] args) throws IOException {
//这里创建缓冲流对象后,使用的时候与基本流是一样的,
BufferedInputStream bis=new BufferedInputStream(new FileInputStream("D:\\我的世界\\a1.txt"));
BufferedOutputStream bos=new BufferedOutputStream(new FileOutputStream("D:\\我的世界\\copy.txt"));
int b;
while((b=bis.read())!=-1){
bos.write(b);
}
//这里释放资源时不用关闭基本流,直接关闭缓冲流就行
//缓冲流关闭的时候会把基本流关上
bos.close();
bis.close();
}
- 一次读取一个数组
public static void main(String[] args) throws IOException {
//这里创建缓冲流对象后,使用的时候与基本流是一样的,
BufferedInputStream bis=new BufferedInputStream(new FileInputStream("D:\\我的世界\\a1.txt"));
BufferedOutputStream bos=new BufferedOutputStream(new FileOutputStream("D:\\我的世界\\copy1.txt"));
byte[]bytes=new byte[1024];
int len;
while((len=bis.read(bytes))!=-1){
bos.write(bytes,0,len);
}
//这里释放资源时不用关闭基本流,直接关闭缓冲流就行
//缓冲流关闭的时候会把基本流关上
bos.close();
bis.close();
}
字节缓冲流的基本原理
创建缓冲流后,在实际写入与读取时还是用的基本流,只是数据在内存的的过程中用到了缓冲流
每一个缓冲流对象都会创建一个缓冲区
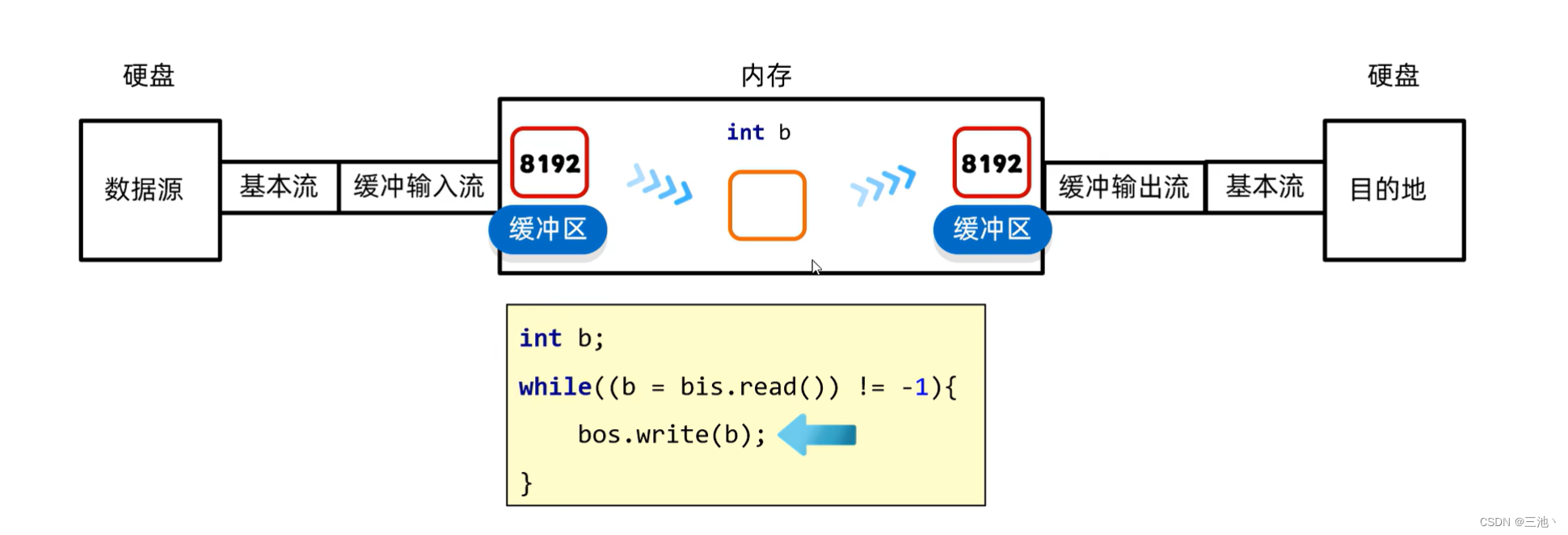
整体过程就是:
首先基本流读取数据,一次性读8192个数据,把读取到的数据放到缓冲区当中,而中间的变量就是一个中转站,把数据从缓冲输入流的缓冲区转移到缓冲输出流的缓冲区
,当右边的缓冲区填满了,就会利用基本流自动的写出数据,当变量在缓冲输入流的缓冲区读不到数据了,这时基本流又会读取8192个数据,然后循环,直到文件读取完毕。
由于数据从硬盘到硬盘转移到内存中去,所以效率提高
如果中间变量是数组,原理也类似,只不过中间变量变成了数组
字符缓冲流
提高效率的原理:
底层自带了长度8192的缓冲区提高性能
- 字符缓冲流的创建(构造方法)
| 方法名 | 说明 |
|---|---|
| public BufferedReader(Reader r) | 把基本流变成高级流 |
| public BufferedWriter(Writer w) | 把基本流变成高级流 |
字符缓冲输入流特有的方法
| 方法名 | 说明 |
|---|---|
| public String readLine() | 读取一行数据,如果没有数据可读了,会返回null |
字符缓冲输出流特有的方法
| 方法名 | 说明 |
|---|---|
| public String newLine() | 跨平台的换行 |
之前写换行是\r\n但是这不合理,因为只有在window中是\r\n,在Mac中是\r,在Linux中是\n
所以| public String newLine() | 跨平台的换行 |是一个很有用的方法,方法的底层会先判断程序运行的是什么操作系统,然后给出相应的值来换行
- readLine
public static void main(String[] args) throws IOException {
BufferedReader br=new BufferedReader(new FileReader("D:\\我的世界\\a1.txt"));
//一次读取一行,与read一样,再次读取会读取下一行
//readLine遇到回车换行结束,但是不会把回车和换行读到内存中
// String s1 = br.readLine();
// System.out.println(s1);
//
// String s2 = br.readLine();
// System.out.println(s2);
//殷勤昨夜三更雨,又得浮生一日凉。——《鹧鸪天·林断山明竹隐墙》我
//何日功成名遂了,还乡,醉笑陪公三万场。
//一次读取所有数据
String line;
while((line=br.readLine())!=null){
System.out.println(line);
}
//殷勤昨夜三更雨,又得浮生一日凉。——《鹧鸪天·林断山明竹隐墙》我
//何日功成名遂了,还乡,醉笑陪公三万场。
//何日功成名遂了
//12345
//123
br.close();
}
- newLine
public static void main(String[] args) throws IOException {
//这里write的续写要在基本流里打开
BufferedWriter bw=new BufferedWriter(new FileWriter("D:\\我的世界\\b2.txt",true));
String s1="画堂人静雨蒙蒙,屏山半掩余香袅。";
bw.write(s1);
bw.newLine();
String s2 = "——寇准《踏莎行·春暮》";
bw.write(s2);
bw.newLine();
bw.close();
//画堂人静雨蒙蒙,屏山半掩余香袅。
//——寇准《踏莎行·春暮》
}
小结

综合练习

public static void main(String[] args) throws IOException {
//基本流
FileInputStream fis=new FileInputStream("D:\\我的世界\\UnitySetup64-2020.3.47f1c1.exe");
FileOutputStream fos1=new FileOutputStream("D:\\我的世界\\copy1.txt");
FileOutputStream fos2=new FileOutputStream("D:\\我的世界\\copy2.exe");
long l1 = System.currentTimeMillis();
int b1;
while((b1=fis.read())!=-1){
fos1.write(b1);
}
long l2 =System.currentTimeMillis();
System.out.println(l2-l1);
byte[]bytes1=new byte[1024];
long l3 = System.currentTimeMillis();
System.out.println(l3);
int len1;
while ((len1=fis.read(bytes1))!=-1){
fos2.write(bytes1,0,len1);
}
long l4 = System.currentTimeMillis();
System.out.println(l4);
System.out.println(l4-l3);
fos2.close();
fos1.close();
fis.close();
//缓冲流
BufferedInputStream bis=new BufferedInputStream(new FileInputStream("D:\\我的世界\\a1.txt"));
BufferedOutputStream bos1=new BufferedOutputStream(new FileOutputStream("D:\\我的世界\\copy3.txt"));
BufferedOutputStream bos2=new BufferedOutputStream(new FileOutputStream("D:\\我的世界\\copy4.txt"));
long l5 = System.currentTimeMillis();
int b2;
while((b2=bis.read())!=-1){
bos1.write(b2);
}
long l6 =System.currentTimeMillis();
System.out.println(l6-l5);
byte[]bytes2=new byte[1024];
long l7 = System.currentTimeMillis();
int len2;
while ((len2=bis.read(bytes2))!=-1){
bos2.write(bytes2,0,len2);
}
long l8 = System.currentTimeMillis();
System.out.println(l8-l7);
bos2.close();
bos1.close();
bis.close();
}
这里好像不能一次运行太多流,要写成方法的形式

- 第一种写法
//由于字符流的基本流只能一个一个的读取数据,不方便,所以用字符流的缓冲流读取写入
public static void main(String[] args) throws IOException {
//读取
BufferedReader br=new BufferedReader(new FileReader("D:\\我的世界\\csb.txt"));
String s;
ArrayList<String>list=new ArrayList<>();
while ((s=br.readLine())!=null){
list.add(s);
}
//排序
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
String s1 = o1.split("\\.")[0];
int i1 = Integer.parseInt(s1);
String s2=o2.split("\\.")[0];
int i2=Integer.parseInt(s2);
return i1-i2;
}
});
//写入
br.close();
BufferedWriter bw=new BufferedWriter(new FileWriter("D:\\我的世界\\copy.txt"));
for (String s1 : list) {
bw.write(s1);
bw.newLine();
}
bw.close();
}
- 第二种写法
//将第一种写法的Arraylist改成TreeMap,可以自动根据序号排序
public static void main(String[] args) throws IOException {
//读取
BufferedReader br=new BufferedReader(new FileReader("D:\\我的世界\\csb.txt"));
String s;
TreeMap<Integer,String>list=new TreeMap<>();
while ((s=br.readLine())!=null){
String s1 = s.split("\\.")[0];
String s2 = s.split("\\.")[1];
int i = Integer.parseInt(s1);
list.put(i,s2);
}
//写入
br.close();
BufferedWriter bw=new BufferedWriter(new FileWriter("D:\\我的世界\\copy.txt"));
Set<Map.Entry<Integer, String>> entries = list.entrySet();
for (Map.Entry<Integer, String> entry : entries) {
String value = entry.getValue();
bw.write(value);
bw.newLine();
}
bw.close();
}

//这个练习的关键就是统计次数,
//所以统计次数的变量不能定义在程序中,而是定义在本地文件中
//读取本地文件获得运行次数
public static void main(String[] args) throws IOException {
BufferedReader br=new BufferedReader(new FileReader("D:\\我的世界\\count.txt"));
String s = br.readLine();
int count = Integer.parseInt(s);
count++;
BufferedWriter bw=new BufferedWriter(new FileWriter("D:\\我的世界\\count.txt"));
bw.write(count+"");//注意,这里写字符串的原因是:
// 如果直接写入数字,在写入时会变成数字在字符集中对应的字符,所以写入字符串
if(count<=3){
System.out.println("第"+count+"次使用免费");
}else{
System.out.println("开始收费喽!");
}
bw.close();
br.close();
}
使用IO流的原则:什么时候用就什么时候创建,什么时候不用就什么时候关闭
转换流
属于字符流的一种高级流

转换流是字符流和字节流之间的桥梁
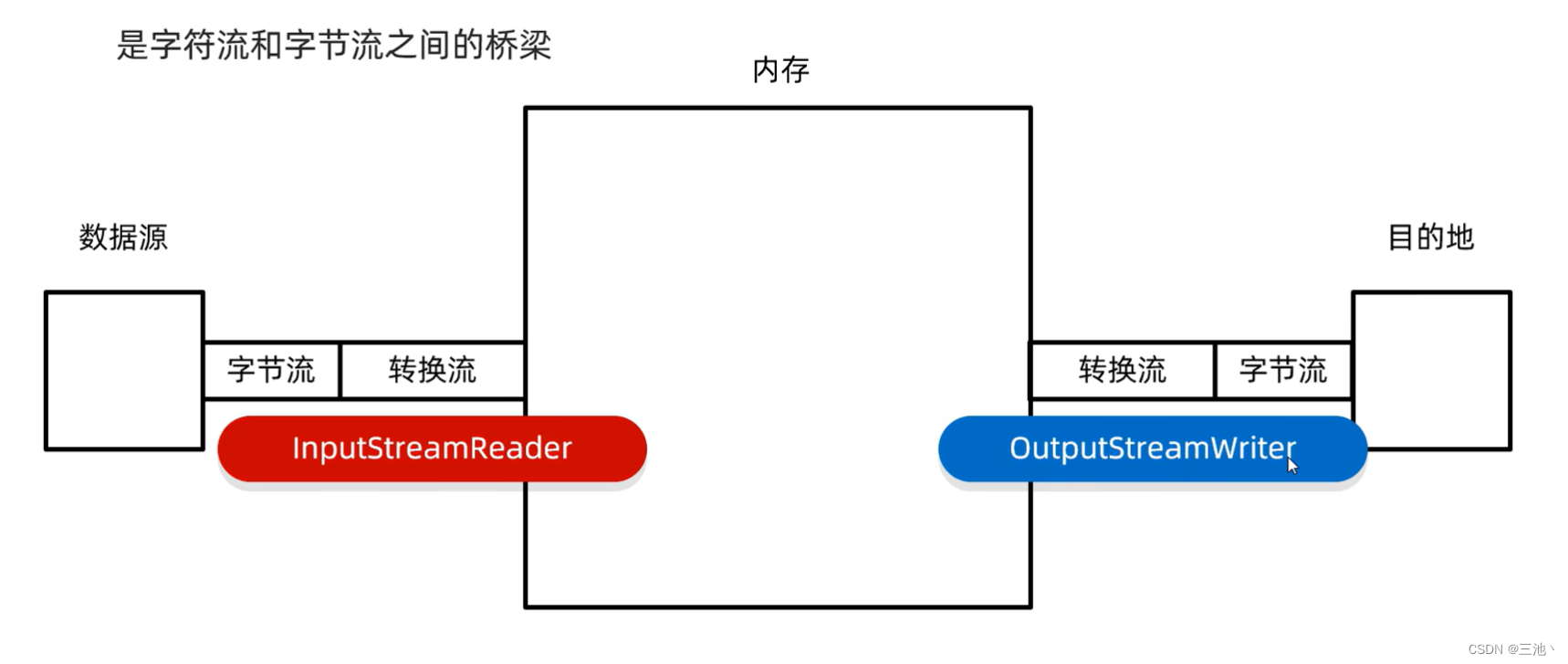
通过转换输入流(InputStreamReader)把字节流转换成字符流,这样就可以在转换的过程中让字节流有字符流的特性
写出时,再通过转换输出流(OutputStreamWriter)把字符流转成字节流,存储到文件中
转换流的应用场景:
作用1:指定字符集读写数据(在jdk11后被淘汰)
作用2:字节流想要使用字符流的方法
练习:

| 方法名 | 说明 |
|---|---|
| public InputStreamReader(InputStream is) | 把字节流转成字符流 |
| public InputStreamReader(InputStream is,String charseName) | 把字节流包装成字符流,第二个参数可以指定字符流的字符集 |
| public OutputStreamWriter(OutputStream os) | 把字符流包装成字节流 |
| public OutputStreamWriter(OutputStream os,String charseName) | 把字符流包装成字节流,第二个参数可以指定字符流的字符集,这个方法基本不用 |
public static void main(String[] args) throws IOException {
/*需求1*/
//了解,在jdk11被淘汰
// InputStreamReader isr=new InputStreamReader(new FileInputStream("D:\\我的世界\\one.txt"),"GBK");
// int b;
// while ((b=isr.read())!=-1){
// System.out.print((char)b);
// }
// isr.close();
//掌握,FileReader的构造方法参数
// FileReader fr=new FileReader("D:\\我的世界\\one.txt", Charset.forName("GBK"));
// int b;
// while ((b=fr.read())!=-1){
// System.out.print((char)b);
// }
// fr.close();
/*需求2*/
//了解,在jdk11被淘汰
// OutputStreamWriter osw=new OutputStreamWriter(new FileOutputStream("D:\\我的世界\\one.txt"),"GBK");
// String s="我好你不好";
// osw.write(s);
// osw.close();
//掌握,FileWriter的构造方法参数
// FileWriter fw=new FileWriter("D:\\我的世界\\one.txt",Charset.forName("GBK"));
// fw.write("你好你好杨");
// fw.close();
/*需求3*/
FileReader fr=new FileReader("D:\\我的世界\\one.txt", Charset.forName("GBK"));
FileWriter fw=new FileWriter("D:\\我的世界\\two.txt");
int b;
while ((b=fr.read())!=-1){
fw.write(b);
}
fw.close();
fr.close();
}
转换流练习

//先把字节流包装成字符流,再把字符流包装成高级字符流
public static void main(String[] args) throws IOException {
// //创建基本流
// FileInputStream fis=new FileInputStream("D:\\我的世界\\copy.txt");
// //把基本流转换成字符流
// InputStreamReader fsr=new InputStreamReader(fis);
// //再把刚才转换的字符流进行包装,变成缓冲流
// BufferedReader br=new BufferedReader(fsr);
// String str=br.readLine();
// System.out.println(str);
//上述代码可以写成以下形式
BufferedReader br=new BufferedReader(new InputStreamReader(new FileInputStream("D:\\我的世界\\copy.txt")));
String str=br.readLine();
System.out.println(str);
}
- 小结

序列化流
属于字节流的一种,负责输出数据,与之对应的还有一个反序列化流,用来读取数据
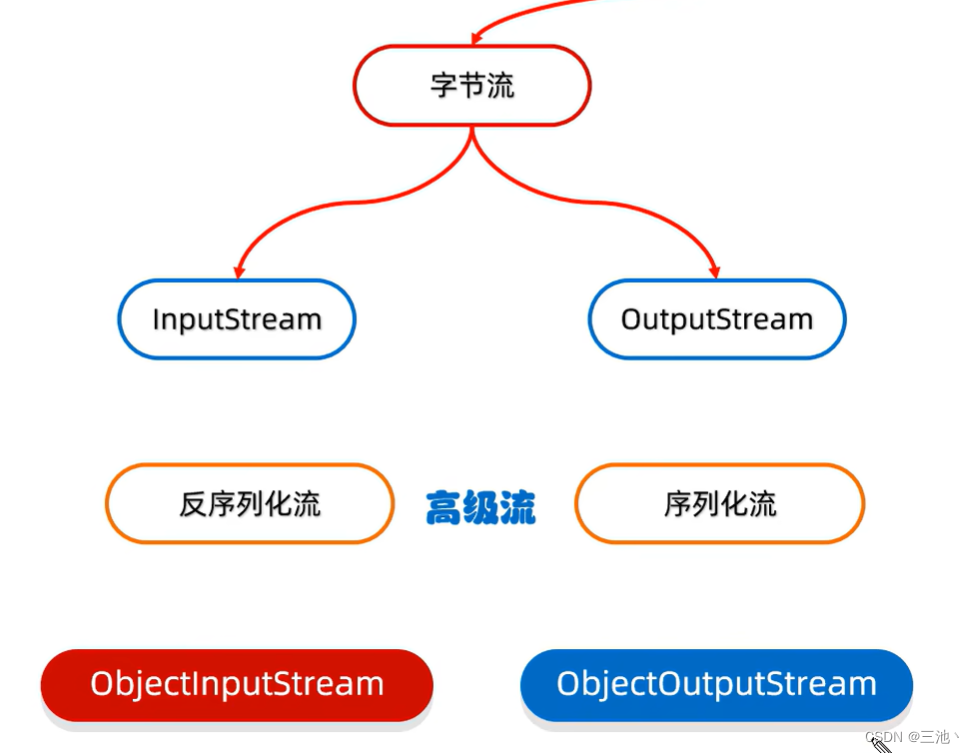
序列化流(对象操作输出流)的解析
作用:可以把Java中的对象写到本地文件中
- 构造方法(序列化流的创建):
| 方法名 | 说明 |
|---|---|
| public ObjectOutputStream(OutputStream out) | 把基本流包装成高级流 |
- 写出数据的方法
| 方法名 | 说明 |
|---|---|
| public final void writeObject (Object obj) | 把对象序列化(写出)到文件中去 |
-
序列化流的注意事项:
使用序列化流(对象输出流)将对象保存到文件时会出现NotSerializableException异常解决方案:
让Javabean类实现Serializable接口就行了Serializable接口中没有抽象方法的,这种接口叫做标记形接口,一旦实现了这个接口,就表示当前被标记的类可以被序列化
注意:序列化流写到文件中的数据是不能修改的,一旦修改就无法再次读回来了
//student类 public class student implements Serializable { 标准的javabean类 } //测试类 public static void main(String[] args) throws IOException { student stu=new student("zhangsan",16); ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream("D:\\我的世界\\one.txt")); oos.writeObject(stu); oos.close(); }
反序列化流(对象操作输入流)的解析
可以把序列化到本地的对象读取到程序中来
- 反序列化流(对象操作输入流)的构造方法
| 方法名 | 说明 |
|---|---|
| public ObjectInputStream(InputStream out) | 把基本流包装成高级流 |
- 读取数据的方法
| 方法名 | 说明 |
|---|---|
| public Object readObject () | 把序列化到本地的对象读取到程序中来 |
public static void main(String[] args) throws IOException, ClassNotFoundException {
ObjectInputStream ois=new ObjectInputStream(new FileInputStream("D:\\我的世界\\one.txt"));
Object o = ois.readObject();
System.out.println(o);
ois.close();
}
序列化流和反序列化流的细节
-
细节1
当一个
类实现了Serializable接口后(这里的类称为类1),java底层会根据这个类的所有内容生成一个long类型的版本号(号1),当创建这个类的对象时,这个对象里就会包含这个版本号,用序列化流写到文件中时,文件里也会包含类的版本号,如果此时类1的代码被修改(添加成员变量,成员方法等等),版本号就会改变(号2),再用反序列化流读取文件中的对象到程序中时就会报错,因为程序中的版本号(号2)与文件中对象的版本号(号1)不同 -
解决方案:固定版本号
可以在javabean类中固定版本号,
格式:
private static final long serialVersionUID=1L;
不用自己写,ieda会提示,然后直接alt+回车就可以自动写了 -
细节2:
如果不想让某些成员变量序列化到本地,就在成员变量前加上关键字
transient
例如:private transient int age;
transient:瞬态关键字,作用:不会把当前属性序列化到本地文件中 -
小结:

练习

规定:以后创建对象写到本地文件中时,要先把对象添加到集合中,再把集合写道本地文件中,读取时可以直接读取集合
//反序列化流
public static void main(String[] args) throws IOException {
student s1=new student("shangyang",13);
student s2=new student("shangya",23);
student s3=new student("shangy",43);
ArrayList<student>list=new ArrayList<>();
list.add(s1);
list.add(s2);
list.add(s3);
ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream("one.txt"));
oos.writeObject(list);
oos.close();
}
//序列化流
public static void main(String[] args) throws IOException, ClassNotFoundException {
ObjectInputStream ois=new ObjectInputStream(new FileInputStream("one.txt"));
ArrayList<student>list = (ArrayList<student>) ois.readObject();//这里返回值是一个对象,要转成arraylist
for (student student : list) {
System.out.println(student);
}
}
打印流
打印流不能读只能写,所以打印流只有输出流
打印流一般是指PrintStream和PrintWriter两个类
- 注意:
1.打印流只操作文件目的地,不操作数据源
2.打印流有特有的写出方法可以实现,数据可以原样写出
例如:在程序里打印97,在文件中也是97
3.特有的写出方法可以实现自动刷新,自动换行
所以,打印流打印一次数据=写出+换行+刷新
字节打印流
- 字节打印流的构造方法(创建字节打印流)
| 方法名 | 说明 |
|---|---|
| public PrintStream(OutputStream /File /String) | 关联字节输出流/文件/文件路径 |
| public PrintStream(String fileName,Charset charset) | 指定字符编码 |
| public PrintStream(OutputStream out,boolean auto autoFlash) | 自动刷新 |
| public PrintStream(OutputStream out,boolean auto autoFlash,String encoding) | 指定字符编码且自动刷新 |
字节打印流底层没有缓冲区,开不开自动刷新都一样,所以下面两个构造方法意义不大
- 字节打印流的成员方法
| 方法名 | 说明 |
|---|---|
| public void write(int b) | 常规方法,规则和之前的方法一样 |
| public void println(Xxx xx) | 特有方法:打印任意数据,自动刷新,自动换行 |
| public void print(Xxx xx) | 特有方法:打印任意数据,不换行 |
| public void printf(String format,Object… args) | 特有方法:带有占位符的打印语句,不换行 |
字节打印流底层没有缓冲区,开不开自动刷新都一样
public static void main(String[] args) throws IOException, ClassNotFoundException {
PrintStream ps=
new PrintStream
(new FileOutputStream
("D:\\我的世界\\a2.txt"),true,"UTF-8");
//这两个跟sout的输出是一样的
ps.println(97);
ps.print(true);
ps.println();
//这个是占位符的写法
//这个占位符有很多,这里就不一一细说了
ps.printf("%sone%s","two","three");
ps.close();
}
字符打印流
字符打印流有缓冲区,想要自动刷新需要开启
- 字符打印流的构造方法(创建字符打印流)
| 方法名 | 说明 |
|---|---|
| public PrintWriter(Writer /File /String) | 关联字符输出流/文件/文件路径 |
| public PrintWriter(String fileName,Charset charset) | 指定字符编码 |
| public PrintWriter(Write w,boolean auto autoFlash) | 自动刷新 |
| public PrintWriter(OutputStream out,boolean auto autoFlash,String encoding) | 指定字符编码且自动刷新 |
- 字符打印流的成员方法
| 方法名 | 说明 |
|---|---|
| public void write(int b) | 常规方法,规则和之前的方法一样 |
| public void println(Xxx xx) | 特有方法:打印任意数据,自动刷新,自动换行 |
| public void print(Xxx xx) | 特有方法:打印任意数据,不换行 |
| public void printf(String format,Object… args) | 特有方法:带有占位符的打印语句,不换行 |
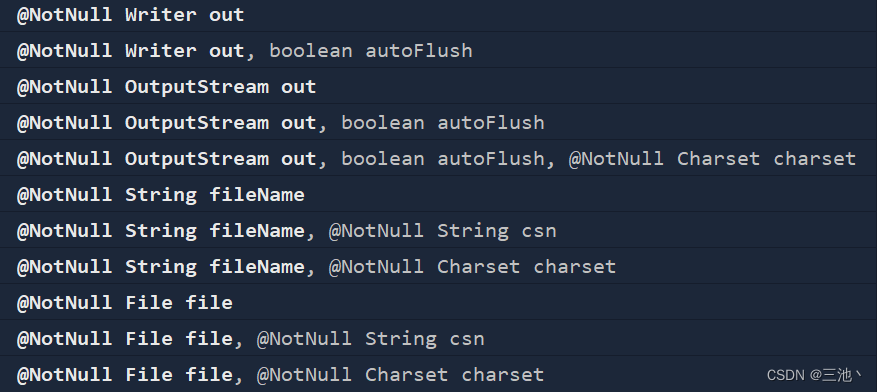
在构造方法中,能开启自动刷新的参数是比较常用的
public static void main(String[] args) throws IOException, ClassNotFoundException {
//注意,要开启自动刷新
PrintWriter pw=new PrintWriter(new FileWriter("D:\\我的世界\\a2.txt"),true);
pw.println("one");
pw.print(111);
pw.printf("%sone%s","two","three");
pw.close();
}
- 打印流的应用场景
System.out创建一个指向控制台的打印流
sout就是调用打印流的方法
这个打印流是不能关闭的,在系统中唯一存在
- 小结

解压缩流/压缩流
解压缩流就是读取压缩包中的文件
压缩流就是把文件中的数据写道压缩包中
解压缩流
压缩包里的每一个文件在java中都是一个ZipEntry对象
解压的本质就是:把每一个ZipEntry对象按照层级拷贝到本地另外一个文件夹中
ZipInputStream:zip压缩包的解压缩流,也是一个高级流
| 方法名 | 说明 |
|---|---|
| public ZipInputStream(InputStream is) | 把基本流包装成高级流 |
| 方法名 | 说明 |
|---|---|
| public Entry getNextEntry() | 获得文件夹中的文件或子文件夹 |
public static void main(String[] args) throws IOException{
File src=new File("D:\\我的世界\\three.zip");
File dest=new File("D:\\我的世界\\");
unzip(src,dest);
}
public static void unzip(File src,File dest) throws IOException {
//创建一个解压缩流用来读取压缩包中的数据
ZipInputStream zip=new ZipInputStream(new FileInputStream(src));
//中间值,用来记录获取的文件或文件夹对象
ZipEntry entry;
//getNextEntry会一个一个的遍历压缩包,直到全部遍历完成,返回null
while ((entry=zip.getNextEntry())!=null){
System.out.println(entry);
if(entry.isDirectory()){
//entry为文件夹,在目的地创建一个新的文件夹
File file=new File(dest,entry.toString());
file.mkdirs();
}else {
//entry为文件,读取压缩包中的文件,放到目的地中
File file = new File(dest, entry.toString());
FileOutputStream fos=new FileOutputStream(file);
int b;
while ((b= zip.read())!=-1){
fos.write(b);
}
fos.close();
zip.closeEntry();
}
}
zip.close();
}
压缩流
- 压缩单个文件
public static void main(String[] args) throws IOException {
//创建File对象表示要压缩的文件
File src=new File("D:\\我的世界\\a1.txt");
//创建File对象表示压缩包的位置
File dest=new File("D:\\我的世界\\");
toZip(src,dest);
}
public static void toZip(File src,File dest) throws IOException {
ZipOutputStream zos=new ZipOutputStream(new FileOutputStream(new File(dest,"a.zip")));
//创建zipEntry对象,表示压缩包中每一个文件和文件夹
ZipEntry entry=new ZipEntry("a.txt");
//把Zip对象放到压缩包中
zos.putNextEntry(entry);
FileInputStream fis=new FileInputStream(src);
int b;
while ((b=fis.read())!=-1){
zos.write(b);
}
zos.closeEntry();
zos.close();
fis.close();
}
- 压缩整个文件夹
注意:ZipEntry entry=new ZipEntry("aaa\\bbb\\a.txt");这里的参数代表压缩包里的路径,如果写压缩包里没有的路径,就会创建新的路径
public static void main(String[] args) throws IOException {
//创建File对象表示要压缩的文件
File src=new File("D:\\我的世界\\aaa");
//创建File对象表示压缩包放在哪里
File fufile=src.getParentFile();//可以得到src的父级路径
System.out.println(fufile);
//创建File对象表示压缩包的位置
File dest=new File(fufile,src.getName()+".zip");
//创建压缩流关联压缩包
ZipOutputStream zos=new ZipOutputStream(new FileOutputStream(dest));
toZip(src,zos,src.getName());
}
/*
* 函数作用:获取src的每一个文件,变成ZipEntry对象,放到压缩包中
* 参数1:数据源
* 参数2:压缩流
* 参数3:压缩包内部的路径
* */
public static void toZip(File src,ZipOutputStream zos,String name) throws IOException {
File[] files = src.listFiles();
for (File file : files) {
if(file.isFile()){
//文件,变成Entry对象,放到压缩包中
ZipEntry entry=new ZipEntry(name+"\\"+file.getName());//这里不能直接传file,因为file是绝对路径,带盘符的
//所以此时就要用到第三个参数,第三个参数代表压缩包内部的路径
zos.putNextEntry(entry);
//读取文件中的数据,写到压缩包中
FileInputStream fis=new FileInputStream(file);
int b;
while ((b=fis.read())!=-1){
zos.write(b);
}
fis.close();
zos.closeEntry();
}else {
toZip(file,zos,name+"\\"+file.getName());
}
}
}
常用工具包
Commons-io

作用:提高io流的开发效率
-
Commons-io的使用步骤
1.在项目中新建一个文件夹lib(专门存放第三方的jar包)
2.将jar包复制粘贴到文件夹中
3.右键点击jar包,选择Add as Libraby 点击ok
4.在类中导包使用 -
FileUtils类(文件/文件夹相关)
| 方法名 | 说明 |
|---|---|
| static void copyFile(File srcFile,File destFile) | 复制文件 |
| static void copyDirectory(File srcDir,File destDir) | 复制文件夹 |
| static void copyDirectoryToDirectory(File srcDir,File destDir) | 复制文件夹 |
| static void deleteDirectory(File directory) | 删除文件夹 |
| static void clearDirectory(File directory) | 清空文件夹 |
| static String readFileToString(File file,Charset encoding) | 读取文件中的数据变成字符串 |
| static void write(File file,CharSequence data,String encoding) | 写出数据 |
- IOUtils类

外部包的导入:看https://blog.csdn.net/qq_43842093/article/details/121276552这篇文章
public static void main(String[] args) throws IOException {
File src=new File("D:\\我的世界\\one");
File dest=new File("D:\\我的世界\\a2.txt");
//copyFile,拷贝文件,把参数一的文件拷贝到参数二去
// FileUtils.copyFile(src,dest);
//
// //copyDirectory, 复制文件夹,将参数1文件夹的内容复制到参数2
// FileUtils.copyDirectory(src,dest);
// //copyDirectoryToDirectory,复制文件夹,先在参数2的文件夹中创建一个以参数1为名的子文件夹
// // ,再将参数1文件夹的内容复制到参数2
// FileUtils.copyDirectoryToDirectory(src,dest);
// //deleteDirectory,删除文件夹
// FileUtils.deleteDirectory(dest);
// //clearDirectory,清空文件夹
// FileUtils.cleanDirectory(dest);
// //readFileToString,读取文件夹中的数据变成字符串
// FileUtils.readFileToString(src);
//write,写出数据
String s="殷勤昨夜三更雨,又得浮生一日凉。——《鹧鸪天·林断山明竹隐墙》\n" +
"何日功成名遂了,还乡,醉笑陪公三万场。\n" +
"画堂人静雨蒙蒙,屏山半掩余香袅。——寇准《踏莎行·春暮》\n" +
"\n";
FileUtils.write(dest,s,"UTF-8");
}
- 1,IOUtils(数据相关)
拷贝方法:
copy方法有多个重载方法,满足不同的输入输出流
IOUtils.copy(InputStream input, OutputStream output)
IOUtils.copy(InputStream input, OutputStream output, int bufferSize)//可指定缓冲区大小
IOUtils.copy(InputStream input, Writer output, String inputEncoding)//可指定输入流的编码表
IOUtils.copy(Reader input, Writer output)
IOUtils.copy(Reader input, OutputStream output, String outputEncoding)//可指定输出流的编码表
- 拷贝大文件的方法:
这个方法适合拷贝较大的数据流,比如2G以上
IOUtils.copyLarge(Reader input, Writer output) // 默认会用1024*4的buffer来读取
IOUtils.copyLarge(Reader input, Writer output, char[] buffer)//可指定缓冲区大小
- 将输入流转换成字符串
IOUtils.toString(Reader input)
IOUtils.toString(byte[] input, String encoding)
IOUtils.toString(InputStream input, Charset encoding)
IOUtils.toString(InputStream input, String encoding)
IOUtils.toString(URI uri, String encoding)
IOUtils.toString(URL url, String encoding)
- 将输入流转换成字符数组
IOUtils.toByteArray(InputStream input)
IOUtils.toByteArray(InputStream input, int size)
IOUtils.toByteArray(URI uri)
IOUtils.toByteArray(URL url)
IOUtils.toByteArray(URLConnection urlConn)
IOUtils.toByteArray(Reader input, String encoding)
- 字符串读写
IOUtils.readLines(Reader input)
IOUtils.readLines(InputStream input, Charset encoding)
IOUtils.readLines(InputStream input, String encoding)
IOUtils.writeLines(Collection<?> lines, String lineEnding, Writer writer)
IOUtils.writeLines(Collection<?> lines, String lineEnding, OutputStream output, Charset encoding)
IOUtils.writeLines(Collection<?> lines, String lineEnding, OutputStream output, String encoding)
- 从一个流中读取内容
IOUtils.read(InputStream input, byte[] buffer)
IOUtils.read(InputStream input, byte[] buffer, int offset, int length) IOUtils.read(Reader input, char[] buffer)
IOUtils.read(Reader input, char[] buffer, int offset, int length)
- 把数据写入到输出流中
IOUtils.write(byte[] data, OutputStream output)
IOUtils.write(byte[] data, Writer output, Charset encoding)
IOUtils.write(byte[] data, Writer output, String encoding)
IOUtils.write(char[] data, Writer output)
IOUtils.write(char[] data, OutputStream output, Charset encoding)
IOUtils.write(char[] data, OutputStream output, String encoding)
IOUtils.write(String data, Writer output)
IOUtils.write(CharSequence data, Writer output)
- 从一个流中读取内容,如果读取的长度不够,就会抛出异常
IOUtils.readFully(InputStream input, int length)
IOUtils.readFully(InputStream input, byte[] buffer)
IOUtils.readFully(InputStream input, byte[] buffer, int offset, int length) IOUtils.readFully(Reader input, char[] buffer)
IOUtils.readFully(Reader input, char[] buffer, int offset, int length)
- 比较
IOUtils.contentEquals(InputStream input1, InputStream input2) // 比较两个流是否相等
IOUtils.contentEquals(Reader input1, Reader input2)
IOUtils.contentEqualsIgnoreEOL(Reader input1, Reader input2) // 比较两个流,忽略换行符
- 其他方法
IOUtils.skip(InputStream input, long toSkip) // 跳过指定长度的流
IOUtils.skip(Reader input, long toSkip)
IOUtils.skipFully(InputStream input, long toSkip) // 如果忽略的长度大于现有的长度,就会抛出异常
IOUtils.skipFully(Reader input, long toSkip)
-
2,FileUtils(文件/文件夹相关)
-
复制文件夹
FileUtils.copyDirectory(File srcDir, File destDir) // 复制文件夹(文件夹里面的文件内容也会复制)
FileUtils.copyDirectory(File srcDir, File destDir, FileFilter filter) // 复制文件夹,带有文件过滤功能
FileUtils.copyDirectoryToDirectory(File srcDir, File destDir) // 以子目录的形式将文件夹复制到到另一个文件夹下
- 复制文件
FileUtils.copyFile(File srcFile, File destFile) // 复制文件
FileUtils.copyFile(File input, OutputStream output) // 复制文件到输出流
FileUtils.copyFileToDirectory(File srcFile, File destDir) // 复制文件到一个指定的目录
FileUtils.copyInputStreamToFile(InputStream source, File destination) // 把输入流里面的内容复制到指定文件
FileUtils.copyURLToFile(URL source, File destination) // 把URL 里面内容复制到文件(可以下载文件)
FileUtils.copyURLToFile(URL source, File destination, int connectionTimeout, int readTimeout)
- 把字符串写入文件
FileUtils.writeStringToFile(File file, String data, String encoding)
FileUtils.writeStringToFile(File file, String data, String encoding, boolean append)
- 把字节数组写入文件
FileUtils.writeByteArrayToFile(File file, byte[] data)
FileUtils.writeByteArrayToFile(File file, byte[] data, boolean append) FileUtils.writeByteArrayToFile(File file, byte[] data, int off, int len) FileUtils.writeByteArrayToFile(File file, byte[] data, int off, int len, boolean append)
- 把集合里面的内容写入文件
// encoding:文件编码,lineEnding:每行以什么结尾
FileUtils.writeLines(File file, Collection<?> lines)
FileUtils.writeLines(File file, Collection<?> lines, boolean append)
FileUtils.writeLines(File file, Collection<?> lines, String lineEnding)
FileUtils.writeLines(File file, Collection<?> lines, String lineEnding, boolean append)
FileUtils.writeLines(File file, String encoding, Collection<?> lines)
FileUtils.writeLines(File file, String encoding, Collection<?> lines, boolean append)
FileUtils.writeLines(File file, String encoding, Collection<?> lines, String lineEnding)
FileUtils.writeLines(File file, String encoding, Collection<?> lines, String lineEnding, boolean append)
- 往文件里面写内容
FileUtils.write(File file, CharSequence data, Charset encoding)
FileUtils.write(File file, CharSequence data, Charset encoding, boolean append)
FileUtils.write(File file, CharSequence data, String encoding)
FileUtils.write(File file, CharSequence data, String encoding, boolean append)
- 文件移动
FileUtils.moveDirectory(File srcDir, File destDir) // 文件夹在内的所有文件都将移动FileUtils.moveDirectoryToDirectory(File src, File destDir, boolean createDestDir) // 以子文件夹的形式移动到另外一个文件下
FileUtils.moveFile(File srcFile, File destFile) // 移动文件
FileUtils.moveFileToDirectory(File srcFile, File destDir, boolean createDestDir) // 以子文件的形式移动到另外一个文件夹下
FileUtils.moveToDirectory(File src, File destDir, boolean createDestDir) // 移动文件或者目录到指定的文件夹内
- 清空和删除文件夹
FileUtils.deleteDirectory(File directory) // 删除文件夹,包括文件夹和文件夹里面所有的文件
FileUtils.cleanDirectory(File directory) // 清空文件夹里面的所有的内容
FileUtils.forceDelete(File file) // 删除,会抛出异常
FileUtils.deleteQuietly(File file) // 删除,不会抛出异常
- 创建文件夹
FileUtils.forceMkdir(File directory) // 创建文件夹(可创建多级)
FileUtils.forceMkdirParent(File file) // 创建文件的父级目录
- 获取文件输入/输出流
FileUtils.openInputStream(File file)
FileUtils.openOutputStream(File file)
- 读取文件
FileUtils.readFileToByteArray(File file) // 把文件读取到字节数组
FileUtils.readFileToString(File file, Charset encoding) // 把文件读取成字符串
FileUtils.readFileToString(File file, String encoding)
FileUtils.readLines(File file, Charset encoding) // 把文件读取成字符串集合
FileUtils.readLines(File file, String encoding)
- 测试两个文件的修改时间
FileUtils.isFileNewer(File file, Date date)
FileUtils.isFileNewer(File file, File reference)
FileUtils.isFileNewer(File file, long timeMillis)
FileUtils.isFileOlder(File file, Date date)
FileUtils.isFileOlder(File file, File reference)
FileUtils.isFileOlder(File file, long timeMillis)
- 文件/文件夹的迭代
FileUtils.iterateFiles(File directory, IOFileFilter fileFilter, IOFileFilter dirFilter)
FileUtils.iterateFiles(File directory, String[] extensions, boolean recursive)
FileUtils.iterateFilesAndDirs(File directory, IOFileFilter fileFilter, IOFileFilter dirFilter)
FileUtils.lineIterator(File file)
FileUtils.lineIterator(File file, String encoding)
FileUtils.listFiles(File directory, IOFileFilter fileFilter, IOFileFilter dirFilter)
FileUtils.listFiles(File directory, String[] extensions, boolean recursive)
FileUtils.listFilesAndDirs(File directory, IOFileFilter fileFilter, IOFileFilter dirFilter)
- 其他
FileUtils.isSymlink(File file) // 判断是否是符号链接
FileUtils.directoryContains(File directory, File child) // 判断文件夹内是否包含某个文件或者文件夹
FileUtils.sizeOf(File file) // 获取文件或者文件夹的大小
FileUtils.getTempDirectory()// 获取临时目录文件
FileUtils.getTempDirectoryPath()// 获取临时目录路径
FileUtils.getUserDirectory()// 获取用户目录文件
FileUtils.getUserDirectoryPath()// 获取用户目录路径
FileUtils.touch(File file) // 创建文件
FileUtils.contentEquals(File file1, File file2) // 比较两个文件内容是否相同
- FilenameUtils(文件名/后缀名相关)
FilenameUtils.concat(String basePath, String fullFilenameToAdd) // 合并目录和文件名为文件全路径
FilenameUtils.getBaseName(String filename) // 去除目录和后缀后的文件名
FilenameUtils.getExtension(String filename) // 获取文件的后缀
FilenameUtils.getFullPath(String filename) // 获取文件的目录
FilenameUtils.getName(String filename) // 获取文件名
FilenameUtils.getPath(String filename) // 去除盘符后的路径
FilenameUtils.getPrefix(String filename) // 盘符
FilenameUtils.indexOfExtension(String filename) // 获取最后一个.的位置
FilenameUtils.indexOfLastSeparator(String filename) // 获取最后一个/的位置
FilenameUtils.normalize(String filename) // 获取当前系统格式化路径
FilenameUtils.removeExtension(String filename) // 移除文件的扩展名
FilenameUtils.separatorsToSystem(String path) // 转换分隔符为当前系统分隔符
FilenameUtils.separatorsToUnix(String path) // 转换分隔符为linux系统分隔符
FilenameUtils.separatorsToWindows(String path) // 转换分隔符为windows系统分隔符
FilenameUtils.equals(String filename1, String filename2) // 判断文件路径是否相同,非格式化
FilenameUtils.equalsNormalized(String filename1, String filename2) // 判断文件路径是否相同,格式化
FilenameUtils.directoryContains(String canonicalParent, String canonicalChild) // 判断目录下是否包含指定文件或目录
FilenameUtils.isExtension(String filename, String extension) // 判断文件扩展名是否包含在指定集合(数组、字符串)中
FilenameUtils.wildcardMatch(String filename, String wildcardMatcher) // 判断文件扩展名是否和指定规则匹配
Hutool工具包
胡涂包:
IO相关的工具类:
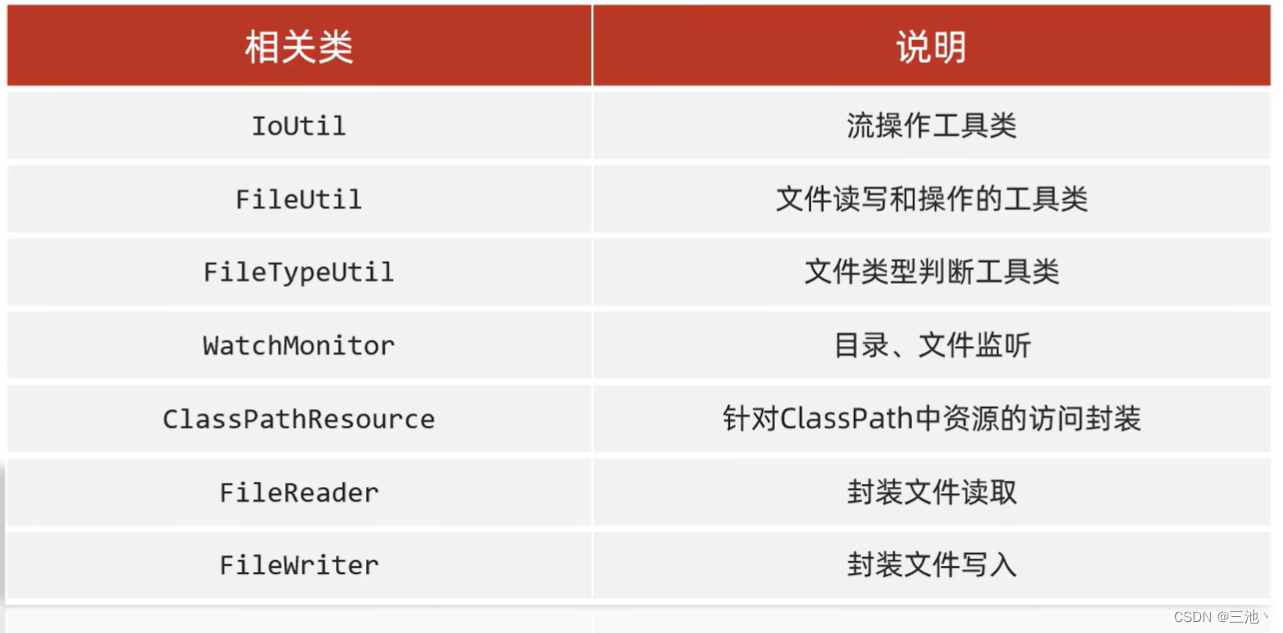
注意:封装文件读取(FileReader)和封装文件写入(FileWriter)的类名和java的字符流类名重复了,所以要想使用工具类,一定要注意导包。
Hutool的中文使用文档:https://hutool.cn/docs/#/
Hutool的Api帮助文档:https://apidoc.gitee.com/dromara/hutool/
方法的举例:
static <T> File appendLines(Collection<T> list, File file, Charset charset) 将列表写入文件,追加模式,策略为: 当文件为空,从开头追加,尾部不加空行 当有内容,换行追加,尾部不加空行 当有内容,并末尾有空行,依旧换行追加
这里的列表就是单列集合,追加模式就是原有的不会清空
public static void main(String[] args) {
//常用的Hutool方法
/*
* FileUtil类:
* file:根据参数创建一个File对象
* touch:根据参数创建文件
*
* writeLines:把集合中的数据写出到文件中,覆盖模式
* appendLines:把集合中的数据写出到文件中,续写模式
* readLines:指定字符编码,把文件中的数据,读到集合中
* readUtf8Lines:按照UTF-8的形式,把文件中的数据读到集合中
*
* copy:拷贝文件或者文件夹
*
* */
//可以用多个参数进行拼接,创建File对象
File file = FileUtil.file("D:\\", "我的世界", "noc", "a.txt");
System.out.println(file);
//touch,根据参数创建文件,如果父级路径不存在,可以连父级路径一起创建
FileUtil.touch(file);
//writeLines:把集合中的数据写出到文件中,覆盖模式
ArrayList<String>list=new ArrayList<>();
list.add("aaa");
list.add("aaa");
list.add("aaa");
list.add("aaa");
FileUtil.writeLines(list,file,"UTF-8");
//appendLines:把集合中的数据写出到文件中,续写模式,与writeLines使用方法一样
//readLines:指定字符编码,把文件中的数据,读到集合中
List<String> stringList = FileUtil.readLines(file, "UTF-8");
System.out.println(stringList);
}














 169
169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









