






HTTP/HTTPS协议
HTTP协议
HTTP全称是超文本传输协议(Hypertext Transfer Protocol),是应用层非常常见的协议
认识URL
平时我们所说的网址,就是URL(Uniform Resource Locator,统一资源定位符)

- 在URL中,部分字符被特殊定义,如/ ? :等字符
- 因此如果参数中带有这些字符,就对这些特殊字符进行转义,通过urlencode编码
- 再通过urldecode进行解码
HTTP协议格式

- 请求报文(Request)
- 请求方法:GET/POST方法
- URL:如a/b/c.html等请求资源
- 协议版本:如http/1.0,http/1.1等HTTP协议版本(Client端)
- 响应报文(Response)
- 协议版本:HTTP协议版本(Server端)
- 状态码:如404、200、502等状态码
- 状态码描述:描述状态码,如404:Not Found
如何分离报头和有效载荷
在HTTP中,以\r\n作为分隔符,通过空行分隔报头和有效载荷!
HTTP报头
在HTTP协议报头中,有许多的‘’KV值‘’,用来传递参数,HTTP报头分为四类:
- 通用报头
- 请求报头
- 响应报头
- 实体报头
HTTP报头中有些常见字段
- Content-Type:数据类型,如text、html、css等
- Content-Length:Body(有效载荷)的长度
- Host:客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上
- Use-Agent:声明用户的操作系统额浏览器版本信息
- referer:当前页面是从哪个页面跳转来的
- location:搭配3xx状态码使用,告诉用户接下来要去哪里访问
- Cookie:用于在客户端存储少量信息,实现会话(session)的功能
HTTP方法
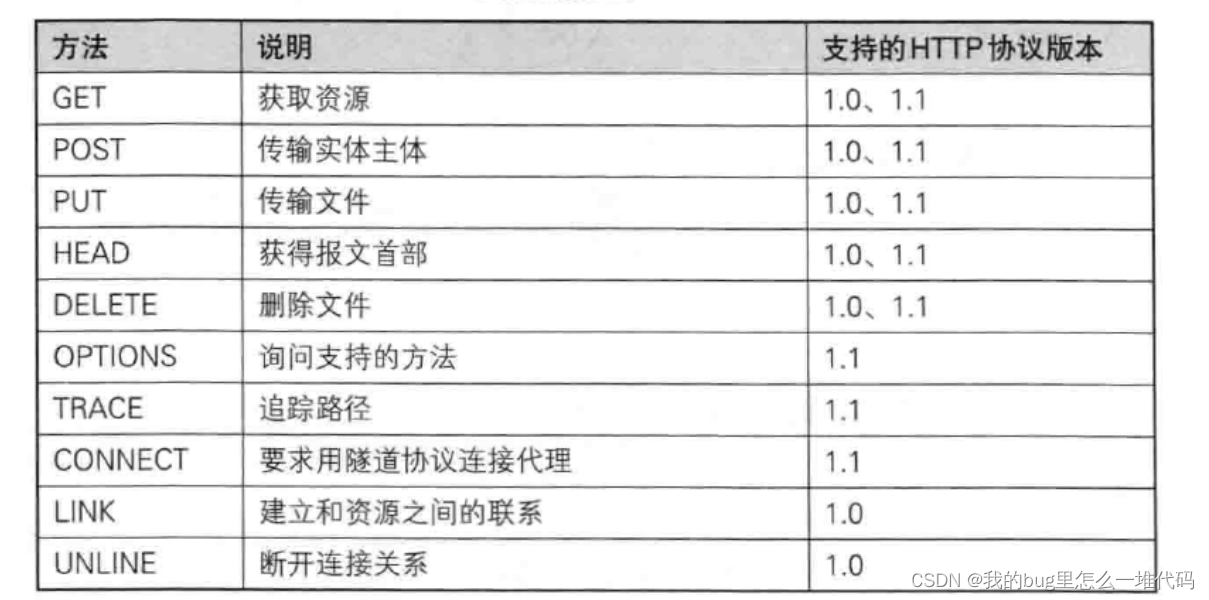
这里重点介绍GET和POST方法
- GET和POST方法都可以构建一个HTTP请求
- 不同点在于二者提交参数的方式不同
GET方法通过URL的方式提交参数,而POST方法通过正文的方式提交参数
相对来说POST方法更为私密,允许参数数据大小也更大(因为正文的大小在理论上是比URL字符串更大的)
在html标签中,通过设置form的method方法使用GET或POST方法
<form method="get"></form>
<form method="post"></form>
HTTP状态码
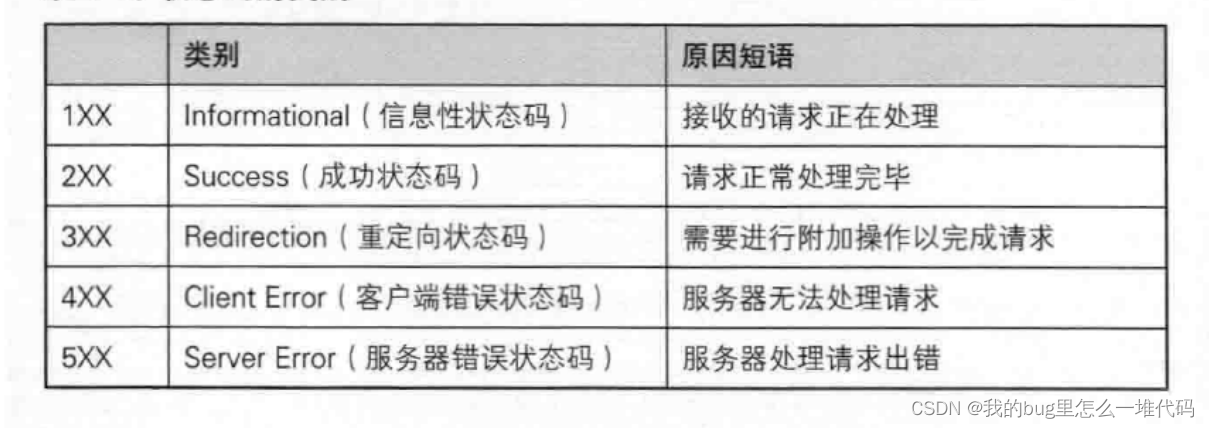
- 1XX:表示请求正在被处理
- 2XX:表示请求处理成功,如200(OK)
- 3XX:一般用作重定向,如临时重定向(302,303,307)和永久重定向(301)
- 4XX:服务端无法处理请求,表示客户端出了问题!如404(Not Found)表示服务器找不到要请求的资源
- 5XX:服务端处理请求错误,表示服务端出了问题!如502(Bad Gateway)
临时重定向和永久重定向
- 临时重定向
临时重定向表示请求的资源可能无法从这个地址进行访问,但是可以通过其他地址进行访问。如搜索引擎在识别到该状态码时,会继续抓取原始的URL,因为它认为这只是个临时的变动
- 永久重定向
顾名思义,永久重定向说明当前的URL已经不再使用了,永久重定向到新的URL,会以状态码的形式告诉浏览器。如爬虫和搜索引擎识别到该状态码时,会将旧的URL进行替换
临时重定向和永久重定向的作用的区别好像对用户差别不大,但实际上对搜索引擎这种程序影响还是很大的
重定向通常是搭配HTTP报头中的location属性使用的,通过location告诉浏览器接下来要跳转到哪个页面
序列化和反序列化
在网络传输中,通常是以字符串的形式进行数据传输,那对于某些结构化数据如何进行传输呢?
这时就要借助序列化这种操作将结构化数据转换为字符串发送给对端,对端拿到数据后再通过反序列化将字符串转换为结构化数据
- 序列化(Serialize):struct -> string
- 反序列化(Deserialize):string -> struct
可以通过JsonCpp、Protobuf等进行序列化和反序列化,也可以自己简单实现
这里简单实现以下将http请求转换为http响应(自己结构化出http请求报文)
先封装一下Util组件
#pragma once
#include <iostream>
#include <string>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
#include <sstream>
class Util
{
public:
static bool ReadFile(const std::string &path, std::string *fileContent)
{
// 1.获取文件本身大小
struct stat st;
int n = stat(path.c_str(), &st);
if (n < 0)
return false;
int size = st.st_size;
// 2.调整string空间
fileContent->resize(size);
// 3.读取
int fd = open(path.c_str(), O_RDONLY);
if (fd < 0)
return false;
read(fd, (char *)fileContent->c_str(), size);
close(fd);
return true;
}
static std::string ReadOneLine(std::string &message, const std::string &sep)
{
auto pos = message.find(sep);// 先找到分隔符的位置
if (pos == std::string::npos)
return "";
// 找到后截取分隔符前的内容
std::string s = message.substr(0, pos);
// 清空这一行的内容
message.erase(0, pos + sep.size());
return s;
}
// 将读到的请求行内容写入http请求对象中
static bool ParseRequestLine(const std::string &line, std::string *method, std::string *url, std::string *httpVersion)
{
std::stringstream ss(line);
ss >> *method >> *url >> *httpVersion;
return true;
}
};
#include <vector>
#include "Util.hpp"
using namespace std;
const string SEP = "\r\n";// 分隔符
const std::string defaultHomePage = "index.html";// 默认网页
const std::string webRoot = "./wwwroot"; // web根目录
// 创建一个HTTP请求类,用来封装HTTP报文中请求方法、url、http版本等字段
class HttpRequest
{
public:
HttpRequest() : path_(webRoot)
{
}
~HttpRequest() {}
public:
std::string method_;
std::string url_;
std::string httpVersion_;
std::vector<std::string> body_;// 有效载荷
std::string path_;// 文件路径
std::string suffix_;// 后缀
};
// 反序列化 string -> struct
HttpRequest Deserialize(std::string &message)
{
HttpRequest req; // 创建一个http请求对象
// 读取http请求报文中的请求行
std::string line = Util::ReadOneLine(message, SEP);
//将请求行中读到的数据写入到http请求对象中
Util::ParseRequestLine(line, &req.method_, &req.url_, &req.httpVersion_);
// 读取http请求报头中的内容
while (!message.empty())
{
line = Util::ReadOneLine(message, SEP);
req.body_.push_back(line);
}
// 截取url中文件路径
req.path_ += req.url_; // "wwwroot/a/b/c.html", "./wwwroot/"
if (req.path_[req.path_.size() - 1] == '/')
req.path_ += defaultHomePage;// 如果没有默认网页就加上
// 找到访问文件的后缀
auto pos = req.path_.rfind(".");
if (pos == std::string::npos)
req.suffix_ = ".html";
else
req.suffix_ = req.path_.substr(pos);
return req;
}
// 获取文件后缀
std::string GetContentType(const std::string &suffix)
{
// 可以参照Content-Type对照表
std::string content_type = "Content-Type: ";
if (suffix == ".html" || suffix == ".htm")
content_type + "text/html";
else if (suffix == ".css")
content_type += "text/css";
else if (suffix == ".js")
content_type += "application/x-javascript";
else if (suffix == ".png")
content_type += "image/png";
else if (suffix == ".jpg")
content_type += "image/jpeg";
else if (suffix == ".mp4")
content_type += "video/mpeg4";
else
{
}
return content_type + SEP;// http报头中每个kv值后都要带上分隔符
}
// 处理http请求
// http请求 -> http响应
string HandlerHttp(string &message)
{
// 先将http请求反序列化
HttpRequest req = Deserialize(message);
// 从http请求的路径中获取文件,并作为http响应的有效载荷
string body;
Util::ReadFile(req.path_, &body);
// 组装http响应
string response = "HTTP/1.0 200 OK" + SEP;// 状态行
// 补充响应报头,标识Content-Length,Content-Type等属性
response += "Content-Length: " + to_string(body.size()) + SEP;
response += GetContentType(req.suffix_);
response += SEP;// 空行
response += body;// 有效载荷
return response;
}
HTTP的缺陷
HTTP协议内容是按照文本的方式明文传输的,很显然这是不安全的,因此我们需要对传输的数据进行加密,这就有了HTTPS
HTTPS协议
HTTPS协议是在HTTP协议的基础上,引入了一个加密层
明文和密文
- 加密:将明文通过一系列变换形成密文
- 解密:将密文通过一系列逆变换转换为明文
在加密和解密的过程中,往往需要借助一个或多个中间数据,辅助其完成,而这个数据就叫做密钥
为什么要加密
在网络传输的过程中,数据往往要经过路由器,WiFi热点,通信服务运营商,代理服务器等多个物理节点,如果数据是明文的,很容易被中间人劫持后篡改,即被中间人攻击,这样很显然是不安全的,所以必须要对数据进行加密
常见加密方式
- 对称加密
- 采用单钥密码系统的加密方法,同一个密钥可以同时用作信息的加密和解密,这种加密方法称为对称加密,也称为单密钥加密,特征:加密和解密所用的密钥是相同的
- 常见对称加密算法:DES、3DES、AES、TDEA、Blowfish、RC2等
- 特点:算法公开、计算量小、加密速度快、加密效率高
- 非对称加密
- 需要两个密钥来进行加密和解密,这两个密钥是公开密钥(public key,简称公钥)和私有密钥(private key,简称私钥)
- 常见非对称加密算法:RSA,DSA,ECDSA
- 特点:算法强度复杂、安全性依赖于算法与密钥但是由于其算法复杂,而使得加密解密速度没有对称加密解密的速度快。
公钥和私钥
公钥和私钥是两个配对的密钥,但是加密速度非常慢
使用非对称加密有两种方式
- 公钥加密,私钥解密
- 私钥加密,公钥解密
一般来说公钥是公开的每个用户都有,而私钥是服务器私有的,不论是哪种方式,两个密钥必须交替使用
数据摘要和数据指纹
- 数据摘要:通过单向散列函数(Hash函数)对信息进行运算,生成一端固定长度的数据摘要
- 数据指纹:不是一种加密机制,但可以判断数据是否被篡改
- 摘要常见算法:有MD5、SHA1、SHA256、SHA512等,算法把无限的映射成有限,因此可能会有碰撞
- 摘要特征:和加密算法的区别是,摘要并不是严格意义的加密,因为没有解密,从摘要很难反推原始信息,通常用来做数据对比(将需要对比的数据做摘要,并对比已有的摘要)
如何对HTTP进行加密
这里有四种方案
- 只使用对称加密
- 如果通信双方都持有一个密钥X,且没有别人知道,那么这种做法是安全的
- 但如果中间人劫持并破解了这个密钥,这个时候就不安全了
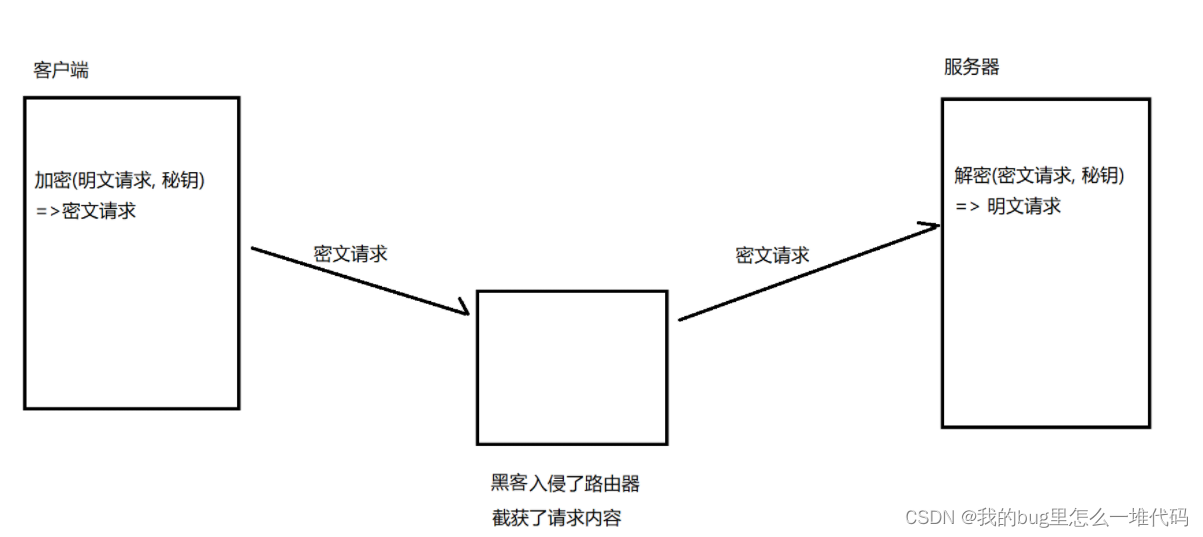
同一时刻,服务器会向很多个客户端提供服务,这句需要大量不同的密钥(肯定不能是相同的密钥,这样很明显不安全),此时就增大了服务器的维护成本
有一种做法是客户端与服务器通信前先协商好要使用的密钥
但这种做法也有漏洞,协商密钥时,也要进行加密(不然中间人就获取到秒了),这就成了“先有鸡还是先有蛋”的问题了
- 只使用非对称加密(C端公钥,S端私钥)
- 这对于客户端到服务端是安全的,因为私钥只有服务端有,所以这个方向上传输的数据是安全的
- 但对于服务端到客户端就不安全了,每一个用户都拥有公钥(中间人也不例外),这条方向上中间人就很容易劫持数据了
- 双方都是用非对称加密(C\S端分别持有对方的公钥和私钥)
- S端持有公钥S和公钥S’,C端持有公钥C和私钥C’
- 双方交换公钥
- C端->S端:C端用S加密,S端用S’解密
- S端->C端:S端用C加密,C端用C’解密
这样做好像确实是安全的(也有安全问题,例如双方交换公钥是会存在问题),但是效率会很低!
- 对称加密+非对称加密
- S端持有公钥S和私钥S’
- C端发起https请求,获取服务端公钥S
- C端本地生成密钥C,并通过公钥S加密,发送给S端
- S端通过私钥S’解密,获取密钥C
- 之后双方通过密钥C进行通信
首先,这种方案很显然解决了效率问题,其次很大程度上也解决了安全问题,但依旧存在安全问题
如果中间人在S端向C端发送公钥S时劫持,就会引发安全问题!
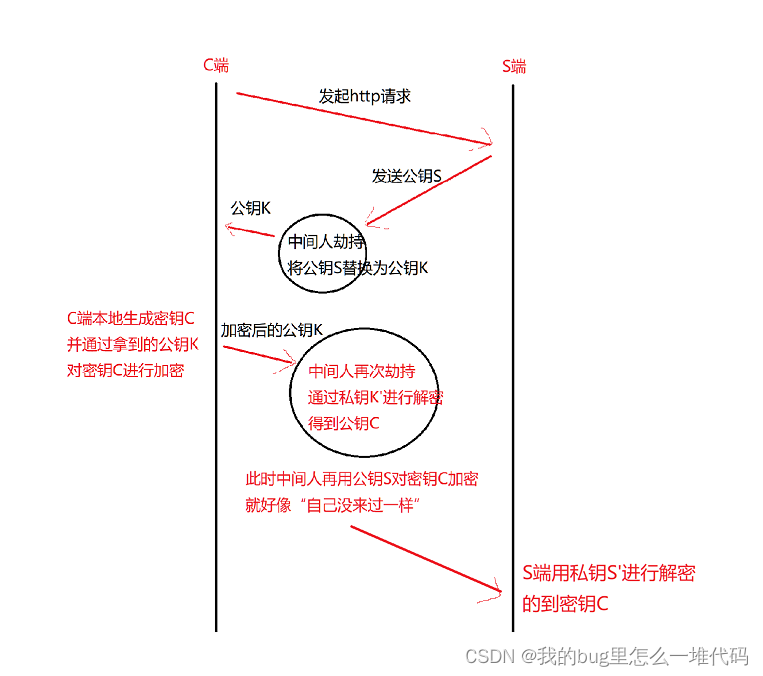
就这样,双方通过密钥C进行通信,并不知道中间人已经在神不知鬼不觉的通过密钥C,不断获取双方通信的数据,并进行攻击!
问题出在了哪儿?
正因为客户端不知道自己拿到的公钥“S”是否是真正的服务端发送的,才导致了这一系列的问题
因此解决这个问题,就需要通过CA证书!
CA证书
服务端在使用HTTPS前,需要向CA机构申领一份数字证书,数字证书里含有证书申请者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书里获取公钥就行了,证书就如身份证,证明服务端公钥的权威性
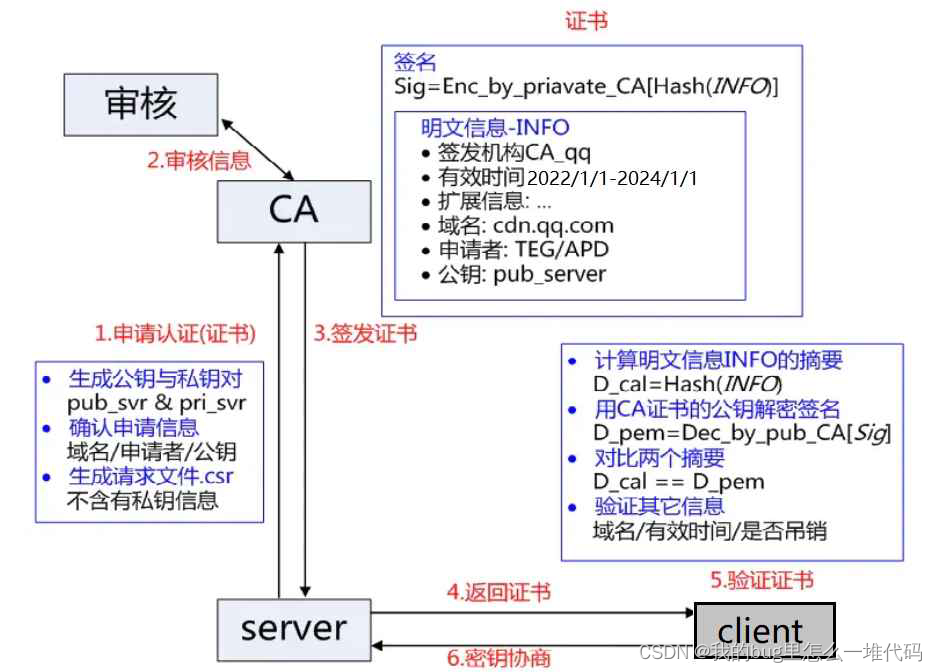
在申请证书时,会同时生成一堆公钥和私钥,其中公钥会随着CSR文件,一起发给CA进行权威认证,私钥服务端自己保留,用作之后的通信
数据签名
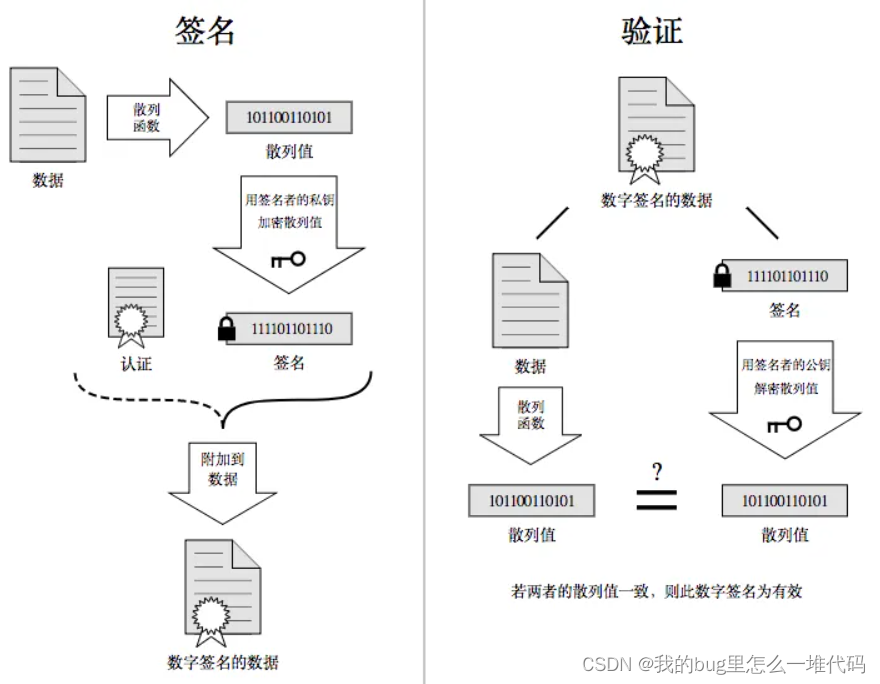
当服务端在申请CA认证时,CA机构会对服务端进行审核,并为该网站做数字签名
- CA机构拥有公钥A和私钥A’
- CA机构对服务端申请的证书明文进行数据摘要
- 然后对数据摘要通过私钥A’进行加密,得到数据签名S
- 这样证书明文和签名S共同组成数字证书
那么问题又来了,C/S两端在进行证书验证时,证书会不会是假的呢?
- 中间人篡改证书
- 中间人篡改了证书明文
- 由于他没有CA机构的私钥,因此无法hash之后用私钥加密形成签名,也就形成不了与篡改前证书匹配的签名
- 如果强行篡改,客户端在验证证书时会发现明文和签名解密后不一致,说明证书已被篡改,从而终止与服务端通信
- 中间人调包整个证书
- 中间人没有CA私钥,无法制作假证书
- 于是中间人只能去申请真证书,然后用自己申请的证书进行调包
- 但实际上这种做法,客户端一眼就能识别出来,因为证书中包含了域名等服务端认证信息
就是因为中间人没有CA机构的私钥,所以无法对CA机构形成的证书或者自己的假证书做修改
加密方案
因此有了第五种加密方案:对称加密+非对称加密+CA证书认证
CA证书认证解决的是,客户端无法识别出自己拿到的公钥S是否是真正的服务端发来的!















 4325
4325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









