




目录
Hadoop简介
狭义来说,hadoop是Apache基金会开发的分布式系统基础架构,用来解决海量数据的存储和海量数据的分析计算问题。广义上来说,Hadoop 通常是指一个更广泛的概念 —— Hadoop 生态圈。
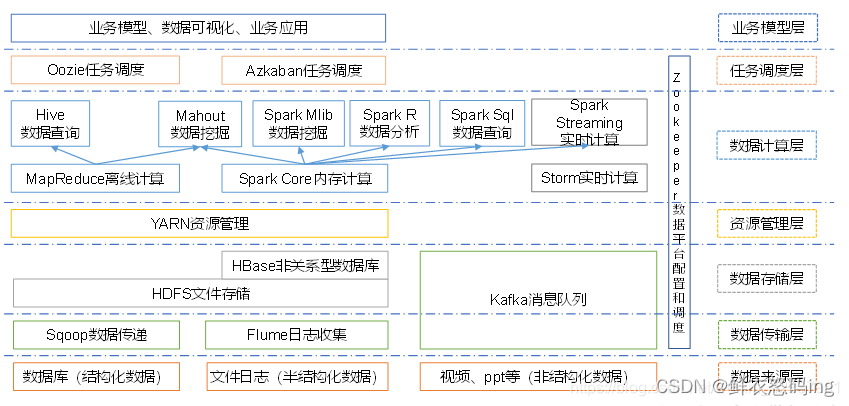
Hadoop 三大发行版本
Apache、Cloudera、Hortonworks
Apache 版本最原始(最基础)的版本,对于入门学习最好。
Cloudera在大型互联网企业中用的较多。其主要产品有CDH、Cloudera Manager,Cloudera Support
Hadoop优势
高可靠性: Hadoop 底层维护多个数据副本,所以即使 Hadoop 某个计算元素或存储出现故障,也不会导致数据的丢失。
高扩展性: 在集群间分配任务数据,可方便的扩展数以千计的节点。
高效性: 在 MapReduce 的思想下,Hadoop 是并行工作的,以加快任务处理速度。
高容错性: 能够自动将失败的任务重新分配。
低成本:Hadoop不要求机器的配置达到极高的标准,大部分普通商用服务器即可满足要求,通过提供多个副本和容错机制提高集群的可靠性
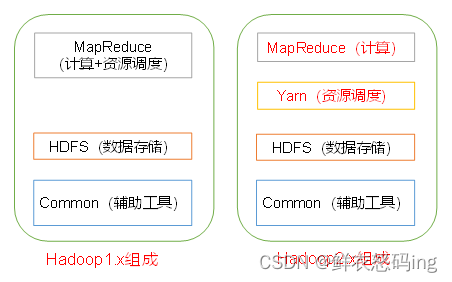
Hadoop基本组成
常用Shell命令
hdfs dfs -ls <path>:列出指定 HDFS 路径下的文件和目录
hdfs dfs -mkdir <path>:在 HDFS 中创建新目录
hdfs dfs -put <localsrc> <dst>:将本地文件(或目录)复制到 HDFS
hdfs dfs -get <src> <localdst>:将 HDFS 上的文件(或目录)复制到本地
hdfs dfs -mv <src> <dst>:移动 HDFS 中的文件目录或重命名文件目录
hdfs dfs -cp <src> <dst>:复制 HDFS 中的文件或目录
hdfs dfs -rm <path>:删除 HDFS 中的文件
hdfs dfs -cat <path>:在控制台显示 HDFS 文件的内容
hdfs dfs -du <path>:显示 HDFS 文件或目录的大小
hdfs dfs -df <path>:显示 HDFS 的可用空间
hdfs fsck path [-files [-blocks [-location]]]
-files列出路径内的文件状态
-files -blocks输出文件块报告(几个块,几个副本)
-files -blocks -locations 输出每个block的详情HDFS分布存储
HDFS是一个分布式文件系统,具有高容错、高吞吐 量等特性,分布在多个集群节点上的文件系统。有NN、DN、SNN三种角色。
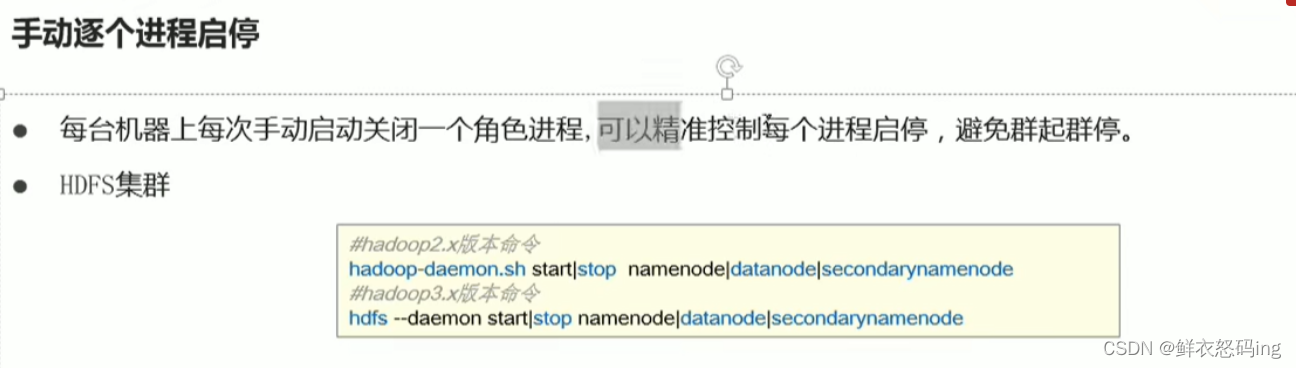
HDFS启停
NameNode(NN)
HDFS的主角色,负责管理每个文件的块所在的 DataNode、整个HDFS文件系统、存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限)等。
DataNode(DN)
HDFS从角色,负责处理客户端的读写请求,存储删除文件块,以及块数据校验和。
SecondaryNameNode(SNN)
NN的辅助角色,帮NN打杂,监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS 元数据的快照。
可通过9870端口(默认9870)访问web界面,查看集群各节点状态及信息
文件写入流程
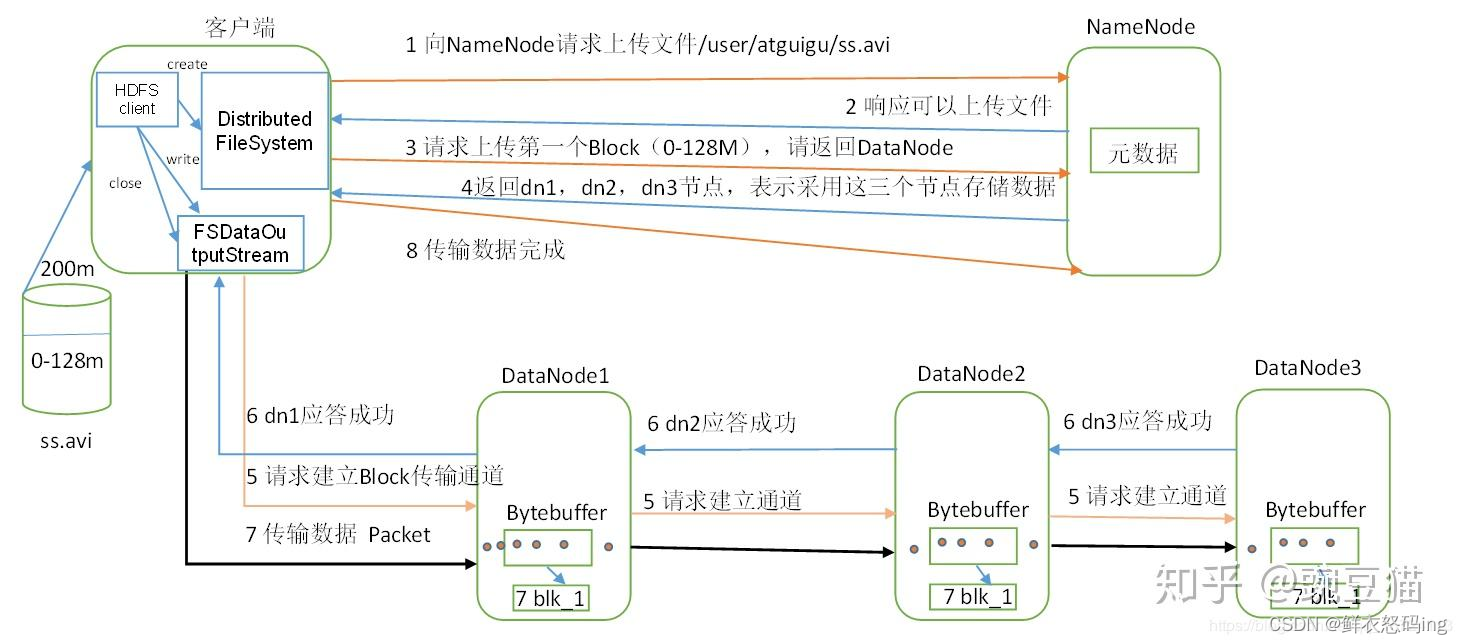
发送的写入请求通过后,客户端会根据NN返回的信息自动把数据分块,向网络距离最近的DN写入数据。同时,DN会完成备份操作,把备份传到其他的DN,然后由其他的DN再次做备份传播,直到满足设置的备份数量 。当数据写入完成后,客户端会通知NN,由NN完成元数据记录。
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6465
6465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









