










背景
当你测试App的时候,想要通过Fiddler/Charles等工具抓包看下https请求的数据情况,发现大部分的App都提示网络异常/无数据等等信息。以“贝壳找房”为例:
Fiddler中看到的请求是这样的: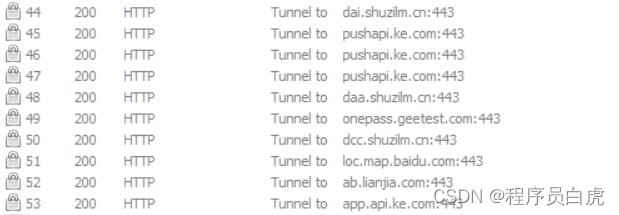
你可能开始找证书的问题:是不是Fiddler/Charles的证书没有导入的手机中去?配置一遍又一遍,又开始对比web端浏览器的https发现没问题。这时候你可能已经开始怀疑人生了。
那么究竟是不是证书的问题?
没错,就是证书的问题,但跟你想象中的证书有点不同,不是Fiddler内置证书的问题,而是App内置证书的问题 -- SSL Pinning机制
什么是SSL Pinning?
首先,在https的建立连接过程中,当客户端向服务端发送了连接请求后,服务器会发送自己的证书(包括公钥、证书有效期、服务器信息等)给客户端,如果客户端是浏览器,则使用内置的CA证书去校验服务器证书是否一致。
那么为什么Fiddler能够抓的到浏览器的https请求呢?原因就是在于用户可以自由的将第三方的证书导入到浏览器内置的CA证书集中。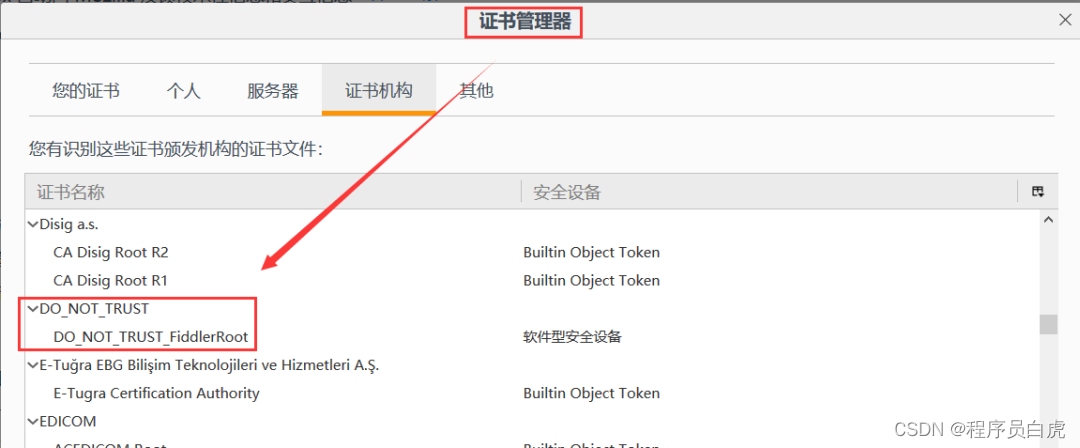
明白上述一点之后,我们再回到App客户端,App默认是信任系统(Android or IOS)用户第三方安装的的CA证书集的,有一些App能够通过Fiddler抓到包的原因是因为:我们可以在系统的用户CA证书集中添加Fiddler的证书。这样App就能信任证书是安全的,放心的发送请求了。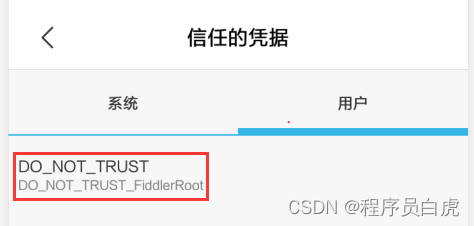
但是现在随着系统的更新,Google or Apple认识到安全越来越重要,所以就引入SSL-Pinning技术:开发者预先把证书相关信息预置到App中再打包,这样在https通讯过程中App本地可以与服务器返回的证书可以做对比,如果发现不一致,那么可能就是由于中间人攻击(比如Fiddler/Charles抓包工具),App客户端可以终止https链接。
而在新版本的系统规则中,应用只信任系统默认预置的CA证书,如果是第三方安装的证书(比如Fiddler安装的)则不会信任:
解决方案
上面的都是一些理论方面的内容,到底该如何突破SSL Pinning机制能够抓到App的https请求包呢?
方案一:使用Android7.0以下的系统
目前已验证在Android 7.0或以上的系统有启用了对第三方证书的限制。但是在Android 7.0以下还是依旧可以将Fiddler/Charles的证书安装在用户的CA集中抓取https请求。
方案二:将Fiddler/Chales证书安装到系统默认预置的CA证书区域中
此种办法前提是需要root权限,但是现在很多新款手机获取root权限困难,所以此办法并不推荐。
方案三:反编译APK,修改AndroidManifest.xml文件
有些APK加了壳,需要先进行脱壳处理
再通过apktool等工具进行反编译
在源码的res/xml目录添加network_security_config.xml文件,内容如下: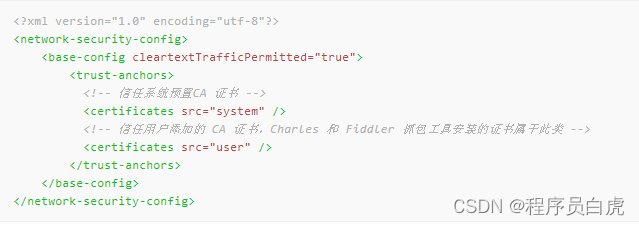
修改AndroidManifest.xml文件,在application标签中增加:
android:networkSecurityConfig="@xml/network_security_config"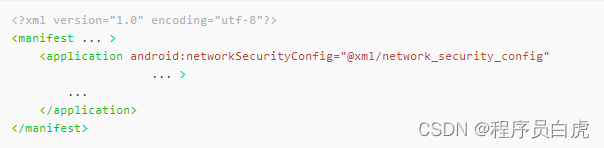
此种方案比较适用于对反编译比较熟练的童靴
方案四:VitualXposed框架+JustTrustMe模块(推荐)
VitualXposed介绍:
Use Xposed with a simple APP, without needing to root, unlock the bootloader, or flash a system image
官网下载地址:https://vxposed.com/
简单来说,VitualXposed可以在不需要设备root的情况下,修改App的行为。此应用的工作原理类似于应用分身功能,会将应用安装到一个虚拟独立的环境当中,其内部会自带一个已经激活了的Xposed工具。
JustTrustMe介绍:
An xposed module that disables SSL certificate checking for the purposes of auditing an app with cert pinning
JustTrustMe是Github上面的一个开源项目,是xposed中的一个模块,用于禁止SSL证书验证。
官方链接:https://github.com/Fuzion24/JustTrustMe
操作流程:
将VitualXposed安装到真机中,点击应用按钮->添加应用,将要调试的App、JustTrustMe.apk进行安装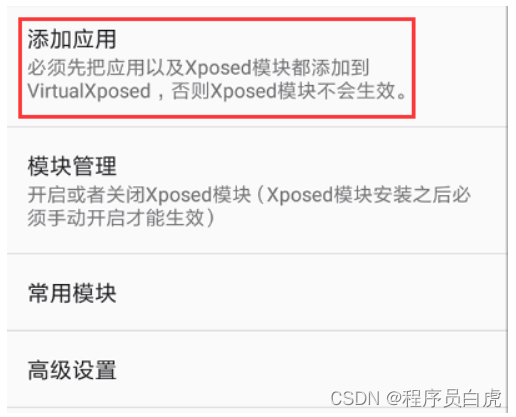
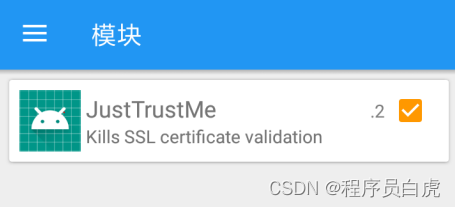
- 打开Xposed,选择左上角导航栏->模块,勾选JustTrustMe
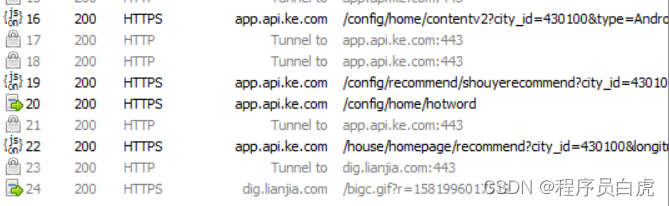
- 重启VitualXposed应用,打开贝壳找房,通过Fiddler抓包,可以看到App请求正常,https请求能抓到
【资源分享】
下面这份资源,对于想学习【软件测试】的朋友来说应该是最全面最完整的备战仓库,希望也能帮助到你!


















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









