







 本文介绍了感知哈希算法在以图搜图中的应用,包括原理、图像预处理步骤和代码实现。通过计算汉明距离评估图像相似度,尤其在数据集筛选和优化过程中发挥重要作用。
本文介绍了感知哈希算法在以图搜图中的应用,包括原理、图像预处理步骤和代码实现。通过计算汉明距离评估图像相似度,尤其在数据集筛选和优化过程中发挥重要作用。
-- 前言(HOOK团队):
想必大家也都见过以图搜图这类的软件,我们大家都仅限于去使用,作为刚入门计算机视觉方向的小白,今天在看书的时候看见了以图搜图的原理,这就使我茅塞顿开,原理这么简单,接下来来看看以图搜图的代码部分吧:
一、感知哈希算法实现以图搜图的原理
感知哈希算法的原理:
当我们提到哈希算法时,通常是指将输入数据转换为固定长度的二进制字符串。感知哈希算法是一种用于图像比较和检索的哈希算法,其原理是将图像转换为一个固定长度的二进制哈希值。
感知哈希算法的步骤如下:
-
图像预处理:首先,将输入的图像转换为灰度图像。这可以通过将彩色图像转换为灰度图像来实现。然后,将图像的大小调整为一个固定的尺寸(通常是8x8像素)。
-
均值化:在将图像进一步处理之前,需要计算图像的平均灰度值。这个平均值将用于对图像进行二值化操作。
-
二值化:接下来,使用均值将图像的像素值二值化。通常,小于等于平均值的像素被设置为0,大于平均值的像素被设置为1。这样,我们将图像转换为一个只包含0和1的黑白图像。
-
哈希值生成:最后,将二值化的图像展平为一个一维数组,并将其作为哈希值输出。这个哈希值是一个固定长度的二进制字符串,可以被用来比较和检索图像。
感知哈希算法的特点是,只要两个图像很相似,它们的哈希值也将非常接近。因此,我们可以使用感知哈希算法来比较和检索图像。通过计算两个图像的哈希值之间的汉明距离(即不同位的数量),可以衡量它们之间的相似程度。
二、代码部分
import cv2
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # plt中文显示
def hash(img):
img = cv2.cvtColor(img,cv2.COLOR_RGB2GRAY) #将输入的彩色图像转换为灰度图像,方便后续处理。
img = cv2.resize(img,(8,8)) # 将图像的大小调整为8x8像素,以便后续处理。
img = (img/4).astype(np.uint8)*4 # 为了进一步降低图像的颜色细节,以获取更简化的特征表示,简化色彩。
m = np.mean(img)
img[img <= m] = 0 # 图像的二值化操作
img[img > m] = 1 # 图像的二值化操作
print(img.shape)
plt.imshow(img.astype(np.uint8) * 255, cmap='gray')
return img.reshape(-1) # 将处理后的图像展平为一个一维数组,并返回该数组。
img1 = cv2.imread(r'C:\Users\Acer\Desktop\1.jpg',3)
img2 = cv2.imread(r'C:\Users\Acer\Desktop\2.jpg',3)
img3 = cv2.imread(r'C:\Users\Acer\Desktop\4.jpg',3)
hash_img1 = hash(img1)
hash_img2 = hash(img2)
hash_img3 = hash(img3)
# 使用计算哈希值的结果,通过计算汉明距离来比较图像的相似程度:
distance1 = np.sum(hash_img1 == hash_img2) / hash_img1.shape[0]
distance2 = np.sum(hash_img1 == hash_img3) / hash_img1.shape[0]
# 原图展示
plt.subplot(131)
plt.xticks([])
plt.yticks([])
plt.imshow(img1)
plt.title('原图片')
# 图一展示
plt.subplot(132)
plt.xticks([])
plt.yticks([])
plt.imshow(img2)
plt.title('汉明距离:{}'.format(distance1))
# 图二展示
plt.subplot(133)
plt.xticks([])
plt.yticks([])
plt.imshow(img3)
plt.title('汉明距离:{}'.format(distance2))
plt.show()三、代码的问题和细节讲解
①为什么经过灰度转换后还要进行色彩简化,就是如下代码,只要一个不就可以了,为什么要两次进行色彩简化?
1、img = cv2.cvtColor(img,cv2.COLOR_RGB2GRAY) #将输入的彩色图像转换为灰度图像,方便后续处理。
2、img = (img/4).astype(np.uint8)*4 # 为了进一步降低图像的颜色细节,以获取更简化的特征表示,简化色彩。不加1、代码的效果如下:
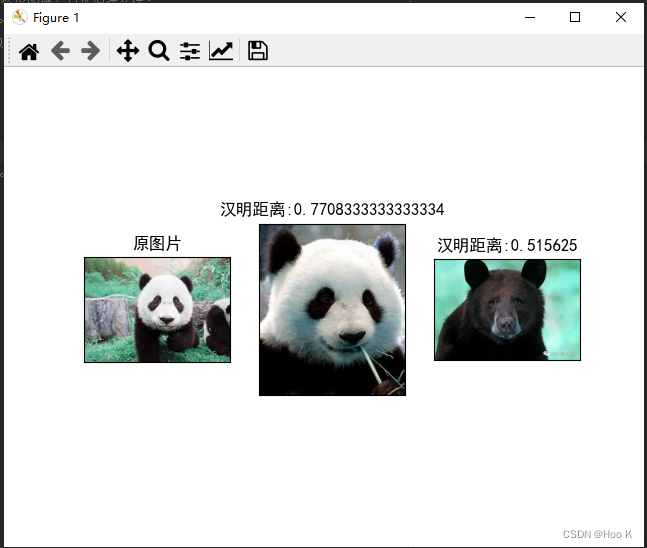
加上1、代码的效果:
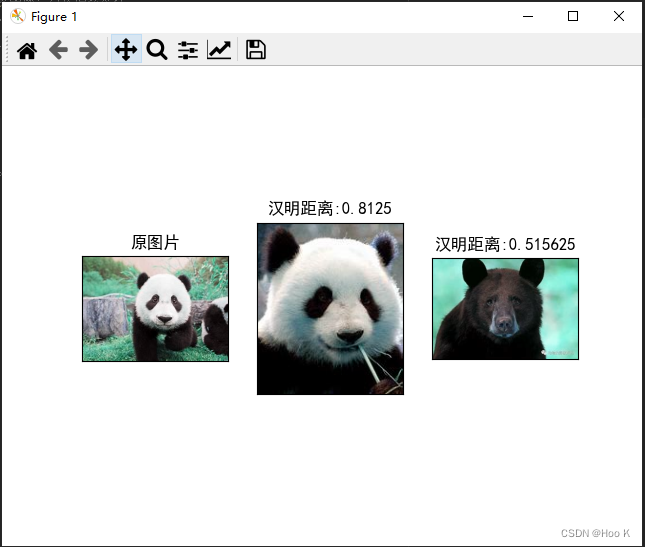
②、什么是汉明距离:
汉明距离是衡量两个等长字符串之间的差异性的度量方式。在图像处理中,可以使用汉明距离来比较两个图像的相似程度。
在上述代码中,哈希函数将图像转换为二进制序列,每个位代表一个像素的值。汉明距离是通过计算两个二进制序列中不同位的数量来衡量它们之间的差异程度。
汉明距离的计算步骤如下:
1. 对比两个二进制序列中对应位置的位,统计不同位的数量。
2. 将不同位的数量除以总位数,得到差异程度的比例。这个比例越小,表示两个序列越相似;比例越大,表示两个序列越不相似。
3. 最终得到的差异程度比例即为汉明距离。
在代码中,通过使用`np.sum()`函数计算两个二进制序列中不同位的数量,并通过除以总位数得到两个二进制序列之间的差异程度比例。
例如,若两个二进制序列的长度为n,其中有k位不同,那么汉明距离就是 k/n。若k为0,表示两个序列完全相同,汉明距离为0;若k等于n,表示两个序列完全不同,汉明距离为1。
在代码中,使用汉明距离来比较图像的相似程度。通过计算图像1和图像2的汉明距离,以及图像1和图像3的汉明距离,可以得出两两图像之间的相似程度。距离越小,表示图像越相似;距离越大,表示图像越不相似。
四、以图搜图的应用场景:
这个以图搜图我之所以写博客可不仅仅是它有趣而是它 的实际应用场景可谓是对我数据集的处理可谓是如虎添翼,在使用卷积神经网络亦或是YOLO来训练模型,都避免不了图片数据集的获取和预处理,经历过的人都知道获取和清晰数据集的痛苦,所以当我们通过爬虫获取了大量的数据集,但是里面的数据集并非全部是我们所需要的,这时我们就可以使用以图搜图来不断筛选和我们想要的图片相似度高的图片,从而获取高质量的数据集!!!

















 963
963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









