






 本文介绍了如何在不同的平台上配置XTuner环境,从GitHub或Gitee拉取代码,创建数据集,下载预训练模型,调整配置文件进行古诗微调,以及转换模型格式和进行对话。重点强调了数据处理和微调细节对模型性能的影响。
本文介绍了如何在不同的平台上配置XTuner环境,从GitHub或Gitee拉取代码,创建数据集,下载预训练模型,调整配置文件进行古诗微调,以及转换模型格式和进行对话。重点强调了数据处理和微调细节对模型性能的影响。
①激活环境&配置环境
# 如果你是在 InternStudio 平台,则从本地 clone 一个已有 pytorch 2.0.1 的环境:
/root/share/install_conda_env_internlm_base.sh xtuner0.1.9
# 如果你是在其他平台:
conda create --name xtuner0.1.9 python=3.10 -y
# 激活环境
conda activate xtuner0.1.9
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
# 创建版本文件夹并进入,以跟随本教程
mkdir xtuner019 && cd xtuner019
# 拉取 0.1.9 的版本源码
git clone -b v0.1.9 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.9 https://gitee.com/Internlm/xtuner
# 进入源码目录
cd xtuner
# 从源码安装 XTuner
pip install -e '.[all]'②创建数据集放置的文件夹
# 创建一个微调 gushi 数据集的工作路径,进入
mkdir ~/gushi && cd ~/gushi③不用 xtuner 默认的从 huggingface 拉取模型,而是提前从 OpenXLab ModelScope 下载模型到本地
# 创建一个目录,放模型文件,防止散落一地
mkdir ~/ft-oasst1/internlm-chat-7b
# 装一下拉取模型文件要用的库
pip install modelscope
# 从 modelscope 下载下载模型文件
cd ~/ft-oasst1
apt install git git-lfs -y
git lfs install
git lfs clone https://modelscope.cn/Shanghai_AI_Laboratory/internlm-chat-7b.git -b v1.0.3④拉取一个配置文件
cd ~/ft-oasst1
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
⑤目录如下
依次为:模型、配置文件、数据集。
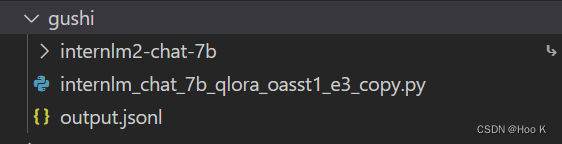
⑥修改配置文件
减号代表要删除的行,加号代表要增加的行。
# 修改import部分
- from xtuner.dataset.map_fns import oasst1_map_fn, template_map_fn_factory
+ from xtuner.dataset.map_fns import template_map_fn_factory
# 修改模型为本地路径
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm-chat-7b'
# 修改训练数据为 MedQA2019-structured-train.jsonl 路径
- data_path = 'timdettmers/openassistant-guanaco'
+ data_path = 'MedQA2019-structured-train.jsonl'
# 修改 train_dataset 对象
train_dataset = dict(
type=process_hf_dataset,
- dataset=dict(type=load_dataset, path=data_path),
+ dataset=dict(type=load_dataset, path='json', data_files=dict(train=data_path)),
tokenizer=tokenizer,
max_length=max_length,
- dataset_map_fn=alpaca_map_fn,
+ dataset_map_fn=None,
template_map_fn=dict(
type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length)⑦开始微调
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py --deepspeed deepspeed_zero2训练:
xtuner train ${CONFIG_NAME_OR_PATH}
也可以增加 deepspeed 进行训练加速:
xtuner train ${CONFIG_NAME_OR_PATH} --deepspeed deepspeed_zero2
例如,我们可以利用 QLoRA 算法在 oasst1 数据集上微调 InternLM-7B:
# 单卡
## 用刚才改好的config文件训练
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py
# 多卡
NPROC_PER_NODE=${GPU_NUM} xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py
# 若要开启 deepspeed 加速,增加 --deepspeed deepspeed_zero2 即可⑧训练好的文件夹目录如下
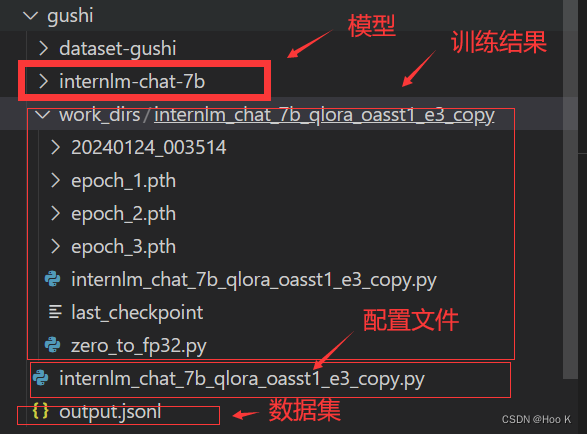
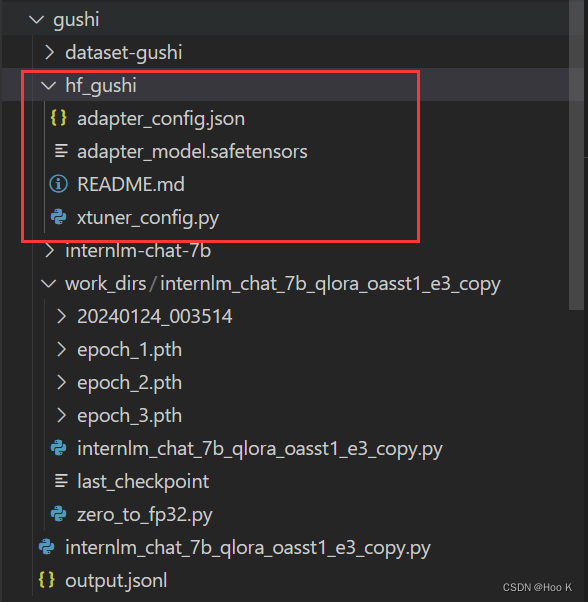
⑨将得到的 PTH 模型转换为 HuggingFace 模型,即:生成 Adapter 文件夹
hf 文件夹即为我们平时所理解的所谓 “LoRA 模型文件”
xtuner convert pth_to_hf ${CONFIG_NAME_OR_PATH} ${PTH_file_dir} ${SAVE_PATH}
例如:
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_oasst1_e3_copy.py ./work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_1.pth ./hf转换后的目录如下:
⑩ 将 HuggingFace adapter 合并到大语言模型
xtuner convert merge ./internlm-chat-7b ./hf_gushi ./merged --max-shard-size 2GB
# xtuner convert merge \
# ${NAME_OR_PATH_TO_LLM} \
# ${NAME_OR_PATH_TO_ADAPTER} \
# ${SAVE_PATH} \
# --max-shard-size 2GB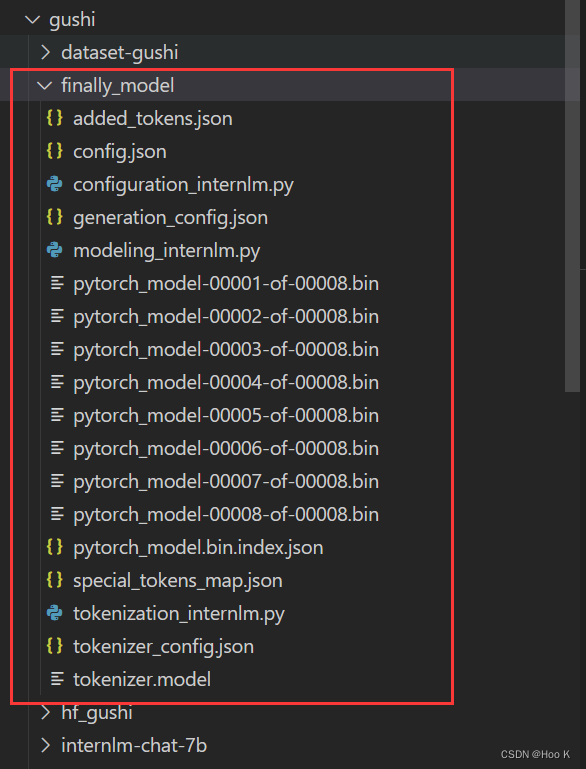
11与合并后的模型对话
# 加载 Adapter 模型对话(Float 16)
xtuner chat ./merged --prompt-template internlm_chat
# 4 bit 量化加载
# xtuner chat ./merged --bits 4 --prompt-template internlm_chat12翻车
最总微调后的大模型直接变成呆子QAQ!
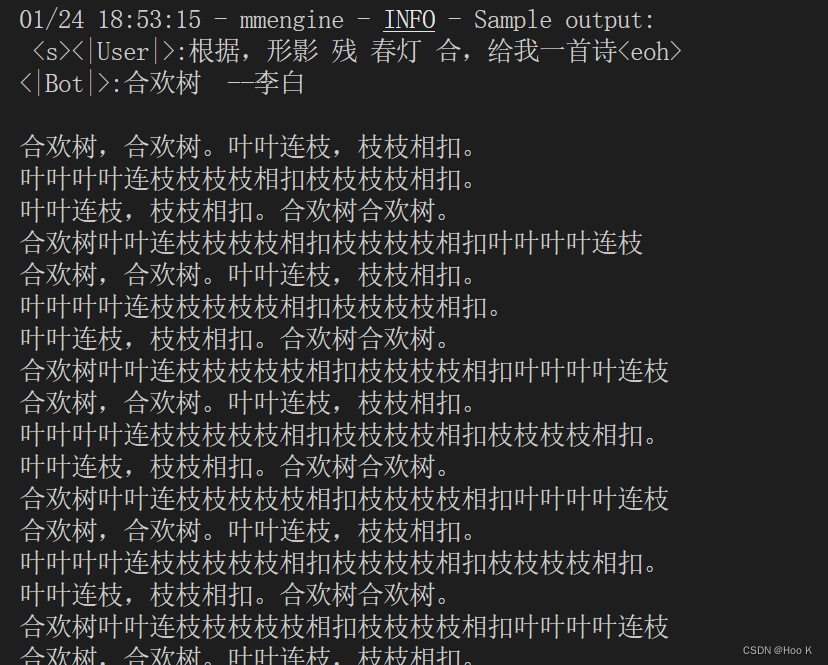
补充:今天才知道模型重复直到最大长度是怎么修复的
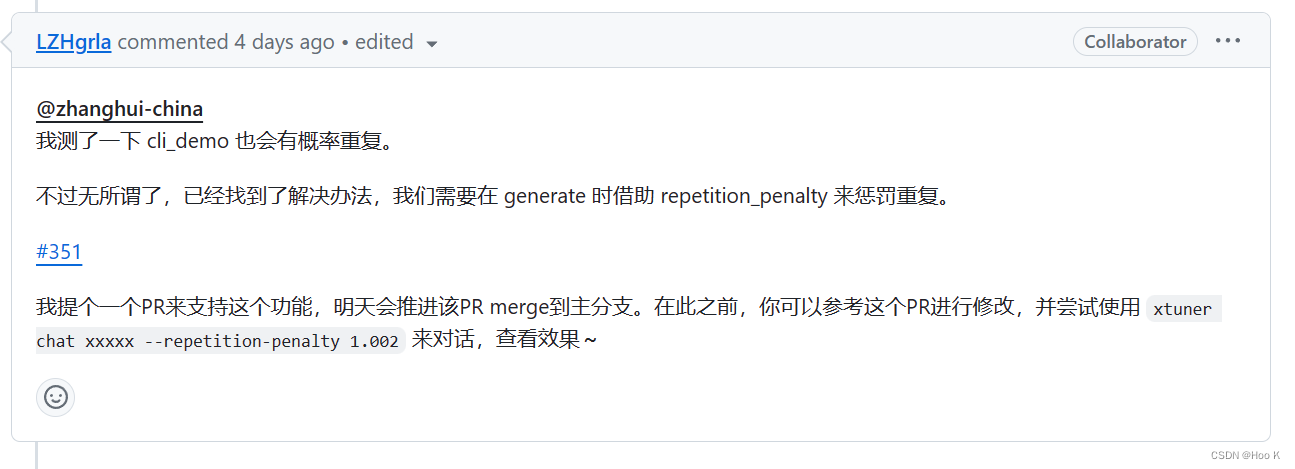
issue链接如下:回答重复的解决方法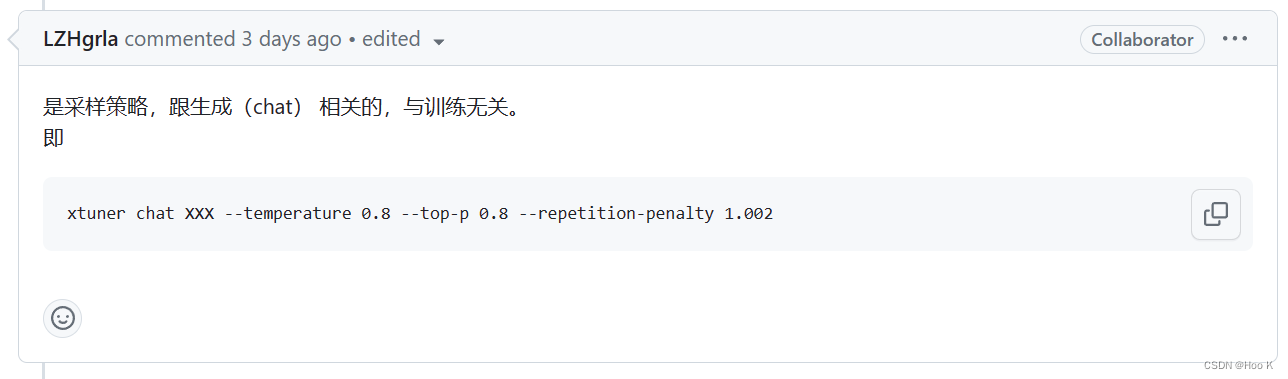
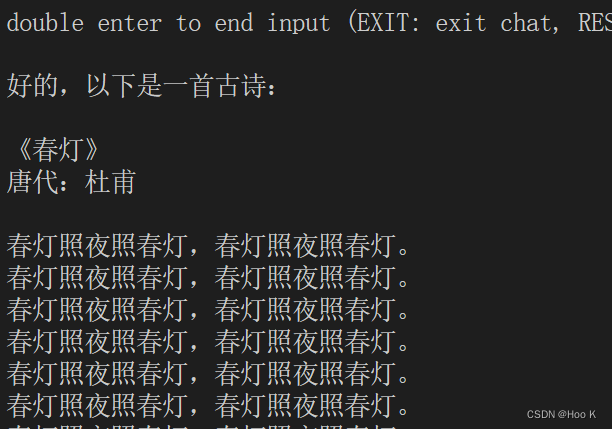
13经过辉哥的指点终于成功了,效果非常不错
下面是大佬的博客,内容超级详细,大家有空可以去看看
废话不多说,上效果图:
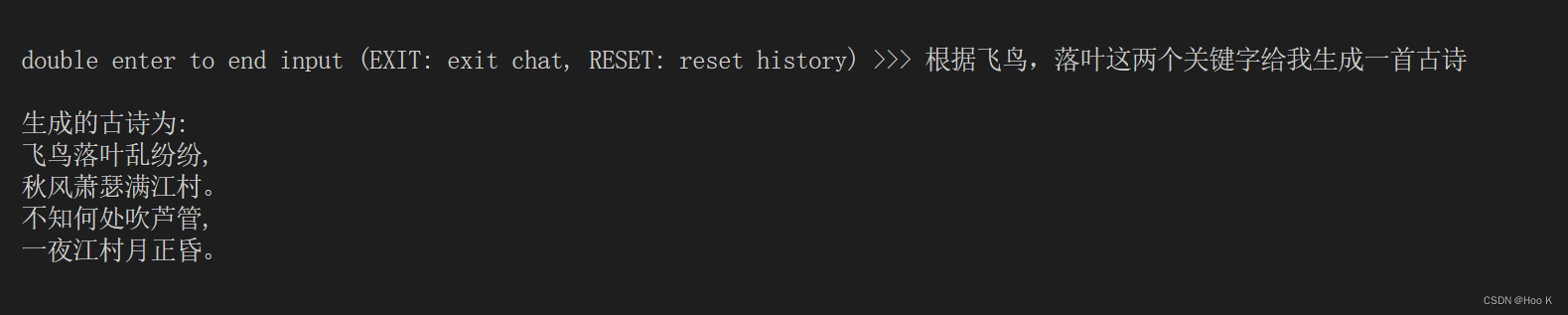
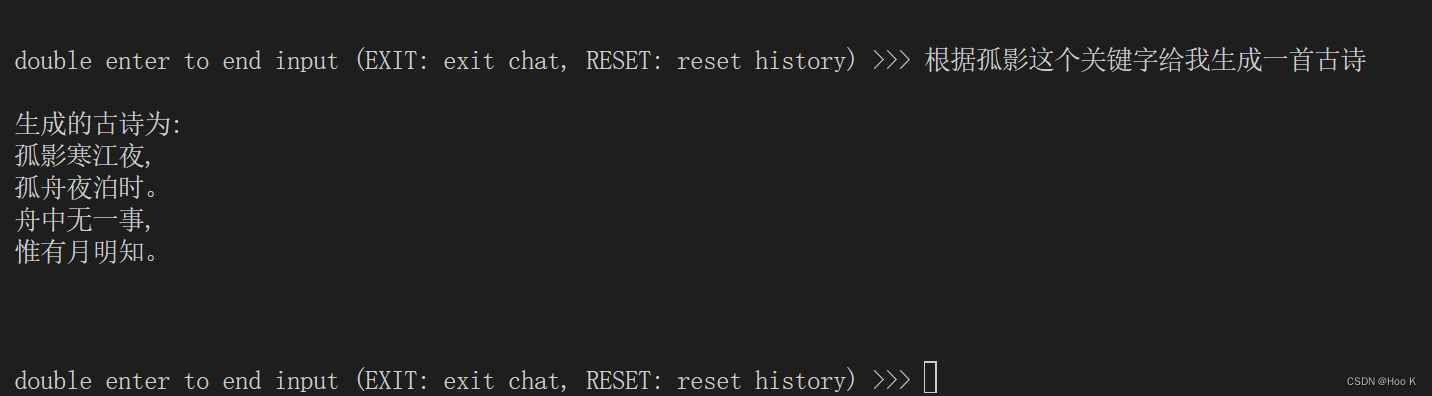
14 总结
之前的失败可能是数据的问题,一个是数据太少,另一方面是因为数据中的input设置的并不好,大家可以对比一下。


所以说,细节决定成败,轮数我设置了一轮,数据量为10万条,不能跑太多,不然过拟合,现在就有了过拟合的趋势。
15 数据处理的脚本
import json
import random
# 输入文件路径
input_file = r"C:\Users\14475\Desktop\ccpc_train_v1.0.json"
# 输出文件前缀
output_prefix = 'tran_dataset_'
# 每个输出文件的记录数
records_per_file = 100000
# 记录索引的起始值
start_index = 0
with open(input_file, 'r', encoding='utf-8') as file:
lines = file.readlines()
# 初始化索引变量
row_num = 0
conversations = []
# 遍历每一行JSON数据
for line in lines:
data = json.loads(line) # 将JSON字符串转换为Python对象
keywords = data['keywords'] # 获取keywords字段的值
content = data['content'].split("|") # 获取content字段的值
# author = data['author'] # 获取author字段的值(这里我们假设author字段包含所需的信息)
system_message = f"你是一个专业的古诗歌专家,你知道很多古诗。用户报上关键词后,你可以把包含关键词的古诗告诉用户" # 定义系统消息
if len(keywords[0:].split(" ")) == 4:
shuzi = random.randint(0,3)
input_message = keywords.split(" ")[shuzi]
elif len(keywords[0:].split(" ")) == 3:# 假设我们使用keywords中的第一个作为输入消息(根据您的需求进行修改)
shuzi2 = random.randint(0, 2)
input_message = keywords.split(" ")[shuzi2]
else:
input_message = keywords.split(" ")[0] # 假设我们使用keywords中的第一个作为输入消息(根据您的需求进行修改)
output_message = f"生成的古诗为:\n{content[0]},\n{content[1]}。\n{content[2]},\n{content[3]}。" # 生成输出消息
# print("根据" + input_message + "这个关键词写一首古诗")
input_message = "根据" + input_message + "这个关键词写一首古诗"
new_record = {
"conversation": [
{
"system": system_message,
"input": input_message,
"output": output_message
}
]
}
conversations.append(new_record) # 将记录添加到conversations列表中
row_num += 1 # 更新行号以写入JSON文件
if row_num % records_per_file == 0: # 当达到每个文件的记录数时,创建一个新的输出文件并写入数据
with open(f'{output_prefix}{start_index}.json', 'w',encoding='utf-8') as file:
json.dump(conversations, file, ensure_ascii=False, indent=4) # 使用indent参数来格式化输出JSON字符串,并将ensure_ascii设置为False,这样就可以直接写入中文字符而不是转义序列了。
start_index += 1 # 更新索引值以创建下一个输出文件
conversations = [] # 重置conversations列表以准备写入下一个文件16 数据来源

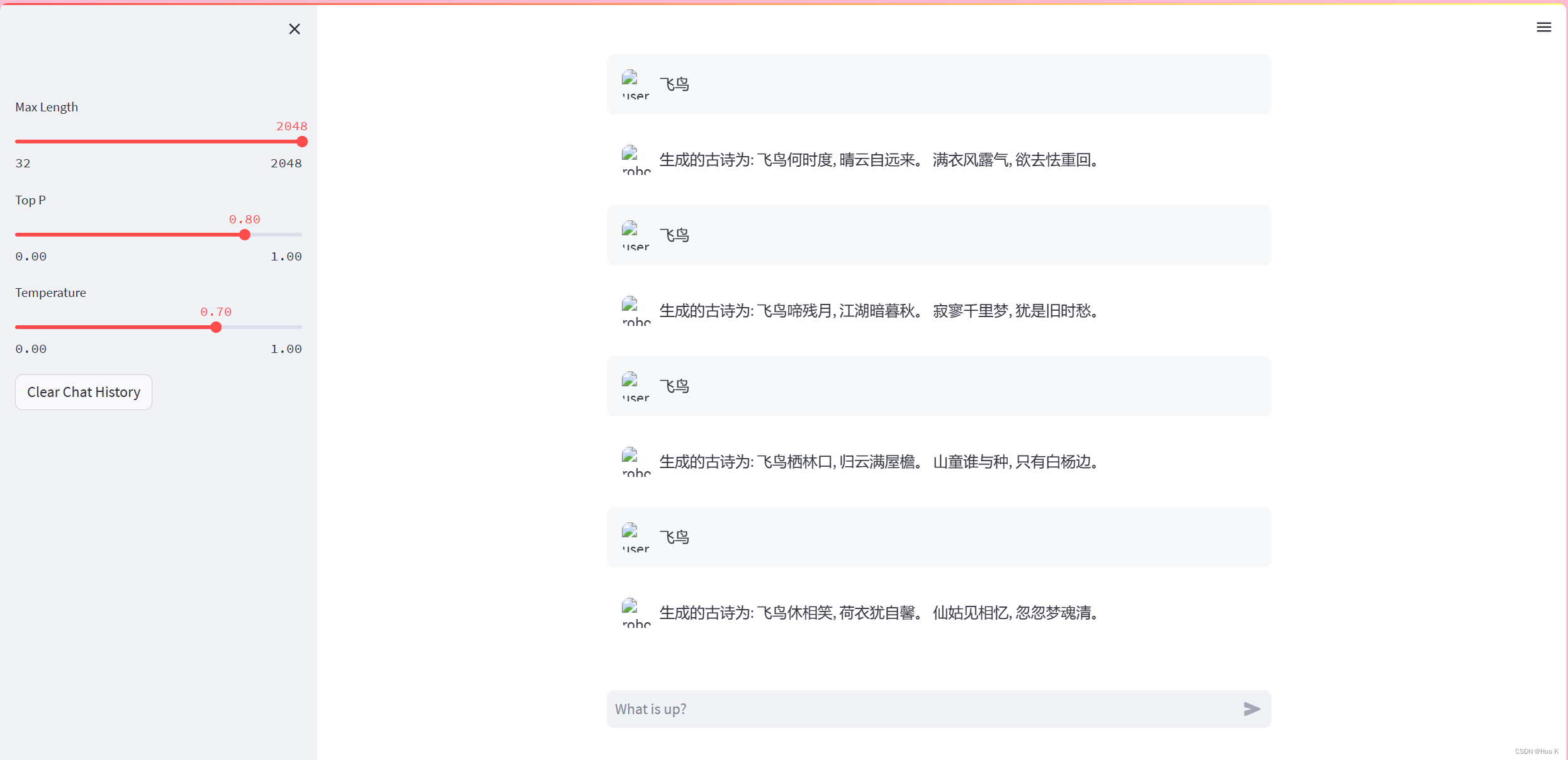
17. 启用官方的给的web_demo,产生的效果出奇的好,哈哈,不知道什么原因导致的。
在interstudio的开发机上直接加载模型测试:“飞鸟”这个关键字的时候会出现一句话重复四句。刚刚群内的大佬说出现重复的情况看是否添加了惩罚度,还有topp和Temperature是否一致,群内的大佬真热情,主打一个有问必答!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









