






笔者在学习python爬虫时遇到了Python爬虫在爬取网页数据时因文件夹名称含非法字符导致爬取失败的问题,在解决问题的过程中运用了两种方法。
在本文中笔者将以爬取当当网的书籍基本信息(封面、标题)为例
下面是解决方法演示:
首先是基本代码:
import urllib.request
from lxml import etree
for page in range(1,101):
if page == 1:
url = 'https://category.dangdang.com/cp01.36.04.01.00.00.html'
else:
url = f'https://category.dangdang.com/pg{page}-cp01.36.04.01.00.00.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'
}
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('gbk')
tree = etree.HTML(content)
print(tree)
name = tree.xpath('//ul[@id="component_59"]/li/a/img//@alt')
src = tree.xpath('//ul[@id="component_59"]/li/a/img/@data-original')
for i in range(0,101):
urllib.request.urlretrieve('https:'+src[i], f"{name[i]}.jpg")以下是代码运行结果:
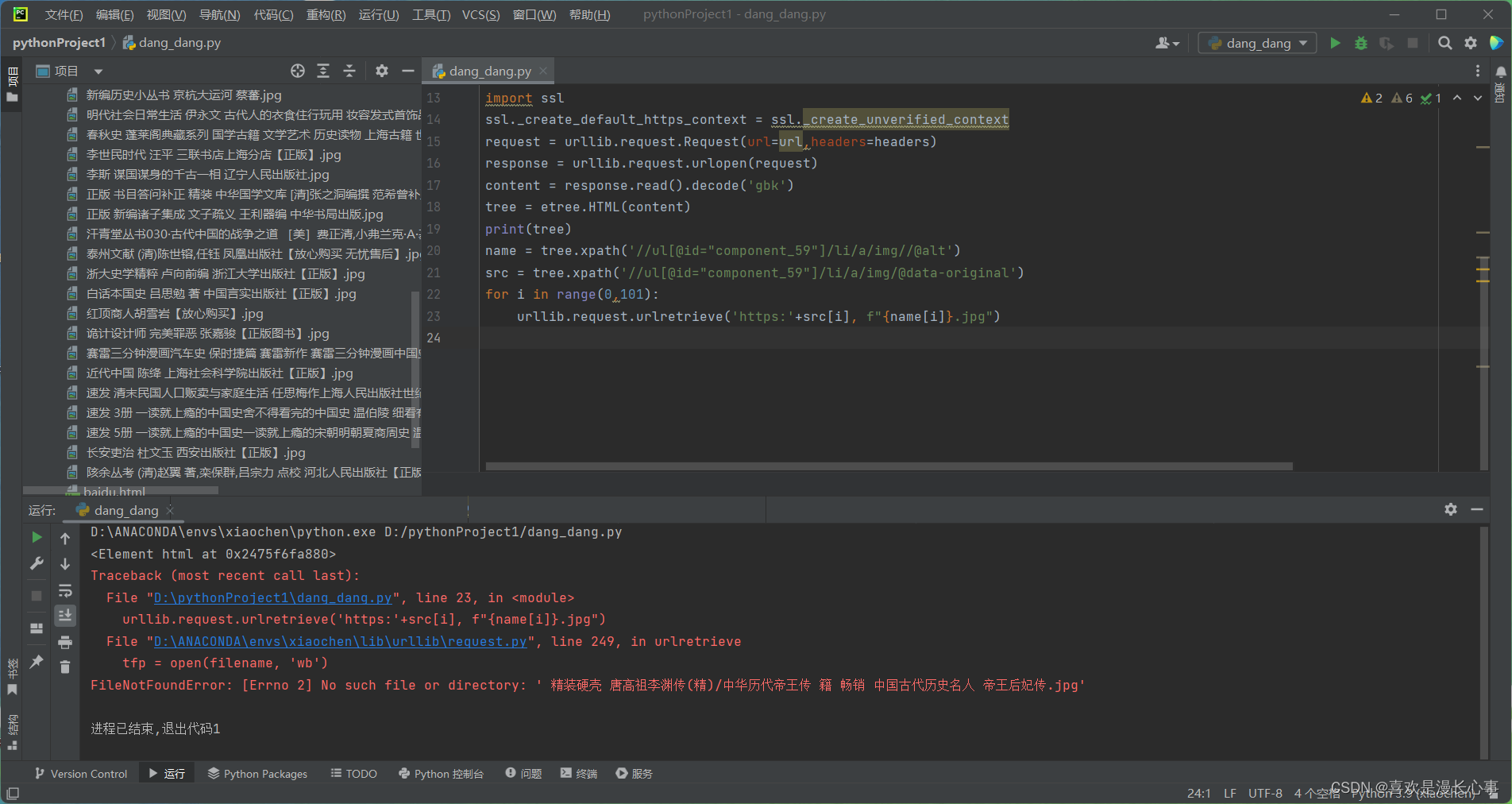
在这个结果中我们可以看到程序报错“FileNotFoundError: [Errno 2] No such file or directory: ' 精装硬壳 唐高祖李渊传(精)/中华历代帝王传 籍 畅销 中国古代历史名人 帝王后妃传.jpg'”这是因为在本书籍的标题中含有非法字符 '/' 。
![]()
这类问题的基本解决思路就是去掉非法字符,笔者首先想到的是切片法,我们只取书籍标题的一部分,来达到去掉非法字符,避免程序出错的目的。以下是第一个方法:切片法的演示;
切片法代码:
import urllib.request
from lxml import etree
for page in range(1,101):
if page == 1:
url = 'https://category.dangdang.com/cp01.36.04.01.00.00.html'
else:
url = f'https://category.dangdang.com/pg{page}-cp01.36.04.01.00.00.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'
}
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('gbk')
tree = etree.HTML(content)
print(tree)
name = tree.xpath('//ul[@id="component_59"]/li/a/img//@alt')
src = tree.xpath('//ul[@id="component_59"]/li/a/img/@data-original')
for i in range(0,101):
urllib.request.urlretrieve('https:'+src[i], f"{name[i][1:5]}.jpg")在这里,我们在第二个for循环语句中加入了切片'[1:5]'来尝试解决问题,以下是代码运行结果。
切片法代码运行结果: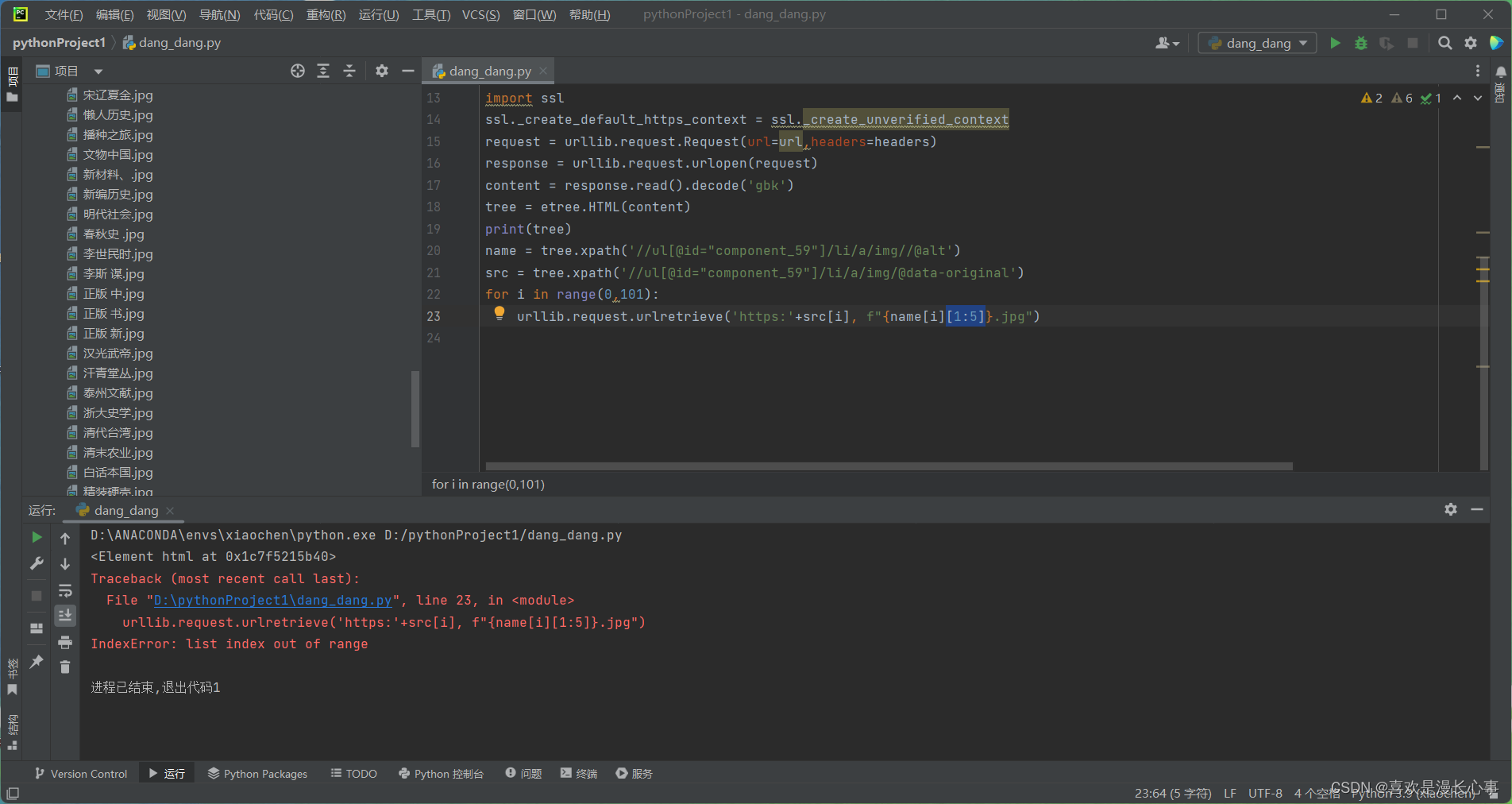 在这里我们可以看到代码成功的运行,但是该方法也存在一个非常明显的缺陷,即网页信息爬取不完整。
在这里我们可以看到代码成功的运行,但是该方法也存在一个非常明显的缺陷,即网页信息爬取不完整。
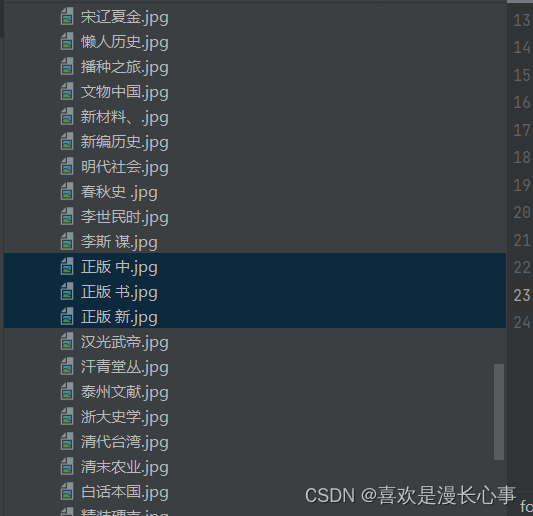
在这里,我们可以明显看到书籍的标题严重缺失,为了防止出现这种错误,我们可以通过尝试将非法符号替换为其他符号,而这种方式可以通过多种方法来实现。在这里笔者将演示‘re.sub’方法替换非法字符为下划线符号。以下是‘re.sub’方法演示:
re.sub方法代码:
import re
import urllib.request
from lxml import etree
for page in range(1,101):
if page == 1:
url = 'https://category.dangdang.com/cp01.36.04.01.00.00.html'
else:
url = f'https://category.dangdang.com/pg{page}-cp01.36.04.01.00.00.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'
}
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('gbk')
tree = etree.HTML(content)
print(tree)
name = tree.xpath('//ul[@id="component_59"]/li/a/img//@alt')
src = tree.xpath('//ul[@id="component_59"]/li/a/img/@data-original')
for i in range(0,101):
urllib.request.urlretrieve('https:'+src[i], f"{name[i]}.jpg")re.sub方法代码运行结果: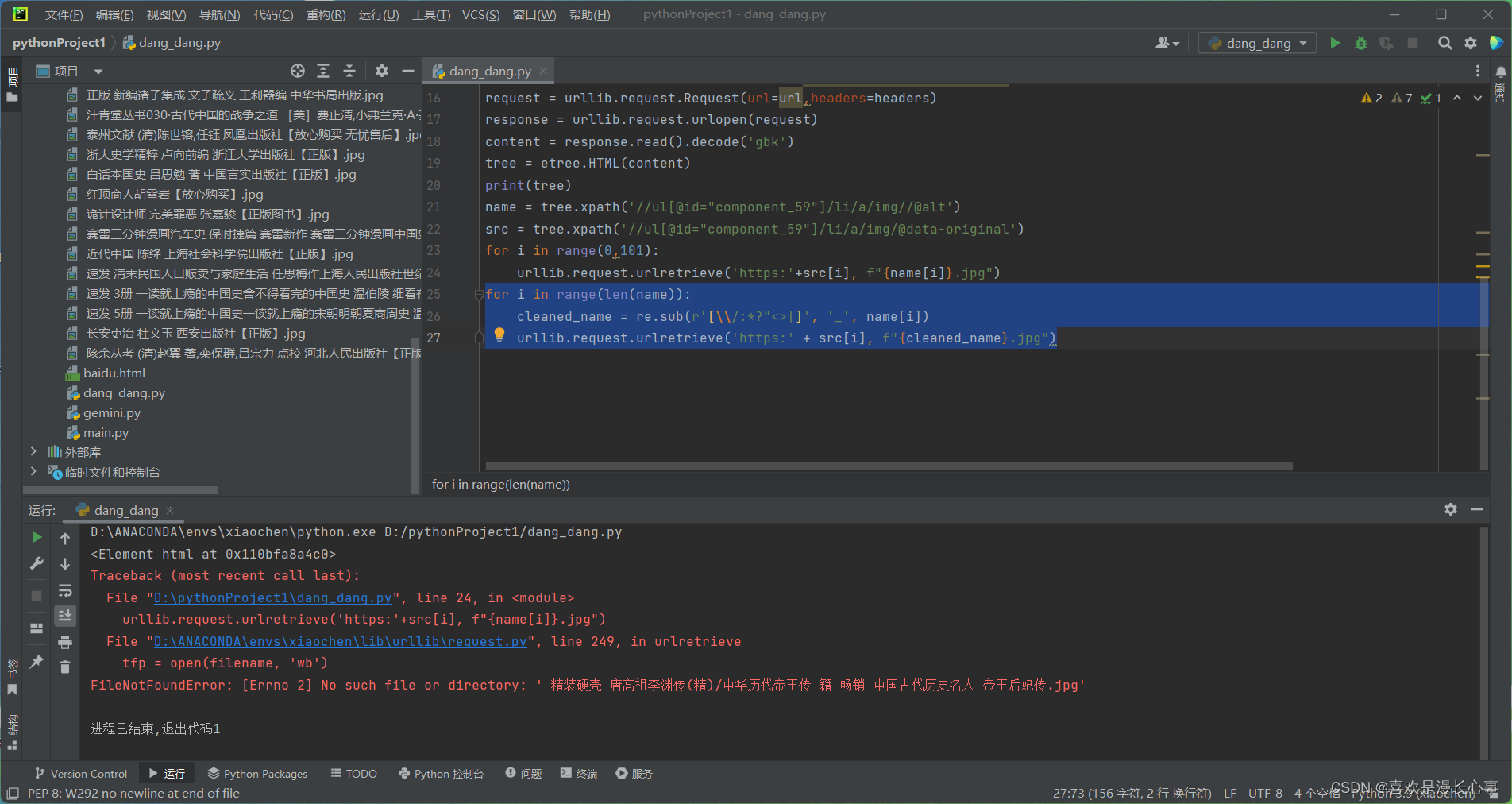
在这里出现的一个新的错误,是与非法符号同类型的错误:
![]() 在re.sub语句中加入空格替换就可以解决:
在re.sub语句中加入空格替换就可以解决:
新代码:
import re
import urllib.request
from lxml import etree
for page in range(1,101):
if page == 1:
url = 'https://category.dangdang.com/cp01.36.04.01.00.00.html'
else:
url = f'https://category.dangdang.com/pg{page}-cp01.36.04.01.00.00.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'
}
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('gbk')
tree = etree.HTML(content)
print(tree)
name = tree.xpath('//ul[@id="component_59"]/li/a/img//@alt')
src = tree.xpath('//ul[@id="component_59"]/li/a/img/@data-original')
for i in range(0,101):
urllib.request.urlretrieve('https:'+src[i], f"{name[i]}.jpg")
for i in range(len(name)):
cleaned_name = re.sub(r'[\\/:*?"<>| ]', '_', name[i])
urllib.request.urlretrieve('https:' + src[i], f"{cleaned_name}.jpg")新代码运行结果: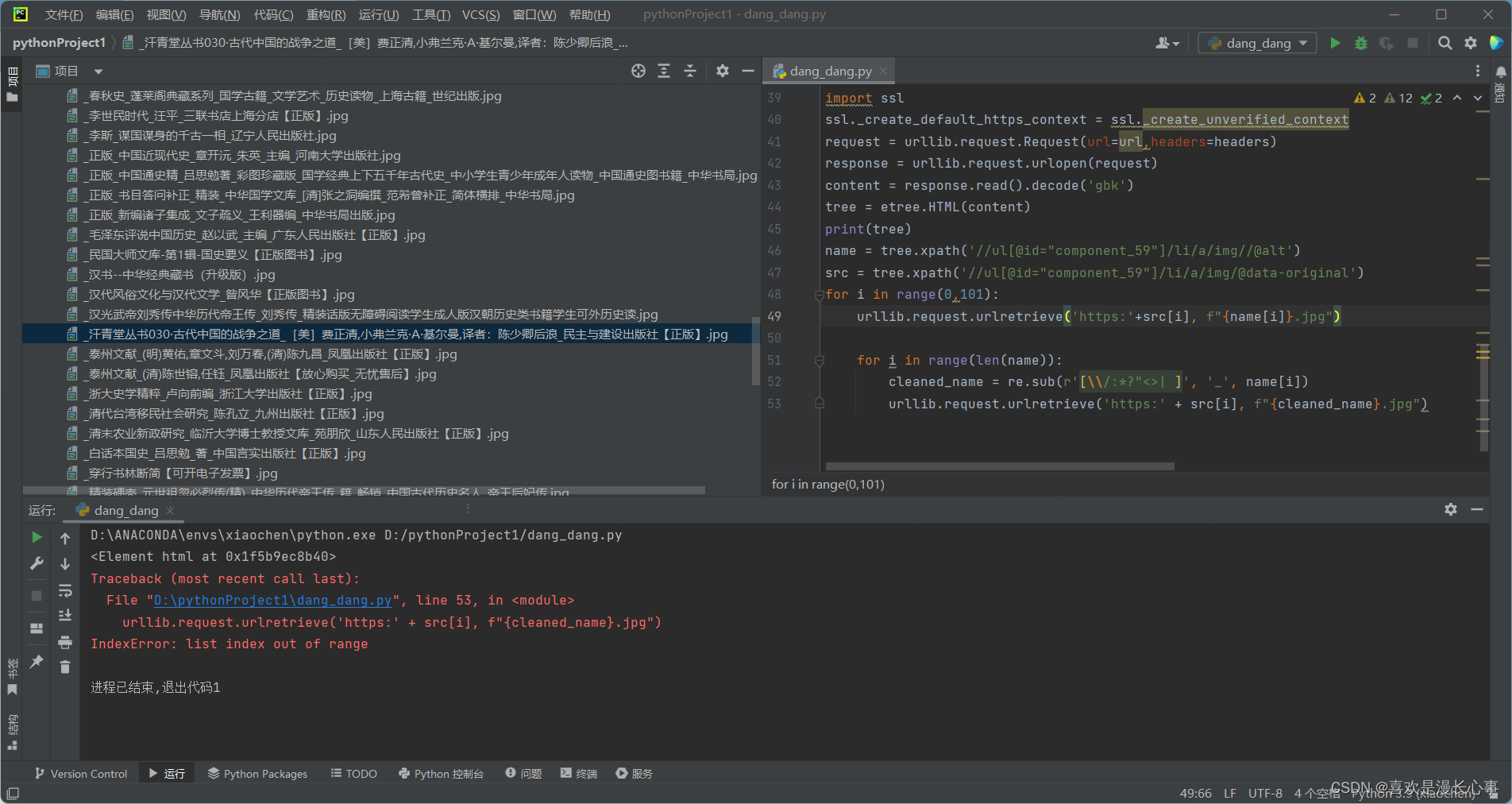
这里可以看到代码运行成功,并且数据信息也是完整的。所有的非法字符都被替换为了下划线符号,当然为了后续数据处理可以将不同的非法字符替换为对应的合法符号,笔者在这里不再展示。
以上就是本文所有内容,演示网站为:中国通史_中国史类图书【推荐 正版 价格】_图书-当当网 (dangdang.com)
仅做学习用途,不做商业用途。
如有错漏请读者斧正。















 4214
4214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









