






感谢关注,上一章地址(顺序必看从上往下):
vmware(大数据)虚拟机网络配置(学不会打死我)-CSDN博客
linux下mysql5.7安装(学不会我出门踩屎)-CSDN博客
什么是Hadoop的伪分布模式?
Hadoop的伪分布模式是一种配置方式,用于在单个节点上模拟一个完整的Hadoop集群环境。在伪分布模式下,Hadoop的各个组件(如HDFS、YARN、MapReduce等)会在同一台机器上运行,但会使用多个进程来模拟分布式环境的各个角色。这种模式通常用于开发、测试或学习目的,可以在单个节点上进行Hadoop应用程序的开发和调试,而无需真正的集群环境。
在伪分布模式下,通常会在单个节点上运行以下核心组件:
1.HDFS:模拟分布式文件系统,将数据存储在单个节点的本地文件系统上。
2.YARN:资源管理器,用于管理集群资源,并为作业分配任务。
3.MapReduce:分布式计算框架,用于处理大规模数据的计算任务。
虽然在伪分布模式下只使用了一台机器,但通过模拟多个角色的多个进程,使得开发者能够体验到类似于真实集群环境的开发和测试体验,同时能够在单个节点上完成整个Hadoop生态系统的操作和调试。
缺点:
资源限制: 在单个节点上运行整个Hadoop生态系统会受到物理资源(如CPU、内存、磁盘)的限制。因此,无法模拟真实的集群规模和性能。
不真实的网络通信: 在伪分布模式下,所有的组件都在同一台机器上运行,而真实的分布式系统涉及多台计算机之间的网络通信。因此,在伪分布模式下无法测试真实的网络通信情况。
不适用于性能测试: 由于受到资源限制和单节点环境的限制,伪分布模式并不适合进行大规模的性能测试。在伪分布模式下,无法模拟出真实集群环境下的性能表现。
不适合真实负载测试: 由于伪分布模式无法模拟出真实的集群环境,因此在此模式下进行的负载测试结果可能并不准确,无法反映出在实际集群环境中的表现。
Hadoop的文件与重要组件
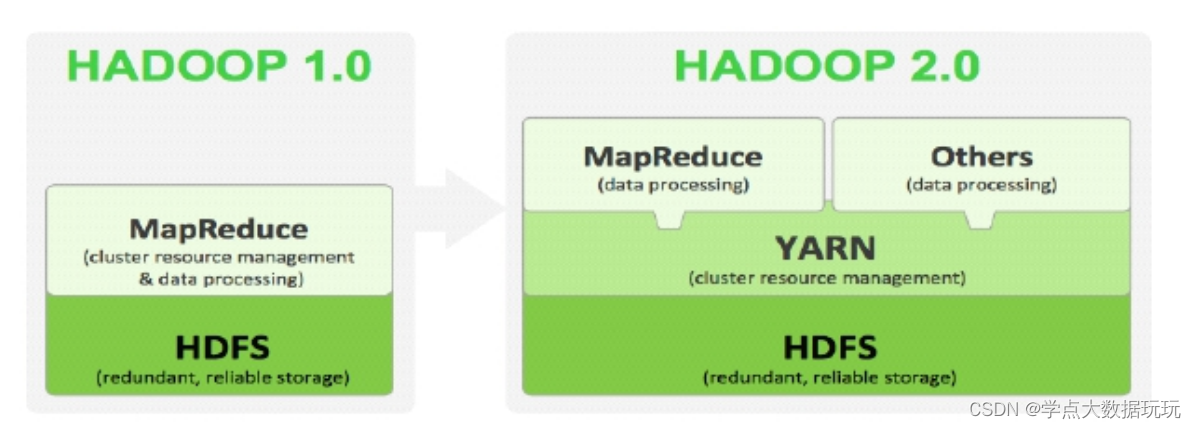
hadoop通用组件 - Hadoop Common
包含了其他hadoop模块要用到的库文件和工具
分布式文件系统 - Hadoop Distributed File System (HDFS)
运行于通用硬件上的分布式文件系统,高吞吐,高可靠
资源管理组件 - Hadoop YARN
于2012年引入的组件,用于管理集群中的计算资源并在这些资源上调度用户应用。
分布式计算框架 - Hadoop MapReduce
用于处理超大数据集计算的MapReduce编程模型的实现。
在搭建是那些文件的意义
-
bin目录:
hadoop: 启动Hadoop命令行工具。hdfs: Hadoop分布式文件系统命令行工具。yarn: Hadoop资源管理系统命令行工具。- 其他一些辅助脚本和工具,如启动/停止Hadoop服务的脚本等。
-
etc目录:
hadoop-env.sh: Hadoop环境配置文件,可以设置Java环境变量等。core-site.xml: Hadoop核心配置文件,配置Hadoop核心功能。hdfs-site.xml: HDFS配置文件,配置HDFS相关参数。mapred-site.xml: MapReduce配置文件模板,用于配置MapReduce相关参数。yarn-site.xml: YARN配置文件,配置YARN资源管理器相关参数。
-
lib目录:
- 包含Hadoop运行所需的JAR文件,以及Hadoop依赖的其他库文件。
-
sbin目录:
- 包含一些Hadoop的启动和停止脚本,如
start-dfs.sh用于启动HDFS,start-yarn.sh用于启动YARN等。
- 包含一些Hadoop的启动和停止脚本,如
-
share目录:
- 包含一些Hadoop共享资源,如示例程序、配置示例等。
-
logs目录:
- Hadoop运行时的日志文件存放位置。
Hadoop的伪分布式搭建
打开虚拟机,拍摄快照,方便我们对Hadoop的搭建方式进行回溯
拍玩快照后打开虚拟机,连接xshell
使用xftp导入Hadoop安装包
解压Hadoop并改名为hadoop

tar -zxvf hadoop包名
mv hadoop包名 hadoop
这样就能是解压好了(环境变量在搭建linux的时候已经配了,连接为:zookeeper平台搭建(学不会干死我)-CSDN博客)
根据配置文件,我们开始修改hadoop的配置文件了
进入hadoop文件配置的目录
cd /opt/hadoop/etc/hadoop/
hadoop-env.sh (指定java目录)
vim hadoop-env.sh
JAVA_HOME=/opt/java
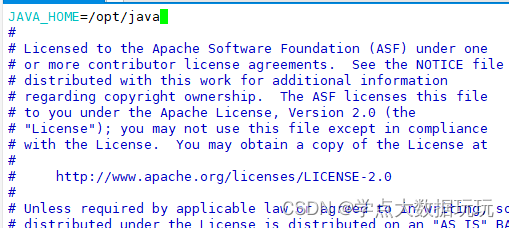
core-site.xml(hadoop核心配置文件)
vim core-site.xml
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/data</value>
</property>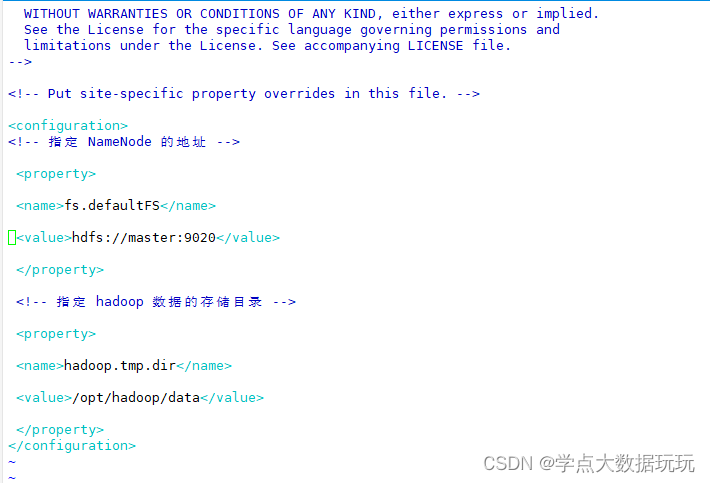
hdfs-site.xml
vim hdfs-site.xml <!--web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!--web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:9868</value>
</property> 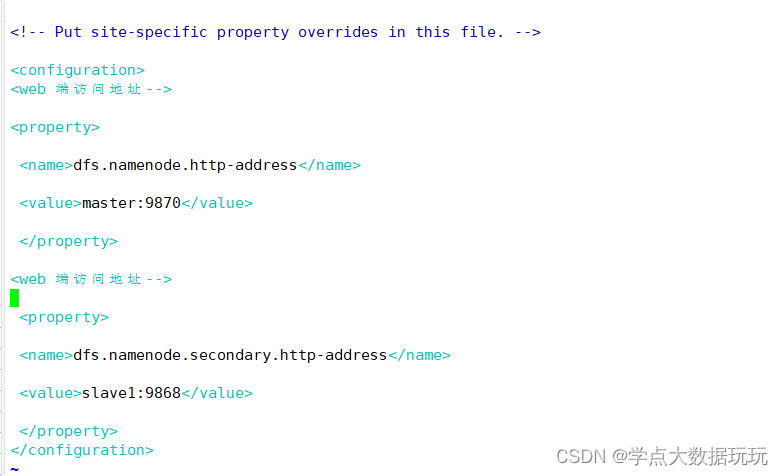
yarn-site.xml
vim yarn-site.xml<!--指定shuffle的洗牌模式,shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property> 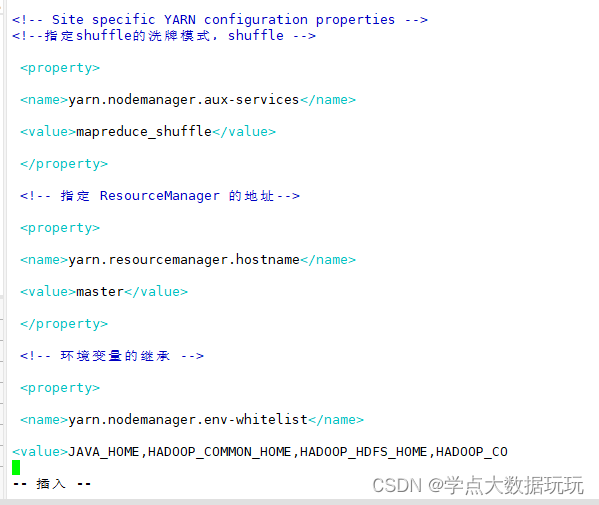
mapred-site.xml
vim mapred-site.xml <!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> 
进入sbin启动目录,在3.x后面都要去指定hdfs用户和yarn的用户
cd /opt/hadoop/sbin/
vim start-dfs.sh 在顶部写下
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root 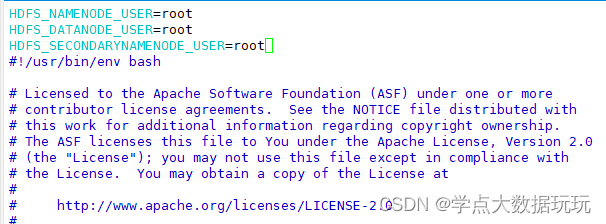
start-dfs.sh 是hdfs的启动脚本,同理我们需要修改stop-dfs.sh,一样的修改方法
然后修改start-yarn.sh,同理也要修改stop-yarn.sh的文件
在文件顶部加上
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root 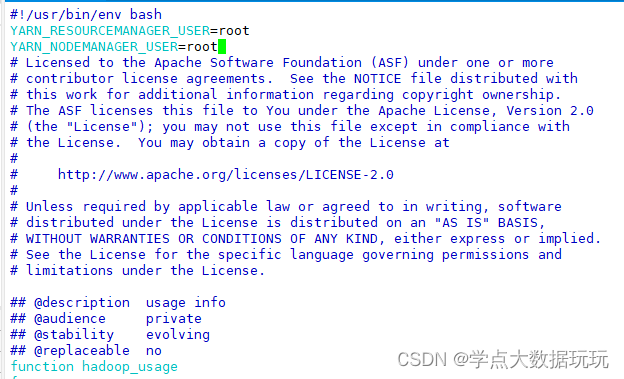
修改完后启动
start-all.sh
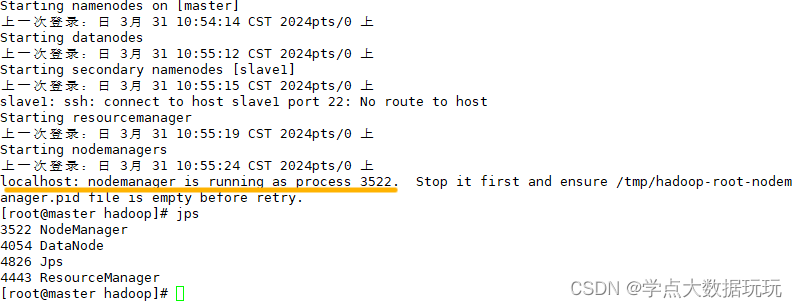
出现localhost,伪分布搭建成功















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









