






QQ导出聊天记录
核心目标是找到消息管理器,通过消息管理器查看聊天记录并保存文件;建议是保存成txt文件,方便查看和解析清理;
示例
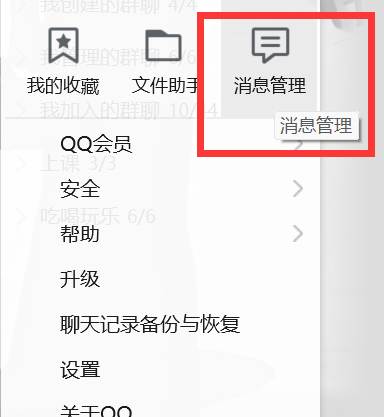
1.点击QQ左下角三条横线

2.选择消息管理打开消息管理器
3.在消息管理器选择需要导出的聊天记录,右键点击导出
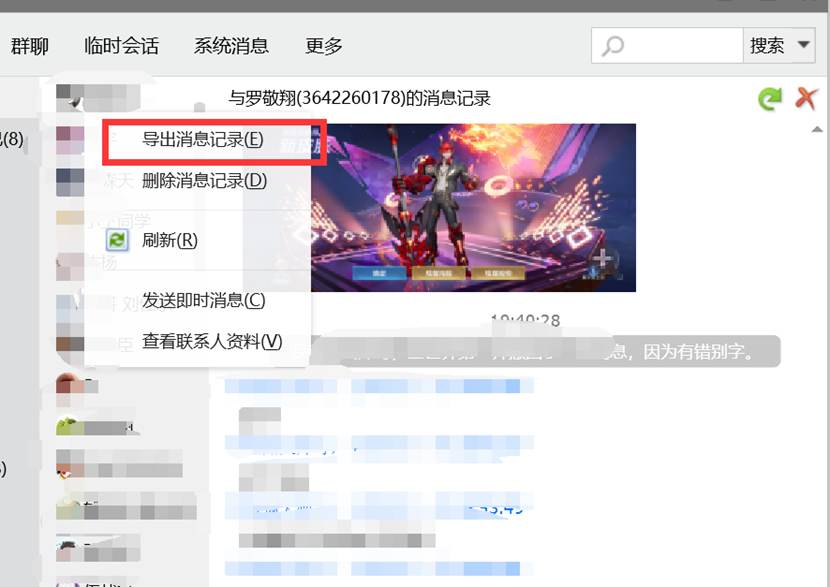
4.保存文件到需要的目录,推荐选择txt文件,最终文件例如下面

聊天记录数据分析
保存的聊天记录有下面的特点:
- 开头8行一般聊天记录头,记录分组、对象
- 每条聊天记录由时间、对象、消息内容组成;消息对象可能为空。
- 每条消息记录的消息对象一般为保存或发送消息时的qq昵称、群昵称,他人的话也可能为备注
- 表情、图片等以[图片]、[表情]、[生气]等格式存在于聊天记录

处理数据
在我的的项目中,我需要把聊天记录保存成jsonl文件,一行表示一次来回的对话,且聊天角色只能是固定的一个角色例如“我”和别人,例如:
{"conversations": [{"role": "user", "content": "hi"}, {"role": "assistant", "content": "Hello! I am MiniMind, an AI assistant developed by Jingyao Gong. How can I assist you today?"}]}
{"conversations": [{"role": "user", "content": "hello"}, {"role": "assistant", "content": "Hello! I am MiniMind, an AI assistant developed by Jingyao Gong. How can I assist you today?"}]}
由txt文件转化成需要的jsonl文件,基本需要实现下面的功能:
- 匹配聊天对象,区分别人和‘我’
- 处理无效的聊天内容,对于单纯一条[图片]、[表情]又或者文件接收、消息撤回等内容,并不是需要的有效的聊天内容,需要抛弃这些内容。
- 区分话题,对于不同的上下文、聊天话题需要进行区分隔离
- 内容合并,由于需要一来一回的聊天内容,对于同一个人的连续内容需要进行合并
- 单条聊天内容时间、对象、内容的提取
- 全部内容的提取与写入
下面是针对各个功能的解决方法
身份识别匹配
建立一个全局集合变量,可以是别人也可以是自己,再捕获到对象时根据是否在集合中来判断属于别人还是自己

无效内容过滤
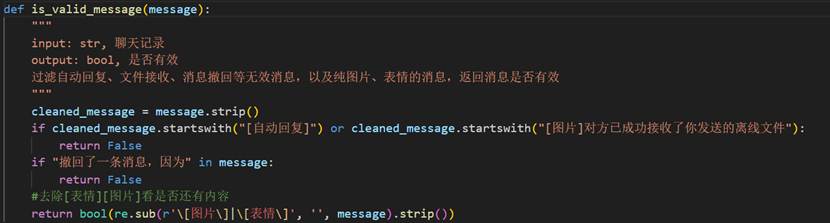
通过正则表达式,如果以’[自动回复]’、‘[图片]对方已成功接收了你发送这样开头的说明是系统消息,内容中存在‘撤回了一条消息,因为’的说明是消息撤回,除去[图片][表情]后为空的说明是纯表情/图片内容,dou’ke’shi’we 无效内容,用一个函数来判断是否有效即可
话题上下文分割
话题的上下文分割较难,比较合理的方法应该是使用NLP进行处理,但是这样成本太高,我的方法是设置一个时间,如果两条消息时间间隔较大,则认为属于不同的上下文对话。
连续对话合并
对于时间间隔较短的、连续同一个人的对话内容,需要进行合并
元数据精准提取
读取单条聊天记录时,需要读取消息头获取时间、消息对象,然后继续向下直到遇到新的消息头来读取聊天内容,不能简单读取一行,因为又是消息的发送可能一次消息就有刻意的换行发送。
一个MSG对象来存储消息,其可以视为一个没有方法只有属性的类

需要一个函数来辅助试探下一行:
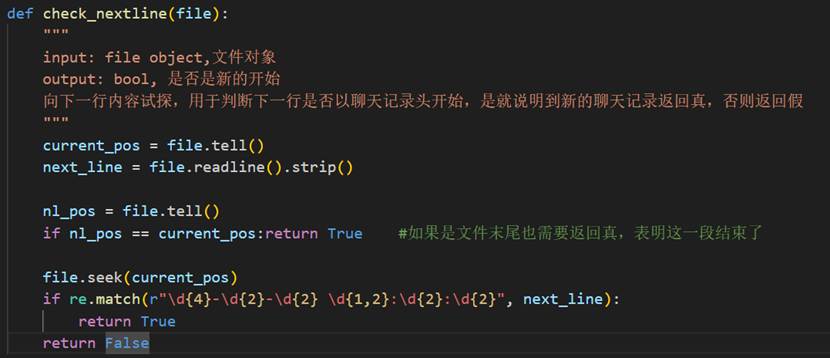
这个函数会先记录当前指针位置,跳转下一行后如果确实属于消息头,就回退指针,防止下一次调用readline()出问题。
全量数据导出。
数据导出时的基本逻辑应该是:
先读取第一条聊天为last_msg,随后开始读取循环:
每次读一条消息为cur_msg,然后进行如下判断
- 时间间隔是否超过设定的话题间隔?
如果是,说明当前话题结束,把上一条消息last_msg加入列表,可以把内容写入并清空话题消息记录表
- 是否为同一角色的消息?
如果是同一角色,需要合并内容,更新cur_msg =last_msg+cur_msg
- 都不是,及为正常来回对话
换人了,需要把上一条消息加入消息列表
最后,都要把last_msg = cur_msg完成内容的更新
退出机制:
如果cur_msg读不到新的内容为空了需要结束程序break,且需要把最后一条last_msg加入消息列表后写入文件;
跳过机制:
如果读到的cur_msg属于无效内容,则直接跳过,读取下一条内容
下面是源码
import re
from collections import namedtuple
from datetime import datetime
import json
import os
#MYNAME集合来存储自己的QQ名称,方便识别对话双方
MYNAME = {}
#保存信息记录
Msg = namedtuple('Message', ['time', 'role', 'message'])
def read_chattingContact(file):
"""
input: file object
output: str, 联系人名称
读取聊天记录头,获取联系人名称返回并跳到正式聊天记录前
"""
while True:
line = file.readline().strip()
if line.startswith("消息对象:"):
contact = line.split(":")[1].strip()
if check_nextline(file):break #读到开始有消息
return contact
def is_valid_message(message):
"""
input: str, 聊天记录
output: bool, 是否有效
过滤自动回复、文件接收、消息撤回等无效消息,以及纯图片、表情的消息,返回消息是否有效
"""
cleaned_message = message.strip()
if cleaned_message.startswith("[自动回复]") or cleaned_message.startswith("[图片]对方已成功接收了你发送的离线文件"):
return False
if "撤回了一条消息,因为" in message:
return False
#去除[表情][图片]看是否还有内容
return bool(re.sub(r'\[图片\]|\[表情\]', '', message).strip())
def extract_datetime_and_name(input_str):
"""
input: str, 单条聊天头
output: datetime, str, 聊天记录时间和名称
提取单条聊天的时间和讲话人名称分下面情况:
1.正确提取时间和名字
2.系统的撤回、接收文件等消息,只有时间没有名字,返回时间和空名字
3.读到最后一行了,返回两个none,说明文件结束了
"""
# 正则表达式匹配时间和名字
pattern = r"(\d{4}-\d{2}-\d{2} \d{1,2}:\d{2}:\d{2})\s*(.*)"
match = re.match(pattern, input_str, flags=re.UNICODE)
if match:
# 提取时间和名字
time_str = match.group(1)
name = match.group(2).strip() # 如果名字为空则返回空字符串
# 将时间字符串转换为 datetime 对象
try:
time_obj = datetime.strptime(time_str, "%Y-%m-%d %H:%M:%S")
except ValueError:
print(f"时间格式错误: {time_str}")
return None, None
return time_obj, name
else:
print("无法匹配输入格式,文件可能结束")
return None, None
def check_nextline(file):
"""
input: file object,文件对象
output: bool, 是否是新的开始
向下一行内容试探,用于判断下一行是否以聊天记录头开始,是就说明到新的聊天记录返回真,否则返回假
"""
current_pos = file.tell()
next_line = file.readline().strip()
nl_pos = file.tell()
if nl_pos == current_pos:return True #如果是文件末尾也需要返回真,表明这一段结束了
file.seek(current_pos)
if re.match(r"\d{4}-\d{2}-\d{2} \d{1,2}:\d{2}:\d{2}", next_line):
return True
return False
def read_message(file,contact):
"""
input: file object,文件对象; contact,联系人名称
output: Msg, 聊天记录信息,记录时间、角色、消息内容
读取当天聊天记录,返回Msg对象
"""
#读取时间和角色名称
time_obj, name = extract_datetime_and_name(file.readline().strip())
if time_obj is None and name is None: return None #文件终止
#读取消息内容
message = ""
#合并多行消息
while True:
line = file.readline().strip()
if check_nextline(file):break # 如果下一行是新的开始,结束读取
message += line + "\n"
name = contact if name not in MYNAME else '我'
#print(f"[{name}] {message}")
return Msg(time_obj, name, message)
def encryption(name):
"""
input: name, 角色名称
output: str, 加密后的角色名称
简单加密
"""
if name != "我":return "对方"
return name
def write_json(filename,content_list):
"""
input: filename, 输出文件名; content_list, 聊天记录列表
output: None
单轮聊天记录写入,将聊天记录列表转换为JSON格式并写入文件
"""
# 将元组列表转换为字典格式
formatted_data = [{"role": role, "content": content} for role, content in content_list]
# 将字典数据写入 JSON 文件
with open(filename, 'w', encoding='utf-8') as f:
json.dump(formatted_data, f, ensure_ascii=False, indent=4)
def new_write_json(filename,content_list,force_me_first=False):
"""
input: filename, 输出文件名; content_list, 聊天记录列表; force_me_first, 是否强制把“我”放在第一条消息前面
output: None
单轮写入,每次来回写成一段;如果force_me_first为True,则强制把“我”放在第一条消息前面
"""
if force_me_first:
if content_list[0][0] != "我":
content_list = content_list[1:]
with open(filename, 'a', encoding='utf-8') as file:
# 处理每一对话
for i in range(0, len(content_list) - 1, 2): # 步长为2,确保每对话是成对的
conversation = [
{"role": encryption(content_list[i][0]), "content": content_list[i][1]},
{"role": encryption(content_list[i+1][0]), "content": content_list[i+1][1]}
]
json.dump({"conversations": conversation}, file, ensure_ascii=False)
file.write("\n")
def read_chattingRecord(file,output_name,me_first=False):
"""
input: file object,文件对象; output_name,输出文件名;me_first,是否强制把“我”放在第一条消息前面
output: None
主读取函数,读取QQ聊天记录,将聊天记录转换为JSON(L)格式并写入文件
"""
with open(file, 'r', encoding='utf-8') as f:
content_list = []
contact = read_chattingContact(f)
# 读取第一条有效消息,确保正确开始读取聊天
while True:
last_msg = read_message(f,contact)
if is_valid_message(last_msg.message):break
while True:
msg_obj = read_message(f,contact)
#读不到新消息,结束读取,最后写入json
if msg_obj is None:
content_list.append((last_msg.role, last_msg.message))
if len(content_list) > 2:
new_write_json(output_name,content_list,me_first)
content_list = []
break
# 跳过无效消息
if not is_valid_message(msg_obj.message):continue
#读取逻辑:1.间隔大,视为新话题 2.角色相同,合并消息 3.角色不同,写入json(l),清空列表
if abs((msg_obj.time - last_msg.time).total_seconds()) > 6*3600: #时间间隔超过12小时,写入json,清空列表
content_list.append((last_msg.role, last_msg.message))
if len(content_list) > 2:
new_write_json(output_name,content_list,me_first)
print("new conv____________________\n\n")
content_list = []
elif msg_obj.role == last_msg.role: #角色相同,合并上一条消息并更新时间内容
msg_obj = Msg(msg_obj.time, last_msg.role, last_msg.message +msg_obj.message)
else:
content_list.append((last_msg.role, last_msg.message))
#更新上一条消息
last_msg = msg_obj
def clean_mefirst(input_filename):
"""
input: input_filename, 输入文件名
output: None
去除“我”放在第一条消息前面的聊天记录
"""
# 如果给定的是路径,获取文件名并生成新文件名
base_filename = os.path.basename(input_filename)
output_filename = f"new_{base_filename}"
# 如果是全路径,确保文件保存到相同的目录下
output_filepath = os.path.join(os.path.dirname(input_filename), output_filename)
with open(input_filename, 'r', encoding='utf-8') as infile, open(output_filepath, 'w', encoding='utf-8') as outfile:
for line in infile:
# 解析每一行的 JSON 数据
conversation_data = json.loads(line.strip())
# 检查每一行的第一个角色是否是“我”,如果是“我”,才保留这行
if conversation_data['conversations'][0]['role'] == '我':
# 如果是“我”,写入到新的文件
json.dump(conversation_data, outfile, ensure_ascii=False)
outfile.write('\n')
print(f"清洗后的文件已保存为: {output_filepath}")
def test():
output_name = 'output.jsonl'
read_chattingRecord('lll.txt',output_name)
if __name__ == "__main__":
#program setting:
MYNAME = {'AAA','BBB'}
directory = r"D:\QQbcackup\296_chattingRecords"
output_name = f'{os.path.basename(directory)}.jsonl'
if_me_first = True
if_clean_mefirst = False
for filename in os.listdir(directory):
if filename.endswith(".txt"):
filepath = os.path.join(directory, filename)
read_chattingRecord(filepath,output_name,if_me_first)
if not if_me_first and if_clean_mefirst:
clean_mefirst(output_name)
写入逻辑:
- 直接写入,不区分谁先谁后
- 强制话题由“我”先开始,可以让内容全部是“我”在前
- 斩杀法,直接把第一中方法得到的内容删除不是“我”先开始的内容

















 2364
2364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









