







目录
大数据的历史
“大数据”作为时下最火热的IT行业的词汇,随之而来的数据仓库、数据安全、数据分析、数据挖掘等等围绕大数据的商业价值的利用逐渐成为行业人士争相追捧的利润焦点。
对于“大数据”(Bigdata)研究机构Gartner给出了这样的定义。“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据”这个术语最早期的引用可追溯到apacheorg的开源项目Nutch。当时,大数据用来描述为更新网络搜索索引需要同时进行批量处理或分析的大量数据集。随着谷歌MapReduce和GoogleFileSystem(GFS)的发布,大数据不再仅用来描述大量的数据,还涵盖了处理数据的速度。
早在1980年,著名未来学家阿尔文·托夫勒便在《第三次浪潮》一书中,将大数据热情地赞颂为“第三次浪潮的华彩乐章”。不过,大约从2009年开始,“大数据”才成为互联网信息技术行业的流行词汇。美国互联网数据中心指出,互联网上的数据每年将增长50%,每两年便将翻一番,而目前世界上90%以上的数据是最近几年才产生的。此外,数据又并非单纯指人们在互联网上发布的信息,全世界的工业设备、汽车、电表上有着无数的数码传感器,随时测量和传递着有关位置、运动、震动、温度、湿度乃至空气中化学物质的变化,也产生了海量的数据信息。
一.大数据特征
大数据有四个主要特征:
1.Volume:数据量巨大
体量大是大数据区分于传统数据最显著的特征。一般关系型数据库处理的数据量在TB级,大数据所处理的数据量通常在PB级以上。
2.Variety:数据类型多
大数据所处理的计算机数据类型早已不是单一的文本形式或者结构化数据库中的表,它包括订单、日志、BLOG、微博、音频、视频等各种复杂结构的数据。
3.Velocity:速度快时效高
第三个特征是处理数据的速度快,时效性要求高。是大数据区分于传统数据的重要特征。在海量数据面前,需要实时分析获取需要的信息,处理数据的效率就是组织的生命。
4.Value:价值密度低
第四个特征时数据价值密度相对较低。如随着物联网的广泛应用,信息感知无处不在,信息海量但价值密度较低,如何通过强大的机器算法更迅速的完成数据密度的“提纯”,是大数据时代亟待解决的难题。
除以上四个主要特征之外我认为还有一个特征与我们生活息息相关---准确性
身处大数据时代我们每个人都应该有所发现,在我们日常上网冲浪时,大数据会精准把握我们每个人的感兴趣的方面,并推送相关作品;
例如:我们在刷抖音时,我们会发现刷着刷着就变成了我们喜欢的内容因此逐渐的从很快到慢慢的细品,因此让我们停留在刷视频上的时间变得越来越长,甚至有些时候你说的话也会被记录,你想看什么说出来,大数据也会帮你筛选出你喜欢的作品;同时在网上购物时也会出现类似的现象,当你搜寻某件商品时,就会出来你想要的商品各式各样,任你挑选,即使下次登陆时,你会发现,推荐的都是你以前搜索过的商品。
二.大数据的结构
大数据的结构通常涉及数据的组织、存储、处理和分析等方面。在大数据架构中,数据结构可以分为以下几个层次:
1.数据源层:这是大数据架构的起点,包括各种数据输入源,如日志文件、传感器数据、社交媒体数据、交易记录等。这些数据源可能来自内部系统(如企业内部数据库)或外部系统(如互联网)。
2.数据存储层:在这一层,原始数据被收集并存储。数据存储可以是结构化的(如关系数据库),也可以是非结构化的(如Hadoop分布式文件系统HDFS)。数据湖(Data Lake)是一个流行的概念,它允许存储大量原始数据,这些数据可以是结构化的、半结构化的或非结构化的。
3.数据处理层:这一层涉及对存储的数据进行处理,以便于分析。处理过程可能包括数据清洗、转换、聚合等。数据处理可以是批处理(如使用Hadoop MapReduce)或实时处理(如使用Apache Storm或Apache Spark)。
4. 数据分析层:在这一层,处理后的数据被用于分析,以提取洞察和知识。分析可以是描述性的(总结过去发生了什么),预测性的(预测未来可能发生的事情),或规范性的(推荐行动方案)。分析工具可能包括SQL查询、数据挖掘算法、机器学习模型等。
5. 数据应用层:这是大数据架构的输出层,分析结果在这里被用于支持决策制定、业务流程优化、客户体验提升等。数据应用可以是BI(商业智能)报告、仪表板、移动应用等。
6. 数据管理层:这一层涉及数据的治理、安全、隐私保护和合规性。它确保数据的质量、一致性和可访问性,同时遵守相关法律法规。
在实际的大数据平台中,这些层次可能会有所重叠,而且不同的技术和工具可能会在多个层次中发挥作用。例如,Hadoop生态系统提供了一整套工具,从数据存储(HDFS)到数据处理(MapReduce、Spark)再到数据分析(Hive、Pig)的解决方案。此外,还有许多其他技术和平台,如NoSQL数据库、数据仓库、数据流处理系统等,它们共同构成了大数据的丰富结构。
三.结构化数据与非结构化数据的区别
1.结构化数据
结构化数据是指按照一定规则和格式组织数据,通常以表格、数据库或者其他类似的结构形式存储。它具有明确的数据类型和关系,可以通过行和列的方式进行访问和处理。结构化数据通常用于存储和管理大量的信息,例如企业的客户数据、销售记录、学生信息等。
在结构化数据中,数据以表格的形式呈现,每一行代表一个实例或记录,每一列代表一个属性或字段。每个属性都有特定的数据类型,例如整数、浮点数、字符串等。通过定义表格的结构和约束条件,可以确保数据的完整性和一致性。
结构化数据的优点包括:
1. 数据组织清晰:通过表格形式,数据之间的关系和结构清晰可见。
2. 数据查询方便:可以使用SQL等查询语言进行复杂的数据检索和分析。
3. 数据分析能力强:结构化数据可以进行统计分析、数据挖掘等操作,帮助发现隐藏在数据中的模式和规律。
4. 数据共享和集成性好:结构化数据易于共享和集成到不同的系统和应用中。
2.非结构化数据
非结构化数据是指没有明确定义格式和组织方式数据。与结构化数据相比,非结构化数据没有固定的表格、字段或关系,通常以自由文本、图像、音频、视频等形式存在。
非结构化数据的特点是多样性和复杂性。它可以包含各种类型的信息,如自然语言文本、社交媒体帖子、电子邮件、网页内容、音频录音、图像和视频等。这些数据通常不易于直接处理和分析,因为它们缺乏明确的结构和规范。
非结构化数据在现实生活中广泛存在,例如社交媒体上的用户评论、新闻文章、研究报告、医疗记录、传感器数据等。这些数据对于企业和组织来说具有重要的价值,因为它们包含了大量的信息和见解,可以用于洞察用户行为、市场趋势、舆情分析、科学研究等领域。
对于非结构化数据的处理和分析,通常需要借助一些技术和工具。例如,自然语言处理(NLP)可以用于处理文本数据,图像和视频处理技术可以用于分析图像和视频数据,音频处理技术可以用于处理音频数据等。此外,机器学习和深度学习等技术也可以应用于非结构化数据的分析和挖掘。
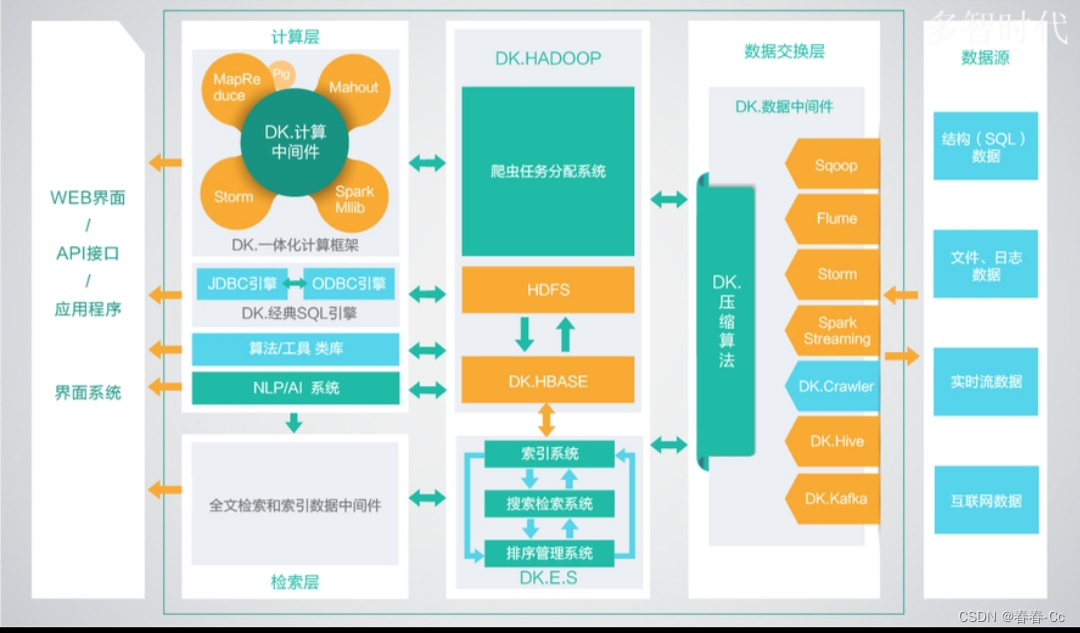
四.Hadoop生态圈组件
Hadoop生态圈包括多个组件,这些组件共同协作以支持大规模数据处理和分析。主要组件包括:
HDFS(Hadoop Distributed File System)。它是Hadoop的核心存储系统,提供高容错性和可扩展性,适合处理超大数据集。
MapReduce。这是一个编程模型,用于处理和生成超大数据集,它提供简单的编程接口,易于扩展,但随着大数据处理的需求增加,MapReduce的局限性也逐渐显现。
YARN(Yet Another Resource Negotiator)。它是Hadoop的资源管理器,负责集群资源的统一管理和调度。
Hive。它构建在Hadoop之上,提供类SQL查询语言,用于构建数据仓库和执行复杂的数据分析。
Pig。它是一种高级编程语言和平台,用于将复杂的数据处理流程转化为简单的脚本。
HBase。它是一个分布式、可扩展的列式数据库,适用于处理大规模结构化数据。
ZooKeeper。它是一个分布式协调服务,用于协调Hadoop集群中各个节点的行为。
Sqoop。它用于在Hadoop和关系型数据库之间进行数据传输。
Flume。它是一个分布式、可靠的系统,用于收集、汇聚和移动大规模日志数据。
Spark。它是一个高速大数据处理框架,支持内存计算和更广泛的数据处理模型。
Kafka。它是一个高吞吐量的分布式消息系统,用于发布和订阅流数据。
ES(Elasticsearch)。它是一个全文检索数据库,常与HBase结合使用,用于扩展索引功能。
这些组件共同构成了Hadoop生态圈,支持各种大数据处理和分析任务。
五.HDFS架构
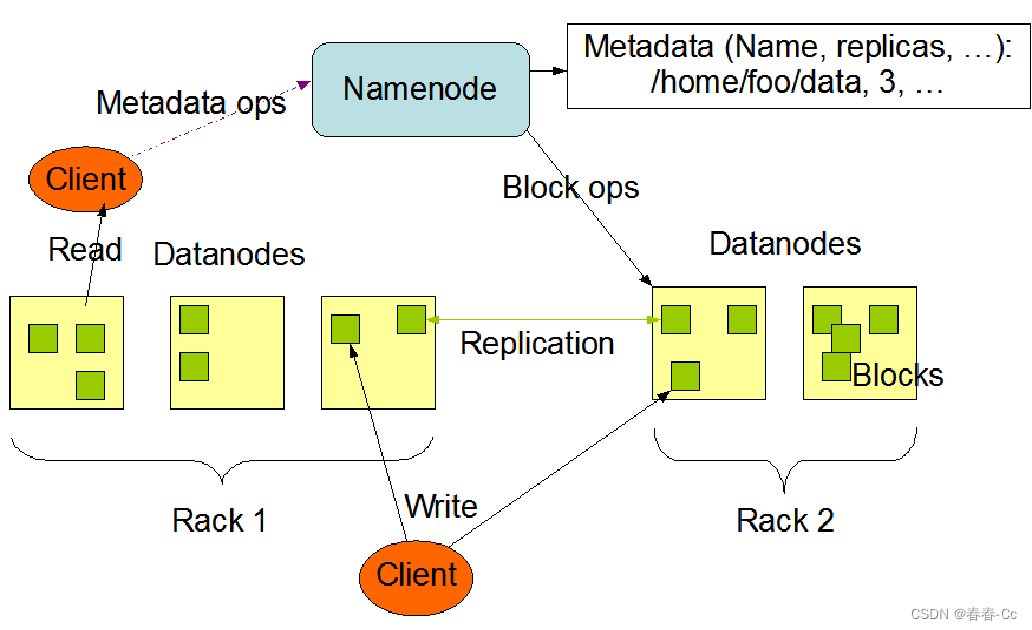
hdfs组成架构
架构主要由四个部分组成,分别为 HDFS Client、NameNode、DataNode 和Secondary NameNode。
1. Client:就是客户端,自己编写的代码+Hadoop API。其主要功能:
(1)进行文件切分。文件上传 HDFS 的时候,Client 将文件切分成一个一个的 Block,然后进行存储。
(2)当我们要查询一个文件时,与 NameNode 交互,获取文件的位置信息。
(3)与 DataNode 交互,读取或者写入数据。
(4)Client 提供一些命令来管理 HDFS,比如启动或者关闭 HDFS。
(5)Client 可以通过一些命令来访问 HDFS。
2. NameNode:就是 Master,它是一个主管、管理者。也叫 HDFS 的元数据节点。集群中只能有一个活动的 NameNode 对外提供服务。
(1)管理 HDFS 的名称空间(文件目录树);HDFS 很方便的一点就是对于用户来说很友好,用户不考虑细节的话,看到的目录结构和我们使用 Window 和Linux 文件系统很像。
(2)管理数据块(Block)映射信息及副本信息;一个文件对应的块的名字以及块被存储在哪里,以及每一个文件备份多少都是由 NameNode 来管理。
(3)处理客户端读写请求。
3. DataNode:就是 Slave。实际存储数据块的节点,根据 NameNode 下达的命令,DataNode 执行实际的操作。
(1)存储实际的数据块。
(2)根据NameNode的命令执行数据块的读/写操作。
4. Secondary NameNode:并非 NameNode 的热备。当 NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。它的功能如下:
(1)辅助 NameNode,分担其工作量。
(2)定期合并 Fsimage 和 Edits,并推送给 NameNode。
(3)在紧急情况下,可辅助恢复 NameNode。
Secondary NameNode 的工作与 HDFS 设计是相关的,主要针对元数据设计的。它维护了两种文件 Fsimage 和 Edits。
六.HDFS读的流程
HDFS(Hadoop Distributed File System)是一个分布式文件系统,它被设计用来在廉价的硬件上运行,并且能够提供高吞吐量的数据访问。HDFS的读取流程大致可以分为以下几个步骤:
1. 客户端请求:用户或者应用程序通过HDFS客户端发起读取文件的请求。
2. NameNode查询:客户端首先会联系NameNode来获取文件的位置信息。NameNode存储了整个文件系统的元数据,包括文件和目录信息、文件的块(block)信息以及块所在的DataNode位置等。
3. 获取数据块位置:NameNode响应客户端请求,提供文件的数据块信息以及包含这些数据块的DataNode地址。
4. 与DataNode通信:客户端根据从NameNode获取的信息,直接与存储有文件数据块的DataNode进行通信。如果文件数据块被复制到了多个DataNode上,客户端会优先选择最近的DataNode进行读取。
5.数据传输:DataNode将数据块通过网络传输给客户端。在传输过程中,客户端可能会同时从多个DataNode读取数据,以提高读取速度。
6. 数据合并:由于HDFS的数据块可能会被分散在多个DataNode上,客户端需要将这些数据块合并,以恢复成完整的文件内容。
7. 读取完成:客户端接收到所有必要的数据块后,读取操作完成。
8. 错误处理:如果在读取过程中出现错误,比如DataNode宕机或者网络问题,HDFS会尝试从其他复制的块中读取数据,以确保数据的可靠性。
HDFS的读取流程设计使得它非常适合大规模数据集的批量处理,因为它可以并行地从多个DataNode读取数据,从而实现高吞吐量。同时,通过数据块的复制和分布式存储,HDFS也提供了一定程度的容错能力。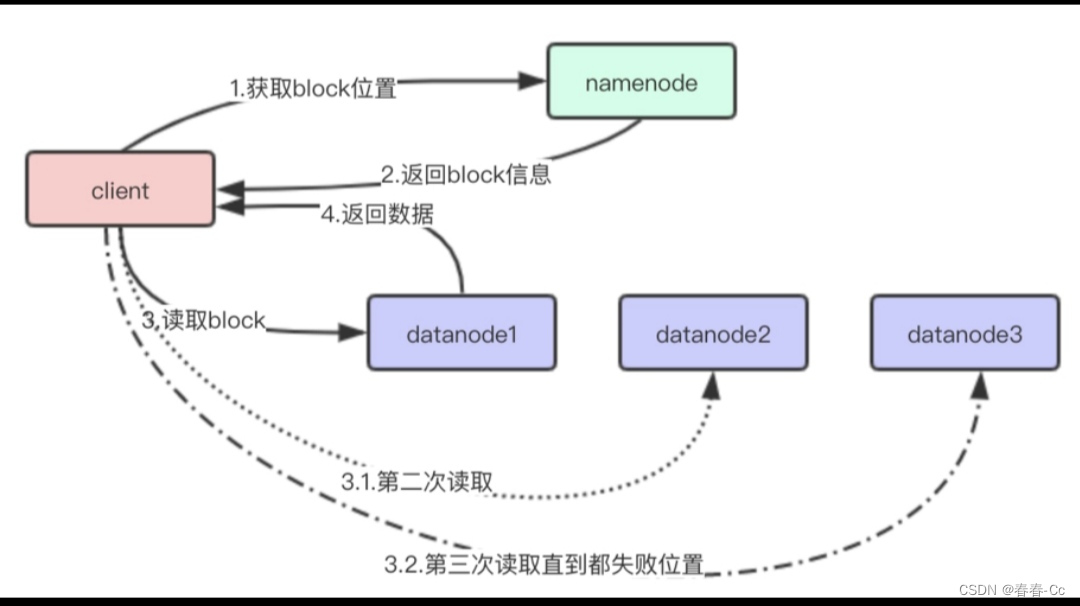















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









