






![]()
目录
![]()
一、现象引入
在之前谈到C++中类的大小的时候涉及到一个概念,即"内存对齐",今天我们来探讨一下具体什么是"内存对齐"。
现在我们可以先观察两组代码及其运行结果:
#include <stddef.h>
#include <stdio.h>
typedef struct {
char a; // 1 byte
int b; // 4 bytes
short c; // 2 bytes
} AlignedStruct;
int main() {
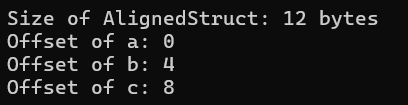
AlignedStruct s;
printf("Size of AlignedStruct: %zu bytes\n", sizeof(s));
printf("Offset of a: %zu\n", offsetof(AlignedStruct, a)); //a地址偏移量
printf("Offset of b: %zu\n", offsetof(AlignedStruct, b)); //b地址偏移量
printf("Offset of c: %zu\n", offsetof(AlignedStruct, c)); //c地址偏移量
return 0;
}
#include <stdio.h>
#include <stddef.h>
#pragma pack(push, 1) // 设置结构体的对齐方式 结构体的成员以 1 字节对齐
typedef struct {
char a; // 1 byte
int b; // 4 bytes
short c; // 2 bytes
} AlignedStruct;
#pragma pack(pop) // 恢复默认的对齐方式
int main() {
AlignedStruct s;
printf("Size of AlignedStruct: %zu bytes\n", sizeof(s));
printf("Offset of a: %zu\n", offsetof(AlignedStruct, a)); //a地址偏移量
printf("Offset of b: %zu\n", offsetof(AlignedStruct, b)); //b地址偏移量
printf("Offset of c: %zu\n", offsetof(AlignedStruct, c)); //c地址偏移量
return 0;
}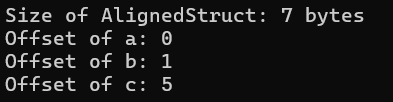
我们可以观察到同样的结构体,只是因为多了两行代码就改变了结构体的大小和结构体中变量的内存偏移量。这便是因为两组代码应用了不同的“对齐参数”,在第一组中默认的“对齐参数”是“4”字节,在第二组中,我们手动将对其参数改为了“1”字节。
如图,这就是两组数据在内存中不同的存储方式。每个方框代表一字节大小的存储空间,黑色括号标注了变量占用的空间,红色括号标注了变量实际所占空间。
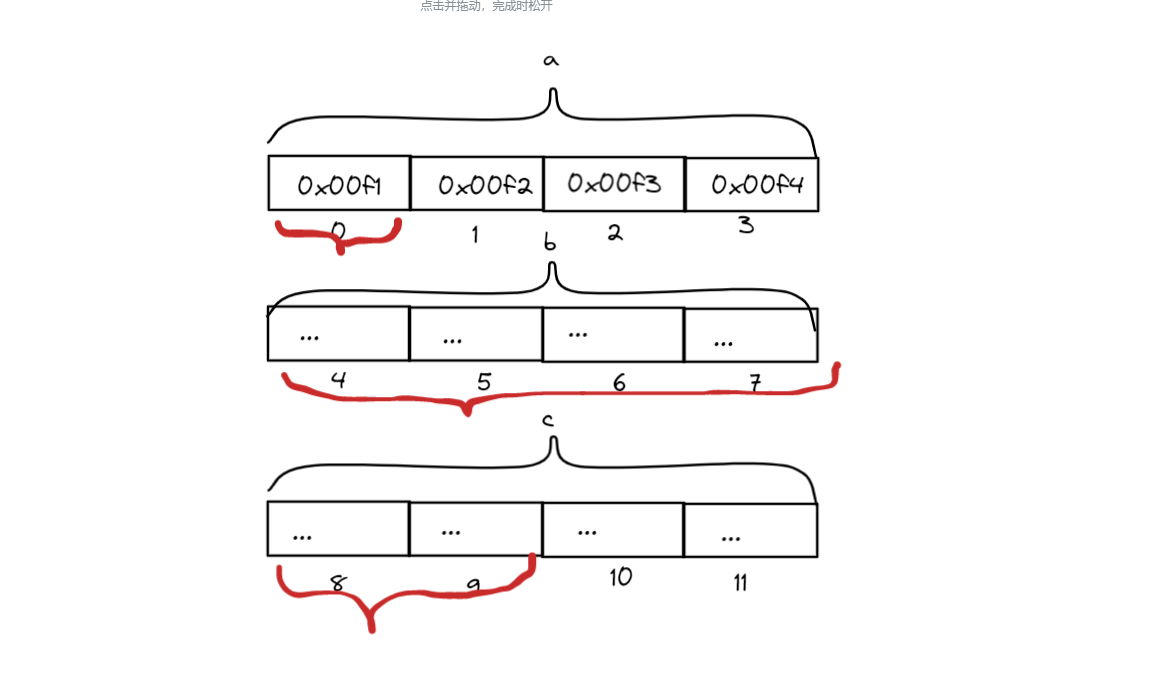
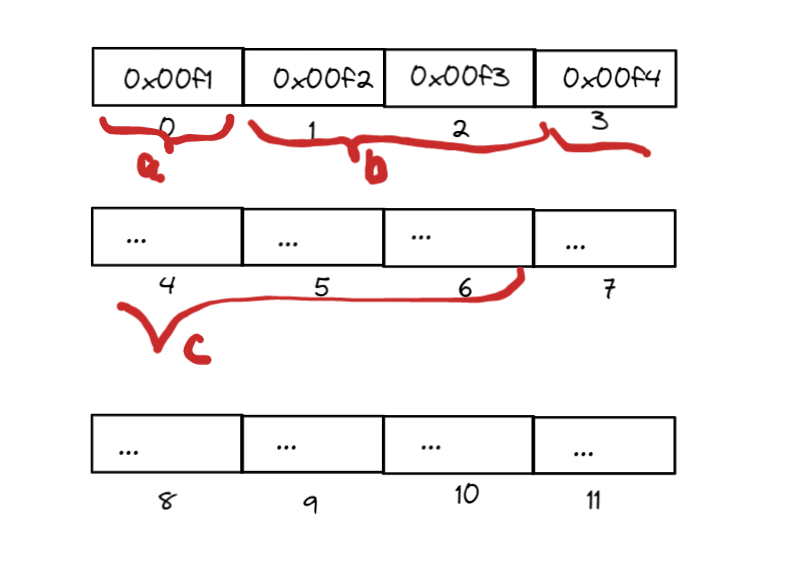
[图-结构体中变量的内存分布]
二、概念辨析
在C++中,内存对齐是指将数据元素的存储地址调整为特定边界的过程,这样做可以提高内存访问的效率。
三、内存对齐规则
内存对齐遵循一定规则:
- 第一个结构成员在对于结构体偏移量为0的地址处。
- 该结构体成员变量地址会统一到“对齐数”的整数倍的地址处(即使变量大小为4字节,如果对齐数是3字节的话,该结构体成员大小也会变为3的整数倍“6”)。
- 结构器总大小为:最大对齐数的整数倍。
以上规则都和“对齐数”有关吗,那么这个“对齐数”的大小该如何确定呢?一般情况下,所有变量类型中最大的一个,和编译器设置的默认对齐参数比较大小,取二者中较小的一个,即
struct test{
char b; //1
int a; //4
long c; //4 或 8
long long d; //8
};
对齐数 = min(sizeof(结构体中最大类型), sizeof(默认对齐参数));此处我们假设结构体中最大变量是char类型的,编译器的默认对其参数是4字节,那么对齐数就是1字节,如果结构体中有long long类型的话,那么对齐数将会是8字节。
4、如果出现了嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
我们接下来看一下实例:
struct B {
long long a; // 8 bytes
};
struct A {
int x; // 4 bytes
char y; // 1 byte
struct B b; // 8 bytes
}; 由于结构体B中只有一个long long类型的成员,因此结构体B的对齐数通常将是long long的对齐数是8字节。结构体A包含一个整型变量(int)、一个字符型变量(char)和一个结构体B类型的成员。我们已经知道结构体B的对齐数是8字节。然而,由于结构体A中包含一个对齐要求更高的成员(即结构体B),结构体A的整体对齐数将至少与结构体B的对齐数相同。因此,在不考虑编译器默认的对齐数的情况下,结构体A的对齐数也将是8字节。
对齐数 = 编译器默认的一个对齐数与该结构体成员中最大值中二者的较小值
VS中默认为8字节
对于实际大小,往往根据不同情况编译器会做出不同选择,但不论结果如何,最终目的还是要提高整体效率;
class A
{
long a1;
short a2;
int a3;
int* a4;//64位机器下是8字节,32位机器下是4字节
};
int main(void)
{
std::cout << sizeof(A) << std::endl;//结果是24,所以这里对齐数选择了4
//在对齐数是4的情况下,可以做到空间利用和读取次数的总和提高
return 0;
}四、缘由探究
到此我们已经理解了什么是内存对齐,但是为什么要这样操作呢?我们通过图片可以很容易的观察出如果对齐数是1字节,那么对于内存的利用将会十分高效,省去了很多不必要的浪费,这就是很多同学的疑问。除了空间之外我们还要考虑到数据读取速度的问题。
(1)计算机读取规则的限制:
计算机在读取数据时通常为固定的大小,这样就导致及时我们将数据紧密排放,但是计算机在读取时仍然是这样的场景:
以第一组实验为例,在读取a时仍然是先读取了四个字节的数据,然后提取出来第一个字节的内容,在读取第二个数据b时仍然是读取前4个字节的数据然后提取出来中间两个字节的数据,在读取第三个数据就更复杂了,要提取两次数据然后再进行一次数据拼接。我们可以体会到这是一个复杂的过程,这样做极大地降低了计算机读取数据的效率。在如今存储空间已经没有那么稀缺了,没有必要为了小部分空间去降低速度,同样我们采用结构体中较小的值作为对其数,这样做已经可以减少大量的空间浪费了。
(2)计算机硬件层的限制:
①处理器特性
访问效率:许多处理器和硬件架构在访问内存时,对于特定数据类型的地址有对齐要求。例如,某些处理器可能要求访问4字节整数的地址必须是4的倍数,8字节长整数的地址必须是8的倍数。这种对齐要求可以确保处理器在访问内存时能够一次性读取或写入完整的数据块,从而提高访问效率。
性能优化:未对齐的数据访问可能会增加额外的处理器周期来处理,因为处理器需要执行额外的步骤来读取或写入跨边界的数据。这种额外的处理会降低整体性能,因此内存对齐成为了一种优化手段。
②内存构造与并行访问
内存芯片结构:内存由多个芯片(chip)组成,每个芯片包含多个存储体(bank)。这些存储体能够并行工作,同时从多个位置读取或写入数据。当数据在内存中对齐时,可以同时从多个存储体中读取数据,从而提高存取速度。
减少冲突:内存对齐还可以减少不同存储体之间的访问冲突,因为对齐的数据块更有可能位于不同的存储体中,从而可以并行访问。
③缓存一致性
缓存行:现代CPU通常具有缓存,用于存储最近访问的数据。缓存以缓存行为单位进行访问,每个缓存行包含多个字节的数据。当数据在内存中对齐时,可以确保整个数据块都位于同一个缓存行中,从而减少因跨缓存行访问而带来的额外延迟。
④硬件平台限制
地址边界:不是所有的硬件平台都能访问任意地址上的任意数据。某些硬件平台可能只能在特定的地址边界上访问特定类型的数据。例如,某些平台可能要求访问4字节数据的地址必须是4的倍数。内存对齐可以确保数据存储在正确的地址边界上,从而避免硬件异常。
⑤内存碎片减少与空间优化
紧凑布局:内存对齐可以使得数据在内存中的布局更加紧凑和连续,从而减少内存碎片的产生。在结构体或对象中,对齐字段可以使得整个结构体的大小更加紧凑,避免不必要的填充,节省内存空间。
总的来说就是空间换时间的方式,牺牲空间利用率来提高计算机读取效率。
一下是一个我觉得十分生动的场景,这是一个工人在使用工具来夹取砖块的场景,这种夹子只有在完好夹取四块砖块的时候是最稳定的状态,多一块少一块都会夹不住,对于计算机来说也是,工具是设计好的,每次能拿多少数据对于计算机来说是固定的,这样对它来说最轻松,也是最快的。



















 1400
1400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











