






图像融合(Image Fusion)
定义
图像融合是指将多幅图像的信息融合在一起,生成一幅新的图像,使得新图像能够包含原始图像的所有关键信息和特征。图像融合技术可以将不同源的图像信息进行有效的组合,以提高图像的质量和信息量。
实现
将多幅图像进行适当的处理和组合,以实现信息的互补和增强。主要的图像融合方法包括基于像素级的融合、基于特征级的融合和基于模型级的融合。
- 基于像素级的融合:该方法将多幅图像的像素逐个进行处理和组合,通常采用加权平均、最大值或最小值等方式进行像素级的融合。这种融合方法简单直观,但可能会导致某些信息的丢失。
- 基于特征级的融合:该方法将多幅图像的特征进行提取和匹配,然后根据匹配结果进行融合。常用的特征包括边缘、纹理、颜色等。这种融合方法可以更好地保留图像的细节和特征,但对特征提取和匹配的准确性要求较高。
- 基于模型级的融合:该方法将多幅图像的信息进行建模和优化,以得到最优的融合结果。常用的模型包括小波变换、多尺度分析和深度学习等。这种融合方法可以更好地处理不同尺度和分辨率的图像,但对模型的选择和参数的调整要求较高。
应用场景
- 红外与可见光图像融合:将红外图像和可见光图像进行融合,可以提高目标检测和识别的性能,尤其在夜间或恶劣环境下具有重要意义。红外图像能看到热辐射目标,但是对纹理细节表现很差,可见光图像纹理细节丰富,但是受光照影响,黑暗中拍不清,图像融合后,可以得到一张包含热辐射显著目标和丰富纹理细节的融合图像。

- 多模态医学图像融合:将不同模态的医学图像进行融合,可以提供更全面和准确的医学诊断信息,有助于医生做出更准确的判断和决策。
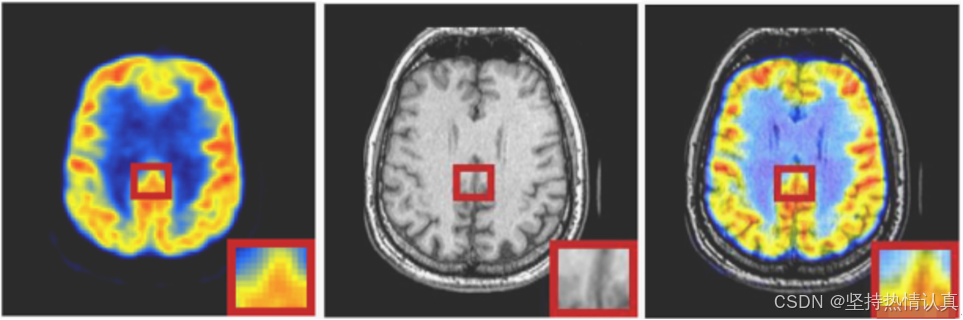
- 遥感图像融合:将多源的遥感图像进行融合,可以提高地物的识别和分析能力,对于土地利用、资源调查和环境监测等领域具有重要意义。
- 视频图像融合:将多个视频图像进行融合,可以提高视频质量和信息量,对于视频监控、视频分析和虚拟现实等应用有很大的帮助。
资源负载
DeepFlood: A deep learning based flood detection framework using feature-level fusion of multi-sensor remote sensing images
这篇论文介绍了名为DeepFlood的框架,这是一种基于深度学习的洪水检测系统,它利用多传感器遥感图像在特征级进行融合。该框架使用全卷积网络(FCN)对合成孔径雷达(SAR)图像和多光谱(MS)图像进行独立训练,并将所学特征连接起来以更好地表示洪水情况。随后使用随机森林分类器来识别洪水区域。这种方法在SEN12-FLOOD数据集上的表现优于其他方法,达到了94.17%的高准确率。
研究中提到,单独使用光学或雷达数据进行洪水检测存在局限性,特别是在复杂环境中。而DeepFlood通过结合SAR和MS图像的优点,在特征层面进行融合,从而提高了洪水检测的准确性。此外,论文还比较了不同方法在不同数据集上的性能,并展示了DeepFlood在SEN12-FLOOD数据集上针对洪水与非洪水区域分类的优越性。

Improved Image Fusion Method Based on Sparse Decomposition
这篇论文介绍了一种改进的基于稀疏分解的图像融合方法,主要应用于解决显微场景下的图像离焦问题。研究发现显微镜成像模糊的主要原因是景深较浅。因此,作者提出了一种新的基于稀疏表示的多焦点图像融合方法(DWT-SR),以获取一系列离焦图像中的完整清晰信息。

TransFuse: A Unified Transformer-based Image Fusion Framework using Self-supervised Learning
这篇论文提出了一种名为TransFuse的新框架,它是一个统一的基于Transformer的图像融合框架,利用自监督学习来提升图像融合效果。该方法旨在克服传统端到端图像融合方法因缺乏特定任务训练数据和相应的真实标签而容易过拟合的问题,同时避免了两阶段方法由于自然图像和不同融合任务之间的领域差距导致的性能受限。
TransFuse设计了一个新颖的编码器-解码器结构,并提出了一个基于破坏-重建的自监督训练方案,鼓励网络学习特定任务的特征。具体来说,对于多模态图像融合、多曝光图像融合和多焦点图像融合,分别设计了三种基于像素强度非线性变换、亮度变换和噪声变换的破坏-重建自监督辅助任务。为了促进不同融合任务间的相互促进并增加训练网络的泛化能力,这三种自监督辅助任务通过随机选择其中一种来破坏自然图像的方式整合在一起。
此外,TransFuse还设计了一个结合了CNN和Transformer的新编码器,以在特征提取过程中同时利用局部和全局信息。实验结果显示,该方法在多模态图像融合、多曝光图像融合和多焦点图像融合任务中都达到了最新的最优性能,既在主观评价也在客观指标上超越了现有方法。

Bridging the Gap between Multi-focus and Multi-modal: A Focused Integration Framework for Multi-modal Image Fusion
这篇文章提出了一种针对多模态图像融合(MMIF)的聚焦信息集成框架,该框架旨在解决可见光图像由于镜头景深限制导致的焦点区域不完整问题,以及不同模态图像(如可见光与红外图像)之间难以同时捕获显著信息的问题。
文章中提到,传统的多模态图像融合技术通常假设可见光设备捕捉到的场景信息总是清晰的,但在实际应用中,只有在景深范围内的物体才是清晰的。为了解决这一问题,文中提出了一种新的方法,该方法首先将源图像分解为结构和纹理两个部分,然后通过多尺度特征检测引导的金字塔结构来进行纹理层融合,同时考虑像素在多个方向上的分布并通过有效的融合策略来提取结构层中的能量信息。
具体来讲,该方法通过半稀疏平滑滤波器(SSF)分解图像,利用多尺度特征检测和金字塔引导的显著特征提取算子来融合纹理层。在结构层融合中,则考虑了熵和频率方差的信息分布,以有效地捕捉每个源图像中的细节分布。此外,还引入了基于金字塔尺度分离的特征提取算法,以提高融合结果的细节感知性能。

Classification Similarity Network Model for Image Fusion Using Resnet50 and GoogLeNet
这篇论文提出了一种基于ResNet50和GoogLeNet的分类相似性网络模型(CSN),用于图像融合(IF)。传统图像融合算法主要关注融合过程本身,而较少考虑输入图像之间的相似性及其参与融合的特征。为了解决这些问题,作者设计了一个新框架,即分类相似性网络(CSN),该网络具有分类预测和相似性估计的功能。通过修改ResNet50和GoogLeNet作为CSN的不同版本(CSN v1 和 CSN v2)的分类分支,可以减少特征维度。融合规则依赖于输入数据集来融合提取的特征,融合过程的输出被送入CSN v3以改善输出图像质量。

行人重识别(Person Re-identification)
定义
用各种智能算法在图像数据库中找到与要搜索的目标相似的对象。ReID是图像检索的一个子任务,本质上是图像检索而不是图像分类。给定一个监控行人图像,检索跨设备下的该行人图像。
实现
- 行人检测:通过目标检测模型提取当前帧的行人图像。
- 特征提取:基于特征提取模型,项目中现使用预训练的特征提取模型提取行人区域图片的特征向量。
- 单镜头行人跟踪:结合行人区域特征,通过deepsort等算法进行行人跟踪。
- 跨镜头行人跟踪:基于深度学习的全局特征和数据关联实现跨镜头行人目标跟踪。
- 向量存储与检索:对于给定的行人查询向量,与行人特征库中所有的待查询向量进行向量检索,即计算特征向量间的相似度(计算余弦距离等方法)。
在以上步骤中,特征提取是最关键的一环,它的作用是将输入的行人图片转化为固定维度的特征向量,以用于后续的目标跟踪和向量检索。好的特征需要具备良好的相似度保持性,即在特征空间中,相似度高的图片之间的向量距离比较近,而相似度低的图片对的向量距离比较远。通常用于训练这种模型的方式叫做度量学习。
- 全局特征:每一张图片的全局信息进行一个特征抽取,全局特征没有任何的空间信息。
- 局部特征:对图像的某一个区域进行特征提取,最后将多个局部特征融合起来作为最终特征。
- 度量学习:将学习到的特征映射到新的空间,表现为同一行人的不同图片间的相似度大于不同行人的不同图片(即相同的人更近,不同的人更远)。
- 图像检索:根据图片特征之间的距离进行排序,返回检索结果。
应用场景
- 智能安防
- 智能商业
- 人机交互
- 相册图片聚类

面临的问题
- 无正面照
- 服装更换
- 遮挡
- 图像分辨率低
- 光线差异
- 室内室外场景变化

资源负载
Tran-GCN: A Transformer-Enhanced Graph Convolutional Network for Person Re-Identification in Monitoring Videos
这篇文章提出了一种基于Transformer增强图卷积网络(Tran-GCN)的行人再识别(Person Re-Identification)模型,旨在提高监控视频中行人的识别准确度。该模型由四个主要组件构成:姿态估计学习分支用来估计行人的姿态信息和骨骼结构数据;Transformer学习分支学习细粒度且语义丰富的局部行人特征之间的全局依赖关系;卷积学习分支使用基本的ResNet架构提取行人细粒度的局部特征;图卷积模块(GCM)将局部特征信息、全局特征信息和身体信息融合后进行更有效的行人身份识别。
该模型的特点在于多分支特征提取模块和图卷积网络模块(GCM),其中多分支特征提取包括行人关键点特征、局部特征和全局特征。GCM整合了上述三种类型的特征以获得判别性的特征表示。实验结果表明,该方法在Market-1501、DukeMTMC-ReID和MSMT17三个不同的数据集上,对行人再识别的准确性有显著提升。

Mutual Information Guided Optimal Transport for Unsupervised Visible-Infrared Person Re-identification
这篇文章提出了一种基于互信息指导的最优传输(Mutual Information Guided Optimal Transport,简称MIOT)的无监督可见光-红外线行人再识别(USVI-ReID)方法。该方法致力于在没有任何标签信息的情况下,实现跨模态的行人图像检索。文章首先推导出了一个基于模型跨模态输入输出间互信息的优化目标,并由此导出了三个学习原则:“Sharpness”(熵最小化)、“Fairness”(均匀标签分布)和“Fitness”(可靠的跨模态匹配)。
在这些原则指导下,设计了一种交替迭代训练策略,交替进行模型训练和跨模态匹配。在匹配阶段,提出了一种基于均匀先验引导的最优传输分配方法来选择匹配的可见光和红外原型。在训练阶段,利用匹配信息引入基于原型的对比学习来最小化跨模态和同模态内的熵。这种方法在SYSU-MM01和RegDB数据集上实现了较高的无监督再识别准确率,分别为60.6%和90.3%,且没有使用任何标注数据。

Synthesizing Efficient Data with Diffusion Models for Person Re-Identification Pre-Training
这篇论文提出了一种新的范式Diffusion-ReID,该范式通过扩散模型高效地基于已知身份生成多样化的图像,无需收集和标注任何额外数据。该范式分为生成和过滤两个阶段:在生成阶段,提出语言提示增强(Language Prompts Enhancement,LPE)以确保输入图像序列与生成图像的身份一致性;扩散过程中,引入多样性注入(Diversity Injection,DI)模块以增加属性多样性。为了保证生成数据的质量更高,采用了一个基于再识别置信度阈值的过滤器进一步移除低质量图像。
受益于提出的范式,作者创建了一个新的大规模人员再识别数据集Diff-Person,包含超过777,000张来自5,183个身份的图片。接着,基于Diff-Person构建了一个更强的人再识别骨干网络。广泛的实验在四个再识别基准数据集上的六种常用设置中进行,结果表明该方法在各种预训练和自我监督条件下均优于其他方法。

DenoiseReID: Denoising Model for Representation Learning of Person Re-Identification
这篇文章提出了一种用于行人再识别(Person Re-Identification, ReID)表征学习的去噪模型(DenoiseReID),旨在通过联合特征提取与去噪来改善特征区分度。作者首先将骨干网络中的每一层嵌入层视为一个去噪层,并认为递归地逐步去除噪声可以统一特征提取与特征去噪的框架。前者逐步从低级到高级嵌入特征,而后者递归地逐步去除噪声。
为了实现这一点,文章设计了一个新的特征提取与特征去噪融合算法(FEFDFA),并在理论上证明了融合前后的一致性。FEFDFA将去噪层参数合并到现有的嵌入层中,使得特征去噪计算变得免费。这个算法是无标签的,可以逐步提高特征质量,并且如果存在标签的话也是互补的。实验结果表明,该方法在四个ReID数据集和多种骨干网络上都显示出了稳定性和显著的改进。

Enhancing Person Re-Identification via Uncertainty Feature Fusion and Auto-weighted Measure Combination
这篇论文介绍了一种新的用于增强行人再识别(Person Re-Identification, ReID)的技术,称为不确定性特征融合方法(UFFM)与自动加权测度组合(AMC)。该技术旨在通过多视角特征的融合来减少单一视角带来的偏差,并通过组合不同的相似性度量来生成更稳定的相似性判断。实验结果显示,在Market-1501、DukeMTMC-ReID、Occluded-DukeMTMC和MSMT17等标准数据集上,该方法显著提高了Rank-1准确率和平均精度(mAP)。

深度聚类(Deep Clustering)
定义
将深度学习技术与传统聚类方法相结合,通过深度神经网络学习数据的高层次表示(特征),然后在这些表示上进行聚类分析。其目标是利用深度学习强大的特征提取和表示能力,改进传统聚类方法在高维、复杂和多模态数据上的表现。
现有的深度聚类算法大都由聚类损失与网络损失两部分构成,下面从两个视角总结现有的深度聚类算法,即聚类模型与神经网络模型。
实现
1.自编码器(Autoencoder)聚类
- 深度嵌入聚类(Deep Embedded Clustering, DEC):这种方法首先使用自编码器学习数据的低维嵌入,然后在嵌入空间上应用K-means聚类,并通过联合优化过程迭代地微调自编码器和聚类中心。
- 变分自编码器(Variational Autoencoder, VAE)聚类:VAE是一种生成模型,通过学习数据的概率分布来生成新样本。VAE聚类方法利用变分推断和聚类目标联合优化,以获得更好的聚类结果。
2.深度生成模型聚类
- 生成对抗网络(Generative Adversarial Networks, GANs)聚类:GANs通过生成器和判别器的对抗训练来学习数据分布。GANs聚类方法将聚类目标引入GANs框架,通过生成模型的隐变量空间进行聚类。
- 深度潜变量模型(Deep Latent Variable Models)聚类:这类方法利用深度潜变量模型(如变分自编码器)学习数据的隐变量表示,并在隐变量空间中进行聚类。
3.深度卷积网络(Deep Convolutional Networks)聚类
- 深度卷积生成对抗网络(DCGANs)聚类:DCGANs是一种卷积GANs,通过卷积神经网络(CNN)实现生成和判别过程。DCGANs聚类方法结合卷积特征提取和生成对抗训练,以获得更好的图像聚类效果。
4.深度聚类网络(Deep Clustering Network)
- 联合学习(Joint Learning): 方法通过同时优化深度网络的重构误差和聚类损失函数,使得网络学习的表示既能重构输入数据,又能进行有效的聚类。
- 深度聚类(Deep Clustering,DC) 这种方法将聚类目标引入深度学习框架,通过联合优化深度表示学习和聚类目标,获得更好的聚类性能。
5.递归神经网络(RNNs)聚类
- 长短期记忆网络(Long Short-Term Memory, LSTM)聚类:LSTM是一种特殊的RNN,用于捕捉序列数据中的长期依赖关系。LSTM聚类方法通过LSTM网络学习序列数据的表示,并在表示空间中进行聚类。
- 双向LSTM(Bi-directional LSTM)聚类:双向LSTM通过同时考虑前向和后向的时间依赖信息,提高了序列数据的表示能力,适合序列聚类任务。
资源负载
Deep Clustering via Distribution Learning
这篇文章介绍了一种新的深度聚类方法,称为通过分布学习实现的深度聚类(DCDL)。该方法结合了聚类和分布学习的概念,提出了一种理论分析来指导聚类优化过程,并引入了面向聚类的分布学习方法——蒙特卡洛边缘化(Monte-Carlo Marginalization for Clustering),以克服直接应用分布学习方法到数据的问题。
文章首先阐述了分布学习与聚类之间的关系,并提出理论分析来优化聚类过程。然后,文章描述了如何将蒙特卡洛边缘化集成到深度聚类中形成DCDL,该方法在流行的聚类数据集上与当前最先进的方法相比取得了令人满意的结果。

Scaling Up Deep Clustering Methods Beyond ImageNet-1K
这篇文章探讨了在超越ImageNet-1K规模的数据集上,特征基础的深度聚类方法的表现,并分析了数据相关因素的影响,包括类别不平衡、类别粒度、易于识别的类别以及捕捉多重类别能力等因素。研究团队基于ImageNet21K创建了多个新的基准测试,并揭示了特征基础的K均值聚类经常在平衡数据集上被不公平地评估。然而,深度聚类方法在大多数大规模基准测试中超过了K均值。有趣的是,K均值在易于分类的基准测试中表现较差,但这种性能差距在最高数据级别如ImageNet21K上缩小。最后,研究发现非主类别的聚类预测能够捕捉有意义的类别(即更粗的类别)。
Dual-Level Cross-Modal Contrastive Clustering
这篇论文介绍了一种新的图像聚类框架,名为双层跨模态对比聚类(Dual-level Cross-Modal Contrastive Clustering, DXMC)。该方法主要针对无监督学习中的图像聚类任务,旨在通过利用图像本身的内在信息以及外部监督知识来提高图像的语义理解。具体来说,该方法首先引入外部文本信息来构建一个语义空间,并基于此生成图像-文本对。然后,将这些图像-文本对分别送入预训练的图像和文本编码器中以获得图像和文本嵌入表示,并进一步输入到四个精心设计的网络中进行处理。接下来,在不同模态的判别表示之间执行双层跨模态对比学习。实验结果表明,所提出的方法在五个基准数据集上取得了优异的结果,展示了其优越性。
论文还回顾了近期深度聚类技术的发展,特别是对比学习的整合,这极大地提升了深度聚类方法的表现,通过增强学习到的嵌入质量并促进更好的聚类分离度。例如,IDFD方法使用实例判别和谱聚类的思想来学习实例间的相似性和减少特征内的相关性;CC是首个同时在实例级和聚类级上执行对比学习的工作;而后续的工作如TCC和GCC则进一步扩展了这一基础。此外,SACC探索了强弱增强对对比聚类的影响,而ProPos框架结合了对比与非对比学习的优点。

Deep Image Clustering with Contrastive Learning and Multi-scale Graph Convolutional Networks
这篇论文提出了一种称为TGC(Temporal Graph Clustering)的新框架,该框架致力于时序图聚类任务,通过引入两个深度聚类模块来适应时序图的交互序列批处理模式。TGC由两个主要模块组成:一个是用于挖掘时间信息的时间模块,另一个是用于节点聚类的聚类模块。
该研究强调了时序图聚类与静态图聚类的区别,并在直觉、复杂性、数据和实验等多个方面进行了探讨。通过广泛的实验验证,TGC在无监督时序图表示学习方面的优势得以展示。实验结果显示,TGC能够更灵活地在时间和空间需求之间寻找平衡,并且可以有效提升现有时序图学习方法的性能。
此外,论文指出了目前时序图聚类面临的一个问题——缺乏有效的数据集,并整理或开发了几组有用的数据集。论文还评估了TGC的聚类性能、灵活性和可转移性,并进一步阐明了时序图聚类的特点。

Image Clustering using an Augmented Generative Adversarial Network and Information Maximization
这篇论文提出了一种利用改进的生成对抗网络(GAN)和信息最大化来进行图像聚类的新方法。该方法的核心在于通过在GAN的判别器之前应用Sobel操作来增强特征的可分性,并利用判别器生成的表示作为辅助分类器的输入。为了使辅助分类器更加鲁棒,即最小化由判别器生成的多个表示之间的分歧,使用了一个自适应目标函数来训练辅助分类器进行聚类。此外,辅助分类器是由多个聚类头组成的,通过使用容忍度超参数来处理数据不平衡的问题。
研究结果表明,与现有方法相比,该方法在CIFAR-10和CIFAR-100数据集上的聚类性能显著提高,并且在STL10和MNIST数据集上也表现出竞争力。值得注意的是,该方法没有对原始数据直接进行图像增强,而是依靠不特定于图像数据的转换,这意味着该策略可以扩展应用于非图像数据。此外,实验结果显示,对于CIFAR-10数据集,该算法平均性能比其他现有方法提高了7.5%,对于CIFAR-100数据集提高了5%。

参考文章:深度聚类算法研究综述(A Survey of Deep Clustering Algorithms) - 凯鲁嘎吉 - 博客园 (cnblogs.com)
深度聚类与行人重识别结合
论文
Multi-modal data clustering using deep learning: A systematic review
多模态数据是指由两种或两种以上不同类型的数据和信息组成的数据集。
聚类:无监督学习技术,没有标签,自动学习
MultiModal Deep Clustering (MMDC)
探讨了应用于多模态聚类的深度学习(DL)技术,包括卷积神经网络(CNN)、自动编码器(AE)、循环神经网络(RNN)和图卷积网络(GCN)等方法。值得注意的是,这项调查代表了专门针对多模态聚类研究深度学习技术的第一次尝试。
本研究提出了一种新的基于dl的多模态聚类分类方法,对各种多模态聚类方法进行了比较分析,并对评估过程中使用的数据集进行了讨论。此外,该调查还指出了多模态聚类领域的研究差距,为未来潜在的研究途径提供了见解。


Deep Clustering for Epileptic Seizure Detection
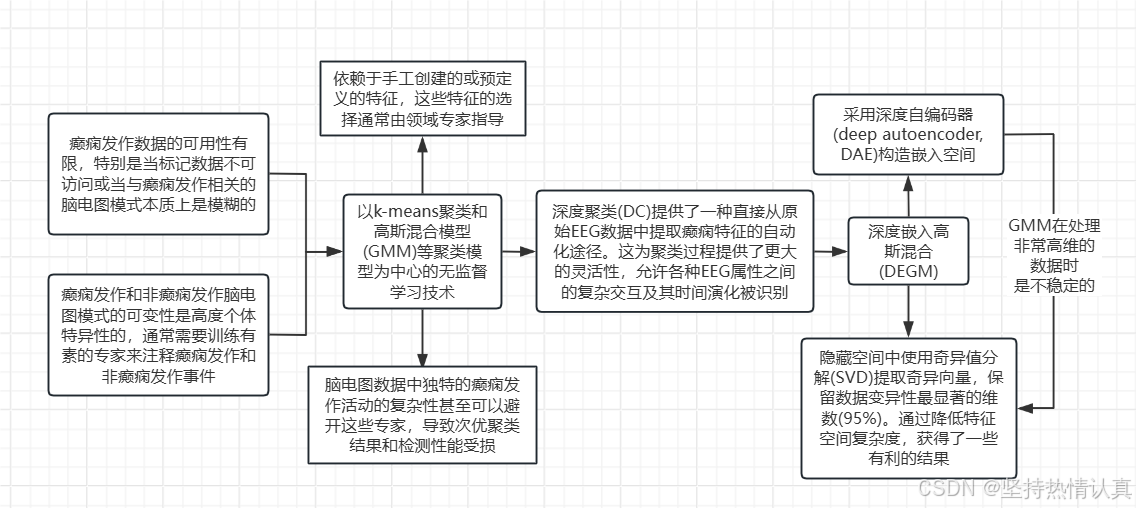
。值得注意的是,本研究使用了一种不直接涉及标签的学习过程,与无监督方面保持一致。然而,识别无癫痫数据本质上依赖于专家标记,引入了一定程度的“部分监督”。他们取得了可以接受的结果。
Multiview Deep Subspace Clustering Networks:多视图深度子空间聚类网络
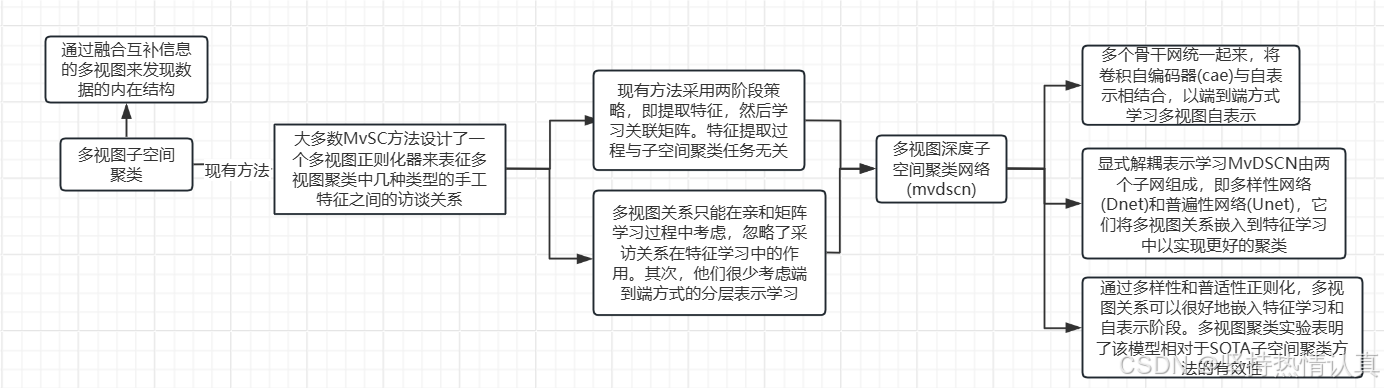
自动编码器通过将数据映射到低维空间来提取数据的特征。随着深度学习的快速发展,深度(或堆叠)自编码器在无监督学习中越来越受欢迎。深度自编码器已广泛应用于降维[36]和图像去噪[37]。
与浅层模型提取深层特征然后进行子空间聚类不同,MvDSCN将特征学习和子空间聚类结合起来,使得多视图关系影响两个部分。
Cross-Modality Spatial-Temporal Transformer for Video-Based Visible-Infrared Person
Re-Identification
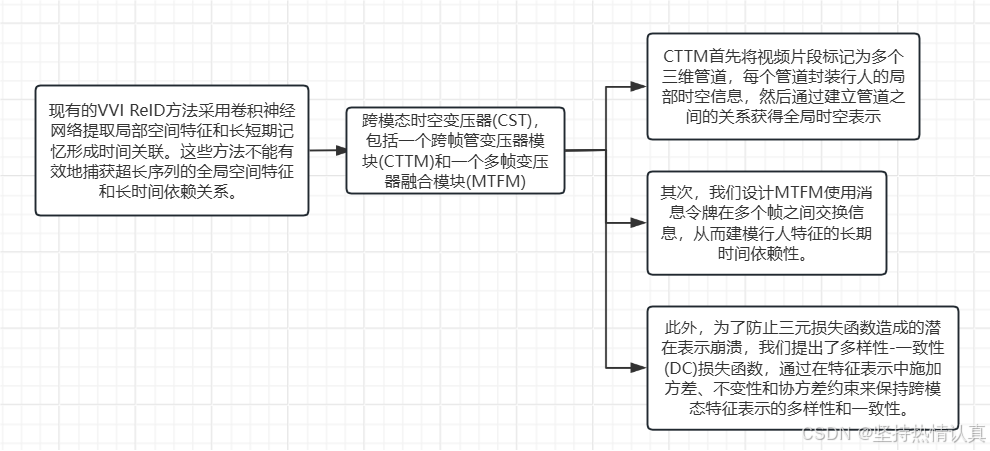
DMA: Dual Modality-Aware Alignment for Visible-Infrared Person Re-Identification:可见-红外人员再识别的双模态感知校准
本文介绍了针对可见光-红外线行人重识别(VI-ReID)的新模型DMA(Dual Modality-aware Alignment)。VI-ReID的目标是在可见光图像和红外线图像之间识别同一人。主要挑战在于如何提取与模态无关的个人身份信息。现有的方法通常采用两种范式来减少跨模态差异:一种是将可见光图像转换为灰度颜色空间,并映射到红外域;另一种是将红外图像堆叠到RGB颜色空间,并映射到可见域。然而,由于可见光和红外波具有不同的光学特性,这种映射通常会导致信息不对称。尽管一些方法试图通过数据级对齐来防止此类差异,但同时可能会引入误导性信息并带来额外的分歧。
本文首先分析了产生模态差异的基本因素,并提出了一种新的DMA模型用于VI-ReID任务,该模型可以在统一方案中保留区分性的身份信息并抑制误导信息。基于两种模态的内在光学特性,提出了一种双模态传输(DMT)模块,在HSV颜色空间中执行信息补偿,从而有效减轻跨模态差异并更好地保留区分性的身份特征。此外,还提出了一种局内对齐(IA)模块以抑制误导信息,其中设计了一个细粒度的局部一致性目标函数以实现更紧凑的类内表示。









Market1501
2015年,论文 Person Re-Identification Meets Image Search 提出了 Market 1501 数据集,现在 Market 1501 数据集已经成为行人重识别领域最常用的数据集之一。
数据库中常见的缺点有:
- 数据库规模小(图片少)
- 摄像头个数少(一般为两个)
- 行人身份较少
- 每个身份的query只有一个
- 图片均为手动标记的完美图片,缺乏实际性
针对以上种种问题,创立了Market1501:
- 1501个身份
- 6个摄像头
- 32668张图片
- DPM检测器代替手工框出行人
- 500K张干扰图片
- 每一个身份有多个query
- 每一个query平均对应14.8个gallery
Market 1501 的行人图片采集自清华大学校园的 6 个摄像头,一共标注了 1501 个行人。其中,751 个行人标注用于训练集,750 个行人标注用于测试集,训练集和测试集中没有重复的行人 ID,也就是说出现在训练集中的 751 个行人均未出现在测试集中。
- 训练集:751 个行人,12936 张图片
- 测试集:750 个行人,19732 张图片
- query 集:750 个行人,3368 张图片。query 集的行人图片都是手动标注的图片,从 6 个摄像头中为测试集中的每个行人选取一张图片,构成 query 集。测试集中的每个行人至多有 6 张图片,query 集共有 3368 张图片。
网络模型训练时,会用到训练集;测试模型好坏时,会用到测试集和 query 集。此时测试集也被称作 gallery 集。因此实际用到的子集为,训练集、gallery 集 和 query 集。
数据集结构
Market 1501 包括以下几个文件夹:
- bounding_box_test 是测试集,包括 19732 张图片。
- bounding_box_train 是训练集,包括 12936 张图片。
- gt_bbox 是手工标注的训练集和测试集图片,包括 25259 张图片,用来区分 “good” “junk” 和 “distractors” 图片。
- query 是待查找的图片集,在 bounding_box_test 中实现查找。这些图片是手动绘制生成的。而 gallery 是通过 DPM 检测器生成的。
- gt_query 是一些 Matlab 格式的文件,里面记录了 “good” 和 “junk” 图片的索引,主要被用来评估模型。
数据集命名规则
以图片 0012_c4s1_000826_01.jpg 对数据集命名进行说明。
- 0012 是行人 ID,Market 1501 有 1501 个行人,故行人 ID 范围为 0001-1501
- c4 是摄像头编号(camera 4),表明图片采集自第4个摄像头,一共有 6 个摄像头
- s1 是视频的第一个片段(sequece1),一个视频包含若干个片段
- 000826 是视频的第 826 帧图片,表明行人出现在该帧图片中
- 01 代表第 826 帧图片上的第一个检测框,DPM 检测器可能在一帧图片上生成多个检测框



MSMT17
CVPR2018会议上,提出了一个新的更接近真实场景的大型数据集MSMT17,即Multi-Scene Multi-Time,涵盖了多场景多时段。数据集采用了安防在校园内的15个摄像头网络,其中包含12个户外摄像头和3个室内摄像头。为了采集原始监控视频,在一个月里选择了具有不同天气条件的4天。每天采集3个小时的视频,涵盖了早上、中午、下午三个时间段。因此,总共的原始视频时长为180小时。
基于Faster RCNN作为行人检测器,三位人工标注员用了两个月时间查看检测到的包围框和标注行人标签。最终,得到4101个行人的126441个包围框。和其它数据集的对比以及统计信息如下图所示。
目录结构
MSMT17
├── bounding_box_test
├── 0000_c1_0002.jpg
├── 0000_c1_0003.jpg
├── 0000_c1_0005.jpg
├── bounding_box_train
├── 0000_c1_0000.jpg
├── 0000_c1_0001.jpg
├── 0000_c1_0002.jpg
├── query
├── 0000_c1_0000.jpg
├── 0000_c1_0001.jpg
├── 0000_c14_0030.jpg
评估协议
按照训练-测试为1:3的比例对数据集进行随机划分,而不是像其他数据集一样均等划分。这样做的目的是鼓励高效率的训练策略,由于在真实应用中标注数据的昂贵。
最后,训练集包含1041个行人共32621个包围框,而测试集包括3060个行人共93820个包围框。对于测试集,11659个包围框被随机选出来作为query,而其它82161个包围框作为gallery.
测试指标为CMC曲线和mAP. 对于每个query, 可能存在多个正匹配。


SYSU-30k 数据集
目前没有公开发布的「弱监督」行人重识别数据集。为了填补这个空白,研究者收集了一个新的大规模行人重识别数据 SYSU-30k,为未来行人重识别研究提供了便利。他们从网上下载了许多电视节目视频。考虑电视节目视频的原因有两个:第一,电视节目中的行人通常是跨摄像机视角,它们是由多个移动的摄像机捕捉得到并经过后处理。因此,电视节目的行人识别是一个真实场景的行人重识别问题;第二,电视节目中的行人非常适合标注。在 SYSU-30k 数据集中,每一个视频大约包含 30.5 个行人。
研究者最终共使用的原视频共 1000 个。标注人员利用弱标注的方式对视频进行标注。具体地,数据集被切成 84,930 个袋,然后标注人员记录每个袋包含的行人身份。他们采用 YOLO-v2 进行行人检测。三位标注人员查看检测得到的行人图像,并花费 20 天进行标注。最后,29,606,918(≈30M)个行人检测框共 30,508(≈30k)个行人身份被标注。研究者选择 2,198 个行人身份作为测试集,剩下的行人身份作为训练集。训练集和测试集的行人身份没有交叠。
SYSU-30k 数据集的一些样例如下图所示。可以看到,SYSU-30k 数据集包含剧烈的光照变化(第 2,7,9 行)、遮挡(第 6,8 行)、低像素(第 2,7,9 行)、俯视拍摄的摄像机(第 2,5,6,8,9 行)和真实场景下复杂的背景(第 2-10 行)。
PETA 远距离行人识别数据集
PETA 全称 The PEdes Trian Attribute dataset,是用于远距离识别行人属性的图像数据集。比如远距离识别性别和服装风格。该数据集包含了 8,705 个行人、65 个属性(61 个二类属性和 4 个多类属性)和 19,000 张图像。
第二次任务
Multi-Domain Learning and Identity Mining for Vehicle Re-Identification:车辆再识别的多领域学习和身份挖掘
本文介绍了在2020年AI City Challenge竞赛中Track2赛道的解决方案。该赛道的任务是在包含真实世界数据和合成数据的情况下进行车辆再识别(Vehicle Re-ID)。本文作者团队最终在mAP得分上达到了0.7322的成绩,在比赛中获得了第三名。
引言
文章首先介绍了AI City Challenge,这是在CVPR2020会议中的一个研讨会,关注的是利用计算机视觉技术使城市的交通系统更加智能化。本文则专注于解决Track2的问题,即城市规模多摄像头下的车辆再识别任务。方法
基线模型
基线模型基于一个人脸再识别领域的强基准(BoT-BS),并对其进行了修改以适应Track2的数据集。具体来说,输出特征后跟随着BNNeck结构,将ID损失(交叉熵损失)与三重损失分开到两个不同的嵌入空间中。同时,还使用了软边距版本的三重损失,并且采用了硬示例挖掘技术。删除了中心损失,并尝试了arc-face损失,但是后者表现不佳。在推理阶段,发现特征ft的表现优于fi,因此选择了SGD优化器而非Adam优化器,并使用更深的骨干网络和更大的图像尺寸来训练BoS-BS。多域学习
由于竞赛提供了真实世界和合成数据,如何从这两个不同领域学习区分性特征成为了一个重要的问题。文中提出了一个多域学习方法(MDL),这种方法不同于直接合并数据或先在合成数据上预训练模型然后再微调的方法,而是提出了一种新的方法,通过预训练模型并在冻结前几层的情况下对真实世界数据进行微调,以利用共享的低级特征如颜色和纹理。身份挖掘
身份挖掘方法用于自动为测试数据的一部分生成伪标签,其效果优于k-means聚类。具体来说,IM选择了一些不同ID的样本作为聚类中心,然后为每个聚类中心标记一些相似的样本。重新排序策略
为了进一步提高再识别性能,引入了带有加权特征的tracklet级重新排序策略。虽然单个模型在CityFlow数据集上可以达到68.5%的mAP准确率,但是通过多个模型集成,最终将mAP准确率提高到了73.2%。实验结果
文章描述了所使用的数据集,包括真实世界数据(CityFlow)和合成数据(VehicleX)。真实世界数据由40个摄像头捕获,总共包含56277张图片,而合成数据则包含192150张图片。实验部分还包括了实施细节,但具体内容未详细说明。结论
文章总结了提出的解决方案,包括基于人再识别领域强基准的模型,多域学习方法以及自动标记测试数据一部分的身份挖掘方法。这些技术使得模型在测试数据上的表现得到提升,最终在竞赛中排名第三。
Track2是一个车辆再识别(ReID)任务,使用真实数据和合成数据。
本文提出了一种多领域学习方法,将真实数据和合成数据结合起来训练模型
城市规模多摄像头车辆再识别(ReID)
车辆识别是计算机视觉领域的一个重要课题。它的目的是在不同摄像头的图像或视频中识别目标车辆,特别是在不知道车牌信息的情况下。
Veri-776 and VehicleID
提供了真实世界和合成数据集来训练Track2中的模型。两种不同的数据集之间存在较大的偏差,因此如何合理地使用合成数据集仍然是一个挑战。
Market1501
DukeMTMC-reID
VeRi
VehicleID
Track2的规则:
无法使用外部数据。禁止使用公共的基于人和车辆的数据集,包括Market1501[29]、DukeMTMC-reID[18]、VeRi、VehicleID等。其他机构收集的私人数据集也不允许使用。
a strong baseline with bag of tricks (BoT-BS) in person ReID
Bag of Tricks and A Strong Baseline for Deep Person Re-identification
由于任务类似于person ReID,因此我们在本文中使用了以BoT-BS (bag of tricks) in person ReID[13,14]为基线的强基线。
A strong baseline and batch normalization neck for deep person re-identification
为了减少训练阶段ID损失(交叉熵损失)和三元组损失之间的不一致性,BoT-BS引入了BNNeck。
BoT-BS is not only a strong baseline for person ReID, but
also suitable for vehicle ReID while it can achieve 95.8%
rank-1 and 79.9% mAP (ResNet50 backbone) accuracy on
Veri-776 benchmark.
BoT-BS不仅是一个强大的行人ReID基线,也适用于车辆ReID,在Veri-776基准上,它可以达到95.8%的rank-1和79.9%的mAP (ResNet50 backbone)准确率。
我们提出了一种多域学习(MDL)方法,该方法在真实世界和部分合成数据上进行预训练,然后在真实世界数据上进行微调,前几层被冻结
然而,由于ReID模型的性能较差,伪标签不够准确。因此,我们提出身份挖掘(Identity Mining, IM)方法来生成更精确的伪标签。
IM选取一些具有高置信度的不同id的样本作为聚类中心,每个id只能选取一个样本。然后,对于每个聚类中心,将一些相似的样本标记为相同的ID。与k-means聚类将所有数据分成几个簇不同,我们的IM方法只是对部分数据进行高置信度的自动标记。
为进一步提升性能,引入了一种带有加权特征的轨道级重新排序策略(WF-TRR)[4]。虽然我们的单一模型在CityFlow上可以达到68.5%的mAP精度[16],但我们通过多模型集成进一步将mAP精度提高到73.2%。
挡风玻璃、车灯和车辆品牌等特定部件往往具有很多进行区分的信息
3.1 基线模型 基线模型对最终排名很重要。在track2中,我们使用了针对个人ReID提出的强基线(BoT-BS)[13,14]作为基线模型。为了提高在Track2数据集上的性能,我们修改了BOT-BS的一些设置。输出特征之后是BNNeck[13,14]结构,它将ID损失(交叉熵损失)和三重态损失[5]分离到两个不同的嵌入空间中。
删除了中心损失,因为它在增加计算资源的同时并没有大大提高检索性能。
我们尝试将交叉熵损失修改为arcface loss,但arcface loss在CityFlow上的表现更差
在推理阶段,我们观察到特征ft比fi获得了更好的性能。由于性能更好,我们使用SGD优化器而不是Adam优化器。为了提高性能,我们使用更深的主干和更大的图像来训练BoS-BS。
作为参考,我们改进的基线在Veri-776基准上达到了96.9%的rank-1和82.0%的mAP精度。
3.2 一种新的多领域学习(MDL)方法来利用合成数据。
在这个挑战中既提供了真实的数据,也提供了合成的数据,因此如何从两个不同的领域中学习判别特征是一个重要的问题。
目标是在DR 和 DS的并集上训练模型,并使其在DR上获得更好的性能。
两种方案
解决方案-1:直接合并真实数据和合成数据来训练ReID模型;
解决方案-2:首先在合成数据DS上训练预训练模型,然后在真实数据DR上对预训练模型进行微调。
然而,这两种解决方案在挑战中不起作用。
由于DS中的数据数量远远大于DR中的数据数量,因此解决方案-1将导致模型更偏向于DS。
由于DR和DS之间存在较大的偏差,对于CityFlow数据集,DS上的预训练模型可能并不比ImageNet上的预训练模型更好。因此,解决方案-2不是解决这个问题的好方法。
一些研究[21,7]在Veri-776、VehicleID或CompCar[27]数据集上使用预训练模型,以在AI CITY Challenge中获得更好的性能
表明在合理数据上训练的预训练模型是有效的
在此基础上,我们提出了一种新的MDL方法来利用合成数据vehicle - lex。该方法包括两个阶段:预训练阶段和微调阶段。
3.3 Identity Mining 测试集允许用于无监督学习。一种广泛使用的方法是使用聚类方法对数据进行伪标签标注。由于测试集包含333个身份/类别,我们可以直接使用k-means聚类将测试数据聚为333个类别。然而,这种方法在Track2中不起作用,因为糟糕的模型不能给出准确的伪标签。当加入这些自动标注的数据来训练模型时,我们观察到性能变得更差。
我们认为没有必要添加所有的测试数据来训练模型,但有必要确保伪标签的正确性。因此,我们提出了一种身份挖掘(IM)方法来解决这个问题。
3.4. Tracklet-Level Re-Ranking with Weighted Features:tracklet级重排名与加权特征
tracklet id为Track2中的测试集提供。先验知识是tracklet的所有帧都属于相同的ID。在推理阶段,标准ReID任务是一个图像到图像(I2I)问题。然而,有了tracklet信息,任务就变成了图像-轨道(I2T)问题。对于I2T问题,tracklet的特征由tracklet所有帧的特征表示。
4. Experimental Results
现实世界的数据。真实世界的数据,本文称之为CityFlow数据集[16,22],是在真实世界的交通监控环境中,由40个摄像头捕获的数据。总共包含666辆车的56277张图像。36935张333辆车的图像用于训练。其余333辆车的18290张图像用于测试。在测试集中,分别有1052张查询图像和17238张图库图像。平均而言,每辆车有来自4.55个摄像头视图的84.50个图像签名。在训练和测试集上都提供了单摄像头跟踪器。在测试集上的表现决定了在排行榜上的最终排名。
合成数据。合成数据在本文中称为VehicleX数据集,它是由一个公开的3D引擎VehicleX[28]生成的。该数据集仅提供训练集,共包含1362辆汽车的192150张图像。此外,还对属性标签(如汽车颜色和汽车类型)进行了注释。在Track2中,合成数据可用于模型训练或迁移学习。然而,实际数据与合成数据之间存在很大的领域偏差。
验证数据。由于每个团队只有20个提交,因此有必要使用验证集来离线评估方法。我们将CityFlow的训练集分成训练集和验证集。为方便起见,我们将它们分别命名为Split-train和Split-test。Splittrain和Split-test分别包含233辆车的26272张图像和100辆车的10663张图像。在Splittest中,每辆车采样3张图像作为探针,其余图像作为图库。
如果在微调阶段不冻结前两层,则性能将降低1.4% mAP。较少的标识提供较少的知识,而更多的标识可能导致模型更偏向于合成数据。
A Strong Baseline for Vehicle Re-Identification:车辆再识别的强基线
这篇论文主要介绍了一种针对车辆再识别(Vehicle Re-Identification, Re-ID)任务的强大基线方法。研究团队的目标是识别同一车辆在不同摄像头视角下的图像,这对于现代交通管理系统有着重要意义。尽管深度学习近年来取得了诸多进展,但车辆Re-ID仍面临许多挑战,例如从不同视角产生的严重变化、部分遮挡、图像模糊或光照变化等问题。
方法
为了解决上述问题,研究团队提出了以下几种解决方案:
1. 减少现实数据与合成数据之间的域差距:通过采用MixStyle传输作为正则化方法来减少真实世界数据与合成数据之间的差异。
2. 网络修改:在主干网络中堆叠多头架构(multi-head architecture)与注意力机制(attention mechanism),帮助模型学习更细致的特征。这些特征随后会自动分组为子特征,每组特征都有助于缩小目标身份的搜索范围。
3. 自适应损失权重调整:用监督对比损失(Supervised Contrastive Loss)替代常见的三重损失(Triplet Loss),并且提供了一个新颖的自适应损失权重调整机制,以改进监督对比损失与交叉熵损失之间的平衡。实验结果
在CityFlow数据集上,通过多头架构、SupCon损失和自适应损失权重调整(MALW)的组合,模型在Real-split和CityFlow上的表现分别为88.1%和49.5%的mAP。此外,通过应用重排序算法、融合距离方法、轨迹排名算法以及模型集成等后处理技术,最终在CityFlow测试集上实现了61.34%的mAP成绩,而没有使用任何外部数据或伪标签。在VeRi776数据集上的实验表明,该方法达到了87.1%的mAP,显著优于先前的工作。
车辆再识别(Re-ID)旨在通过不同的摄像头识别同一辆车辆,因此在现代交通管理系统中起着重要作用。技术挑战要求算法必须在不同的视角、分辨率、遮挡和光照条件下具有鲁棒性。
车辆Re-ID任务还没有一个大型公开数据集可供使用
不使用外部数据集或伪标签
创新点:
(1)缩小真实数据和合成数据之间的“域差异”。
(2)通过使用带有注意力的多头(multi head)结构修改网络架构。
(3)自适应的损失权重调整。
评价:
(1)首先建立了一个私有数据集CityFlow来评价方法。
(2)还有一个在Veri benchmark上的评价结果。
车辆Re-ID仍然面临许多挑战,例如不同视点的严重变化,部分遮挡,图像模糊或照明变化。
池化算子
损失函数使用三重损失和交叉熵损失的组合
主要贡献有:
(1)我们采用MixStyle Transfer[29]作为一种正则化方法来减少真实数据和合成数据之间的差距。
(2)将带有注意机制的多头附着在主干上,帮助模型学习更详细的特征。然后将特征自动分组为子特征,每个子特征有助于缩小目标身份的搜索空间。
(3)我们将常用的Triplet Loss替换为Supervised contrast Loss[5],这有助于网络更有效地学习。此外,提出了一种介于监督对比损失和交叉熵损失之间的自适应损失权值,显著提高了性能
3.1 域泛化
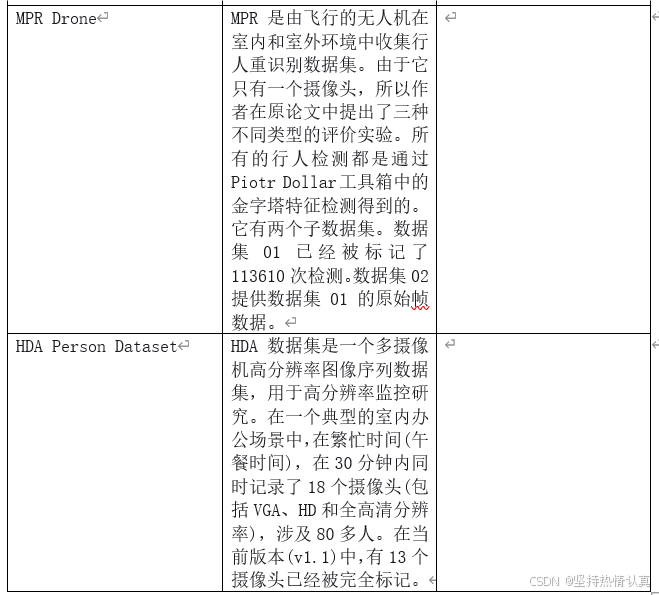
给定一个 batch的以及一个shuffle之后的,计算混合数据的统计特征: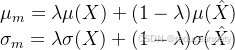 ,其中是beta分布。
,其中是beta分布。
则可将MixStyle规定为![]() ,很显然是有可学习参数的。事实上之后的网络分析部分我们就可以看到MixStyle是作为一个model层出现的。起到对两个领域图像的正则化(normalized)作用。
,很显然是有可学习参数的。事实上之后的网络分析部分我们就可以看到MixStyle是作为一个model层出现的。起到对两个领域图像的正则化(normalized)作用。
3.2 网络体系结构
Backbone:网络骨干,实例批处理归一化(Instance Batch Normalization, IBN)网络族
利用实例归一化,特征提取器可以学习对外观差异不变的鲁棒编码表示。其次,它可以提高ResNet、ResNeXt和SENet等其他高级深度神经网络架构的性能。
值得注意的是在Backbone中加入了上面提到的MixStyle,而且给出了网络插入位置的考虑,即“早阶段卷积层对样式信息进行编码,而后期则倾向于捕获语义内容”,因此将MixStyle加入到了Block1与Block2之间(即早期阶段,以学习到更多的特征)。
Multi-head with Attention Mechanism:多头注意机制
解决Re-ID问题的方法目前就那么几种,其中注意力机制是最为有效的方式之一
与只使用一个头部相比,使用多个头部可以鼓励重新识别模型从不同的车辆特征中学习更多不同的特征。因此,我们采用多头架构来进一步提高车辆重新识别的视觉表现质量。
3.3 损失函数
3.3.1
统一描述:一般地,训练一个Re-ID模型,常用的方法是结合ID loss和Metric loss。而交叉熵(CE)一般被作为ID loss,用于对不同类别的样本进行分类,而Metric loss通常是对比损失,例如Triplet loss或Circle loss,以优化每个类别之间的特征距离。
在深度学习中,特征(features)是用于描述数据实例的属性或测量值,它们帮助模型理解和预测目标变量。当我们谈论“正特征”和“负特征”时,这通常不是深度学习中的标准术语,但在某些上下文或应用中,这样的概念可能被用来描述特征与目标变量之间的关系。
一般来说,可以这样理解:
-
正特征(Positive Features):这些特征与目标变量的正面或增加趋势相关联。换句话说,当这些特征的值增加时,目标变量的值(例如,分类任务中的某一类别的概率,或回归任务中的预测值)也倾向于增加。例如,在预测房价的任务中,房屋面积(假设其他条件不变)可能是一个正特征,因为更大的面积通常意味着更高的价格。
-
负特征(Negative Features):这些特征与目标变量的负面或减少趋势相关联。当这些特征的值增加时,目标变量的值倾向于减少。在同样的房价预测例子中,房屋的维护状况(假设用某种量化指标表示,且较高值表示较差的维护状况)可能是一个负特征,因为较差的维护状况通常会导致房价降低。
3.3.2 Constructing Adaptive Loss Weight
训练ReID模型需要优化ID Loss和Metric Loss的组合。通常,损失权值是相等的,即1:1的比例。但在实际应用中,ID Loss相对于Metric Loss要大得多,这会造成不平衡,影响训练性能。
在自适应损失权重调整的激励下,我们提出了动量自适应损失权重(Momentum Adaptive Loss Weight, MALW),通过根据损失值的统计特征自动更新损失权重来提高训练稳定性。
自适应权重算法

动量适应性减重。算法1和图4描述了MALW如何在训练过程中更新权重。设λID和λMetric分别为ID loss和Metric loss的损失权值。初始设置λID和λMetric的比值为1:1。经过K次迭代训练后,根据记录的ID loss LID和Metric loss LMetric的标准差,带动量因子更新ID损失权值λID。
MSINet: Twins Contrastive Search of Multi-Scale Interaction for Object ReID:ReID对象的多尺度交互的孪生对比搜索
Abstract
神经结构搜索(NAS)在对象再识别(ReID)领域受到越来越多的关注,因为它的特定任务结构显著提高了检索性能。以往的研究为NAS ReID探索了新的优化目标和搜索空间,但忽略了图像分类与ReID训练方案的差异。在这项工作中,我们提出了一种新的双胞胎对比机制(TCM),为ReID架构的搜索提供更合适的监督。TCM减少了训练和验证数据之间的类别重叠,并帮助NAS模拟真实的ReID训练方案。然后,我们设计了一个多尺度交互(MSI)搜索空间来搜索多尺度特征之间的合理交互操作。此外,我们还引入了空间对齐模块(Spatial Alignment Module, SAM),以进一步增强不同来源图像的注意力一致性。在提议的NAS方案下,一个特定的体系结构被自动搜索,命名为MSINet。大量的实验表明,我们的方法在域内和跨域场景上都优于最先进的ReID方法。
1 Introduction
对象重新识别(Re-ID)旨在从不同的视图中检索特定的对象实例[39,40,57,65,70],因其广泛的应用而受到计算机视觉界的广泛关注。以往的工作在有监督的[42,49,58]和无监督的ReID任务[17,50,78]上都取得了很大的进展,其中大部分采用了原本为一般图像分类任务设计的骨干模型[20,52]。
最近的文献[64,75]表明,应用不同ReID上的体系结构会导致很大的性能变化。
一些研究采用神经结构搜索(NAS)进行ReID[28,45]。所提出的优化目标和搜索空间稳定地提高了模型性能,但主要的搜索方案仍然沿用传统的针对一般分类任务设计的NAS方法[12,36]。
ReID作为一个开放集任务,在训练集和验证集中包含不同的类别[64,71],而在标准分类任务[10]中,这两个集共享完全相同的类别,这也是传统NAS方法所遵循的。搜索方案和真实训练方案之间的不兼容性使得搜索的体系结构对ReID来说不是最优的。此外,与图像级分类相比,ReID需要在细粒度实例之间区分更细微的区别[48,63]。
先前的一些研究[4,44,68,75]表明,局部视角和多尺度特征对ReID具有区别性。
但目前对这些特性的利用多是经验性设计,可以根据不同网络层的特点更加灵活。
在这项工作中,我们提出了一种新的NAS方案,旨在解决上述挑战。为了模拟真实的ReID训练方案,提出了一种孪生对比机制(TCM)来解绑定训练集和验证集的类别。可调整的类别重叠比例建立了NAS和ReID之间的兼容性,为ReID架构搜索提供了更合适的监督。此外,为了更合理地利用多尺度特征,我们设计了一个多尺度交互(MSI)搜索空间。MSI空间侧重于多尺度特征之间沿网络浅层和深层的交互操作,引导特征之间相互促进。此外,为了进一步提高模型的泛化能力,我们提出了一个空间对齐模块(Spatial Alignment Module, SAM)来增强模型在面对不同来源图像时的注意力一致性。通过上述NAS方案,我们获得了一种轻量级而有效的模型体系结构,称为多尺度交互网络(MSINet)。
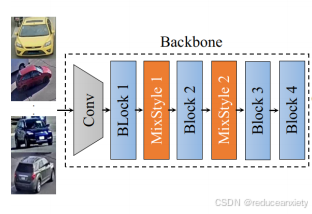
我们在图1中可视化了在VeRi-776[38,39]上训练的MSINet和ResNet50[20]的示例激活图。与ResNet50相比,MSINet侧重于使用特定语义信息来识别实例的更独特的区别。此外,MSINet极大地增加了查询图像与相应负样本之间的距离差,体现了非凡的判别能力。广泛的实验表明,MSINet在域内和跨域场景上都超过了最先进的(SOTA) ReID方法。
贡献
1.据我们所知,我们是第一个根据现实世界的ReID训练方案构建NAS搜索方案的人,这为ReID架构搜索提供了更合适的监督。
2.我们提出了一种基于多尺度交互(MSI)操作和空间对齐模块(SAM)的新型搜索空间,以提高模型在域内和跨域场景下的性能(泛化能力)
3.我们为ReID任务构建了一个轻量级但有效的架构,表示为MSINet。MSINet仅使用230万个参数, MSINet 在MSMT17 上超过 ResNet50 [20] 9% mAP
MSINet 在Market-1501 上超过 ResNet50 [20] 16% mAP
2.Related Works
神经结构搜索
NAS以其自动化架构设计的特点,越来越受到计算机视觉界的青睐。
NAS方法大致可分为四类:强化学习[1,77]、进化算法[35,46]、梯度下降[36,43]和性能预测[11,34]。
Liu等人建立了一种可微分架构搜索(DARTS)方法[36],在很大程度上提高了NAS的实用性。
后来的一些研究通过采样策略[62]、网络修剪[2,8]、渐进式学习[5]、协同竞争[7]等进一步改进了结构。
大多数NAS工作集中在一般的图像分类任务上,其中训练集和验证集共享完全相同的类别。然而,这样的设置会导致对象ReID与现实世界的训练方案不兼容。在这项工作中,我们解除了两个集合之间的类别绑定,并提出了一种适合于ReID的新搜索方案。
ReID网络设计
目前的ReID作品多采用为图像分类而设计的主干[20,23,47,52]。
一些作品[14,31,67]设计了基于共同主干的注意模块,以挖掘其在区分局部差异方面的潜力。然而,这些方法通常会导致大量的计算消耗。
还有一些作品专注于设计特定于reid的架构。
Li等人提出了一种过滤器配对神经网络来动态匹配特征映射中的补丁[30]。
Wang等人使用WConv层对两个样本的特征进行分离和重组[56]。
Guo等人提取多尺度特征,直接评价样本之间的相似性[18]。然而,连体结构在大型画廊进行检索时不方便。
Zhou等人聚合多尺度信息,以较小的计算消耗实现高精度[75]。
Quan等人在dart搜索空间中引入了一个部件感知模块[36,45]。
Li等人提出了一种新的感受野尺度搜索空间[28]。这些方法在有限的参数尺度上有很好的性能,但无法超越复杂结构的网络。
与以往的工作不同,我们设计了一个轻量级的搜索结构,关注多尺度特征之间的合理交互操作。搜索的MSINet在域内和跨域任务上都优于SOTA方法。
SOTA,全称是“State Of The Art”,在科技、学术和工程领域中,通常指的是某一特定任务或领域中的最先进(或最优)的技术、方法或性能水平。在提供的文本中,SOTA方法指的是在行人重识别(ReID)领域中的当前最先进的方法。
具体来说,文中提到的SOTA方法包括:
- 基于图像分类任务设计的骨干网络(backbones),如[20, 23, 47, 52]等文献中提到的网络。
- 基于通用骨干网络设计的注意力模块(attention modules),这些模块旨在挖掘骨干网络在区分局部差异方面的潜力,如[14, 31, 67]等文献中提到的模块。然而,这些方法通常会导致较大的计算消耗。
- 针对ReID任务设计的特定架构,如Li等人提出的Filter Pairing Neural Network(FPNN)动态匹配特征图中的补丁[30];Wang等人使用WConv层分离和重组两个样本的特征[56];Guo等人提取多尺度特征来直接评估样本之间的相似性[18];以及Zhou等人聚合多尺度信息以实现高精度和低计算消耗[75]。
- 通过神经架构搜索(NAS)得到的网络,如Quan等人将部分感知模块引入DARTS搜索空间[36, 45];Li等人提出了一个新的关于感受野尺度的搜索空间[28]。
然而,文中也指出,尽管这些方法在有限的参数规模下表现优异,但它们仍然未能超越具有复杂结构的网络。因此,作者提出了一种新的轻量级搜索结构,即MSINet,该结构专注于多尺度特征之间的合理交互操作,并在域内和跨域任务上都超越了当前的SOTA方法。
总的来说,SOTA方法是不断发展和变化的,随着技术的进步和研究的深入,新的SOTA方法会不断涌现。
3.Methods
目标是构建一个有效的NAS方案,寻找适合ReID任务的轻量级骨干架构。在ReID训练方案的基础上,我们提出了一种新的双胞胎对比机制,为搜索过程提供更合适的监督。针对多尺度特征之间的合理交互,设计了一个多尺度交互搜索空间。我们进一步引入了空间对准模块,以提高在参数增长有限的情况下的泛化能力。
3.1 双胞胎对比机制
NAS旨在为特定的数据自动搜索最优的网络架构。受[36]的启发,一个基本的可微体系结构搜索方案建立了。我们将普通模型参数定义为ω,结构参数定义为α。对于搜索空间为0的网络层i, αi控制该空间中各操作0的权值。特征通过所有操作并行传递,最终输出由操作输出的softmax加权和表示:
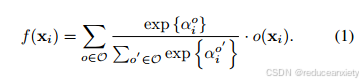
搜索过程以另一种方式进行。使用训练数据更新模型参数,然后使用验证数据更新体系结构参数。对于大多数设计用于图像分类任务的NAS方法,训练和验证数据共享完全相同的类别和用于损失计算的线性分类层。
与标准图像分类不同的是,ReID作为一个开放集检索任务,在训练集和验证集上有不同的分类。搜索方案与真实训练方案之间的不兼容性可能导致搜索结果不理想。因此,我们提出了一种新的双胞胎对比机制(TCM)用于NAS ReID训练。具体来说,我们使用两个独立的辅助存储器Ctr和Cval分别存储训练和验证数据的嵌入特征。记忆用质心特征初始化,质心特征通过平均每个类别的特征来计算。每次迭代时,首先用Ctr计算训练损失,更新模型参数。

其中,c n tr表示类别n的记忆特征,Nc tr表示训练集中的类别总数,τ为温度参数,经验取0.05[17]。更新模型参数后,将类别标号为j的嵌入特征f整合到对应的记忆特征c j tr中,方法为:
![]()
其中β经经验设定为0.2[17]。然后对更新后的模型在验证数据上进行评估,以Cval代替式2中的Ctr生成验证损失。然后使用验证丢失更新体系结构参数,以完成迭代。
由于损失计算不依赖于线性分类层,因此训练集和验证集的类别是不绑定的。我们可以动态调整这两个集合中的类别重叠比例。适当的重叠比的优点概括为两个方面。首先,TCM更好地模拟了ReID的真实训练,帮助模型专注于真正的判别区别。训练数据和验证数据的差异提高了模型的泛化能力。其次,通过与模型参数更新一致的优化目标,使相对较小比例的重叠类别稳定地更新体系结构参数。
3.2. 多尺度相互作用空间
虽然在以往的ReID作品中已经研究了局部视角和多尺度特征[4,28,44,51,68,72,75,76],但这些信息的利用主要是经验设计的聚合,比较单调和受限。我们认为,一方面,多尺度特征的合理利用应沿着网络的浅层和深层进行动态调整。另一方面,引入交互而不是聚合创建了直接的信息交换,更充分地利用了多尺度特征。因此,我们提出了一种新的多尺度交互(MSI)搜索空间,以建立适合于ReID的轻量级架构
如图2所示,网络主要由MSI cell和down-sample block组成,这与OSNet基本一致[75]。
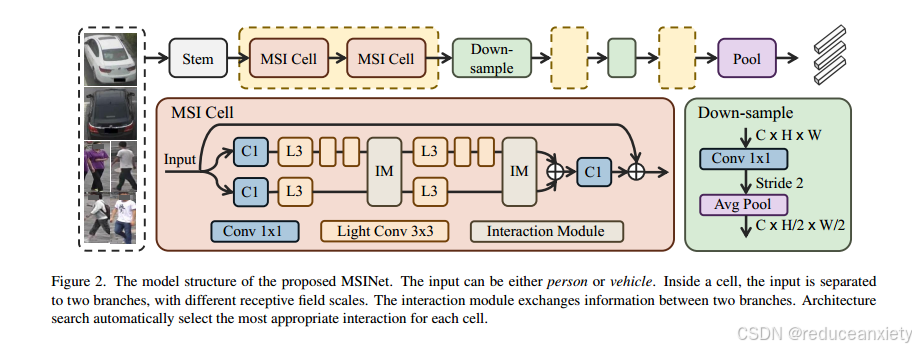
在每个细胞中,输入特征通过具有不同感受野规模的两个分支传递。为了减少网络的计算负担,对于每个分支内部的层,我们采用1×1卷积的堆栈和多个深度3×3卷积来实现特定的尺度。两个分支的比例比ρ为3:1。这两个分支不共享模型参数,除了交互模块(IM)。IM引入了两个分支机构之间的信息交换。IM有4个操作选项。将两支路输入特征定义为(x1, x2),运算可表示为:
无:任何操作都不涉及任何参数,并准确地输出输入特征(x1, x2)。
交换:交换是所有选项中最强的交互。它直接交换两个分支的特征并输出(x2, x1)。Exchange也不包含额外的参数。
通道的门:通道门引入了一个多层感知器(MLP)来生成一个基于通道的注意门[61,75],如下:
![]()
返回(G(x1)·x1, G(x2)·x2)。MLP由2个完全连接的层组成,其参数为两个分支共享。从而通过联合筛选判别特征通道实现交互。
交叉的注意力:传统的通道关注模块计算单个特征映射内的通道相关性[15]。首先将原始特征映射x∈RC×H×W重塑为查询特征x≈∈RC×N,其中N = H× w,然后通过在查询特征x≈与关键特征x≈∈之间进行矩阵乘法来计算相关激活。我们建议交换两个分支的密钥,以显式地计算彼此之间的相关性。然后将相关激活转换为掩模,并以可学习的比例与原始特征相加。
相互作用后,通过求和运算融合多尺度分支。值得注意的是,多个交互选项带来的额外参数是有限的,这使得可以沿整个网络独立搜索每个cell。在网络的开始,我们使用与OSNet中相同的stem模块[75],包含一个7 × 7的卷积层和一个3 × 3的最大池化,其步长为2。搜索过程结束后,保留每层权值α o i最大的交互操作o,形成搜索体系结构。
在搜索体系结构之后,在各种Re-ID任务上验证模型。
The training is constrained by the classification id loss and the triplet loss, formulated by:
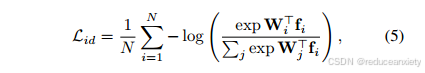
其中fi为特征向量,其对应的分类器权值为Wi,
![]()
式中fa、fp、fn为锚点的嵌入特征,为小批量中最硬的正、负样本,D(·,·)为欧氏距离,m为边界参数,[·]+为max(·,0)函数。
3.3. 空间对齐模块
目标ReID任务的检索精度在很大程度上受相机条件变化时姿态、光照和遮挡等外观变化的影响。
为了使模型正确、一致地聚焦于判别空间位置,我们设计了一个空间对齐模块(spatial Alignment Module, SAM)来显式对齐图像之间的空间注意力,如图3所示。
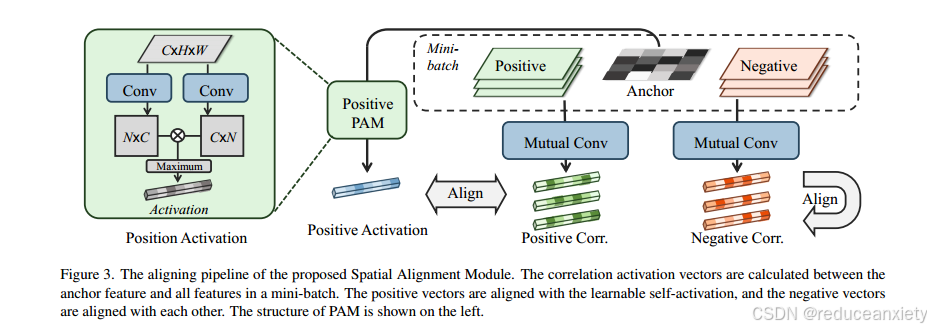
具体来说,我们首先计算minibatch中特征映射之间的位置相关激活图A。样本i与j之间的激活可以表示为:A(i, j) = x≈∈j × x≈i,其中x≈∈RC×N是由原始特征x∈RC×H×W重塑而来。然后取样本i每个位置的最大激活值为:
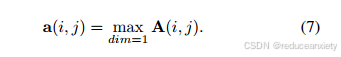
上述过程在图3中表示为“相互转换”。
我们用余弦相似度来评价激活向量之间的一致性。
特别是对于阴性样本,可以有许多不同的识别提示,其中一些可能是不合适的,例如背景。通过对齐样本i的所有相关性,我们希望网络可以纠正一些注意偏差,并始终专注于判别性位置。
然而,通过对正样本对的对齐,期望能强调id相关的特征,这是通过对负样本对的对齐无法实现的。因此,我们引入了一个额外的位置激活模块(PAM)来对正对之间的对齐产生监督。
空间对中损失公式为:
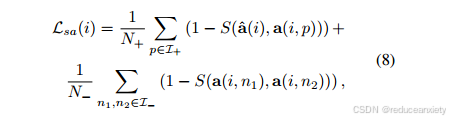
其中I+包含样本I的正指标,样本I的总数为N+,反之亦然。a´(i)表示生成的样本正对齐激活向量,S(·,·)表示余弦相似度。
4. Experiments
Strength in Diversity: Multi-Branch Representation Learning for Vehicle Re-Identification*:多样性的优势:车辆再识别的多分支表示学习*
摘要:本文提出了一种高效、轻量级的多分支深度体系结构,用于改进车辆再识别(V-ReID)。虽然大多数V-ReID工作使用复杂的多分支架构组合来提取健壮且多样化的重新识别嵌入,但我们主张可以设计简单且轻量级的架构来完成重新识别任务,而不会影响性能。
我们提出组合分组卷积和LossBranch-Split策略来设计一个多分支架构,以提高特征多样性和特征可分辨性。
我们将ResNet50全球分支架构与僵尸网络自关注分支架构相结合,两者都是在损失分支分裂(LBS)策略中设计的。我们认为专门化的损失分支分割通过生成专门化的再识别特征,有助于改进再识别任务。还提出了一种使用分组卷积的轻量级解决方案,以模拟将损失分割为多个嵌入的学习,同时显着减小模型大小。此外,我们设计了一个改进的解决方案来利用额外的元数据,如相机ID和姿势信息,使用的参数减少了97%,进一步提高了再识别性能。
与最先进的(SoTA)方法相比,我们的方法在Veri-776中实现了85.6%的mAP和97.7%的CMC1,并在Veri-Wild中获得了88.1%的mAP和96.3%的CMC1的竞争结果。
深度神经网络(dnn),特别是卷积神经网络(cnn),通过显著优于依赖手工制作特征的传统方法,彻底改变了计算机视觉任务。然而,基于cnn的V-ReID仍然面临着很大的挑战,因为类间的相似性和类内的差异,例如相同型号和颜色的不同车辆或相同的车辆,从不同角度观察时具有完全不同的外观的
为了解决这些挑战,我们提出了一种方法,通过使用不同学习的多个表示来生成更鲁棒的图像特征。我们的模型将具有不同架构、损失或应用于不同渠道组的多个分支学习的各种全局表示连接起来,以获得更好的结果。我们提倡使用具有专用损耗的多个分支学习,不同的架构或每个分支在不同的通道组上运行,为V-ReID任务提供了几个优势:
提高特征多样性:骨干网的每个分支学习不同的特征,使用多个分支可以增加捕获特征的多样性。这可以更好地区分不同的车辆,提高再识别系统的准确性。
减少过拟合:当使用单个分支进行特征提取时,存在训练数据过拟合的风险。然而,通过使用多个分支,模型可以学习数据的多个表示,这有助于减少过拟合并提高对新数据的泛化。
增强的健壮性:多个分支可以帮助模型对输入数据的变化变得更加健壮。社区已经证明,通过使用不同设计或学习不同数据和损失的多个分支架构,除了更有效的训练和改进的可扩展性外,还可以提高性能和更好的特征表示,使其成为对象重新识别任务的强大方法。
我们的方法不是依赖于基于部件或基于属性的技术,这些技术也需要多个分支或额外的模型,而是采用了更丰富、更具表现力的全局嵌入的集合,从而增加了灵活性、提高了可转移性和增强了鲁棒性
贡献
使用损失-分支-分割(Loss-Branch-Split, LBS)架构,该架构聚合每个分支的不同架构和损失,以生成不同的全局嵌入。
利用自关注分支来捕获车辆不同部件之间的局部依赖关系。
使用分组卷积获得LBS架构的轻量级模型,克服LBS架构增加的复杂性。
有效利用CNN的额外元数据信息,即摄像头ID和车辆姿势
总之,我们提出的改进方案通过结合一些新颖有效的策略来解决cnn的V-ReID挑战。我们的解决方案通过架构修改和使用每个分支的不同损失来提取不同的车辆表示,并通过有效地利用额外的元数据,提高了重新识别任务的准确性和性能。
相关工作
车辆再识别问题有多种解决方法,包括基于零件的、基于属性的、基于局部的、自监督的、和全局方法。正如我们的,许多这些方法在最后阶段或模型上使用多个分支来提取全局表示的附加信息并生成更健壮的特征。
然而,精度增益与计算成本之比有时不够好,限制了这些方法在实时应用中的使用。
基于部件的方法包括捕获车辆的特定部件,以帮助车辆的重新识别。例如,PEVEN使用分割模型来识别车辆的可见部件,并生成特定于这些部件的嵌入,例如车辆的前部、后部、侧面和顶部。他等人使用检测模型来识别更精细的部件,如挡风玻璃、品牌标志和灯光,以生成基于部件的嵌入。Lee等人也使用多重表示,通过将全局嵌入聚合到n-1个由空间和通道注意生成的基于注意的部分特征。其他基于部分的策略,如Wang等人利用多分支提取不同粒度的局部特征,在每个分支上水平分割最终特征n次。这些模型通常需要额外的模型或分支来检测特定的部件,因此计算成本很高
基于属性的方法也在主干的后期阶段使用多个分支来提取与每个属性相关的全局表示之外的嵌入,或者使用注意力从全局特征中提取属性嵌入。
自监督方法尝试使用输入数据来改进表示,以生成自己的监督。例如,Khorramshahi等人使用变分自编码器在无法重建的不常见部分获得关注,而在中使用师生框架,其中教师是学生的动量编码器,每个人都输入不同的图像作物,如DINO。Li等使用额外的ResNet-18模型,通过不同的旋转捕获注意力图来获取“地标”,以学习全局特征。
其他方法旨在改进全局嵌入,如通过不同主干、多分支、基于图的和后处理技术。Zhai等提出了一种与此思路相同的多分支方法。
与我们不同的是,他们采用了以通道分组和多分支策略为特征的re-id框架,将全局特征向量划分为多个通道组,并通过由交叉熵分类损失唯一驱动的多分支分类层学习判别通道组特征。他等人[12]使用附加信息作为输入来改进结果。在我们的工作中,我们设计了一个适用于CNN的相同策略,其计算成本不到CNN的3%。
我们的工作也使用了多分支架构,但我们不是提取部分、属性或局部特征,而是使用不同的架构提取全局多样化的特征,并在每个分支上应用不同的损失学习策略。我们主张在ReID任务中通常联合使用的分类和度量损失可以在专门分支中单独考虑时提供更多的判别嵌入。此外,通过分组卷积,我们允许LBS和不同的架构在不同的通道组中操作每个分支,同时减小模型的大小。与竞争类似大小的模型相比,我们通过简单而强大的架构修改展示了显著的性能和准确性改进。
方法
方法部分描述了解决车辆重新识别任务所采取的方法。该方法结合了使用多分支体系结构学习的多个全局描述符。该建筑被分成N个分支,每个分支都产生一个独特的全局嵌入。
每个分支都有专门的任务,并获得特定类型的特征提取,从而获得更健壮和信息丰富的总体表示。
为了实现这种表示,我们采用了ResNet50深度架构来适应每个分支的不同损耗,并合并了一个变压器分支[18],以使用自关注来检索多样化的特征。我们进一步利用了类似于[12]的附加元数据,但适应了CNN的元数据。
a .多分支全局嵌入
提出的体系结构是专门设计来提取多个全局嵌入,通过探索多分支体系结构,利用分支特定的体系结构模型和分支损失专门训练(MBR)。如图2所示,我们的网络结构由两个主要模块组成,一个是全局模块,一个是注意力模块,它们可以在分支架构中进行独特的组合,以提取多样化的嵌入。
每个分支最近在端到端CNN框架中与元数据信息相结合,进一步提高了再识别能力。
骨干网由ResNet50-IBN (Instance Batch Normalization)组成[19]。全局模块使用ResNet50的第4层提取全局嵌入,而注意力模块使用僵尸网络转换器结构提取全局关注嵌入。
我们考虑每个损失的不同分支,一个单独用于分类,另一个仅依赖于度量损失。
通过拆分损失函数,我们允许系统明确区分身份的语义理解(分类损失)和特征嵌入的判别能力(度量损失)。图3展示了MBR4B体系结构,它利用了特定于损失的分支训练,并在每个体系结构模块上合并了两个不同的分支。
系结构的N个分支共享权重,直到主干的倒数第二层Fs123 (x;θs)输出一个特征映射fL3∈R 16×16×1024。每个分支都有自己的第4阶段FN4 (fL3;θN),如图3所示。每个分支由,fN (x) = GAP[FN4 (Fs123 (x;θ;θN)],(1)其中fN为第n个结果嵌入,FN4为第n个分支层,Fs123为直到最后一层的骨干层,GAP为全局平均池化,θs为共享权值,x为输入图像,θN为第n个分支权值。
这个架构输出一个嵌入fN∈R D,其中对于所使用的N个分支中的每一个,D = 2048,这些分支被L2归一化以做出相同的贡献,然后连接起来得到最终的表示fg∈R DN。
1) ResNet50全球分支(R50):全球分支旨在捕获全球表示,并简单地将骨干网架构(ResNet50- ibn)的最终(第四层)调整为基于分支的配置。
2)瓶颈转换分支(Bottleneck Transformer Branch, BoT):注意力分支模块旨在通过自关注捕获本地依赖关系,这可以追溯到僵尸网络[18]的架构修改,也被[7]采用和修改
这种修改将第四个ResNet层的最后三个瓶颈块[20]替换为多头自注意(MHSA)块(见图3),以实现对2D特征图的all2all注意。MHSA在四个头之后使用[18]。与原始阶段相比,BoT块减少了参数,同时通过自注意从图像中获得不同的信息。
B.分支分组卷积
专注于损失分割的多分支架构表示,我们设计了一种轻量级的替代方案,采用分组卷积[21],也用于ResNeXt[22]。
卷积不是在所有输入通道上进行卷积,而是在G群中进行卷积。这种方法可以生成一个嵌入fN∈R D G的输出,其中D为G组的Cin/G × Cout/G滤波器串接的输出响应的输出维数,每个组对应不同的支路。考虑到每个分支计算Cout的次数是Cin的一小部分,它减少了参数计数。。
每个分支g作用于不同的通道输入特征组fL3 (g)∈R 16×16×1024 g,其中g = 1,···,g,与多分支不同,每个分支作用于相同的特征集fL3∈R 16×16×1024。
该策略允许保留LBS架构,其中我们由于G组模仿N个分支而生成G个分离的特征,同时保留共享的浅层参数,而深层则学习有关每个损失的更复杂的特征。与包含多个N个分支会引入过多的参数开销相反,在此场景中添加额外分支实际上会降低模型的复杂性。我们将这些体系结构定义为MBR-G,并且训练策略与等效的MBR-B保持相同。
C.利用附加信息(LAI)
我们设计了一个基于CNN的策略来利用图像捕获固有的元数据。与车辆类型、型号或颜色等必须推断并可能导致错误结果的细节不同,特定的相机和方向元数据在现实世界中很容易访问。
接下来,我们零初始化一个边嵌入矩阵a∈R N×D×Ncam×Nview,其中Ncam×Nview表示相机和视图方向可用标签的总数。然而,与在补丁级计算位置嵌入的相反,我们将此信息添加到每个fN全局嵌入输出中。根据输入摄像机c和视图v的配置,选择相应的侧嵌入Acv∈R N×D并添加到全局分支中。由于之前方法的补丁总数明显高于分支数量(256 vs 4),因此我们的方法需要的操作参数明显更少(例如,0.33M × N vs Veri-776中的31.46M)。在依赖分组卷积的版本中,我们有0.33M个参数,因为fg∈R D保持不变。根据图像的相机和视图配置,将这些可学习的参数加入到聚合特征中,如图2所示,并在模型训练时进行估计。
D.损失分支和训练对于训练
分类损失和度量损失的组合使用。在Loss-Branch-Split (LBS)策略之后,每个体系结构的损失源自一个独立训练的专门分支。
1)分类分支:体系结构的分类分支专门用于分类任务,提取可以识别特定ID的细粒度信息。嵌入提取后,密集层将向量从R D/G降为R C,降为训练(C)中的类数。
接下来,应用softmax,计算标签平滑后的交叉熵损失[23],其定义为:

2)度量分支:
度量分支负责捕获从不同视图中具有代表性的特定细节的嵌入。它使用批硬三重态损失,其中批是使用随机PK抽样构建的,由P个身份和属于一个身份的K个样本组装而成。批硬是指在每个批内形成三胞胎,将每个图像视为锚点,获得“最难”的样本,简而言之,最难的正面是距离锚点距离最大的同一身份的图像,最难的负面是距离锚点最近的不同身份的图像。该技术比传统的三元组方法取得了更好的结果,因为它挖掘了硬三元组,而不是像[24]中所解释的那样,随机选择阳性和阴性样本,这些样本可能因为不产生任何损失而无法提供信息。损失表示为:
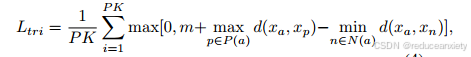
其中,P、K、m、P(a)、N(a)分别为批中每个给定锚点的恒等式个数、属于该恒等式的样本个数、距离边际阈值、正样本集和负样本集。其中xa, xp, xn分别代表锚、正、负样本的提取嵌入。其中,d()为欧氏距离。
3)网络训练:
按照提出的LBS架构,对每个分支损失进行独立训练,通过对每个分支损失i进行加权线性组合得到全局目标损失L,得到
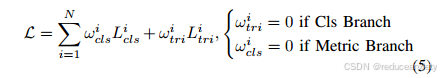
每个损失权重ωi通过交叉验证进行调整。
实验结果
在本节中,我们展示了我们在两个广泛使用的数据集上的实验结果:Veri-776[25]和Veri-Wild[26]。我们首先概述数据集及其规范,然后描述我们提出的体系结构实现细节。我们根据mAP(平均精度)和CMC(累积匹配曲线)在排名1和5的百分比报告了我们的发现,使用标准的图像到图像检索过程,根据相似性分数对每个查询图像对整个图库进行排名。我们也提出消融研究来巩固我们的建筑方案。最后,我们将我们的结果与最先进的方法进行比较。所有报告的值都不包括后处理技术。
A Dataset
我们评估的数据集是Veri776[25]和VeriWild[26]。Veri-776包含了由20个不同的摄像机拍摄的776辆汽车的图像,没有视野限制。数据集分为37778张训练图像、1678张查询图像和11579张图库图像。Veri-Wild由174台摄像机拍摄的40671辆汽车组成,这些摄像机具有更有限的视点(前、后),但具有严峻的光照和天气条件。训练集包含277597张30671个身份的图像,验证集包含3个子集(S、M、L),分别包含3000张、5000张和10000张查询图像,以及38861张、64389张和128517张图库图像。
B. Implementation Details:实施细节
基线架构和方法是基于[27]实现的。考虑到ResNet50IBN在ReID任务中的有效性,我们使用ResNet50IBN[19]代替ResNet50,并将最后一个卷积阶段步幅修改为1。
输入图像被调整为256 × 256像素,并在训练期间使用标准增强技术进行增强,例如从10像素填充的图像中进行256 × 256随机裁剪、水平翻转和随机擦除。为了构建训练批次,我们执行了类似于[13],[6],[14],[7]的PK采样策略,该策略基于每个数据集的每个身份的图像数量。在Veri-776上P = 6和K = 8,在Veri-Wild上P = 32和K = 4,分别产生48和128个批大小。
除了BoT块之外,所有模型层都在ImageNet上使用预训练的权重。模型在每个数据集上进行120个epoch的训练,使用Adam优化器,学习率为1e-4, 10个epoch的线性预热,并在epoch 40、70和100以0.1的因子递减步骤。为了将随机初始化的BoT块与预训练的权重对齐,我们采用了两步微调方法。最初,我们在包含BoT的架构中冻结了前三个骨干阶段,同时使用相同的优化器以固定的学习率1e-4训练其余层10个epoch。随后,我们使用前面的设置对完整的模型进行训练。分类损失的标签平滑系数为λ = 0.1,三元组损失的裕度为m = 0.1。通过交叉验证对MBR超参数进行了经验调整,即分类损失权值设为ωcls = 0.6,度量损失权值设为ωtri = 1.0。在LAI模型上,我们使用每个数据集中可用的元数据,即Veri-776上的相机ID和车辆视图,以及Veri-Wild上的相机ID。
为了证明V-ReID的性能如何受到通过多个分支、损耗和架构增加的特征多样性的影响,我们在Veri-776数据集上进行了一系列的消融研究。图5展示了一些结合了不同损失和体系结构的多分支体系结构(MBR),其中B表示特征分裂分支的数量,G表示分支分组卷积分裂的数量。
具有卷积块(R50)和混合块(R50+BoT)的体系结构使用组合损失(CE+Triplet)及其各自的损失-分支-分裂(LBS)变体(分别表示为MBRR50和MBR)进行训练。
1)多分支的多样性:
首先,我们评估了如何用R50块生成特征多样性。在表1中,我们给出了不同体系结构的结果,
可分为扩展分支(R50-2B、R50-4B)、分组分支(R50-4G、R50-2G)或两者的组合(R50-2x2G)。
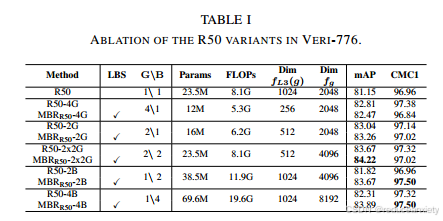
表1中的结果揭示了以下几点:(I)架构分支总是导致mAP增益;(ii)分组分支比扩展分支性能更好。如果没有LBS,通过扩展进行分支会导致复制相同的分支,依靠相同的特征来学习相同的任务。相比之下,分组为每个分支提供了一组不同的通道分组特征来执行相同的任务;(iii)结合两组(R50-2x2G)实现了2.52% mAP和0.36% CMC1的提升,与基线架构的参数相同,以及1.66% mAP和0.42% CMC1的提升一半参数(R50-4G)。
2)具有损失分支分割的多样性:
在表1中报告的所有架构中使用LBS可以改善这两个指标。MBRR50-2x2G架构的mAP增加了0.55%,而MBRR50-2B和MBRR504B模型的mAP分别增加了1.85%和1.58%。除了MBRR50-4G之外,与度量和分类组合损失相比,所有架构都提高了带有LBS的mAP分数,通常是在mAP和CMC1分数之间进行权衡。这些发现支持了多分支和LBS可以为V-ReID的特征表示引入更大多样性的观点。
3)多样性与注意力:
表2给出了将全局分支和注意力分支结合起来的结果,包括一个BoT基线和三种基于注意力的架构:MBR-4G、MBR-2x2G和MBR-4B。总的来说,我们注意到指标之间一致的权衡行为,正如在先前的评估中观察到的那样。然而,尽管这些整体得分较低,但多分支与注意力和LBS (MBR-4B)的组合在所有模型中都以84.72%的mAP和97.68%的CMC1超过了之前的结果。
这表明利用结合了BoT的分支在V-ReID任务中实现卓越性能的潜力。

4) LAI:
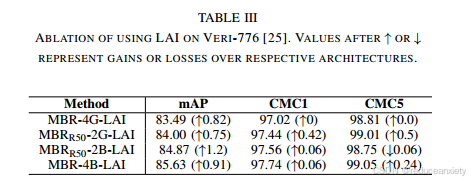
表III给出了所提出的LAI模块的烧蚀分析。我们在所有解决方案上的实验表明,mAP有大约1%的持续改进,CMC1有轻微的提高。
D.结果与最先进(SOTA)车辆识别率的比较见表4。
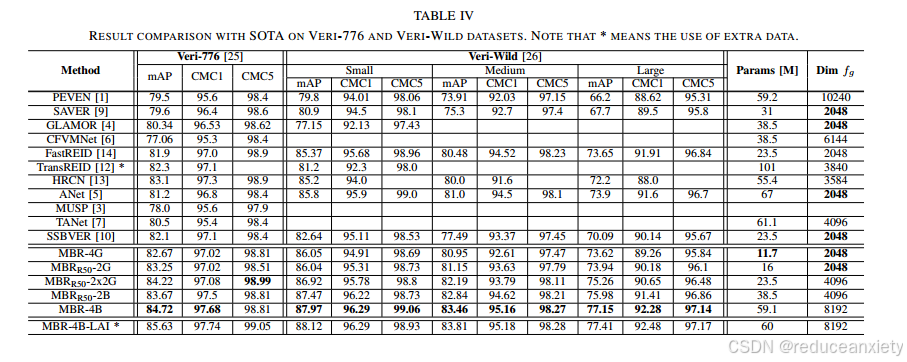
1)在Veri-776上的性能:在这个数据集中,即使没有额外的元数据,我们的模型也优于所有其他模型。与HRCN相比,MBR-4B模型比Veri-776的最佳分数高出1.62% mAP和0.38% CMC1[13]。此外,我们的MBRR50-2G匹配HRCN,模型参数减少3.46倍,嵌入尺寸减小。将LAI模块添加到我们的MBR-4B中,可以获得0.91% mAP和0.06% CMC1的额外增益,比TransREID[12]高出3.3% mAP和0.64% CMC1。此外,考虑到最近对模型大小及其吞吐量的兴趣[10],我们指出,我们的轻量级MBR-4G可以超越大多数旧作品,并且非常接近最近的作品,只需要一小部分参数。
2)在Veri-Wild上的性能:我们最大的变体MBR4B在小集上比ANet[5]高出2.17% mAP和0.39% CMC1。与批量大小为128的FastREID[14]相比,我们获得了2.6%的额外mAP和0.61%的CMC1。MBRR50-2G和MBR-4G架构展示了具有竞争力的轻量级解决方案,在参数较少的情况下,其性能比SSBVER[10]高出至少3.4% mAP。此外,与HRCN[13]等更大的解决方案相比,它们表现出了0.84% mAP和1.31% CMC1的优越性能。
五、结论:所开发的工作在车辆再识别中显示出竞争性结果。结果表明,多样性强度对V-ReID等检索任务至关重要。对组执行分割不仅提高了不同输入的多样性,而且可能对未来的实时应用程序有重大改进,因为它们在保持性能的同时减少了模型的大小。我们希望未来的工作可以在检索任务中进行多样化的表征学习实验。
指标的计算
1.CMC: Cumulative Matching Characteristics 累计匹配特征
CMC是一种计算 top-n 的评价指标,主要用来评估闭集中rank-n的正确率。
举例说明
在双模态特征匹配中。底库 Gallery 中有10条数据(label分别为1,2,3,4···10),现在来了一个待查询 query的数据(label = 1)。通过模型提取特征并计算相似度以后,如果和Gallery中的数据按照相似度从高到低进行排序后,得到的识别结果是:
{1,2,3,4,5···,10}, 因为第一个就已经匹配上了,所以说rank-1 = 100%
{2,1,3,4,5···,10}, 因为第一个计算出来的label是2,没有匹配上,因此 rank-1 = 0, rank-2 = 100%,rank -5同理肯定也是100% 因为前两个已经得到了正确的结果,那么前五个中一定包含正确的结果。
如果存在多条query数据时,CMC指标一般会直接 取平均 的做法
2. mAP: mean Average Precision
mAP全称:mean Average Precision。由多个类的AP值求平均得到,用以衡量多个类的检测好坏。mAP越大,说明模型越好。
AP全称:Average Precision(平均精度)。由PR曲线与X轴的面积得到,用以衡量一个类的检测好坏。AP越大,说明单个类检测的越好。
mAP就是AP值的平均
第三次任务
Combined Depth Space based Architecture Search For Person Re-identification:基于组合深度空间的人物再识别体系结构搜索
Abstract
大多数关于行人重识别(ReID)的研究使用像ResNet这样的大型骨干网络来提取特征,这些网络本质上是为图像分类而设计的,而非专门为ReID设计。因此,这些骨干网络可能在计算效率上不高,也未必是最适合ReID的架构。在本文中,我们提出了一种新的搜索空间,称为组合深度空间(CDS),用于设计轻量级的ReID网络。通过一种可微分的架构搜索算法,我们找到了一个有效的网络架构,称为CDNet。CDNet通过使用CDS中的组合基本模块,能够专注于通常出现在行人图像中的组合模式信息。此外,我们提出了一种低成本的搜索策略,名为Top-k样本搜索策略,旨在充分利用搜索空间,避免陷入局部最优解。同时,我们还提出了一种名为精细平衡颈(FBLNeck)的结构,能够在训练过程中平衡三元组损失和softmax损失的效果,并且该结构可以在推理阶段移除。广泛的实验表明,CDNet(大约1.8M参数)与最先进的轻量级网络具有可比的性能。
1.Introduction
行人重识别(ReID)的目标是从不同监控摄像头中(跨域)检索到特定行人的图像。自从AlexNet【16】在ILSVRC-2012【3】中提出以来,卷积神经网络(CNNs)在ReID任务中变得越来越流行。随着复杂模型的出现【34, 30, 7】,研究者们往往使用这些模型作为骨干网络,以在ReID任务中获得更高的性能。然而,这样的实现方式有两个明显的缺点。首先,它们过度依赖于骨干网络的性能,限制了研究人员探索更适合ReID的网络架构。其次,这些骨干网络在推理时需要大量的计算资源和时间成本,使其在某些计算资源有限的实际设备(如智能监控摄像头)上变得不可行。相反,通过在多个监控摄像头上部署轻量级网络,只需收集这些设备提取的特征来检索目标行人,而不需要收集原始图像并通过大型骨干网络进行处理,这样可以大大加快速度。基于这些原因,我们的目标是构建一个计算效率高、且更适合ReID的轻量级网络。
近年来,神经架构搜索(NAS)被用于寻找轻量且高效的网络架构。【52】利用强化学习搜索NASNet,耗时约2000个GPU天,这对于大多数研究人员来说时间过于昂贵。为减少高昂的搜索成本,【21】提出了一种新算法,称为可微分架构搜索(DARTS),利用梯度下降将搜索成本显著减少到4个GPU天。尽管搜索出的网络架构很小,但该方法仍然存在一些缺点。(1)单元包含大量复杂连接,妨碍并行计算。【20】也指出,不规则的单元结构对GPU并不友好。(2)该算法仅搜索普通单元和缩减单元,并将其应用于不同层。我们认为,CNNs往往在不同深度集中于不同的模式信息,因此在不同层次需要区别对待其结构。(3)在搜索过程中,该算法在前向传播时计算每个分支,即使某些分支的概率较低,贡献很小,仍会造成较重的计算成本。针对第三个缺点,【4】选择仅计算两个节点间权重最大的分支进行前向传播。然而,这种方法很容易陷入单一的局部最优网络架构中,因为梯度主要更新在所选的分支上,而其他可能的分支逐渐被忽视,因此该方法不能充分利用搜索空间。除了上述问题外,我们还观察到,当前大多数搜索空间无法明确学习ReID中特有的组合模式特征,这些特征具有很强的判别能力(见图1)。

为了解决上述问题,并充分利用NAS的优势来搜索轻量网络,我们提出了一种新颖的搜索空间,称为组合深度空间(CDS),以及一种新的搜索策略,称为Top-k样本搜索。在CDS中,我们设计了一个高效的组合模块(CBlock),该模块由两个不同的分支组成,具有不同的卷积核大小,可以明确学习组合模式信息。这样,CBlock仅有两个并行分支,对GPU更友好。此外,我们的Top-k样本搜索在前向传播时根据权重计算出前k个分支,避免了计算无关紧要的分支或陷入单一局部最优网络架构中。通过这种方式,我们不仅大幅减少了搜索成本,还获得了一个竞争力强的轻量网络。与【21】不同,我们选择为每一层独立搜索单元。
此外,我们在训练时联合优化softmax损失和三元组损失【9, 23, 25】。特别地,我们提出了一种简单但有效的平衡颈(BLNeck),用于解决嵌入空间中这两种损失的目标不一致问题。【23】中提出了BNNeck来平衡这些损失的效果,但该方法并不总是适用于任意网络架构(如表6所示)。但是,所提出的BLNeck具有将受三元组损失约束的嵌入空间映射到受softmax损失约束的空间的强大能力,因此这两种损失可以和谐优化。条纹策略通常用于提取局部特征,以引导模型关注更细节的信息。因此,我们也将这一思想融入了我们的平衡颈中,得到了一种新的颈部结构,称为精细平衡颈(FBLNeck),进一步提升了性能。
总而言之,本文的贡献如下:
- 我们提出了一种新颖的搜索空间,称为组合深度空间(CDS),其中CBlocks明确学习组合模式特征,更适合ReID任务。
- 我们提出了一种新的搜索策略,称为逐层Top-k样本搜索,该策略可以大大降低搜索成本,并充分利用搜索空间。
- 我们提出了一种简单但有效的精细平衡颈(FBLNeck),用于平衡三元组损失和softmax损失的效果,以更好地利用它们的优势。
广泛的实验表明,我们的CDNet在轻量级网络中达到了最先进的性能。
2.Related Works
2.1. Lightweight Networks
近年来,为了减少卷积神经网络(CNNs)的计算复杂性,一些研究者开始探索高效且小尺寸的模型。MobileNets【12, 29, 11】通过使用深度可分离卷积,大大减少了参数数量,同时保持了与标准网络相当的性能。ShuffleNets【46, 24】利用组卷积进一步减少了参数数量,尤其是【24】认为过多的分支会妨碍并行计算,这也是我们在本工作中关注的问题。其他研究者通过知识蒸馏【41】、量化【6, 43, 14】、网络剪枝【6, 18, 39, 22】等方法获得小尺寸网络。然而,这些设计方法的最大缺点是需要通过大量实验来经验性地确定最佳网络结构。
为了自动化架构设计过程,强化学习和进化学习已经被引入,用于搜索在分类任务上具有竞争性准确率的高效网络架构【52, 26, 35】。自从【21】提出通过梯度下降的可微分架构搜索算法(DARTS)以来,许多研究者发表了相关扩展工作【44, 4, 42, 2】,采用了类似的算法。然而,这些方法大多采用了与DARTS相同的搜索空间和算法,如前文所述存在多个缺点。因此,我们提出了一种新颖的搜索空间,称为组合深度空间(CDS),其更加高效且适合ReID任务。
2.2. Person Re-Identification
近年来,大多数提出的ReID模型主要使用复杂的网络(例如ResNet)作为骨干,并整合了一些特殊结构,以提取额外信息来增强判别特征【33, 48, 38】。这些方法通常采用ResNet作为骨干,它们参数众多且需要大量计算资源,其在实际应用中(例如资源受限的监控摄像头)难以部署。因此,我们的目标是避免使用ResNet,构建一个高效的轻量级网络来满足这些特定需求。
确实,一些工作【19, 17, 50】已经提出了为ReID设计的小型网络。【25】将一个局部感知模块引入DARTS的搜索空间,并搜索一个轻量级网络用于ReID。【50】提出了OSNet,能够学习全尺度特征,在ReID和分类任务中都取得了有希望的结果。由于OSNet的特殊结构,四个分支在每一层并行计算特征,这导致了尽管OSNet参数量只有2.2M,但其计算资源消耗依然巨大。我们认为,过多的并行分支往往提取冗余信息,因此可以丢弃某些分支以提高效率。
3.Methodology
4.Experiments
知识补充
网络骨干
IBN网络族
Instance Batch Normalization (IBN) network family,即IBN网络族,是一类结合了Instance Normalization (IN)和Batch Normalization (BN)的卷积神经网络(CNN)模型。以下是关于IBN网络族的详细介绍:
一、定义与核心思想
IBN网络族的核心思想是通过整合IN和BN这两种归一化技术,来提升模型的建模能力和泛化能力。IN和BN各自具有不同的特点:IN在每个样本的每个通道内部进行归一化,有助于模型学习到与外观变化(如颜色、样式等)不变的特征;而BN在批量数据的每个通道上进行归一化,有助于模型保留与内容相关的信息。IBN网络族将这两种归一化方式相结合,旨在同时利用它们的优点。
二、主要特点
- 增强学习与泛化能力:IBN网络族通过结合IN和BN,显著提高了模型在不同领域和任务上的学习和泛化能力。
- 适用于多种深度网络架构:IBN网络族可以应用于多种先进的深度网络架构,如DenseNet、ResNet、ResNeXt和SENet等,并在不增加计算成本的情况下持续提高它们的性能。
- 跨域任务表现出色:IBN网络族在处理跨域任务时表现出色,能够在不同数据集或领域间迁移学习时保持较好的外观不变性。
- 易于集成:IBN网络族支持PyTorch等深度学习框架,用户可以通过简单的代码调用,快速集成到现有的深度学习项目中。
三、应用场景
IBN网络族在多个应用场景中展现出了卓越的性能,包括但不限于:
- 人物/车辆重识别:在复杂的监控视频中,IBN网络族能够有效地识别和追踪特定的人物或车辆。
- 图像风格转换:由于IN在图像风格转换任务中的优势,IBN网络族也适用于此类任务,能够生成具有特定风格的图像。
- 语义分割:IBN网络族通过提高模型的泛化能力,有助于在语义分割任务中更准确地识别图像中的不同区域。
四、发展前景与挑战
随着深度学习技术的不断发展,IBN网络族有望在未来继续拓展其应用场景和性能。然而,也面临着一些挑战,如如何进一步优化归一化策略以进一步提高模型性能、如何更好地适应不同规模和复杂度的数据集等。
综上所述,IBN网络族是一类具有强大学习和泛化能力的卷积神经网络模型,通过结合IN和BN两种归一化技术,在多个应用场景中展现出了卓越的性能。未来,随着技术的不断进步和应用场景的不断拓展,IBN网络族有望为深度学习领域带来更多的创新和突破。
损失函数
深度学习中的所有学习算法都必须有一个 最小化或最大化一个函数,称之为损失函数(loss function),或“目标函数”、“代价函数”。损失函数是衡量模型的效果评估。
对比学习中的损失函数概览
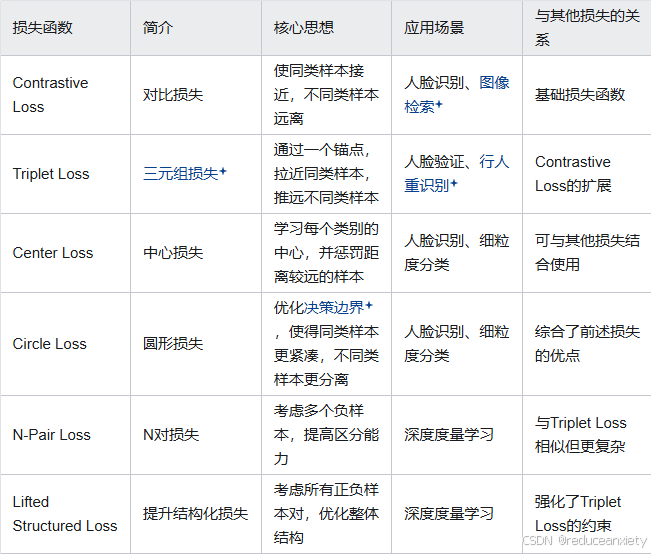
- Contrastive Loss是基础的对比损失函数,它主要关注于成对样本之间的相似性。
- Triplet Loss可以看作是Contrastive Loss的一个扩展,它通过引入一个锚点来考虑正负样本之间的关系。
- Center Loss通过引入类别中心的概念,进一步强化了同类样本之间的紧凑性。
- Circle Loss则综合了前述损失函数的优点,通过优化决策边界来提高性能。
- N-Pair Loss和Lifted Structured Loss是更复杂的损失函数,它们考虑了更多的负样本和整体结构,以进一步提高模型的区分能力。
这些损失函数在深度学习中广泛应用于各种需要度量学习或表示学习的任务中,如人脸识别、图像检索、行人重识别等。
它们的核心思想都是通过拉近同类样本和推远不同类样本来学习有区分力的特征表示。
度量损失
Metric Loss,即度量损失,是深度学习和机器学习领域中用于优化模型性能的一种损失函数。它的核心目标是学习一个有效的距离度量,使得在特征空间中,相似样本之间的距离较小,而不相似样本之间的距离较大。这种损失函数在多种任务中都有广泛应用,如人脸识别、图像检索、聚类等。
一、Metric Loss的原理
Metric Loss的基本原理是通过计算样本之间的距离或相似度,来衡量模型预测结果的准确性。在训练过程中,模型会不断调整其参数,以最小化Metric Loss,从而学习到更加准确的距离度量。这种损失函数通常与深度学习中的嵌入学习(Embedding Learning)相结合,用于学习数据的低维表示。
二、常见的Metric Loss函数
-
Contrastive Loss:
- 适用于成对样本的损失函数。
- 计算两个样本之间的相似度或距离,并根据它们是否属于同一类别来施加惩罚。
- 当两个样本属于同一类别时,损失函数会鼓励它们之间的距离更小;当它们属于不同类别时,损失函数会鼓励它们之间的距离更大。
-
Triplet Loss:
- 适用于三元组样本的损失函数。
- 包括一个锚点样本、一个正样本(与锚点样本属于同一类别)和一个负样本(与锚点样本属于不同类别)。
- 目标是使锚点与正样本之间的距离小于锚点与负样本之间的距离,且这个距离差要大于一个预设的边距(margin)。
-
N-pair Loss:
- 是Triplet Loss的扩展,允许每个锚点样本同时与多个负样本进行比较。
- 通过这种方式,模型可以学习到更加细粒度的距离度量,从而提高其性能。
-
Center Loss:
- 旨在最小化每个样本与其对应类别中心之间的距离。
- 有助于增强模型的类内紧凑性和类间可分性。
-
Angular Loss:
- 基于角度的损失函数,旨在优化样本在特征空间中的角度分布。
- 通过使同类样本之间的角度更小,不同类样本之间的角度更大,来提高模型的性能。
三、Metric Loss的应用场景
-
人脸识别:
- 通过学习一个有效的距离度量,使得在特征空间中,相同人的不同照片之间的距离较小,而不同人的照片之间的距离较大。
-
图像检索:
- 根据用户输入的查询图像,在数据库中找到与之相似的图像。
- 通过Metric Loss优化模型,使得在特征空间中,相似图像之间的距离更小,从而更容易找到与用户查询相似的图像。
-
聚类:
- 将相似的样本聚集在一起,形成不同的簇。
- 通过Metric Loss优化模型,使得在特征空间中,同一簇内的样本之间的距离更小,不同簇之间的样本之间的距离更大。
四、Metric Loss的优势与挑战
优势:
- 能够学习到有效的距离度量,提高模型的性能。
- 适用于多种任务,如人脸识别、图像检索、聚类等。
挑战:
- 需要大量的训练数据和计算资源。
- 模型的性能受到损失函数设计的影响,需要仔细选择和优化。
综上所述,Metric Loss是深度学习和机器学习领域中一种重要的损失函数,它通过优化样本之间的距离或相似度来衡量模型的性能。在实际应用中,需要根据具体任务和数据的特点选择合适的Metric Loss函数,并进行仔细的优化和调整。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









