








前言
在解释深度优先遍历之前,我想先让大家去思考一个可能从未想过的问题:
 为什么我们在学习基础数据结构的时候,都没有出现dfs和bfs这两个词,而在学习二叉树和图的时候,突然蹦出了深度优先遍历和广度优先遍历这两个概念?
为什么我们在学习基础数据结构的时候,都没有出现dfs和bfs这两个词,而在学习二叉树和图的时候,突然蹦出了深度优先遍历和广度优先遍历这两个概念?
而解答这个问题也很简单。
- 数组,链表,双端队列等数据结构,无论产生如何变化,其最终都是线性结构,遍历无非只有一直往后一条路可走。
- 而二叉树,图等结构,是非线性结构,也便是遍历到每一个结点的时候,如果想进入下一层,会出现很多方向(例如二叉树的左子树和右子树),其遍历的时候就会出现多种选择。
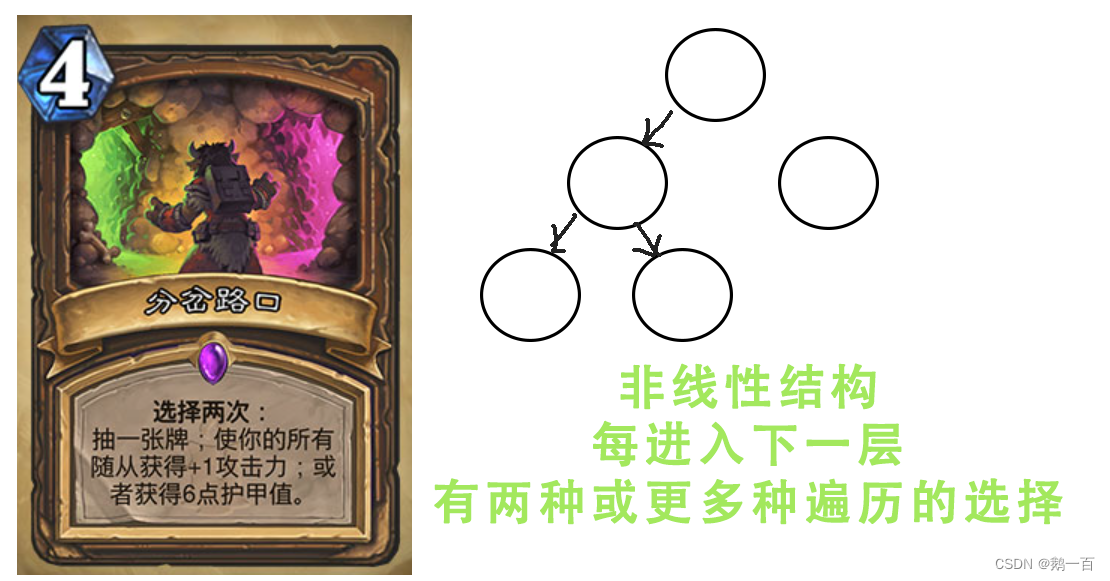
所以,我们在对非线性结构进行遍历的时候,会有两种最常见的方案:
- 一条路走到黑,一直走到无路可走,依次遍历完所有路径
- 先遍历一步就能到达的结点,再遍历两步才能到达的结点,一直遍历到最远的结点
我们分别将其取名,深度优先遍历和广度优先遍历,这就是他们的来源。

深度优先遍历
简介

虽然深度优先遍历是一路走到黑,但是他也不是瞎寄把飞。为了让遍历结果有一定的参考价值,我们在每一个结点的往下遍历,都要遵循一个相同的顺序。
就比如二叉树的前序中序后序遍历,我们不能第一个结点是前序,第二个结点是后续,第三个结点又变成了中序。

我们在二叉树的遍历都知道,只有在左子树全部走完之后,才会回到上一层,继续去遍历右子树。因为在二叉树的遍历就已经非常非常非常详细讲解了,篇幅问题,就不多作解释了。我们把这种当前层遍历完之后,回到上一层的操作称之为回溯。
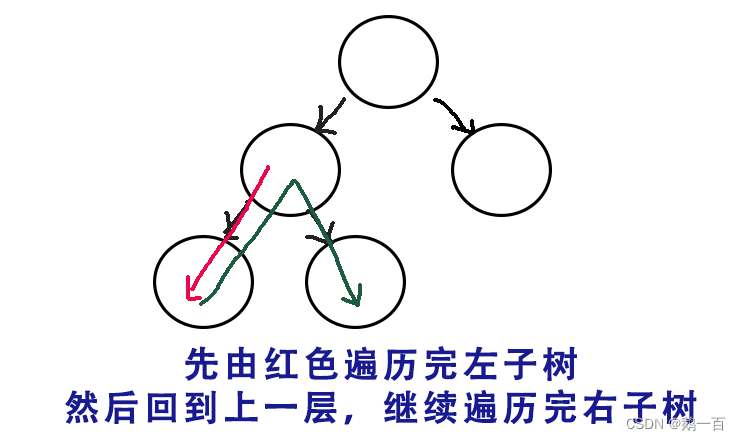
一般来说,解决回溯问题都采用栈和递归。但是,栈和递归其实是一回事,所以为了让代码更容易理解,我们在这里只用递归来实现。
dfs解决问题
其实原本想叫这个为公式的,但是概念太广了,所以只能称之为公式的简介。
dfs解决的问题,其实就是由它的定义所产生的两个问题:
- 选不选?
- 选哪个?
而解决这两个问题,只需要注意两个细节:
- 是否回头?
- 如何剪枝?
关于第一个问题,选不选和选哪个,会在具体的题目里详细说明他的公式。
在这里,先介绍那两个细节:
1.是否回头?
什么是回头?
假如我们在打一个boss,boss放了一个技能,你现在有左右两个方向可以躲闪:

你往左走,到了最左边的位置,发现不行,还是躲不掉技能。
于是你在最左边的位置,继续遍历,往右走,到了最初的位置,发现不行,还是躲不掉技能。
于是你在最初的位置,继续遍历,往左走,到了最左边的位置,发现不行,还是躲不掉技能。
最终,boss就看着你:

有人说,这不很简单吗,只需要记录上一个结点的位置,防止递归到上一个结点,不就可以了。
所以,boss又放了另一个技能:

结果就不必我多说了,直接放图:

所以,我们不得不需要额外开一个哈希数组,用来标记所有走过的地方。而这个标记数组,往往会大量使用于大多数dfs和bfs题目中。
2.如何剪枝?
剪枝,说人话,就是在某一条路走到中间,提前排除掉不可能的情况,从而提升效率。
就比如在迷宫中间,如果放置了一颗炸弹。那么当我们遍历到这颗炸弹的时候,炸弹后的路我们就全部不考虑了,这便叫将不可能的情况全部剪枝掉。图就不放上了,因为迷宫实在是太难画了(
剪枝是公式里唯一需要思考的地方,但是其实也不难,而且大部分情况就算少剪一点,对答案也不会产生太大的影响。
dfs题目分类
dfs题目,以我的经验来说,只分为了四类:
- 子集问题——选不选
- 全排列问题——选哪个
- 爬塔问题——选哪个
- 矩阵路线问题——选哪个
but:

豪德,那就依次看看四种公式分别是什么:
子集
高中都上过吧?那概念就不多解释了。直接来看题目:
不含相同元素的子集

解题步骤
在题目分类中,我们就已经说明了,这道题属于选不选的问题。什么意思?这和dfs有什么关系?

我们把整个数组列出来,对于每个元素,我们有两条路可走:

然后,我们接着往后遍历。对于每个元素,我们都是有这两条路:
- 将该元素放入子集中
- 将该元素不放在子集中
而遍历到最后一个元素,我们便遍历到了所有情况。
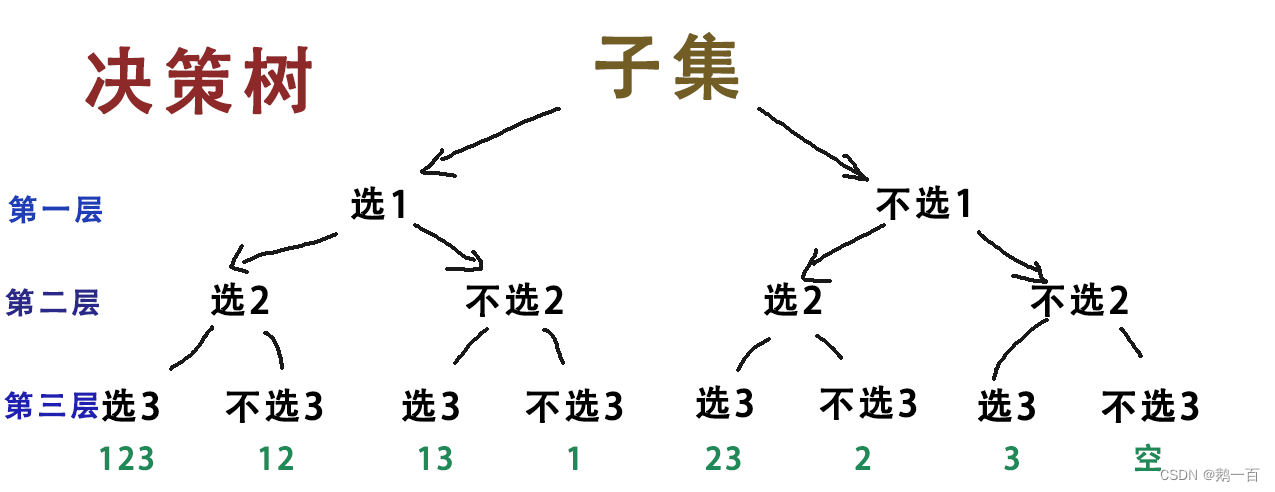
像这样列出所有选择和所有情况的图,我们称之为决策树。决策树,就是将每一步有什么选择,如何选择,最后带来了什么结果,全部列在一棵树中。
而我们发现,每一层的两个选择就是选不选当前元素,这就是我所说的,选不选的问题。
解题代码
我们在递归章节中有讲到,递归代码的完成只需要考虑三步:
- 什么是子问题?
- 解决这个问题需要哪些条件,怎么处理?
- 递归的结束条件是什么?
什么?没见过?那赶紧去递归章节看看:一命通关递归-CSDN博客
我们来分步解析:
1.什么是子问题?
在题目特性就已经说清楚了, 子问题是每一层选还是不选。
2.函数条件和函数体
在分析的时候也很明了,完成这个dfs函数只需要知道,当前遍历到哪一层,和该层的元素是什么,便足够了。
而函数体,便是这个函数要干什么。这个也是在分析问题的时候理清楚了:
- 选择当前元素,继续向下遍历;
- 不选择当前元素,继续向下遍历。
3.结束条件
一直到遍历完最后一个元素,我们将遍历出的情况插入到返回值数组中,就完成了一条路线的遍历,这条路线的递归就结束了。
class Solution {
vector<vector<int>> ret;//返回数组
vector<int> tmp;//子集数组
int n;//nums的大小
public:
void dfs(vector<int>& nums, int p)
{
if(p==n)//结束条件
{
ret.push_back(tmp);
return;
}
//不选当前结点
dfs(nums,p+1);
//选当前结点
tmp.push_back(nums[p]);
dfs(nums,p+1);
}
vector<vector<int>> subsets(vector<int>& nums) {
n=nums.size();
dfs(nums,0);
return ret;
}
};有人可能喜欢给递归函数传一大堆参数,把返回值,临时数组都放在函数参数中,比如:
void dfs(vector<vector<int>>& ret,vector<int>& tmp,int p,vector<int>& nums)但是这种写法,太太太臃肿了,我们其实把一些在递归中不会影响递归的变量放在全局中就好了。
回溯的还原现场
好,我们提交一下代码,然后发现了:
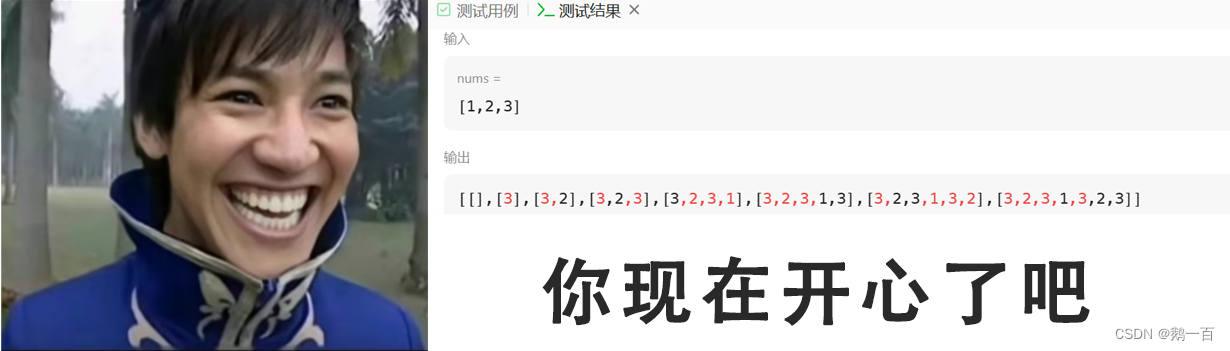
所以说了这么半天,教我一个伪代码是吧?

别急,我们来看输出的结果。我们发现,明明只有三个数产生的子集,最后突然蹦出了一大长串数字。而且越往后,蹦的数字越多。
会产生这个结果的唯一可能,便是一个数字被重复选取了,但是按我们刚刚的思想,这种情况不可能发生啊?

我们来看中间的某个情况:

而我们看那些输出结果,都是在之前出现过的结果中,不断增加数字,而没有删减过数字,自然就会不断累积,导致出现一堆乱七八糟的结果。
而解决这一问题的方法,便是在返回到上一层递归的同时,清除掉这一层递归对全局变量产生的影响。
打个比方:你在某游戏中遇到了一个分岔路口,你进入了其中一个房间,但是发现这个房间打不过, 你决定用作弊代码回档到上一个房间的时候,那么那个打不过的房间对你产生的所有影响,都将随着回档而消失,你的HP,你身上的道具,也都将回到进入这个房间之前的状态,不可能回档之后,在那个房间受到的伤害还是虚空索敌结算到了你的身上。

而这便称之为,回溯的还原现场。我们在回到上一层回溯的时候,必须要消除掉当前层对全局变量产生的所有影响,使其没有遍历过当前路径的痕迹,这样才可以正常遍历其他路径。
而对这道题目,还原现场便是,在子集数组中删掉当前遍历过的元素,往后的遍历便不会出现这个元素。
class Solution {
vector<vector<int>> ret;
vector<int> tmp;
int n;
public:
void dfs(vector<int>& nums, int p)
{
if(p==n)
{
ret.push_back(tmp);
return;
}
//不选当前结点
dfs(nums,p+1);
//选当前结点
tmp.push_back(nums[p]);
dfs(nums,p+1);
tmp.pop_back();//还原现场
}
vector<vector<int>> subsets(vector<int>& nums) {
n=nums.size();
dfs(nums,0);
return ret;
}
};含相同元素的子集
 解题步骤
解题步骤
不管他含不含相同元素,既然是子集问题,那么就是同一种思路:选还是不选。
只不过,如果我们还是按照之前的思路来做,会发现一个问题:

这也便是重复元素最棘手的问题:怎么去重?
在这里,我们介绍一种方法:
- 对于一串相同的数字,如果前一个选了,那么后一个则一定要选上。
而按照这个规律一直递推下去,其实也可以换一句话来说:
- 对一串相同的数字,如果某个位置的数字选了,那么该位置往后的所有数字都要选

采用这种方法,就可以不重不漏涵盖整个子集。别问我这种方法怎么想到的,我也是看题解才学会的。
解题代码
因为需要知道上一个数选不选,所以不得不在递归中加入一个新的参数。
同时,为了让所有相同的元素相邻,我们可以先将数组排序来达到这个目的:
class Solution {
public:
vector<int> tmp;
vector<vector<int>> ret;
void dfs(bool choosePre, int cur, vector<int>& nums) {
if (cur == nums.size()) {
ret.push_back(tmp);
return;
}
//如果上一个选了,并且是相同元素,则这一个必须要选
if(choosePre&&nums[cur]==nums[cur-1])
{
tmp.push_back(nums[cur]);
dfs(true,cur+1,nums);
tmp.pop_back();
}
//否则正常递归
else
{
dfs(false,cur+1,nums);
tmp.push_back(nums[cur]);
dfs(true,cur+1,nums);
tmp.pop_back();
}
}
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(), nums.end());//为了让相同的元素相邻,我们先将数组排序
dfs(false, 0, nums);
return ret;
}
};全排列
还是高中概念,不多解释。
不含相同元素的全排列
 解题步骤
解题步骤
子集是选不选的问题,而全排列则是选哪个的问题。什么是选哪个?
因为我们知道,全排列临时数组的大小就等于原数组nums的大小,我们先将全排列的数组列出来: 也就是,我们有一个背包装着很多不同的食物,每天我们都要从中选一样吃掉。而每天的选择不同,就构成了全排列,这便是选什么的问题。
也就是,我们有一个背包装着很多不同的食物,每天我们都要从中选一样吃掉。而每天的选择不同,就构成了全排列,这便是选什么的问题。
但是,因为如果前面选择了,后面则无法再选择,这便是我们说到的细节——不能回头。我们需要搭配一个标记数组,来标记哪些元素选过了,不能再选择了。
同样的,我们在还原现场的时候,也需要还原标记数组。
解题代码
class Solution {
vector<vector<int>> ret;
vector<int> tmp;
vector<bool> record;//标记数组
public:
void dfs(vector<int>& nums)
{
if(tmp.size()==nums.size())
{
ret.push_back(tmp);
return;
}
for(int i=0;i<nums.size();i++)//每个元素都尝试一遍
{
if(record[i]==false)//没有被标记,表示之前没有被选过,则当前可以被选到
{
record[i]=true;//标记
tmp.push_back(nums[i]);
dfs(nums);
//还原现场
tmp.pop_back();
record[i]=false;
}
}
}
vector<vector<int>> permute(vector<int>& nums) {
record.resize(nums.size());
dfs(nums);
return ret;
}
};含相同元素的全排列
LCR 084. 全排列 II - 力扣(LeetCode)
 解题步骤
解题步骤
和子集中的问题一样,我们此刻的最大问题就是:如何去重?
我们还是采用一种从题解中学到的方法:
- 对一串相同的元素,如果上一个元素没有选择,则下一个元素也不能选
或者说:
- 对一串相同的元素,只有上一个元素选了, 下一个元素才可以选
我们这样做的目的,其实是为了保证,相同元素的顺序是有序的
啥意思?


采用这种方法,就能保证重复元素不会乱序,也就达到了去重的目的。
解题代码
class Solution {
vector<vector<int>> ret;
vector<int> tmp;
vector<bool> record;
public:
void dfs(vector<int>& nums)
{
if(tmp.size()==nums.size())
{
ret.push_back(tmp);
return;
}
for(int i=0;i<nums.size();i++)
{
if(record[i]==false&&!(i>0&&nums[i]==nums[i-1]&&record[i-1]==false))
{
record[i]=true;
tmp.push_back(nums[i]);
dfs(nums);
tmp.pop_back();
record[i]=false;
}
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
sort(nums.begin(),nums.end());
record.resize(nums.size());
dfs(nums);
return ret;
}
};爬塔问题
什么是爬塔问题?
爬塔问题其实很广泛,他涵盖了子集问题,全排列问题,还有自己延伸出的新问题。但是其实,这个名字是我自己瞎编的,只是作为一个资深的游戏玩家,我觉得把他命名为爬塔问题非常非常违和。
介绍这个问题,我来讲一个故事:
你重生了,在一个异世界当了一名勇士。这个异世界有一个魔王,生存在一个魔塔里,你或手无寸铁,或已经磨练许久有着充足的自信,但是最终目的都是爬到塔的顶端打败这个魔王。
在这个塔的每一层,都有着许多分叉路口,每个路口你可能会遭遇怪物,可能会触发特殊事件,可能会遇到商人,你可以在每个分岔路口选择不同的路线,然后获得不同的奖励或一些不同的惩罚,最终磕磕撞撞到了魔王面前。
不过,见到了魔王不等于可以打败魔王,你还需要在魔塔中不断遇到新的怪物后,还有着打败魔王的素质,天哪!这太难了!我怎么知道我会在塔里遭遇哪些事!
于是,你使出了肉鸽绝技:存档大法
好了,有了存档,你就可以放肆尝试所有路口,大不了回档嘛。但是,我该怎么不重不漏走过所有路线,找到最优解呢?

OK,以上这个问题,我们总结出两个特点:
- 每一层都有很多选择
- 我们在爬楼的中途,就可以排除掉很多不可能的情况,比如在半路上就被怪物杀死了,这条路后面的也就走不下去了。
而这类每一层都有很多选择的问题,都和爬一个魔塔一样,我为他取的最恰当的名字——爬塔问题。
爬塔问题有三类:
- 子集
- 全排列,即选择的东西是固定,之前选择过的之后不能再选择
- 爬塔,即每一层的选择都不同,上一层的选项和下一层的选项并不相同
对于第一二类,直接套子集和全排列的公式就可以了,而第三类,实际上是最简单的。直接根据题目,把题目翻译一遍,就做出来了。
 这便是一个最典型的爬塔问题,每一层的选择都是相互独立的。
这便是一个最典型的爬塔问题,每一层的选择都是相互独立的。
解题步骤
题目的意思便是,我们按下哪个键,就对应了哪个键上的字母供我们选择,我们按下了2和3,那么第一层,我们可以选择2对应的abc;第二层,我们可以选择3对应的def。
ok,题目翻译出来,我们就已经做出来了。digits给我们路线,我们在每个路口做出选择,over
解题代码
class Solution {
vector<string> ret;
string tmp;
//每个键对应的选择
vector<string> arr = { " "," ","abc","def","ghi","jkl","mno","pqrs","tuv","wxyz" };
public:
void dfs(string& digits,int cur)
{
if(cur==digits.size())
{
ret.push_back(tmp);
return;
}
int key=digits[cur]-'0';//按下的键的数字
for(int i=0;i<arr[key].size();i++)//每一个选择
{
tmp.push_back(arr[key][i]);
dfs(digits,cur+1);
tmp.pop_back();
}
}
vector<string> letterCombinations(string& digits) {
if(digits.size()==0)
return ret;
dfs(digits,0);
return ret;
}
};矩阵路线问题
矩阵路线问题,就像躲boss技能
你有很多方向可以选择,而你到了下一个位置以后,又会有新的方向可以选择。如果把这些方向也理解成每一层的选择,你会发现,他其实也是一个爬塔问题。
只不过,这个问题解题方法非常非常固定,而且有很多区别于爬塔问题的地方,我们就将其单独列了出来:
- 到一个新的地方后,之前的位置很可能会成为当前的选择,是最典型的不能回头问题
- 到达矩阵的边界后,因为不能越界,所以选择会突然变少,需要判断边界条件
- 你的初始位置可能是不固定的,即递归的起点也需要遍历到每一个点
 解题步骤
解题步骤
我们通过那三个区别,来分析这个题目:
1.方向选择
假设我们从F开始,有四个方向:上下左右
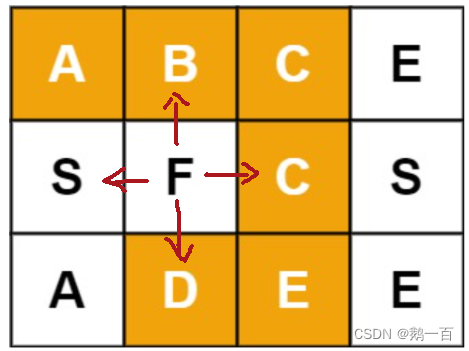
这四个方向,便是爬塔中的四个选择。不过,爬塔问题多个选择都会给一个选择的数组,这里我们应该怎么很好去表达四个方向呢?
很简单,四个方向不过是row和col,横纵坐标的增减,那我们先初始化两个数组:
int drow[4]={1,-1,0,0};
int dcol[4]={0,0,1,-1};我们去遍历四个方向的时候,只需要遍历四个方向的数组:
//假设已知了当前的坐标row和col
for(int i=0;i<4;i++)
{
int newrow=row+drow[i];
int newcol=col+dcol[i];
//newrow和newcol便是每个选择中,新的横纵坐标值
}这样就表示了所有四个方向移动后对应的新坐标值。
同理,如果有更多的方向,也可以这么实现。
而如果我们选择了往右走,则会也有四个方向:上下左右

但是,如果我们此时向左走,就回到了F,也就是新的结点的选择中,很可能会出现回头路。
解决方案很简单,便是解决回头路的通解:配以一个标记数组。
vector<vector<bool>> record(row,vector<bool>(col));//标记数组
if(record[newrow][newcol]==false)
{
record[newrow][newcol]=true;
dfs(...);
}2.边界条件
加入我们从F走一步,走到了S,那么S可以选择的方向就会减少一个。因为如果S再向左走,那么就会超出矩阵的范围,产生越界,所以必须要加一个选择的判断。
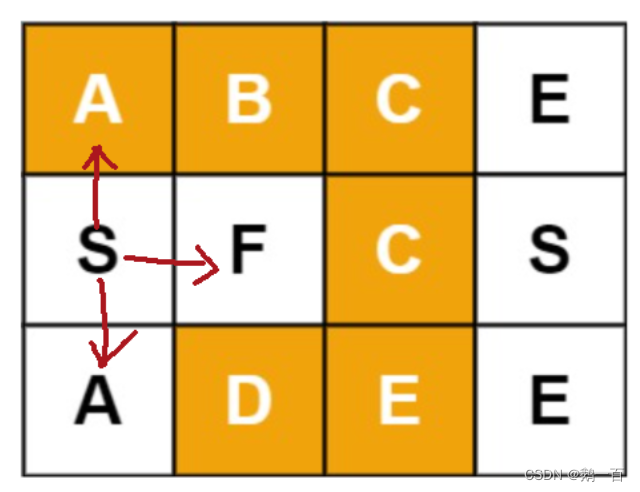
//假如计算出了新的坐标值newrow和newcol
//m和n分别为矩阵的横纵长度
if(newrow>=0&&newrow<m&&newcol>=0&&newcol<n)//判断是否越界
dfs(...);
//只有不越界,遍历才可以继续3.多源遍历
题目说了从哪个点开始遍历吗?没有。因为单词搜索的开头,每个位置都有可能,所以我们要考虑所有点作为源点的情况,用每种情况都去遍历一遍。
for(int i=0;i<m;i++)
for(int j=0;j<n;j++)
dfs(...);
//每个点都作为源头进行遍历而解决了以上三个问题,矩阵路线问题,其实和爬塔问题也并无两异
解题代码
class Solution {
vector<vector<bool>> record;//标记数组
int dx[4]={0,0,1,-1};
int dy[4]={1,-1,0,0};//方向数组
public:
bool dfs(vector<vector<char>>& board,string& word,int cur,int x,int y)
{
if(cur==word.size())
return true;
bool ret=false;
for(int i=0;i<4;i++)
{
int nextx=x+dx[i];
int nexty=y+dy[i];//新的横纵坐标
if(nextx>=0&&nextx<board[0].size()&&nexty>=0&&nexty<board.size()//判断越界
&&record[nexty][nextx]==false//判断是否回头
&&board[nexty][nextx]==word[cur])//判断是否满足题目要求
{
record[nexty][nextx]=true;
ret=dfs(board,word,cur+1,nextx,nexty);//以新的结点开始遍历
record[nexty][nextx]=false;
//剪枝
if(ret==true)
return true;
}
}
return false;
}
bool exist(vector<vector<char>>& board, string& word) {
record.resize(board.size());
for(auto& e:record)
e.resize(board[0].size());
bool ret=false;
//对每个结点都去遍历
for(int i=0;i<board.size();i++)
{
for(int j=0;j<board[0].size();j++)
{
if(board[i][j]==word[0])
{
record[i][j]=true;
ret=dfs(board,word,1,j,i);
record[i][j]=false;
}
//剪枝
if(ret)
return true;
}
}
return false;
}
};剪枝
我们在解题代码中,发现了这么一段代码:

我们知道,对于题目示例的那种情况,在遍历到第一个源头的时候,就已经找到了答案,可以返回true了

但是,如果没有这个判断,程序还是会继续遍历下去,遍历完了所有情况,最后发现,哦!第一种情况符合题意!我返回true吧!

在已经可以判断,后续的情况不需要遍历的时候,我们就直接舍弃掉那些不需要遍历的情况,提升效率,这个操作就叫做剪枝。
但是我们不剪枝,会不会对答案产生影响?当然不会,后续的遍历又不可能改变先前的结果。所以剪枝的目的只是为了提升效率,而不会对算法产生太大的影响。
并且,不同的题目剪枝也是不同的,这些都是依据题目要求来稍加思考,没有太多的公式可靠。

dfs系列题目
公式
和之前的章节不同,为什么在这篇文章,我最后才把公式放出来?
因为dfs的题目无论是剪枝还是判断路径,都是需要独立思考可以自己写出代码之后,才能复述出公式的每一步都在干什么。对于dfs,如果直接告诉你,可以套公式(可以是当然可以),是极不负责任的,因为如果出现了某些题目稍加修改,而你完全不知道递归的每一步在干什么,那么你完全不知道要从哪个地方修改。
所以,我在最后放出公式,不是鼓励大家直接去记公式,而是告诉大家,一个dfs题目应该怎么去求解,应该需要那些先制条件,求解的时候每个函数在干什么,函数体应该怎么设计。这也是dfs与套路化的二分和前缀和之类的章节,最大的不同。
爬塔问题
class solution
{
//全局变量部分:
//判断是否有回头路,如果有的话必须要一个标记数组
vector<bool> record;
//一般来说,遍历的结果会存在一个二维数组中,我们一般设为全局变量
vector<vector<int>> ret;
vector<int> tmp;
public:
//函数部分:
//函数的参数由记录每一步的选择数组,和当前遍历到的层数构成
void dfs(vector<vector<int>>& nums, int cur)
{
//结束条件
if (...)
{
...
//进行一些操作
return;
}
//剪枝
if (...)
{
return;
}
//遍历当前层的每个选择
for (int i = 0; i < nums[cur].size(); i++)
{
tmp.push_back(nums[cur][i]);
record[cur] = true;
dfs(nums, cur + 1);//继续向下遍历
//还原现场
tmp.pop_back();
record[cur] = false;
}
}
vector<vector<int>> main(vector<vector<int>>& nums)
{
//初始化标记数组
record.resize(nums.size());
dfs(nums, 0);//从0开始遍历
return ret;
}
};矩阵路线问题
class Solution {
int dx[4]={0,0,1,-1};
int dy[4]={1,-1,0,0};//方向数组
vector<vector<bool>> record;//标记数组
int m,n;//矩阵长宽
public:
void dfs(vector<vector<int>>& grid,int row,int col)
{
if(...)//递归结束
{
...
//进行一些操作
return;
}
if(...)//剪枝
{
return;
}
for(int i=0;i<4;i++)
{
int nextrow=row+dy[i];
int nextcol=col+dx[i];//新的坐标
if(nextrow>=0&&nextrow<m&&nextcol>=0&&nextcol<n//不越界
&&record[nextrow][nextcol]==false//没有走回头路
&&grid[nextrow][nextcol]...)//满足题目要求
{
record[nextrow][nextcol]=true;
dfs(grid,nextrow,nextcol);//遍历到新的位置
record[nextrow][nextcol]=false;//还原现场
}
}
}
... main(vector<vector<int>>& grid) {
m=grid.size();
n=grid[0].size();
record.resize(m,vector<bool>(n));
//遍历每一个源头
for(int i=0;i<m;i++)
{
for(int j=0;j<n;j++)
{
if(grid[i][j]!=0)
{
record[i][j]=true;
dfs(grid,i,j);
record[i][j]=false;
}
}
}
}
};














 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









