






文本风格迁移的准备工作总结:
在本次项目实训中,我将开展两种类型的文本风格迁移:
- 将文本转化为指定文学作品的写作风格——包括其惯用词汇、典型句式、修辞手法与人物对话模式等,例如:将输入文本转化为《西游记》体裁的表现形式;
- “喵喵”解题风格迁移,通过在问答生成中注入可爱的猫咪语气标记和丰富的装饰性表情,既保留数学或逻辑推理的正确性,又兼具活泼俏皮的“喵~”风格输出。
我将从以下方面来说明:
1.数据集
通过搜集找到了如下数据集:
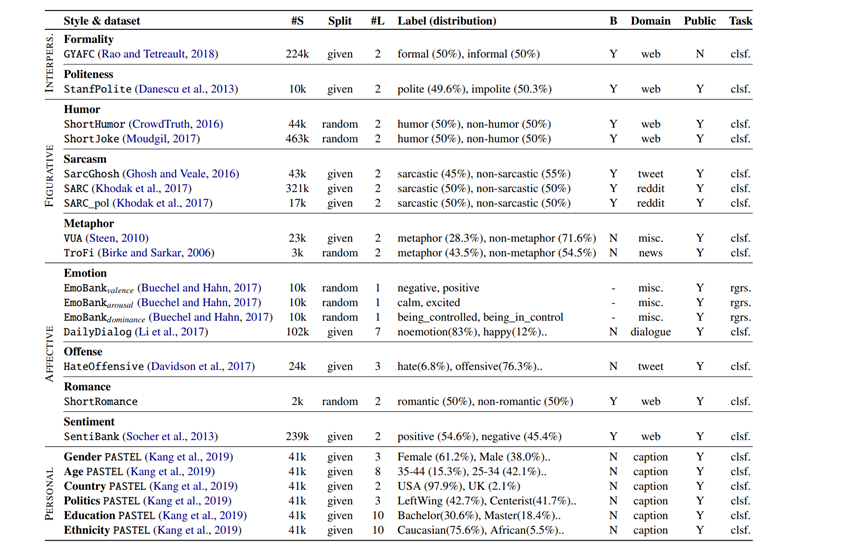
但是这些数据大多是非平行语料,无法进行监督微调,通过查阅资料了解到大致有两类方法:
- 使用类似于回翻技术来构造伪平行语料进行监督微调
- 采用类似于GAN的思想,通过引入判别器网络对生成序列进行域判别,构建生成器-判别器的最小最大博弈框架,使生成器在隐式监督下逼近目标语言分布
我打算首先尝试使用风格提示词(style prompts)来构造伪平行语料,以进行监督微调。该方法可以快速验证模型是否具备基本的风格控制能力。在此基础上,再考虑是否引入方法二:借鉴 GAN 的思想,构建一个生成器-判别器的对抗训练框架。具体而言,判别器的作用是判断生成样本是否符合目标风格,从而为生成器提供隐式监督信号。通过这种最小-最大博弈机制,生成器在训练过程中能够逐步逼近目标风格分布,提升生成文本的风格一致性与质量。
2.微调方法
- 全量参数微调:对预训练语言模型的所有参数进行更新,对下游任务最有针对性,但是其容易过拟合。
- 部分参数微调:采用类似于Adapter,LoRA以及Prefix-Tuning的方法,通过冻结大部分模型参数,仅微调少量关键参数,以降低计算成本并提高训练效率。
由于我们首先提升了模型的数学推理能力,因此在此基础上进行文本风格迁移时,全参数微调可能会显著影响模型的数学能力。为避免这一问题,我选择了部分参数微调。同时,考虑到需要支持多种风格,像LoRA和Adapter这样的技术适用于嵌入型转化任务,但需要切换模型。而Prefix-Tuning在多任务设置中无需切换或重新加载模型,只需替换相应任务的前缀向量即可实现风格切换。因此初步决定采用Prefix-Tuning方法。
3.损失函数选择
文本风格迁移的效果可以从内容保留度,风格化程度方面来衡量,所以初步设想对生成器使用如下三种损失:
1. 自重构损失:原句 + 原风格 → 原句
为了确保迁移后的文本尽可能保留原始文本的语义内容,引入自重构损失。该损失通过最小化输入句子 x 和生成句子 y 之间的语义差异来实现,损失如下:
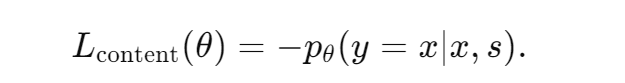
2. 循环重建损失:新句 + 原风格 → 原句
循环重建损失的目的是确保在应用风格迁移时,生成的句子仍然保留原始句子的语义内容。具体地,给定输入句子 和目标风格
,生成的句子
被再次输入到模型中,并使用原始风格
进行风格迁移,模型的任务是重建原始输入句子
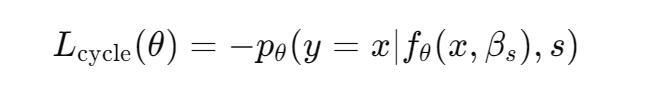
3. 风格化程度损失:原句 + 目标风格 → 新句
为了确保生成的文本具备目标风格的特征,引入风格化程度损失。通过使用判别器来判断生成句子是否符合目标风格,最小化以下损失来优化模型的风格迁移能力:
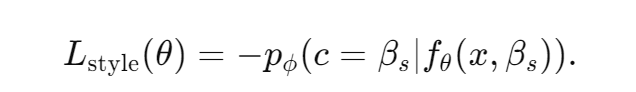

















 863
863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









