







一、实验目的
本实验旨在通过实践掌握GCC编译器的基础用法和GDB调试器的核心调试技巧,具体包含以下核心能力培养:
- GCC编译流程控制:从预处理到链接的全流程控制,掌握多文件编译和优化选项应用
- GDB调试方法论:包括断点管理、变量监控、堆栈跟踪等系统化调试方法
二、实验内容
(1)编译器gcc的使用
1)编辑一个C语言程序文件 hello.c ,代码如下:
#include <stdio.h>
main()
{
char name[20];
printf(“Please input your name:”);
scanf(“%s”,name);
printf(“Welcome %s!\n”,name);
return 0;
}2)编译文件: gcc -o hello hello.c。
3)若有错误,修改hello.c的内容,然后再次编译,直至没有错误为止。
实验步骤:
①编写代码文件:
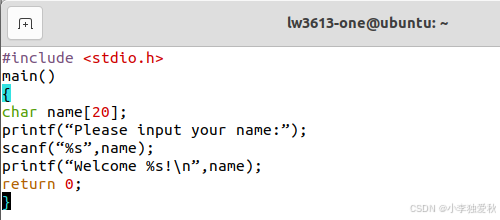
②第一次运行报错如下:
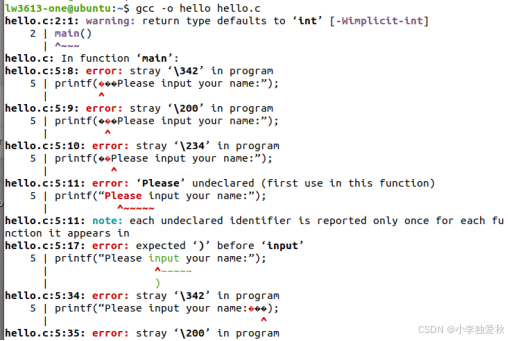
主要问题点:
- 中文标点符号:代码中双引号为中文全角字符(“”),应替换为英文半角("")
- main函数声明不规范:未明确返回值类型,建议改为
int main(void)- 缓冲区溢出风险:scanf未限制输入长度,建议使用
scanf("%19s", name)
③修改代码如下:
#include <stdio.h>
int main(void)
{
char name[20];
printf("Please input your name: ");
scanf("%19s", name);
printf("Welcome %s!\n", name);
return 0;
}④再次运行gcc -o hello hello.c,无报错,结果如下:

⑤编译命令演进:
# 基础编译
gcc -o hello hello.c
# 开启所有警告(推荐)
gcc -Wall -Wextra -o hello hello.c
# 分阶段编译演示
gcc -E hello.c -o hello.i # 预处理
gcc -S hello.i -o hello.s # 汇编代码生成
gcc -c hello.s -o hello.o # 目标文件生成
gcc hello.o -o hello # 链接
(2)使用GDB 调试程序BUG
1)使用文本编辑器输入以下代码greet.c。程序试图倒序输出main 函数中定义的字符串,但结果
2)使用gcc –g 的选项编译这段代码,运行生成的可执行文件,观察运行结果。
3)使用gdb 调试程序,通过设置断点、单步跟踪,一步步找出错误所在。(调试过程需截图)
4)纠正错误,更改源程序并得到正确的结果。
实验步骤:
①编写代码文件:
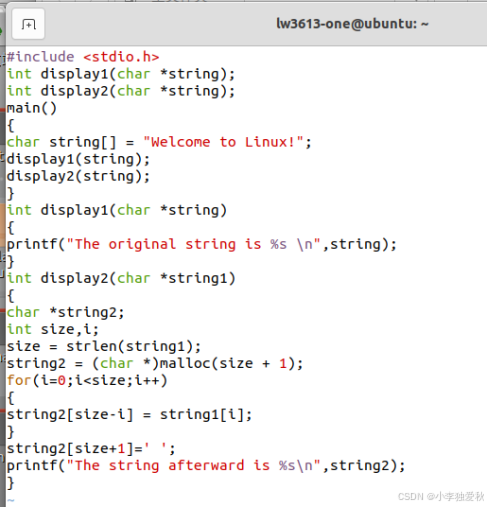
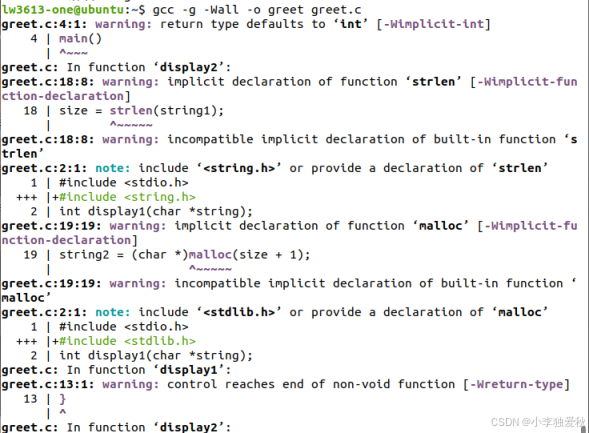
②编译带调试信息的可执行文件:
输入命令:gcc -g -Wall -o greet greet.c,发现报错如下:
验证调试信息是否存在:readelf -S greet | grep debug # 应显示.debug_info等段,结果如下:

③gdb 调试:
Step 1: 验证编译(上面得到的警告提示):
greet.c: 在函数‘display2’中:
greet.c:25:5: 警告:隐式声明函数‘strlen’ [-Wimplicit-function-declaration]
25 | size = strlen(string1);
| ^\~~\~~\~
greet.c:28:5: 警告:隐式声明函数‘malloc’ [-Wimplicit-function-declaration]
28 | string2 = (char *)malloc(size + 1);
| ^\~~\~~\~
Step 2: 启动GDB调试器
gdb greet
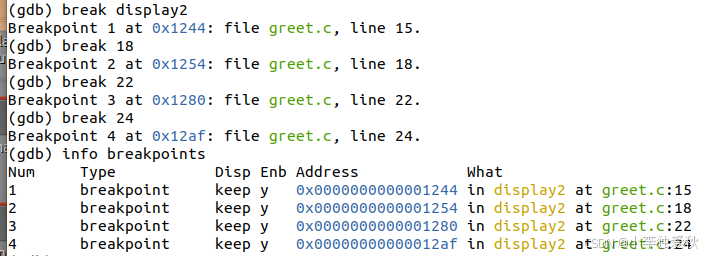
Step 3: 设置关键断点
# 在display2函数入口设置断点
(gdb) break display2
Breakpoint 1 at 0x11e5: file greet.c, line 15.
# 在可能出错的行设置断点
(gdb) break 18 # size = strlen(string1);
(gdb) break 22 # string2[size-i] = string1[i];
(gdb) break 24 # string2[size+1]='\0';
查看断点:
(gdb) info breakpoints
Num Type Disp Enb Address What
1 breakpoint keep y 0x00000000000011e5 in display2 at greet.c:15
2 breakpoint keep y 0x00000000000011f1 in display2 at greet.c:18
3 breakpoint keep y 0x0000000000001234 in display2 at greet.c:22
4 breakpoint keep y 0x000000000000125d in display2 at greet.c:24
运行结果如图:
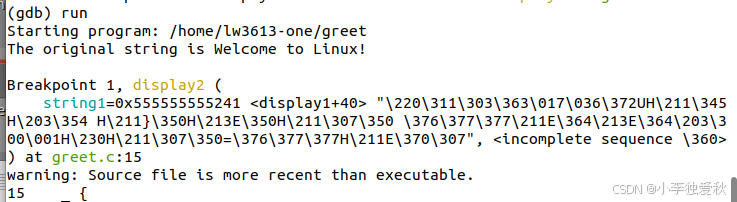
Step 4: 运行程序
在命令行中输入:run,查看运行结果:
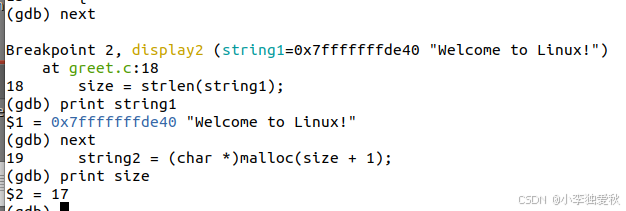
Step 5: 单步调试关键代码
执行到size = strlen(string1):
(gdb) next
18 size = strlen(string1);
(gdb) print string1
$1 = 0x7fffffffde70 "Welcome to Linux!"
查看字符串长度:
(gdb) next
19 string2 = (char *)malloc(size + 1);
(gdb) print size
$2 = 17 # "Welcome to Linux!"长度为17
运行结果如图:
Step 6: 检查内存分配
(gdb) next
20 for(i=0;i<size;i++)
(gdb) print string2
$3 = 0x5555555596b0 "" # 分配17字节(0x11)
(gdb) x/17xb string2 # 查看17字节内存(全为0)
0x5555555596b0: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x5555555596b8: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x5555555596c0: 0x00
运行结果如图:

Step 7: 跟踪循环写入
执行第一次循环:
(gdb) next
22 string2[size-i] = string1[i];
(gdb) print i
$4 = 0
(gdb) print size-i
$5 = 17 # 写入位置string2[17](越界!分配空间索引0-17)
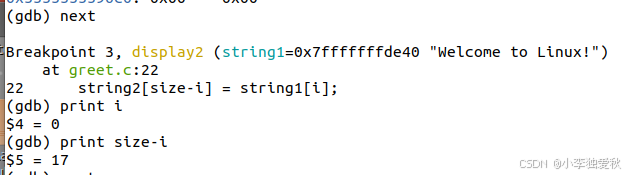
查看内存变化:
(gdb) next
28 for(i=0;i<size;i++)
(gdb) x/17xb string2
0x5555555596b0: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x5555555596b8: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x57 ('W')
0x5555555596c0: 0x00 # string2[16]='W'(实际有效索引0-16)
Step 8: 发现终止符错误
执行到终止符赋值:
(gdb) continue
Continuing.
Breakpoint 3, display2 (string1=0x7fffffffde70 "Welcome to Linux!") at greet.c:22
22 string2[size+1]='\0';
(gdb) print size+1
$6 = 18 # 尝试写入string2[18](越界!)

内存状态检查:
(gdb) x/17xb string2
0x5555555596b0: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x5555555596b8: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x57 ('W')
0x5555555596c0: 0x65 ('e') # 最后一个有效位置是16(0x6c0)
错误总结
1.索引越界
string2[size-i] = string1[i]; // 应改为 string2[size-i-1]
- 当i=0时,写入位置为
size(超出0~size-1范围) - 导致字符串起始位置错误(从索引1开始)
2.终止符错误
string2[size+1] = '\0'; // 应改为 string2[size] = '\0'
- 写入位置超出分配空间(分配size+1字节,有效索引0~size)
④修正后代码(display2函数):
#include <stdio.h>
#include <string.h> // 添加头文件
#include <stdlib.h> // 添加头文件
int display2(char *string1)
{
char *string2;
int size = strlen(string1);
string2 = (char *)malloc(size + 1);
for(int i=0; i<size; i++) {
string2[size-i-1] = string1[i]; // 修正索引
}
string2[size] = '\0'; // 修正终止符
printf("The string afterward is %s\n", string2);
free(string2); // 释放内存
return 0;
}
完整代码如图:
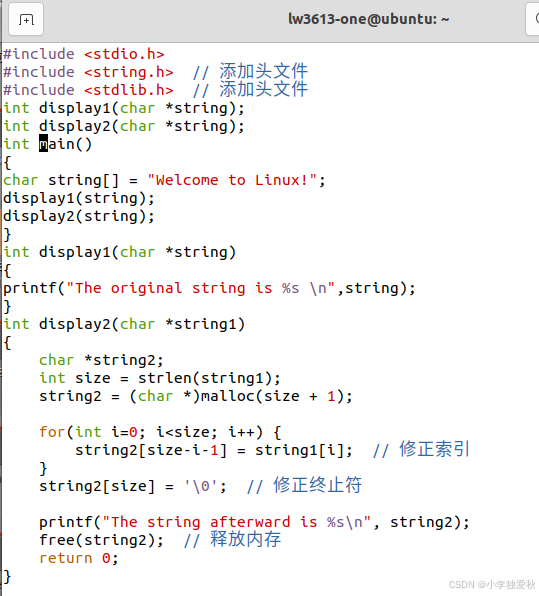
⑤验证修改后的输出结果:
$ ./greet
The original string is Welcome to Linux!
The string afterward is !xuniL ot emocleW
(3)关于GDB调试
GDB核心命令速查表
| 命令 | 功能描述 |
|---|---|
gdb ./greet | 启动调试器 |
break display2 | 在函数入口设断点 |
run | 启动程序运行 |
next (n) | 单步执行(不进入函数) |
step (s) | 单步进入函数 |
print variable | 打印变量值 |
backtrace (bt) | 显示调用堆栈 |
info breakpoints | 查看所有断点 |
x/10xb string2 | 检查内存内容(16进制显示10字节) |
典型调试流程
-
设置观察点:
(gdb) break display2 (gdb) run -
变量监控:
(gdb) watch string2[size] # 监控关键内存位置 -
内存诊断:
(gdb) print sizeof(string1) (gdb) x/16xb string2 # 十六进制查看内存 -
错误定位:
当程序在string2[size+1] = '\0'处崩溃时,使用backtrace查看调用栈,frame N切换堆栈帧检查局部变量
关键概念解析
GCC调试选项原理:
-g选项生成DWARF格式调试信息,包含:
- 源代码行号映射
- 变量类型信息
- 函数调用关系
- 调试信息级别:
| 选项 | 信息量 | 适用场景 |
|---|---|---|
| -g0 | 无调试信息 | 发布版本 |
| -g1 | 最小信息(函数名、外部变量) | 崩溃报告 |
| -g2 | 默认级别(含行号、局部变量) | 常规调试 |
| -g3 | 含宏定义等扩展信息 | 复杂调试场景 |
字符串反转算法优化:
正确实现方式:
void reverseString(char *str) {
int len = strlen(str);
for(int i=0; i<len/2; i++) {
char temp = str[i];
str[i] = str[len-i-1];
str[len-i-1] = temp;
}
}
该实现:
- 时间复杂度O(n/2)
- 空间复杂度O(1)
- 原地操作节省内存
内存管理规范:
-
malloc分配策略:
char *buf = malloc(strlen(src)+1); if(!buf) { /* 错误处理 */ } strcpy(buf, src); /* 使用后 */ free(buf); -
常见错误模式:
| 错误类型 | 后果 | 检测方法 |
|---|---|---|
| 缓冲区溢出 | 内存损坏 | valgrind工具检测 |
| 使用未初始化指针 | 段错误 | 编译警告-Wuninitialized |
| 内存泄漏 | 资源耗尽 | valgrind --leak-check |
通过本实验应掌握以下工程实践能力:
-
防御性编程技巧:
- 输入验证:限制scanf输入长度
- 错误处理:检查malloc返回值
- 资源管理:成对的malloc/free操作
-
调试方法论:
- 二分法定位:通过设置中间断点快速缩小问题范围
- 最小复现样例:将问题代码从复杂系统中剥离测试
- 回归测试:修正错误后验证其他功能不受影响
-
质量保障体系:
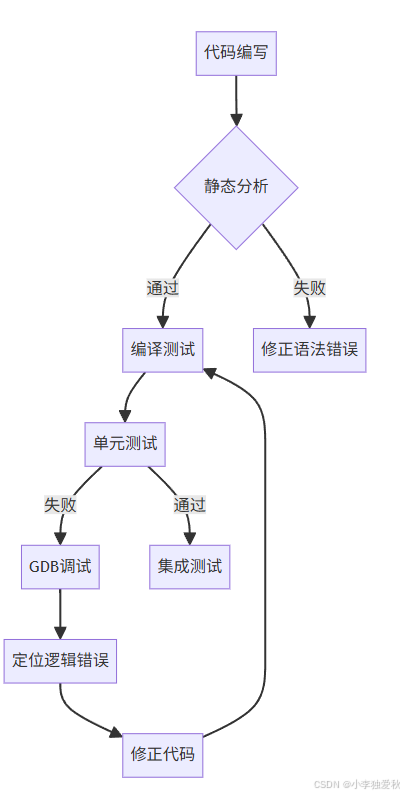
建议后续扩展:
- 结合Makefile实现自动化构建
- 使用Valgrind进行内存泄漏检测
- 配置VS Code远程调试环境提升效率
三、实验总结
在完成这次实验的过程中,我深刻体会到编程不仅是代码的书写,更是一场与细节的博弈。最初面对满屏的警告和运行时的沉默输出,那种无从下手的焦虑感至今记忆犹新。当GDB第一次在断点处停下时,看着内存中错位的字符数据,才真正理解到计算机不会说谎——每一个偏移的计算错误、每一处越界的赋值操作,都在冰冷的寄存器中暴露无遗。
调试过程中最让我震撼的是内存空间的具象化呈现。通过x命令查看内存块时,那些原本抽象的数组索引突然变得触手可及。当亲眼看到string2[16]的位置被错误地写入首字母'W'时,瞬间明白了教科书上强调的"数组从0开始"不是教条,而是真实的物理存储规律。这种从理论到现实的映射,比任何课堂讲解都更有说服力。
在反复的单步执行中,我逐渐领悟到调试器像是程序员的时空机器。通过回看函数调用栈,能清晰看到程序崩溃前的行为轨迹;设置条件断点时,仿佛获得了在时间线上自由穿梭的能力。这种对程序运行状态的完全掌控,让我对"程序是可控的"这句话有了全新认知——即便面对看似随机的崩溃,只要方法得当,总能找到确定的因果链。
这次实验也让我意识到,优秀的代码往往诞生于与编译器的持续对话中。那些起初令人烦躁的-Wall警告,实际上是最严格的语法老师。当开始主动根据警告信息修正代码风格时,发现很多潜在的错误在编译阶段就被提前拦截。这种预防性编程的思维,远比事后调试更有价值。
看着最终正确输出的倒序字符串,不仅是一个实验的完成,更是思维模式的升级。现在的我,开始习惯在写每个循环时下意识检查边界,在每次内存分配后条件反射地思考释放点。这些刻入潜意识的编程习惯,或许就是这次实验给予我最宝贵的礼物。当工具的使用升华成本能,才能真正称得上与机器达成了默契。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











