






前言
设有两个字符串S,T。S为主串,T为子串也可称为模式。在S中查找与模式T相符的子串如果匹配成功,则确定T在主串S中的位置。
著名的模式匹配算法就是BF和KMP。
这两种算法都是用于子串的定位运算,通常称串的模式匹配或串匹配,其用处也非常广泛。如:拼写检测,语言翻译,搜索引擎等等都有用到。
1.BF算法
BF算法最简单直观。
算法的步骤:
1.就是利用两个指针(这里记为指针i和指针j),分别指向主串S,和子串T的当前位置,i的初值为主串S中查找的起始位置,而j初值为T的起始位置(这里设S,T起始位置均为1)。
2.然后比较S[i]和T[j]是否相等。
若相等则,i和j分别指向下一个位置,继续比较下一个字符。
若不相等,指针i退回到(i=i-j+2)处,指针j退回到起始位置1
3.最后如果j>=T.length,就说明T在S中出现,匹配成功。否则就匹配失败。
再看看时间复杂度
当在最好的情况下,即当每次匹配失败都发生在模式串的第一个字符,此时复杂度为: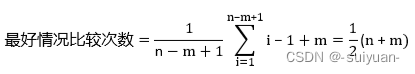
也就是O(n+m)。
而当最坏情况下,即当每次匹配失败都发生在模式串的最后一个字符,此时复杂度为: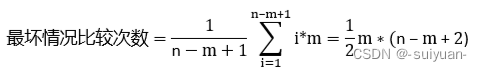
时间复杂度为O(n*m)
虽然BF的时间复杂度为(n*m),但在一般情况下,其实际执行时间近似O(n+m),所以才能至今仍被使用。
2.KMP算法
KMP就有些复杂了,但它可以在时间复杂度为O(n+m)的情况下完成模式匹配。
因为它无需回溯主串的指针。
简单理解其原理:
就是开始时正常匹配,而当主串S指针i和子串T指针j 字符匹配失败时,
在这里还有两种情况:
第一种:匹配的第一个字符就不相同,则此时就让i+1,j不变,继续匹配。
第二种:匹配失败时 j>1,看看T中指针j-1(我们可以将j-1记为k,看作一个新指针) 前面(k-1)个字符是否与i指针前面的(k-1)个字符是否相等,
若不相等,再看指针k=k-1前面(k-2)个字符是否与i指针前面的(k-2)个字符是否相等,再判
断,直至k=1(起始位置),也就是直到k前面没有字符;
当k=1时,就将k赋给j,继续与i位置下的字符进行比较,匹配失败,就让i+1,j不变,继
续匹配
若相等,只需将指针k赋给j再与指针i位置下的字符进行比较;
#为什么是指针j-1(指针k)前面的字符呢?
稍微想想就能理解,如果是j前面的字符,不就和最初匹配时没什么区别了嘛
next
但是只是新加一个指针,时间复杂度可不会只为O(n+m)。有什么更好的方法吗?
我们可以发现让指针k前面的字符串与指针i前面(k-1)个字符进行比较,其实就是与指针j前面(k-1)个字符进行比较。而子串T我们是已知的。所以我们在子串与主串S匹配之前,就能知道k前面字符串是否与i前面的字符串相等。
由上面的原理可以引出next函数 { 0 j=1 next[j] { { k | 1<k<j } { 1 k=1
所以我们在匹配前就可以算出j在每个位置下,k为多少时 前面的字符都与i前面的字符相等。我们可以用next[j]=k,来储存k。然后在匹配失败时将next[j]赋给j,也就是将k赋给j
例:
/*next函数应该怎么求,比如说abaabcac,next[1]=0,next[2]=1,next[3]=1
next[4]=2,next[5]=2,next[6]=3,因为在算到第2个字符,如果第二个字符
就不匹配的,那就让i和第一个字符重新匹配,而第四个字符因为前面的第三个字符是和
第一个字符一样的所以可以让第i个字符和next[4]个字符匹配就是看这个字符之前有几个和
最前面的字符是相同的。*/
int i,j;
i=1;
next[1]=0;
j=0;
while(i<T.length)
{
if(j==0||T.ch[i]==T.ch[j])
{
++i;
++j;
if(T.ch[i]!=T.ch[j])
next[i]=j;
else
next[i]=next[j];
}
else
j=next[j];
}nextval
但next函数还是有缺陷的,例如主串S="aaaabcde",子串T="aaaaax",其next数组值分别为012345,在开始时,当i=5、j=5时,我们发现“b”与“a”不相等,因此j=next[5]=4,此时“b”与第4位置的“a”依然不等,j=next[4]=3,直到j=next[1]=0时,根据算法,此时i++、j++,得到i=6、j=1。
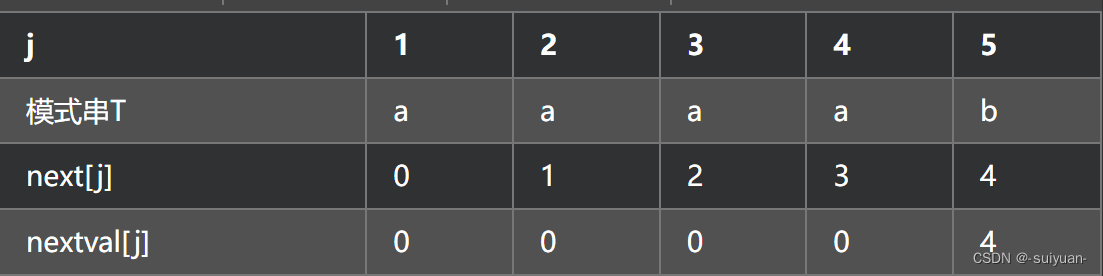
next还是有多余的步骤,所以用nextval[j],进行修正。
nextval计算方法
当j=1时,nextval[1]=0
当j>1时,用当前指针j1字符,与j2=next[j1]指针的字符进行比较,若相等则nextval[j1] = nextval[j2],若不相等则nextval[j1] = next[j1]
例如:















 1170
1170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









