






 本文介绍了生成式对抗网络(GAN)的基本概念、训练过程、实际应用案例,如图像生成、数据增强和风格迁移,并提供了Python代码示例,展示了如何使用GAN生成手写数字。通过评估指标和损失曲线,探讨了训练效果的评判标准。
本文介绍了生成式对抗网络(GAN)的基本概念、训练过程、实际应用案例,如图像生成、数据增强和风格迁移,并提供了Python代码示例,展示了如何使用GAN生成手写数字。通过评估指标和损失曲线,探讨了训练效果的评判标准。
一、什么是GAN呢
1、概述
生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,014年lan Goodfellow的开篇之作Generative Adversarial Network,是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。原始 GAN 理论中,并不要求 G 和 D 都是神经网络,只需要是能拟合相应生成和判别的函数即可。但实用中一般均使用深度神经网络作为 G 和 D 。GAN在各种领域都有广泛的应用,包括图像生成、文本生成、视频生成等
GAN的目标是通过训练生成器和判别器来使生成器能够生成逼真的样本,以至于判别器无法区分生成的样本和真实样本。
生成器的任务是将随机噪声作为输入,生成与真实样本相似的样本,而判别器的任务是根据输入样本判断其是否为真实样本。两个模型相互对抗,生成器试图生成逼真的样本以欺骗判别器,而判别器则努力提高其判别能力以区分真实样本和生成样本。
2、训练过程
GAN的训练过程如下:
- 随机生成一批噪声样本作为输入给生成器。
- 生成器生成一批样本。
- 将生成的样本与真实样本混合,作为输入给判别器。
- 判别器对输入样本进行判别并输出判别结果。
- 根据判别结果,计算生成器和判别器的损失函数。
- 更新生成器和判别器的参数,通过反向传播进行梯度更新。
- 重复步骤1-6,直到生成器生成的样本达到预期的质量。
整体流程如下图所示:
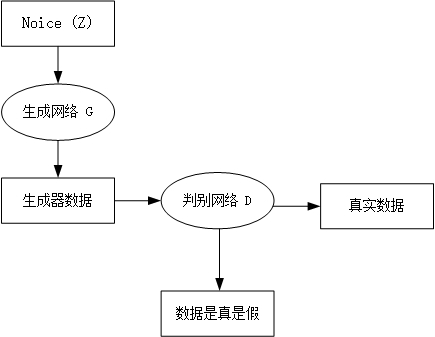
二、GAN实际案例
1、生成图像
生成对抗网络通过基于文本的提示或修改现有图像来创建逼真的图像。它们可以协助在视频游戏和数字娱乐中创造逼真、身临其境的视觉体验。
GAN 还可以编辑图像,例如将低分辨率图像转换为高分辨率图像,或将黑白图像转换为彩色图像。该工具还可以为动画和视频打造逼真的面部、角色和动物。
2、为其他模型生成训练数据
在机器学习(ML)中,数据增强通过使用现有数据创建数据集的已修改副本来人为地增加训练集规模。
可以使用生成模型进行数据增强,以创建具有现实世界数据所有属性的合成数据。例如,机器学习可以生成欺诈性交易数据,然后使用这些数据训练另一个欺诈检测机器学习系统。这些数据可以教导系统准确区分可疑交易和真实交易。
3、补全缺失的信息
有时,您可能希望生成模型能够准确地猜测并补全数据集中的一些缺失信息。
例如,您可以通过了解地表数据与地下结构之间的相关性来训练 GAN 生成地下表面(次表面)的图像。通过研究已知的次表面图像,GAN 可以使用地形图创建用于能源应用的新图像,例如地热测绘或碳捕集和储存。
4、根据 2D 数据生成 3D 模型
GAN 可以根据 2D 照片或扫描的图像生成 3D 模型。例如,在医疗保健领域,GAN 将 X 射线和其他身体扫描相结合以创建逼真的器官图像,将其用于手术计划和模拟。
5、风格迁移
GAN可以用于风格迁移任务。风格迁移是将一个图像的内容与另一个图像的风格相结合,生成一个新的图像,使其既保留原始图像的内容,又具有目标图像的风格。例如下图中斑马与马肤色特点之间的转换:

6、其他
GAN在其他方面依旧表现出色,例如虚拟现实和游戏、音频合成、文本生成、药物发现和人工艺术的创新,由于GAN的强大生成能力,它在创造性任务和模拟现实世界中具有巨大的潜力。
三、GAN架构
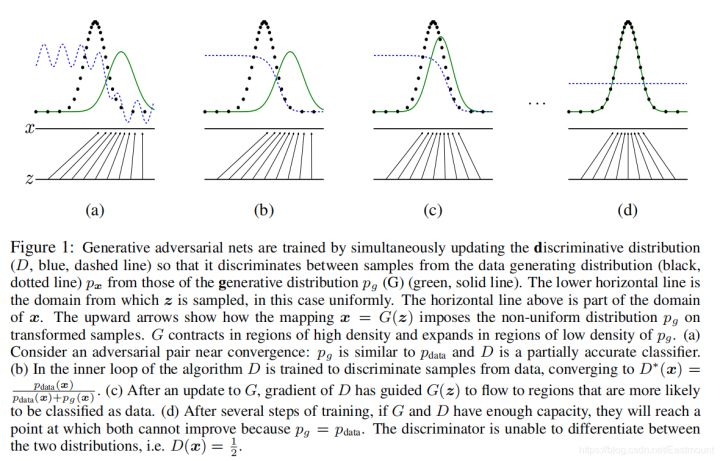
原论文就是如此,如此的头疼,接下来一点点看到底是什么意思
- 最开始在图(a)中我们生成绿线,即生成样本的概率分布,黑色的散点是真实样本的概率分布,这条蓝线是一个判决器,判断什么时候应该是真的或假的。
- 我们第一件要做的事是把判决器判断准,如图(b)中蓝线,假设在0.5的位置下降,之前的认为是真实样本,之后的认为是假的样本。
- 当它固定完成后,在图(c)中,生成器想办法去和真实数据作拟合,想办法去误导判决器。
- 最终输出图(d),如果你真实的样本和生成的样本完全一致,分布完全一致,判决器就傻了,无法继续判断。
下面先举一个例子来说明GAN
- 生成器:学习真实样本以假乱真
- 判别器:小孩通过学习成验钞机的水平

GAN的整体思路是一个生成器,一个判别器,并且GoodFellow论文证明了GAN全局最小点的充分必要条件是:生成器的概率分布和真实值的概率分布是一致的时候。

(1) 目标函数
该目标函数如下所示,其中:
- max()式子是第一步,表示把生成器G固定,让判别器尽量区分真实样本和假样本,即希望生成器不动的情况下,判别器能将真实的样本和生成的样本区分开。
- min()式子是第二步,即整个式子。判别器D固定,通过调整生成器,希望判别器出现失误,尽可能不要让它区分开。
这也是一个博弈的过程。论文中公式如下:
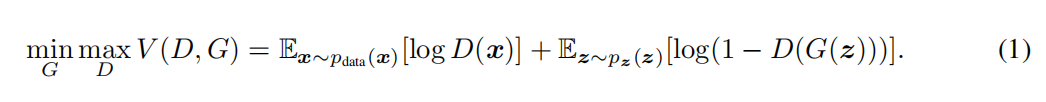
整个公式的具体含义如下:
- 式子由两项构成,x表示真实图片,z表示输入G网络的噪声,而G(z)表示G网络生成的图片。
- D(x)表示D网络判断真实图片是否真实的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。
- D(G(z))是D网络判断G生成的图片是否真实的概率。
- G的目的:G应该希望自己生成的的图片越接近真实越好。
- D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小,这时V(D,G)会变大,因此式子对于D来说是求最大(max_D)。
- trick:为了前期加快训练,生成器的训练可以把log(1-D(G(z)))换成-log(D(G(z)))损失函数。
原论文中 的算法流程如下:

(2) GAN图片生成
接着我们介绍训练方案,通过GAN生成图片。
- 第一步(左图):希望判决器尽可能地分开真实数据和我生成的数据。那么,怎么实现呢?我的真实数据就是input1(Real World images),我生成的数据是input2(Generator)。input1的正常输出是1,input2的正常输出是0,对于一个判决器(Discriminator)而言,我希望它判决好,首先把生成器固定住(虚线T),然后生成一批样本和真实数据混合给判决器去判断。此时,经过训练的判决器变强,即固定生成器且训练判决器。
- 第二步(右图):固定住判决器(虚线T),我想办法去混淆它,刚才经过训练的判决器很厉害,此时我们想办法调整生成器,从而混淆判别器,即通过固定判决器并调整生成器,使得最后的输出output让生成的数据也输出1(第一步为0)。
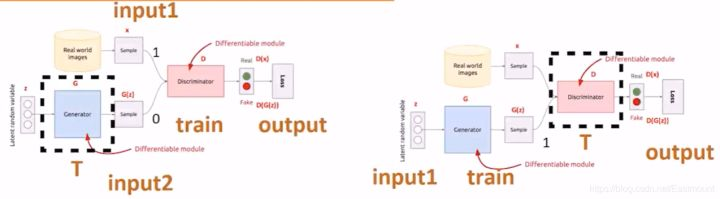
GAN的核心就是这些,再简单总结下,即:
- 步骤1是在生成器固定的时候,我让它产生一批样本,然后让判决器正确区分真实样本和生成样本。(生成器标签0、真实样本标签1)
- 步骤2是固定判决器,通过调整生成器去尽可能的瞒混判决器,所以实际上此时训练的是生成器。(生成器的标签需要让判决器识别为1,即真实样本)
四、生成手写数字代码示例
1、训练过程
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.autograd.variable import Variable
from torchsummary import summary
import numpy as np
import matplotlib.pyplot as plt
# 定义生成器模型
class Generator(nn.Module):
def __init__(self, input_size, output_size):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_size, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 1024),
nn.ReLU(),
nn.Linear(1024, output_size),
nn.Tanh()
)
def forward(self, x):
x = self.model(x)
return x
# 定义判别器模型
class Discriminator(nn.Module):
def __init__(self, input_size):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_size, 1024),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
x = self.model(x)
return x
# 定义训练函数
def train(generator, discriminator, dataloader, num_epochs, generator_optimizer, discriminator_optimizer, loss_function, device):
generator.to(device)
discriminator.to(device)
generator.train()
discriminator.train()
for epoch in range(num_epochs):
for i, (real_images, _) in enumerate(dataloader):
batch_size = real_images.size(0)
real_images = real_images.view(batch_size, -1).to(device)
# 训练判别器
discriminator.zero_grad()
real_labels = torch.ones(batch_size, 1).to(device)
fake_labels = torch.zeros(batch_size, 1).to(device)
# 判别器对真实图像的判别结果
real_outputs = discriminator(real_images)
real_loss = loss_function(real_outputs, real_labels)
# 生成假图像并判别
noise = Variable(torch.randn(batch_size, 100)).to(device)
fake_images = generator(noise)
fake_outputs = discriminator(fake_images.detach())
fake_loss = loss_function(fake_outputs, fake_labels)
# 计算判别器总损失并进行反向传播和优化
discriminator_loss = real_loss + fake_loss
discriminator_loss.backward()
discriminator_optimizer.step()
# 训练生成器
generator.zero_grad()
fake_outputs = discriminator(fake_images)
generator_loss = loss_function(fake_outputs, real_labels)
# 反向传播和优化
generator_loss.backward()
generator_optimizer.step()
# 输出训练信息
if (i+1) % 200 == 0:
print('Epoch [{}/{}], Step [{}/{}], Generator Loss: {:.4f}, Discriminator Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, len(dataloader), generator_loss.item(), discriminator_loss.item()))
# 保存生成器模型
torch.save(generator.state_dict(), "generator_weights.pth")
print("Generator model saved.")
# 设置训练参数
input_size = 100
output_size = 784
batch_size = 100
num_epochs = 100
learning_rate = 0.0002
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载MNIST数据集
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
mnist_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
dataloader = DataLoader(dataset=mnist_dataset, batch_size=batch_size, shuffle=True)
# 创建生成器和判别器实例
generator = Generator(input_size, output_size)
discriminator = Discriminator(output_size)
# 定义损失函数和优化器
loss_function = nn.BCELoss()
generator_optimizer = optim.Adam(generator.parameters(), lr=learning_rate)
discriminator_optimizer = optim.Adam(discriminator.parameters(), lr=learning_rate)
# 训练GAN
train(generator, discriminator, dataloader, num_epochs, generator_optimizer, discriminator_optimizer, loss_function, device)
# 打印生成器模型的摘要信息
summary(generator, (input_size,))
# 生成数字图像
num_samples = 10
noise = Variable(torch.randn(num_samples, input_size)).to(device)
generator.eval()
with torch.no_grad():
generated_images = generator(noise)
generated_images = generated_images.view(num_samples, 1, 28, 28)
generated_images = generated_images.cpu().numpy()
# 显示生成的数字图像
fig, axes = plt.subplots(1, num_samples, figsize=(10, 2))
for i, image in enumerate(generated_images):
axes[i].imshow(np.squeeze(image), cmap='gray')
axes[i].axis('off')
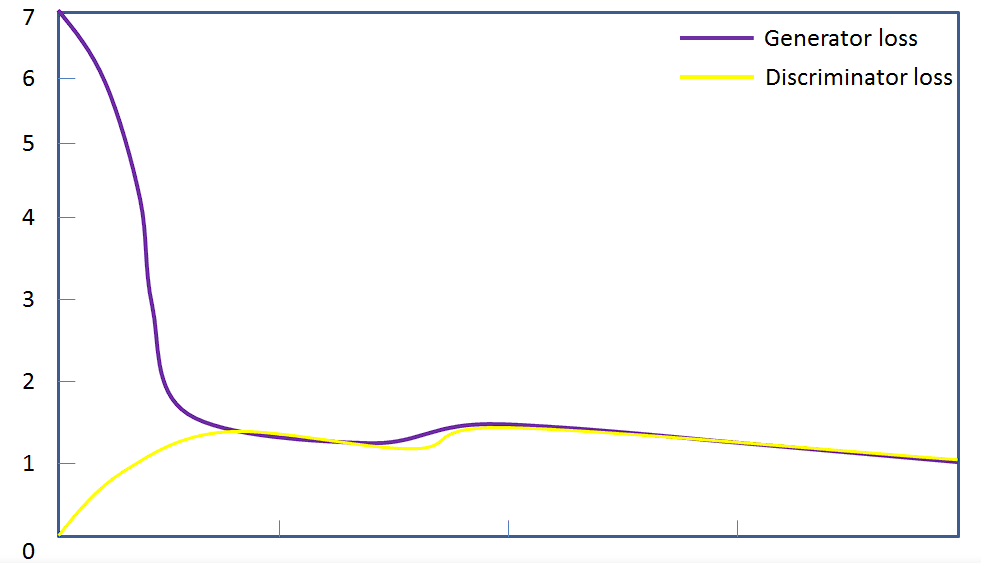
plt.show()训练过程可视化如下图所示:

2、预测结果
使用训练好的模型去生成一个25个数字的图片代码和结果如下
import torch
import torch.nn as nn
from torchvision.utils import save_image
# 定义生成器模型
class Generator(nn.Module):
def __init__(self, input_size, output_size):
super(Generator, self).__init__()
self.input_size = input_size # 添加 input_size 属性
self.model = nn.Sequential(
nn.Linear(input_size, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 1024),
nn.ReLU(),
nn.Linear(1024, output_size),
nn.Tanh()
)
def forward(self, x):
x = self.model(x)
return x
# 创建生成器实例
input_size = 100 # 输入噪声的大小
output_size = 784 # 输出图像的大小(28x28)
generator = Generator(input_size, output_size)
# 加载训练好的生成器权重
generator.load_state_dict(torch.load("generator_weights.pth"))
# 生成数字
num_digits = 25 # 要生成的数字数量
output_path = "generated_digits.png" # 生成的数字图像保存路径
# 设置生成器为评估模式
generator.eval()
with torch.no_grad():
noise = torch.randn(num_digits, input_size) # 生成随机噪声,使用 input_size
generated_images = generator(noise) # 使用生成器生成数字图像
generated_images = generated_images.view(num_digits, 1, 28, 28) # 重新调整图像大小
# 将生成的数字保存为图像文件
save_image(generated_images, output_path, nrow=int(num_digits ** 0.5), normalize=True)
print(f"Generated {num_digits} digits and saved to {output_path}.")
值得注意的是如何去评判训练结果的好坏,需要从以下几个方面去判别:
1、生成器损失:生成器的损失指标表明生成器生成的样本与真实样本之间的差异程度。当生成器损失趋近于0时,表示生成器能够生成与真实样本非常接近的样本,这是一个好的指标。
2、判别器损失:判别器的损失指标表明判别器对真实样本和生成样本的判别能力。当判别器损失趋近于0.5时,表示判别器无法区分真实样本和生成样本,即它们的判别能力相当。这也是一个好的指标。
3、损失曲线:通过观察生成器和判别器的损失随时间变化的曲线,可以判断训练的效果。如果损失曲线在训练过程中稳定下降,并且生成器和判别器的损失都收敛到一个较低的值,那么可以认为训练效果较好。
3、动画演示
以下动画显示了生成器生成的一系列图像,因为它已经过50个历元的训练。 图像以随机噪声开始,随着时间的推移越来越像手写数字。这个GitHUb 资源在MNIST数据集上演示了这个过程

参考:华为开发者论坛















 3082
3082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









