






Diffusion 扩散模型(DDPM)
一、什么是扩散模型?
随着Stable Diffusion 3的问世,AI绘画再次成为最为火热的AI方向之一,那么不可避免地再次会问到Stable Diffusion里的这个”Diffusion”到底是什么?其实扩散模型(Diffusion Model)正是Stable Diffusion中负责生成图像的模型。
对Stable Diffusion 3好奇的可以看这个文章:https://www.jiqizhixin.com/articles/2024-03-06-3
我们今天来看最基础的去噪扩散模型(DDPM),那么什么才是去噪扩散模型呢?
DDPM 是一种基于马尔科夫链的生成模型。其基本思想是将数据生成视为一个逐步去噪的过程,即从纯噪声逐渐生成真实数据。它通过两个过程实现:
- 前向扩散过程(Forward Diffusion Process): 将数据逐步添加噪声,直到得到一个几乎完全是噪声的数据。
- 逆向生成过程(Reverse Generation Process): 学习如何逐步去除噪声,以恢复原始数据。
步骤:
- 前向过程从原始数据开始,通过一系列加噪步骤,将数据转换为高斯噪声。
- 逆向过程从纯噪声开始,通过一系列去噪步骤,逐步恢复原始数据。
这其实就是跟盖房子和拆房子一个道理,是将一个随机噪声z变换成一个数据样本x的过程:
随机噪声
z
→
变换
样本数据
x
类比
↓
↓
类比
砖瓦水泥
→
建设
高楼大夏
\begin{array}{ccc} \text { 随机噪声 } \boldsymbol{z} & \xrightarrow{\text { 变换 }} & \text { 样本数据 } \boldsymbol{x} \\ \text { 类比 } \downarrow & & \downarrow \text { 类比 } \\ \text { 砖瓦水泥 } & \xrightarrow{\text { 建设 }} & \text { 高楼大夏 } \end{array}
随机噪声 z 类比 ↓ 砖瓦水泥 变换 建设 样本数据 x↓ 类比 高楼大夏
可以将这个过程想象为“建设”,其中随机噪声z是砖瓦水泥等原材料,样本数据x是高楼大厦,所以生成模型就是一支用原材料建设高楼大厦的施工队。
为什么把一张图加上噪点,再去掉噪点变回一张图,就可以不仅学会数据分布,还能创新?
听起来将噪声添加到图像中,然后再去除这些噪声,看似是一个无意义的过程。
您有一幅精细的画作。如果您在这幅画上逐渐加入噪声(比如点、线、模糊等),画面将逐渐失去原有的形态,最终变成一片混乱。在这个过程中,画的每一部分都以不同的方式逐渐变得不可识别。这个逐步增加噪声的过程就是扩散模型中的“前向过程”。重要的部分来了:当**使用扩散模型时,AI不仅学习如何将噪声添加到图像中,更重要的是,它学习了如何从这片混乱中恢复出原始的图像,这就是“逆向过程”。**在这个逆向过程中,AI必须理解图像中每个像素的原始状态,以及这些像素是如何相互关联的,从而能够准确地去除噪声,恢复图像。通过这种方式,AI学习到的不仅仅是图像本身的特征,还包括图像中的内容如何随着噪声的增加而逐渐变化和消失。这意味着,当AI需要生成新图像或重建图像时,它已经理解了图像的深层结构和像素间的复杂关系。因此,尽管看起来像是给图像加噪声再去噪声的简单过程,实际上扩散模型学习到的不仅仅是简单的图像恢复。更重要的是,它理解了图像各部分如何相互关联,以及这些部分如何随噪声增加或减少而变化。这个过程超越了简单的图像复制或模仿,而是向AI提供了对图像深层结构的深入理解。
二、与传统的GAN有何区别?
GAN可以参考:生成对抗网络—GAN_生成对抗网络gan-CSDN博客
我们先看看一般的神经网络模型是怎么生成图像的?显然,**为了生成丰富的图像,一个图像生成程序要根据随机数来生成图像。通常,这种随机数是一个满足标准正态分布的随机向量。**这样,每次要生成新图像时,只需要从标准正态分布里随机生成一个向量并输入给程序就行了。
而在AI绘画程序中,负责生成图像的是一个神经网络模型。神经网络需要从数据中学习。对于图像生成任务,神经网络的训练数据一般是一些同类型的图片。比如一个绘制人脸的神经网络会用人脸照片来训练。也就是说,神经网络会学习如何把一个向量映射成一张图片,并确保这个图片和训练集的图片是一类图片。
可是,相比其他AI任务,图像生成任务对神经网络来说更加困难一点——图像生成任务缺乏有效的指导。在其他AI任务中,训练集本身会给出一个「标准答案」,指导AI的输出向标准答案靠拢。比如对于图像分类任务,训练集会给出每一幅图像的类别;对于人脸验证任务,训练集会给出两张人脸照片是不是同一个人;对于目标检测任务,训练集会给出目标的具体位置。然而,图像生成任务是没有标准答案的。图像生成数据集里只有一些同类型图片,却没有指导AI如何画得更好的信息。
为了解决这一问题,人们专门设计了一些用于生成图像的神经网络架构。这些架构中比较出名的有生成对抗模型(GAN)和变分自编码器(VAE)。
GAN的目标是通过训练生成器和判别器来使生成器能够生成逼真的样本,以至于判别器无法区分生成的样本和真实样本。生成器的任务是将随机噪声作为输入,生成与真实样本相似的样本,而判别器的任务是根据输入样本判断其是否为真实样本。两个模型相互对抗,生成器试图生成逼真的样本以欺骗判别器,而判别器则努力提高其判别能力以区分真实样本和生成样本。

但是GAN 因为需要同时训练生成器和判别器,并且很难找到一个平衡点。生成器有时候会通过一些“捷径”欺骗判别器,导致生成的效果不佳。此外GAN生成的样本多样性有限,只适用于特定的判别器。**
扩散模型为什么好过GAN?
由于程序互相对抗的标准是人类导师给定的样本,因此生成的内容实质上只是对现有内容无限地逼近模仿,而模仿则意味着无法实现真正的突破。
Diffusion 是自己探索的过程。扩散模型只需要在生成过程中进行逐步的扩散操作,使生成的样本逐渐接近真实分布。通过逐步扩散噪声的方式生成样本,提高了生成样本的质量和多样性,并且具有更稳定的训练过程。这种训练方式可以避免生成器通过“捷径”欺骗判别器的问题,提高了生成效果。如滴入一杯清水中的墨滴一样,慢慢散开最终变成一片浑浊。如果这个过程可逆,就可以创造由一片浑浊去探寻最初墨滴状态的方法。
不同类型的生成模型概述如下图: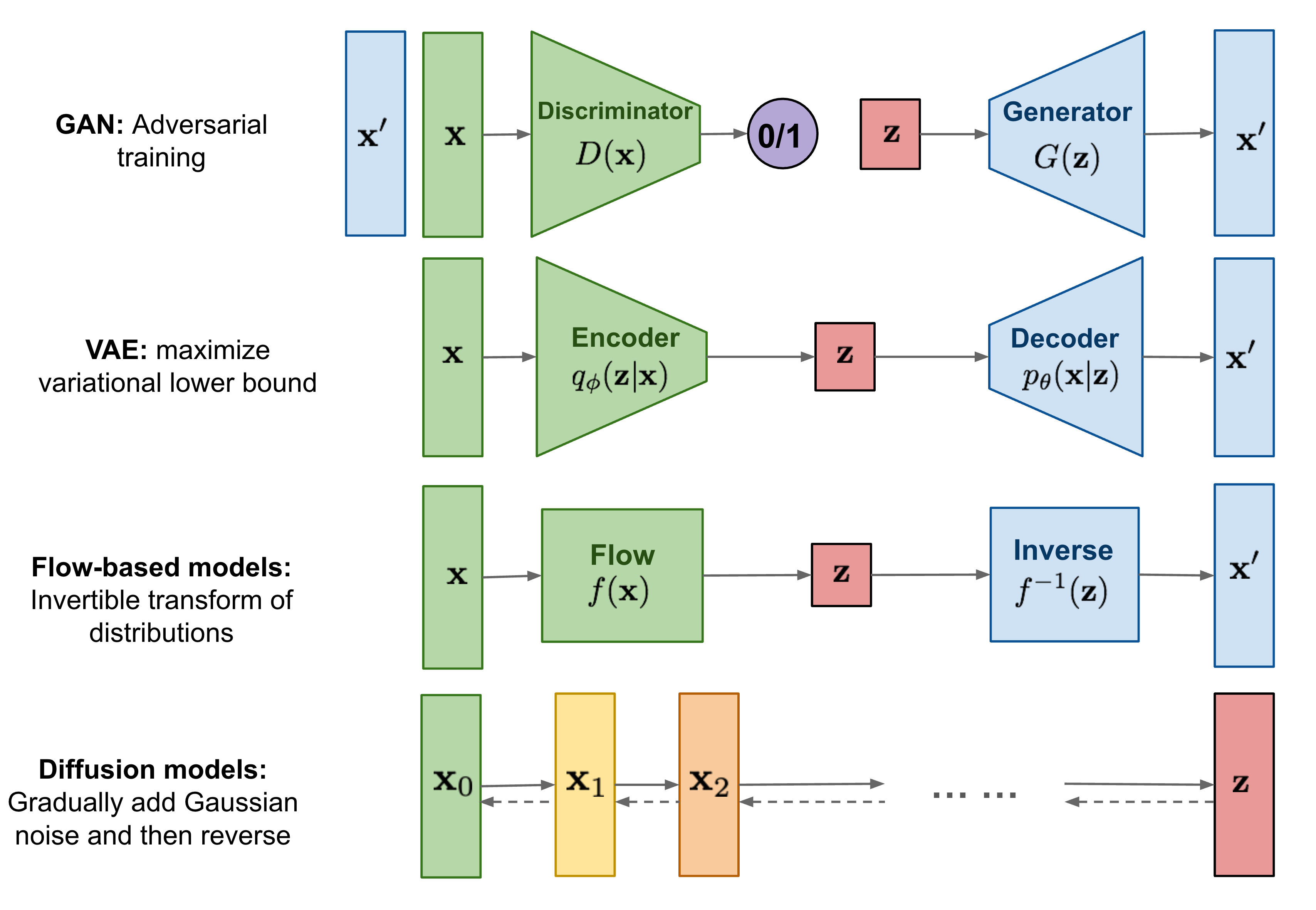
三、扩散模型算法
具体来说,扩散模型由正向过程和反向过程这两部分组成。在正向过程中,输入x会不断混入高斯噪声。经过𝑇次加噪声操作后,图像x_T会变成一幅符合标准正态分布的纯噪声图像。而在反向过程中,我们希望训练出一个神经网络,该网络能够学会𝑇个去噪声操作,把𝑥_𝑇还原回𝑥_0。网络的学习目标是让𝑇个去噪声操作正好能抵消掉对应的加噪声操作。训练完毕后,只需要从标准正态分布里随机采样出一个噪声,再利用反向过程里的神经网络把该噪声恢复成一幅图像,就能够生成一幅图片了。
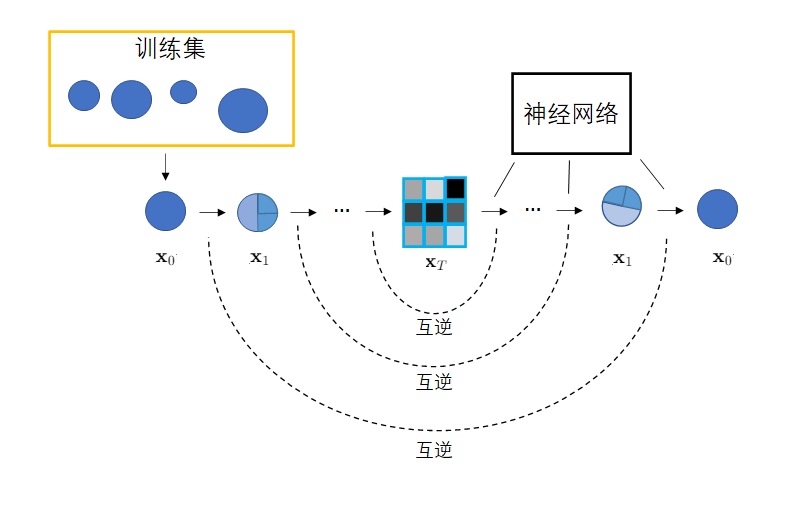
1、前向过程
这里直接引用https://zhouyifan.net/2023/07/07/20230330-diffusion-model/,讲解很详细



2、反向过程



这样,我们就认识了反向过程的所有内容。总结一下,反向过程中,神经网络应该让𝑇个去噪声操作拟合对应的𝑇个加噪声逆操作。每步加噪声逆操作符合正态分布,且在给定某个输入时,该正态分布的均值和方差是可以用解析式表达出来的。因此,神经网络的学习目标就是让其输出的去噪声分布和理论计算的加噪声逆操作分布一致。经过数学计算上的一些化简,问题被转换成了拟合生成𝑥_𝑡时用到的随机噪声𝜖_𝑡
3、训练算法与采样算法
以下是DDPM论文中的训练算法:


训练好了网络后,我们可以执行反向过程,对任意一幅噪声图像去噪,以实现图像生成。这个算法如下:


四、扩散模型总结
扩散模型(Diffusion Models)是一类基于概率和马尔科夫链的生成模型,通过逐步添加和去除噪声实现数据生成。以下是扩散模型的主要特点、工作原理、优势和应用领域的总结。
1、主要特点
- 基于马尔科夫链:扩散模型通过一个多步骤的马尔科夫链过程逐步生成数据。
- 逐步生成:数据生成是一个逐步去噪的过程,从纯噪声开始,逐步恢复到真实数据。
- 高斯噪声:通常使用高斯噪声作为扩散过程中的噪声分布。
- 概率建模:通过最大化数据的对数似然估计或变分下界(Variational Lower Bound, VLB)来训练模型。
2、工作原理
扩散模型的工作原理包括两个主要过程:
-
前向扩散过程(Forward Diffusion Process):
- 从原始数据开始,逐步添加噪声,直到数据完全变成高斯噪声。
- 每一步的噪声添加是小幅度的,遵循高斯分布。
-
逆向生成过程(Reverse Generation Process):
- 从纯噪声开始,通过学习的去噪网络,逐步去除噪声,生成原始数据。
- 每一步的去噪也是小幅度的,确保生成过程的稳定性和质量。
3、优势
- 训练稳定性:扩散模型的训练过程通常比生成对抗网络(GAN)更加稳定,因为它不涉及对抗训练,而是直接优化变分下界或对数似然估计。
- 生成质量:扩散模型可以生成高质量的数据,特别是在图像生成任务中表现出色。
- 概率解释性:扩散模型有明确的概率解释,能够更好地控制生成过程和评估生成数据的概率分布。
4、应用领域
扩散模型在多个领域具有广泛的应用,包括但不限于:
- 图像生成:通过逆向去噪过程生成高质量的图像。
- 图像去噪:利用模型的去噪能力去除图像中的噪声。
- 音频生成:应用于音频生成和去噪,生成高质量的音频样本。
- 其他生成任务:包括文本生成、视频生成等需要逐步生成的任务。
5、主要模型
- DDPM(Denoising Diffusion Probabilistic Models):经典的去噪扩散模型,基于马尔科夫链和高斯噪声,广泛应用于图像生成任务。
- DDIM(Denoising Diffusion Implicit Models):基于DDPM的改进模型,通过减少生成步骤提高生成效率。
五、扩散模型复现MINST(pytorch)
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from diffusers import DDPMScheduler, UNet2DModel
from matplotlib import pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f'Using device: {device}')
dataset = torchvision.datasets.MNIST(root="mnist/",
train=True,
download=True,
transform=torchvision.transforms.ToTensor())
train_dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
# pytorch传统艺能 用DataLoader加载数据
x, y = next(iter(train_dataloader))
print('Input shape:', x.shape)
print('Labels:', y)
plt.imshow(torchvision.utils.make_grid(x)[0], cmap='Greys');
def corrupt(x, amount):
# 根据输入的amount 对 图像加噪
noise = torch.rand_like(x)
amount = amount.view(-1, 1, 1, 1)
# 使用.view方法修改形状
return x*(1-amount) + noise*amount
# 显示一下输入图像
fig, axs = plt.subplots(2, 1, figsize=(12, 5))
axs[0].set_title('Input data')
axs[0].imshow(torchvision.utils.make_grid(x)[0], cmap='Greys')
# 为图像添加噪声
amount = torch.linspace(0, 1, x.shape[0]) # Left to right -> more corruption
noised_x = corrupt(x, amount)
# 画出添加噪声之后的图像
axs[1].set_title('Corrupted data (-- amount increases -->)')
axs[1].imshow(torchvision.utils.make_grid(noised_x)[0], cmap='Greys');
class BasicUNet(nn.Module):
# 简易版的U-net
def __init__(self, in_channels=1, out_channels=1):
super().__init__()
self.down_layers = torch.nn.ModuleList([
nn.Conv2d(in_channels, 32, kernel_size=5, padding=2),
nn.Conv2d(32, 64, kernel_size=5, padding=2),
nn.Conv2d(64, 64, kernel_size=5, padding=2),
])
self.up_layers = torch.nn.ModuleList([
nn.Conv2d(64, 64, kernel_size=5, padding=2),
nn.Conv2d(64, 32, kernel_size=5, padding=2),
nn.Conv2d(32, out_channels, kernel_size=5, padding=2),
])
# 激活函数
self.act = nn.SiLU()
self.downscale = nn.MaxPool2d(2)
self.upscale = nn.Upsample(scale_factor=2)
def forward(self, x):
h = []
for i, l in enumerate(self.down_layers):
x = self.act(l(x))
if i < 2:
h.append(x)
x = self.downscale(x)
for i, l in enumerate(self.up_layers):
if i > 0:
x = self.upscale(x)
x += h.pop()
x = self.act(l(x))
return x
net = BasicUNet()
x = torch.rand(8, 1, 28, 28)
net(x).shape
# Dataloader 加载数据
batch_size = 128
train_dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 我们要训练多少轮
n_epochs = 10
# 创建网络,将模型丢到GPU上(如果有GPU的话)
net = BasicUNet()
net.to(device)
# 损失函数是用的MSE loss
loss_fn = nn.MSELoss()
# 优化器使用的Adam
opt = torch.optim.Adam(net.parameters(), lr=1e-3)
# 记录损失
losses = []
# 训练循环
for epoch in range(n_epochs):
for x, y in train_dataloader:
# 准备好输入数据和加噪数据
# 把数据放到GPU上(如果你有的话)
x = x.to(device)
# 设定随机噪声
noise_amount = torch.rand(x.shape[0]).to(device)
# 处理x,获得加噪之后的样本noisy_x
noisy_x = corrupt(x, noise_amount)
# 获取模型输出结果
pred = net(noisy_x)
# 计算loss
loss = loss_fn(pred, x) # How close is the output to the true 'clean' x?
# 反向传播更新模型参数
opt.zero_grad()
loss.backward()
opt.step()
# 存储loss记录
losses.append(loss.item())
# 输出每轮训练的loss的平均值
avg_loss = sum(losses[-len(train_dataloader):]) / len(train_dataloader)
print(f'Finished epoch {epoch}. Average loss for this epoch: {avg_loss:05f}')
# 画一下loss
plt.plot(losses)
plt.ylim(0, 0.1);
# 取一组图像
x, y = next(iter(train_dataloader))
x = x[:8] # Only using the first 8 for easy plotting
# 用我们前边给八张图加噪的那个方法,看看模型对不同程度的噪声的回复情况
amount = torch.linspace(0, 1, x.shape[0])
noised_x = corrupt(x, amount)
# 获取模型结构
with torch.no_grad():
preds = net(noised_x.to(device)).detach().cpu()
# 画出结果来
fig, axs = plt.subplots(3, 1, figsize=(12, 7))
axs[0].set_title('Input data')
axs[0].imshow(torchvision.utils.make_grid(x)[0].clip(0, 1), cmap='Greys')
axs[1].set_title('Corrupted data')
axs[1].imshow(torchvision.utils.make_grid(noised_x)[0].clip(0, 1), cmap='Greys')
axs[2].set_title('Network Predictions')
axs[2].imshow(torchvision.utils.make_grid(preds)[0].clip(0, 1), cmap='Greys');

参考:https://juejin.cn/post/7208099962910687287
https://blog.csdn.net/qq_41739364/article/details/134926181
https://zhouyifan.net/2023/07/07/20230330-diffusion-model/
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/















 2248
2248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









