







本文主要介绍如何调用文心一言提供的API,初步往自己的应用程序中接入语言大模型,适合初学者,了解一步步地通过HTTP接入外部的服务。
如果你在配置过程中忘记了哪些页面是干啥的,欢迎回到此处查找页面。
1、需求
了解需求的重要性不需要我多说了,由于是入门案例,所以尽可能简单快速。
需求:通过Java 语言,在服务器内部发送HTTP请求,携带我需要问的问题,GPT解析我的问题,返回给我答案。
这样一个需求,显然需要GPT方提供一个API,用于收到我的HTTP请求,然后,解析报文中的内容,然后响应给我的服务器。
好,开干。
2、前置准备
既然要调用人家的API,显然需要遵循人家提供好的操作步骤来完成调用。
2.1 创建应用
打开页面:
会弹出一些注册账号、实名认证的一些东西,快速完成,此处省略不写。
完成认证后,在点击一下上面的页面链接:进入控制台。
此处时间充裕的小伙伴可以看一下操作文档:
不看也没关系
点击应用接入,然后点击创建应用,填写应用名称、应用描述、服务是固定的、不能选择,默认全选,不过放心,是有免费额度的,学习的话绰绰有余。
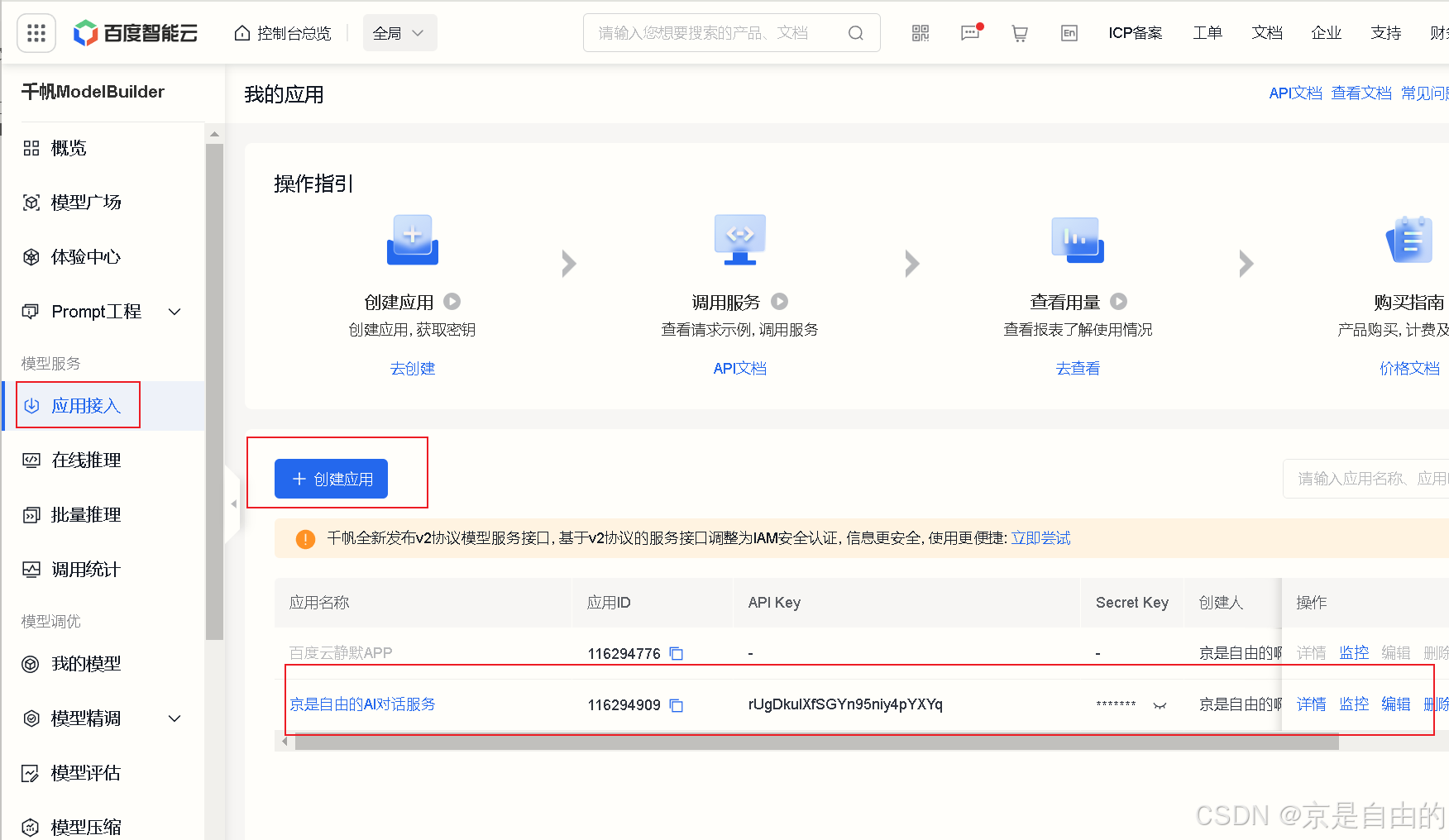
记录好上面的API Key和Secret Key,后面会用到,注意保密。
2.2 获取access_token
可以先看文档
鉴权就类似于登录功能,用于识别谁在调用文心一言提供的API,完成鉴权拿到一个access_token,默认30天的有效期,学习中可以暂时用啦。

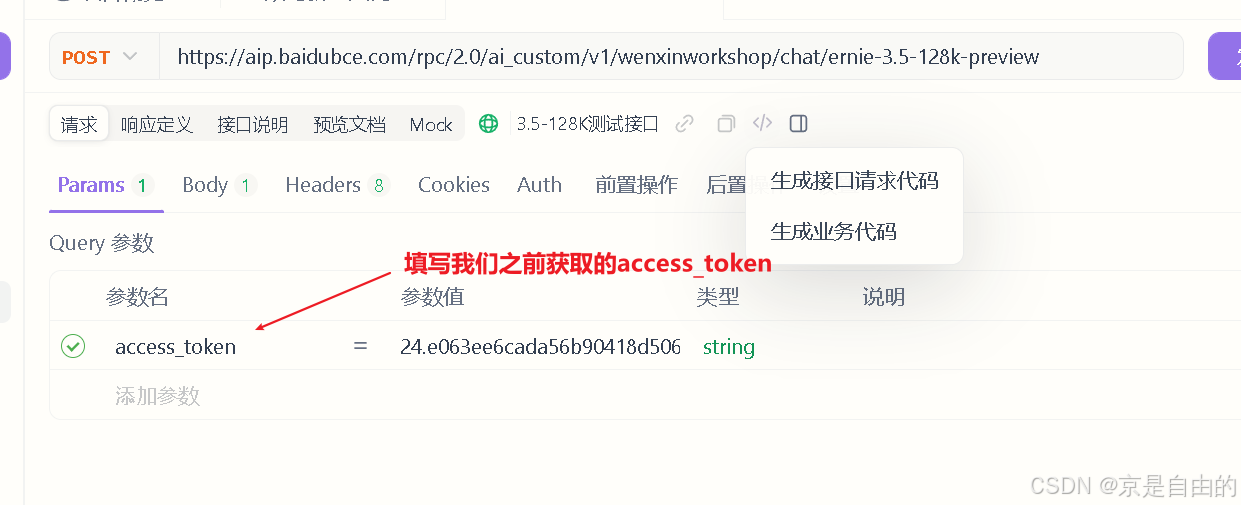
通过在线测试平台一键获取access_token,找个小本本记录下来,和上面一样,要保密。

3、小试牛刀:HTTP请求访问测试
先不硬编码,我们先用ApiFox来进行HTTP请求调用一下,看看好不好使,当然,用Postman也行,不过我觉得前者更好用一点。
按照之前提供的参考文档:
我们来完成示例请求
3.1 填写接口信息
此处用Postman的同学,Params的意思就是url+"?参数key:参数值那些",一个意思
url填写:https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie-3.5-128k-preview
方法是:Post
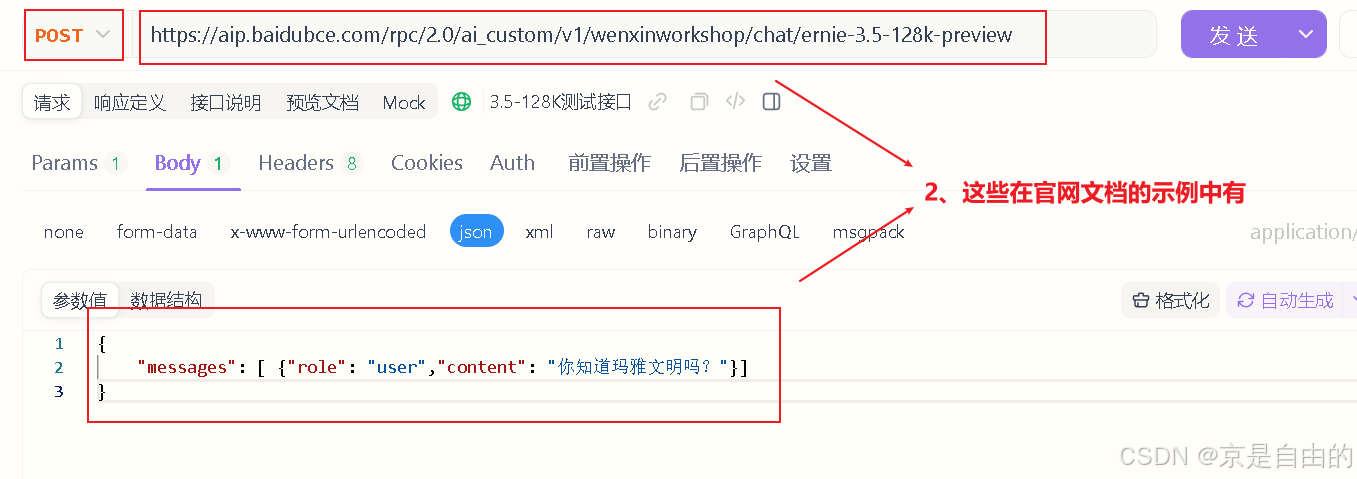
请求体:
{
"messages": [ {"role": "user","content": "你知道玛雅文明吗?"}]
}
3.2 发送请求,等待响应
由于是同步获取,所以速度有点慢,稍微等一会就好了(即它是一次性返回所有的回答的)
可以看到返回了一些我们想要的数据
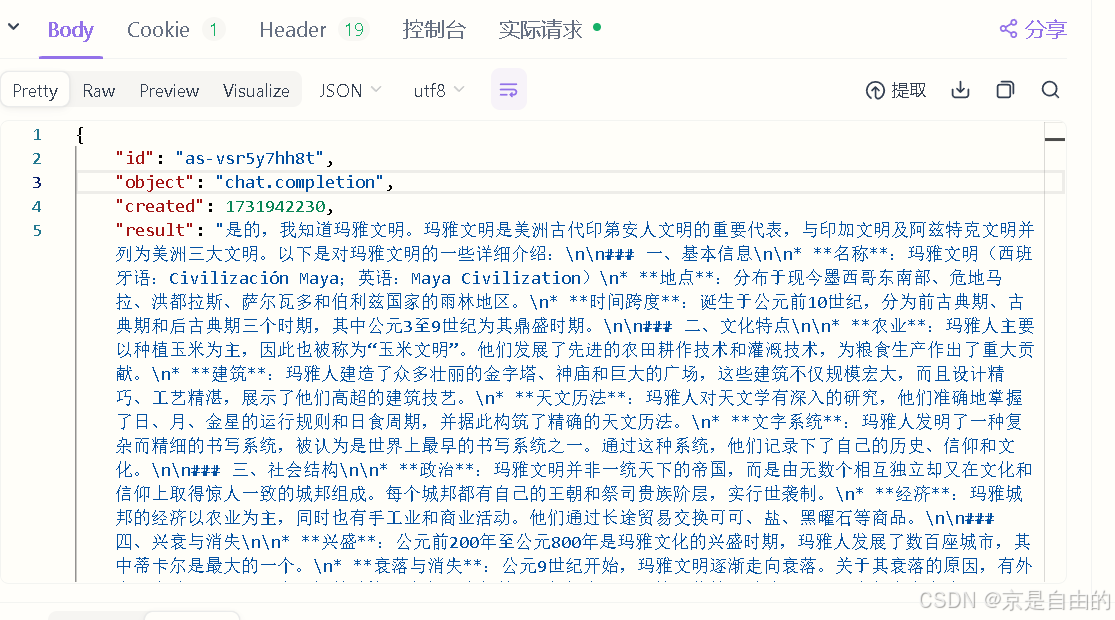
致辞,HTTP请求访问的方式完成。
4、使用Java代码来发起请求
4.1 配置yml以及编写源代码
通常,第三方库提供的HTTP请求包会更好用,这里我们使用OkHttp库,它更轻量,社区活跃度也更高。
使用Maven导入依赖
<!--OkHttp-->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.11.0</version>
</dependency>
<!-- 临时解析yaml的工具 -->
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
<version>2.0</version>
</dependency>编写代码,此处为了解耦合,我使用了yml来外部配置这些配置内容:
在resources目录下放入yml配置文件,名称:ai-config.yml
wenxin:
chat3.5-128k:
url: https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie-3.5-128k-preview
method: POST
headers:
Content-Type: application/json
params:
access_token: 24.e063ee6cada56b90418d50628f350883... # 不完整,填写自己的
编写代码:
//ConfigLoader
package com.ai.config;
import org.yaml.snakeyaml.Yaml;
import java.io.InputStream;
public class ConfigLoader {
public static WenxinConfig loadConfig() {
try (InputStream inputStream = ConfigLoader.class.getClassLoader().getResourceAsStream("ai-config.yml")) {
if (inputStream == null) {
throw new RuntimeException("配置文件未找到!");
}
Yaml yaml = new Yaml();
return yaml.loadAs(inputStream, WenxinConfig.class);
} catch (Exception e) {
throw new RuntimeException("加载配置文件失败", e);
}
}
public static void main(String[] args) {
WenxinConfig wenxinConfig = loadConfig();
}
}
// WenxinConfig
package com.ai.config;
import lombok.Data;
import java.util.Map;
@Data
public class WenxinConfig {
private Map<String, ChatConfig> wenxin;
@Data
public static class ChatConfig {
private String url;
private String method;
private Map<String, String> headers;
private Map<String, String> params;
}
}
// WenxinRequester
package com.ai;
import com.ai.config.ConfigLoader;
import com.ai.config.WenxinConfig;
import okhttp3.*;
import java.util.Map;
public class WenxinRequester {
public static void main(String[] args) {
// 加载配置
WenxinConfig config = ConfigLoader.loadConfig();
WenxinConfig.ChatConfig chatConfig = config.getWenxin().get("chat3.5-128k");
// 构造请求参数
String accessToken = chatConfig.getParams().get("access_token");
String urlWithParams = chatConfig.getUrl() + "?access_token=" + accessToken;
// 构造请求体
String jsonBody = "{ \"messages\": [ {\"role\": \"user\", \"content\": \"你知道玛雅文明吗?\"} ] }";
// 构造 OkHttp 请求
OkHttpClient client = new OkHttpClient();
RequestBody body = RequestBody.create(jsonBody, MediaType.parse("application/json"));
Request.Builder requestBuilder = new Request.Builder()
.url(urlWithParams)
.method(chatConfig.getMethod(), body);
// 添加 Headers
for (Map.Entry<String, String> entry : chatConfig.getHeaders().entrySet()) {
requestBuilder.addHeader(entry.getKey(), entry.getValue());
}
// 发送请求并处理响应
try (Response response = client.newCall(requestBuilder.build()).execute()) {
if (response.isSuccessful()) {
System.out.println("Response: " + response.body().string());
} else {
System.out.println("请求失败,状态码: " + response.code());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
4.2 运行出错与解决
运行一下,报错了,在预料之中

它是阻塞等待获取全部的消息后,才返回的,毕竟生成文本需要时间嘛
解决方案:
新增这四行代码即可:
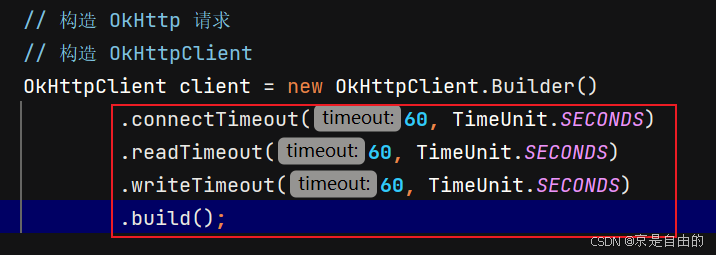
再次运行:可以看到消息已经成功接受了

5、扩展
至此,一个简单的调用API的过程就就结束了,当然,这里还留了很多问题待解决:
-
如何实现连续对话操作,就像我们使用大模型对话那样,能够结合上下文理解我们的意思?
-
如何定位用户,即每个用户都有自己的对话?
-
如何不同步阻塞?阻塞带来了哪些问题?能否实时完成对话的输出呢?
-
......
过两天继续完善吧,如果大家也有兴趣。
最后,一切有为法皆如梦幻泡影,如露亦如电。愿你不为世间事所困,开朗地应对生活这一课题吧。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









