









目录
论文发布于2019
1 BERT VS Transformer
1.1 图示
Transformer
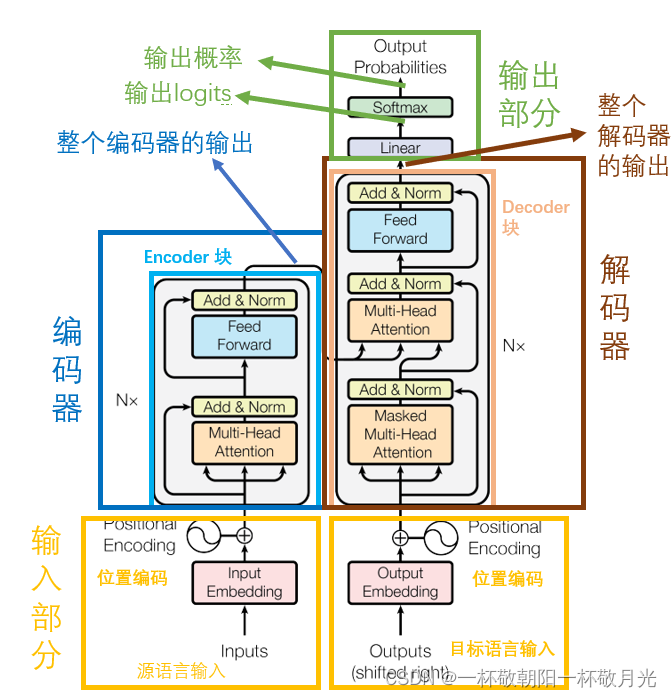
BERT
1.2 输入
Transformer: 位置 encoder + token embedding,在训练的时候 Transformer 有两个输入部分(对应于论文中的 源语言输入 和 目标语言输入)这两个输入是一起全部输入给模型的,预测的时候,源语言 的输入也是一下子给到模型,但是目标语言是一个一个给到的(自回归)。
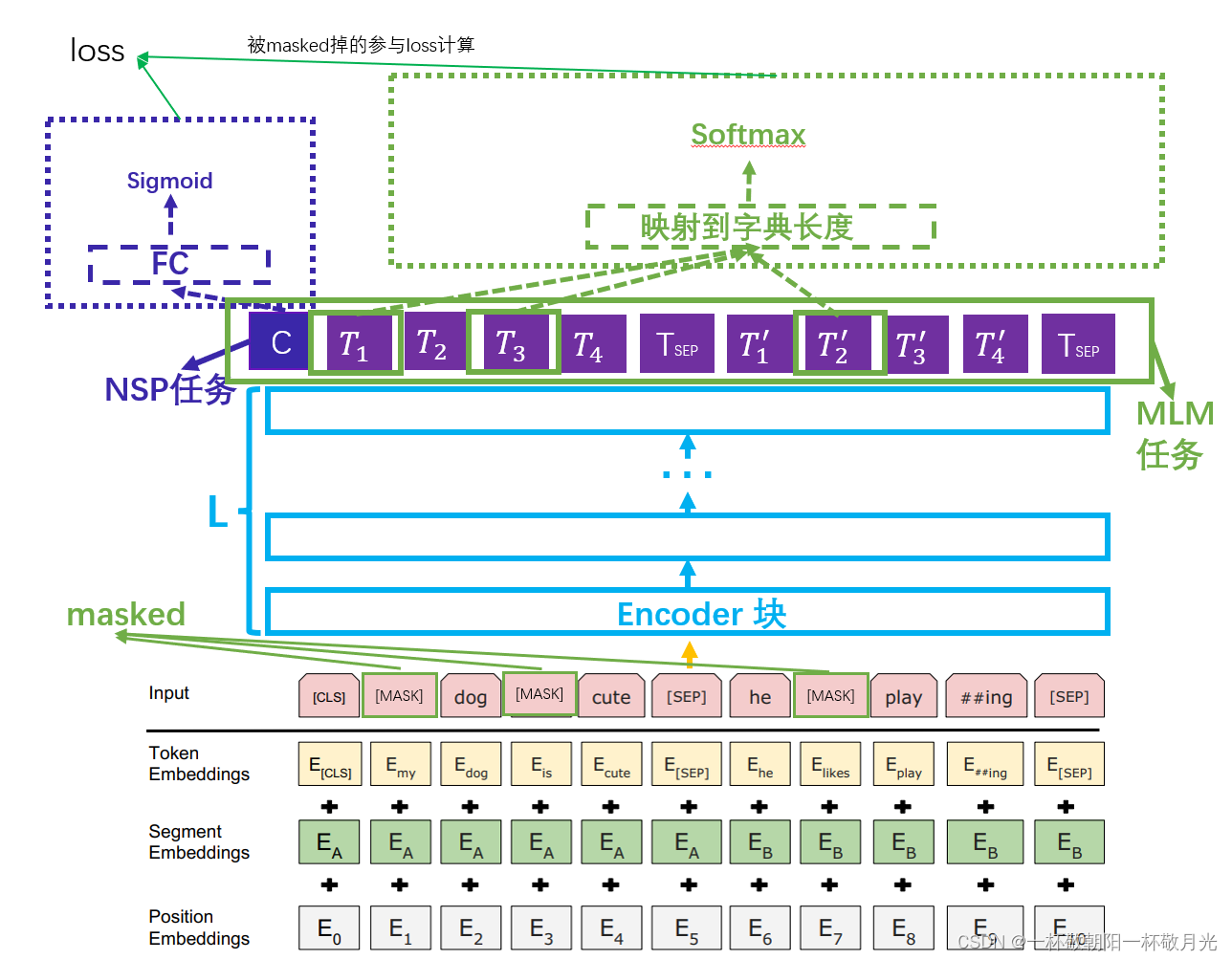
BERT:位置 embedding + token embedding + segment embedding 。其中 segment embedding 是因为 BERT 预训练有两个任务,其中有一个是预测后一个句子是否是前一个句子的下一句,这边 segment embedding 就是用来区分两个句子的 ,句子对之间放置一个 [SEP] 的 token 也是用来区分两个句子的。[CLS] 这个 token 的作用是为了我们可以用该 token 对应的一层输出来做分类任务(可以理解为该 token 对应的一层输出融合了整句话的表达)。位置 embedding 对应 Transformer 中的 位置 encoder 。
BERT 的输入可以是一个句子(此时的 segment Embedding均是一样的,如图中的 ),也可以是句子对 (此时的 segment Embedding 是两种,如图中的
)。关于输入的 token 无论是与训练阶段还是 fine-tuning 阶段,句子开始要放置一个 [CLS] ,句子末尾要放置一个 [SEP],若是句子对,句子之间放置一个 [SEP] 。
- 数据
- 预训练,无标签的数据集,BooksCorpus (800M words,8亿个单词)和 English Wikipedia (2,500M words , 25亿个单词,仅保留长文本,忽略 标题、表格、列表等,因为想要抽取连续的长文本信息)
- 下游任务,利用下游任务的数据(带标签)来 fine-tuning 【由预训练初始化的】 参数。
1.3 模型
Transformer:编码器 + 解码器架构,其中编码器是由6个相同的 Encoder 块组成的,解码器也是由6个相同的 Decoder 块组成的。
BERT:仅有 Transformer 中的 Encoder 块堆叠而成,不过诸如 堆叠的块数、隐藏层的单元数等超参不同,BERT的参数量更大。
参数量,L - Encoder 块的数目,H - embedding 的维度,A - multi-head 的个数。
, L = 12, H = 768,A = 12,共计 110M 约1.1亿个参数
, L = 24, H = 1024,A = 16,共计 340M 约3.4亿个参数
1.4 任务
Transformer : sequence to sequence ,原论文中主体部分是用于机器翻译,也可推广到其它序列到序列的任务,或用于其他场景的一个模块。
BERT:分为 预训练 和 用作下游任务 两个部分,用作下游任务的使用姿势多种多样,预训练好的BERT的参数作为下游任务该模块的参数的初始化,例如用最后一个 Encoder 块的输出、最后一个块的 #CLS# 的输出 或 多个 Encoder 块的输出 等后续接其它网络结构,例如情感分析,我们可以仅使用最后一个块的 #CLS# 的输出接一个全连接层,再接一个 sigmoid 激活函数。
1.4.1 BERT 预训练
Masked LM ( MLM ) 任务,以往的 NLP 场景多是用 conditional 语言模型,但是 BERT 使用的是 self-attention ,且是 编码器 部分的 self-attention ,即经过 L 个 Encoder 块后,我们所有的隐藏层都能看见 该位置对应的输入 token 前面、后面甚至该 token 本身的信息。所以此处用的是 MLM 任务,即 随机的 masked 掉部分的输入token ,然后损失函数也仅考虑被 masked 掉的 token 对应的输出和 label ( 该处若不被 masked 掉的原始值) 的交叉熵损失。
注1:损失函数也仅考虑被 masked 掉那部分的交叉熵损失,真正在实现的时候,我们可以将所有输出均映射到字典长度空间,再过 softmax ,然后一起来算损失,不过我们会在输入的时候做处理,其实编码器也是可以用来做 seq2seq 的,即它们的输入和输出在序列长度这个维度不会发生变化,则我们可以在做 label 的时候给没有被 masked 掉的那些 token 对应的 label 赋一个特殊的 token ,此处我们假设该特殊 token 对应的索引为 0 ,我们只要在计算损失的时候跳过 索引 为 0 的那部分 label 即可。
class BertForPreTraining(BertPreTrainedModel):
def __init__(self, config):
super(BertForPreTraining, self).__init__(config)
self.bert = BertModel(config)
self.cls = BertPreTrainingHeads(config,
self.bert.embeddings.word_embeddings.weight)
self.apply(self.init_bert_weights)
self.vocab_size = config.vocab_size
self.next_loss_func = CrossEntropyLoss()
self.mlm_loss_func = CrossEntropyLoss(ignore_index=0)
def forward(self, input_ids, positional_enc, token_type_ids=None,
attention_mask=None, masked_lm_labels=None, next_sentence_label=None):
sequence_output, pooled_output = self.bert(input_ids, positional_enc,
token_type_ids, attention_mask,output_all_encoded_layers=False)
# 全都送进loss,然后在loss中实现只计算被masked掉的那部分的逻辑
# sequence_output: 预训练是最后一个 encoder 块的输出
# pooled_output:pooled_output为隐藏层中[CLS]对应的token的一条向量
mlm_preds, next_sen_preds = self.cls(sequence_output, pooled_output)
return mlm_preds, next_sen_preds
def compute_loss(self, predictions, labels, num_class=2, ignore_index=-100):
# 这边调用的时候ignore_index 传0即可
loss_func = CrossEntropyLoss(ignore_index=ignore_index)
return loss_func(predictions.view(-1, num_class), labels.view(-1))
class BertPreTrainingHeads(nn.Module):
"""
BERT的训练中通过隐藏层输出Masked LM的预测和Next Sentence的预测
"""
def __init__(self, config, bert_model_embedding_weights):
super(BertPreTrainingHeads, self).__init__()
# 把transformer block输出的[batch_size, seq_len, embed_dim]
# 映射为[batch_size, seq_len, vocab_size]
# 用来进行MaskedLM的预测
self.predictions = BertLMPredictionHead(config, bert_model_embedding_weights)
# 用来把pooled_output也就是对应#CLS#的那一条向量映射为2分类
# 用来进行Next Sentence的预测
self.seq_relationship = nn.Linear(config.hidden_size, 2)
def forward(self, sequence_output, pooled_output):
# 预训练只取最后一层
prediction_scores = self.predictions(sequence_output)
seq_relationship_score = self.seq_relationship(pooled_output)
return prediction_scores, seq_relationship_score注2: 随机 masked 掉15%的 token ,若仅仅将 masked 的 token 替换为 [MASK] ,则会造成预训练和 fine-tuning 的不匹配,因为下游任务中不出现 [MASK] 。所以随机 masked 的过程为
- 先对每个 token 以15%的概率进行 masked ,若该 token 未被 masked ,则不参与最终的损失计算,我们通过将其 label 的 index 设置为0,并在调用交叉熵损失的时候给 ignore_index 传0来实现。一旦一个 token 被选中,则该 token 参与损失计算,将对应的 label 设置为该token ,则该输入 token 如下:
- 以80%的概率将该 token 替换为 [MASK]
- 以10%的概率随机选择一个 token
- 剩下10%的概率维持原样
我们的目的是还原被 masked 掉的 token ,至于为啥还有10%的几率不变,因为不这么做的话,意味着模型的输出应该永远不等于输入,这是不对的。
def random_char(self, sentence):
char_tokens_ = list(sentence)
# 拿到句子文本的索引表示
char_tokens = self.tokenize_char(char_tokens_)
output_label = []
for i, token in enumerate(char_tokens):
prob = random.random()
# 30% 的概率进行选中该token进行 MLM,需要计算loss
if prob < 0.30:
prob /= 0.30
# 被选中,则需要计算loss
output_label.append(char_tokens[i])
# 80% randomly change token to mask token
if prob < 0.8:
# 选中该token的情况下,80%的概率输入进行masked
char_tokens[i] = self.mask_index
# 10% randomly change token to random token
elif prob < 0.9:
# 选中该token的情况下,10%的概率随机选择一个token做输入
char_tokens[i] = random.randrange(len(self.word2idx))
# else:
# 选中该token的情况下,10%的概率输入不变,这一块无需写出来
# char_tokens[i] = char_tokens[i]
else: # 70%的概率不选中该token进行MLM,所以无须计算loss
output_label.append(0)
return char_tokens, output_labelNext Sentence Prediction( NSP )任务。很多下游任务需要理解句子之间的关系,但是这种关系无法被语言模型捕获。为了建模这种关系,预训练了一个二分类任务,预测句子对中后面一句是否是前面一句的下一句。训练数据,以50%的概率将句子 A 的下一句作为句子 B , label 是 IsNext ;剩下的50%的概率从语料库中随机选择一句作为句子 B , label 是 NotNext 。论文里证明了该任务的添加有助于 QA 【问答(Question answer, QA),它可以近似为排名候选答案的句子或短语,基于其相似性的原始问题(Yang et al., 2015)】任务 和 NLI 【自然语言推理(NLI),也被称为识别文本蕴涵(RTE),它关注一个假设是否可以从一个前提中推断出来,需要理解假设和前提之间的语义相似性(Dagan et al., 2006;Bowman等人,2015)】任务。
1.5 附录待续
参考:
https://arxiv.org/pdf/1810.04805.pdf
GitHub - aespresso/a_journey_into_math_of_ml: 汉语自然语言处理视频教程-开源学习资料















 853
853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









