







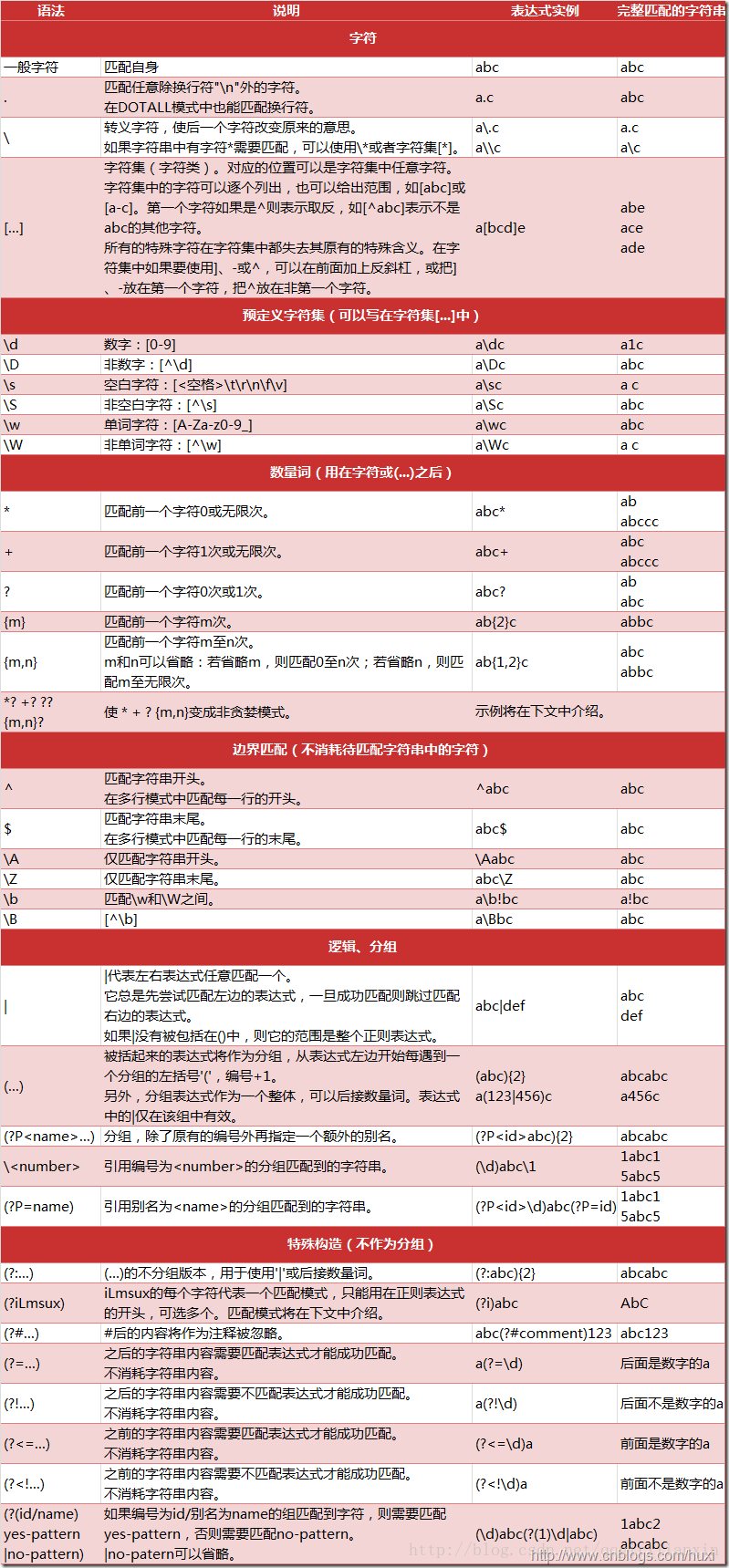
1. 正则表达式语法
2. 常用的正则表达式处理函数
re.match尝试从字符串的开始匹配一个模式
import re
text = "Elaine is a beautiful girl, she is cool,clever, and so on..."
#match从字符串的开始匹配一个模式
m = re.match(r"(\w+)\s",text)
if m:
print m.group()
else:
print 'not match're.search 从字符串的任一位置去匹配一个模式
re.match("c","abcdef") # No Match
re.search("c", "abcdef") # Matchre.sub 替换字符串中的匹配项
re.sub(r'\s+','-',string)
#将string串中的空格替换成"-"re.split 分割字符串
#将字符串按空格分割成一个单词列表
re.split(r'\s+',text)re.findall 获取字符串中所有匹配的串
#匹配所有包含o的单词
re.findall(r’\w*o\w*',text)>>>['cool', 'so', 'on']
re.complie 把正则表达式编译成一个正则表达式对象,可以复用该正则表达式
import re
text = "Elaine is a beautiful girl, she is cool,clever, and so on..."
pattern = re.compile(r'\w*o\w*')
newstring = lambda m: '[' + m.group(0) + ']'
print pattern.findall(text)
print pattern.sub(newstring, text)
#将单词中包含o的用“[]"括起来4. 正则表达式实例
实例1.
teststr1 = "800-123-4234"pattern1 = re.compile(r'^\d{3}-\d{3}-\d{4}$')print pattern1.findall(teststr1)
实例2.
teststr2 = "email: elaine@163.com, email: xx_xx@sina.org"pattern2 = re.compile(r"\w+:\s+\w+@\w+\.(?:org|com|net)") #()中的?:表示括号内的内容不做为分组print pattern2.findall(teststr2)
实例3.
teststring=["HELLO world","hello world!","hello world"]
expressions = ["hello","HELLO"]
for string in teststring:
for expression in expressions:
if re.search(expression,string):
print expression , "found in string" ,string
else:
print expression , "not found in string" ,string















 2579
2579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









