







 本文介绍了如何使用Selenium配合Java处理企查查的滑块验证、图片验证码和数字验证码,成功登录后抓取企业详情、人物图谱和投资图谱等数据。通过打码平台解决验证码难题,并分享了登录验证和数据抓取的思路。
本文介绍了如何使用Selenium配合Java处理企查查的滑块验证、图片验证码和数字验证码,成功登录后抓取企业详情、人物图谱和投资图谱等数据。通过打码平台解决验证码难题,并分享了登录验证和数据抓取的思路。
最近工作上需要一些企业的详细的数据,工商信息啦,基本信息啦,还有一些关系图(投资关系、人物图谱)之类的,然后我来负责从企查查上弄些数据。
强调:下面只是快速实现数据抓取的思路,没有详细的代码,同时也拒绝伸手党。
现实中,一些工商信息网站会被无数的爬虫“骚扰”,所以网站的反爬虫策略也是越来越高,就拿企查查来说,基本的信息是直接可访问的,但是像人物图谱和企业图谱这些内容还是需要登录的,
特别是人物图谱,非VIP会员,一天也只能看两次

企查查的登录也是做了很多限制
比如图片验证码啊,数字验证码啊,还有验证码异常出现刷新按钮啊等等(之前在做的过程中发现的没有及时截图)

但是有了selenium这些都不是问题~接下来按照如下思维导图做一个抓取的分析(代码想了许久还是不贴出来了)

登录
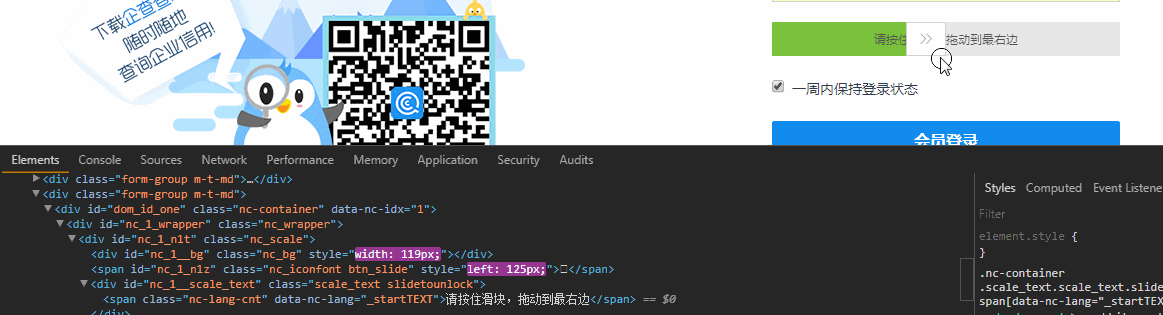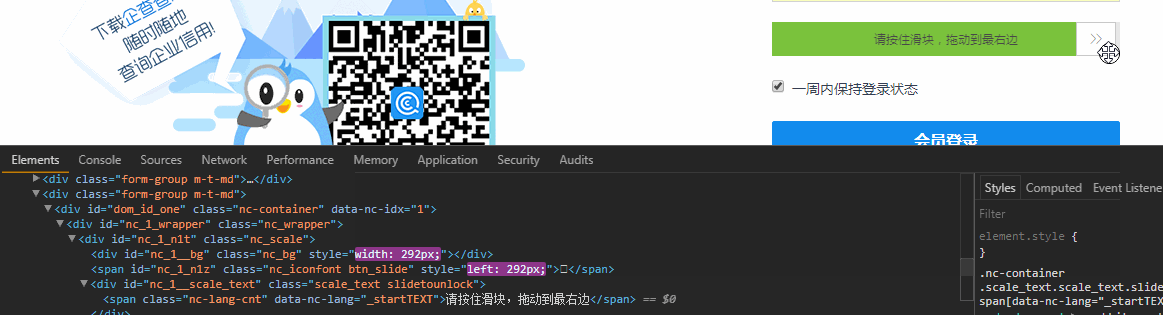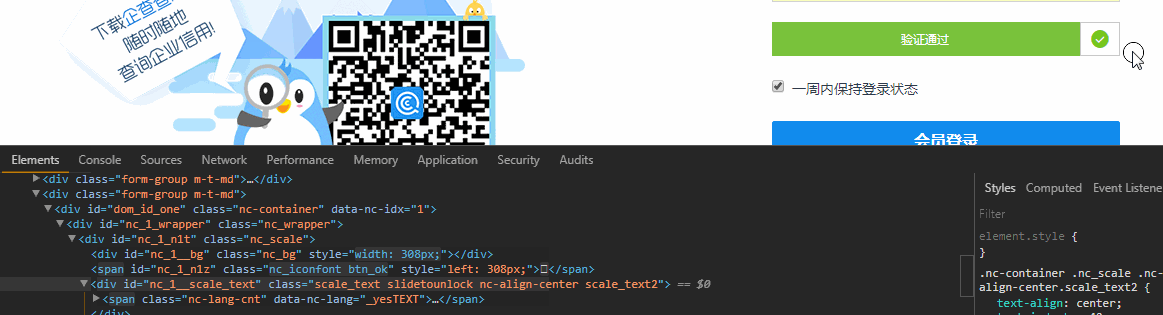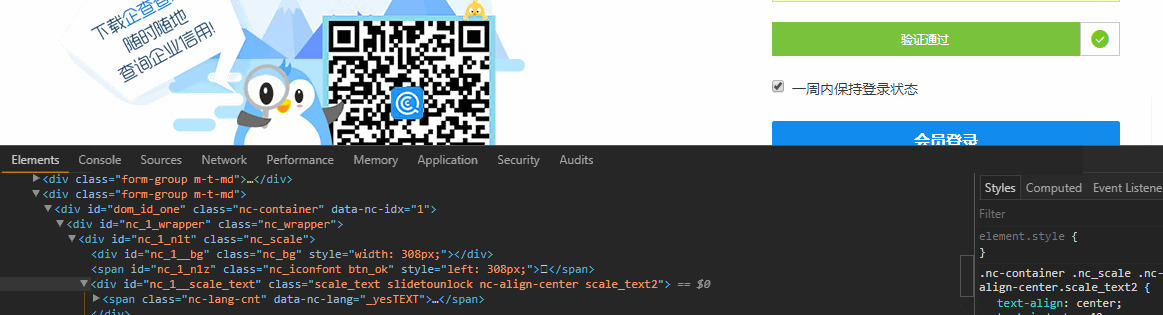
滑块验证
首先出场的是滑块验证,这个可以使用Selenium中的Actions.clickAndHold()来破防,打开浏览器Element面板,边滑动滑块边观察Html
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3944
3944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}