







 本文介绍了如何使用selenium进行网页模拟登录企查查,包括设置chrome选项、处理滑块验证,以及展示完整爬虫代码,以获取企业的详细信息链接。
本文介绍了如何使用selenium进行网页模拟登录企查查,包括设置chrome选项、处理滑块验证,以及展示完整爬虫代码,以获取企业的详细信息链接。
对于爬虫,现在网上的教程也越来越多,方法也是五花八门,甚至出现了APP等爬虫软件。
下面我们将爬取著名的企查查
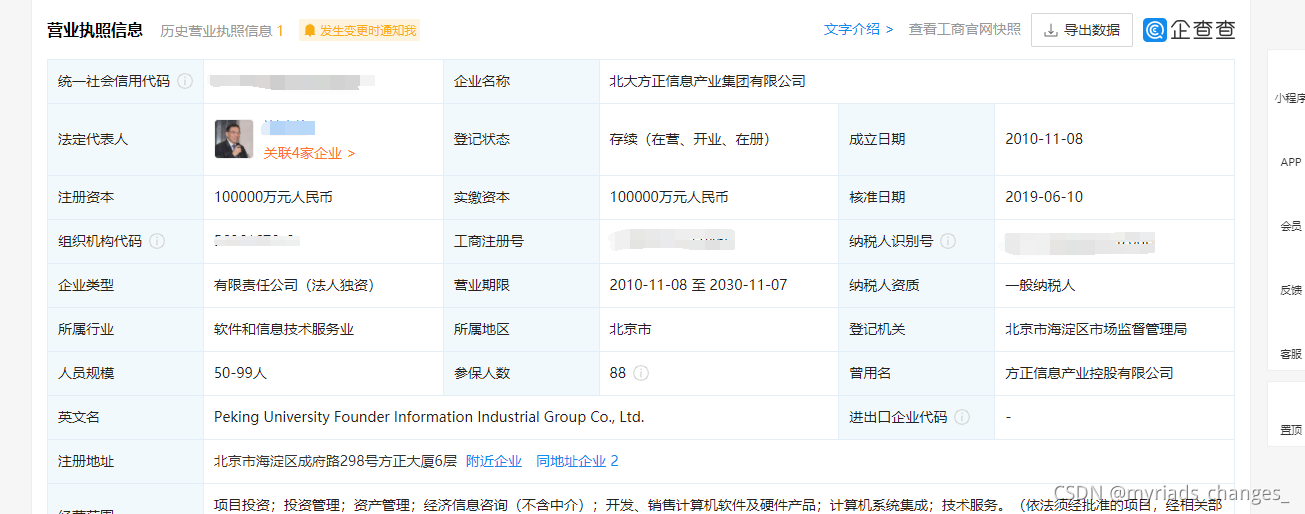
对于企查查网,我们需要做一些营业执照等信息的话,就需要公司的具体信息,例如公司名称,法定代表人,成立日期,注册金额等基础信息,如下图。
本文最最最要:
def main():
while True:
option = webdriver.ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation']) # webdriver防检测
option.add_argument("--disable-blink-features=AutomationControlled")
option.add_argument("--no-sandbox")
option.add_argument("--disable-dev-usage")
option.add_experimental_option("prefs", {
"profile.managed_default_content_settings.images": 2})
driver = webdriver.Chrome(executable_path=r'D:\chromedriver.exe',options=option)
设置参数如下:
- ChromeOptions:是一个配置 chrome 启动是属性的类,就是初始化
- binary_location:设置 chrome 二进制文件位置
- add_argument:添加启动参数
- add_extension、add_encoded_extension:添加扩展应用
- add_experimental_option:添加实验性质的设置参数
- debugger_address:设置调试器地址
下载chromedriver.exe驱动
根据你的谷歌浏览器的版本下载chromedriver,注意这里我们下载的版本要与自己的谷歌浏览器的版本相对应,再引入他的路径

点击事件
针对事件点击的话,这个就需要定位到你要模拟点击的标签,不然会报错,或者找不到。
注意:
- 反应等待时间设置,不然再下一个事件点击之前,定位不了。
- 标签精准定位
driver.delete_all_cookies()
url = "https://www.qcc.com/weblogin?back=%2F" #https://www.qcc.com/weblogin?back=%2F
driver.get(url)
time.sleep(10 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3264
3264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









