







1.1MySQL服务器逻辑架构
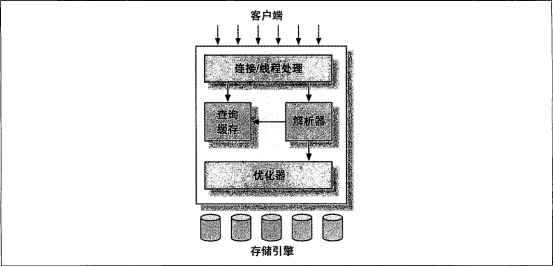
- 最上层的服务并不是MySQL所独有的,大多数基于网络的客户端/服务器的工具或者服务都有类似的架构。比如连接处理、授权认证、安全等等。
- 第二层架构是MySQL比较有意思的部分。大多数MySQL的核心服务功能都在这一层,包括查询解析、分析、优化、缓存以及所有的内置函数(例如,日期、时间、数学和加密函数),所有跨存储引擎的功能都在这一层实现:存储过程、触发器、视图等。
- 第三层包含了存储引擎。存储引擎负责MySQL中数据的存储和提取。每个存储引擎都有它的优势和劣势。存储引擎API包含了几十个底层函数,但存储引擎不会去解析SQL(注释:InnoDB是一个例外,它会解析外键定义,因为MySQL服务器本身没有实现该功能,这也是MyISAM和InnoDB不同处之一),不同存储引擎之间也不会相互通信,而只是简单地响应上层服务器的请求。
1.1.1连接管理与安全性
- 每个客户端连接都会在服务器进程中拥有一个线程,这个连接的查询只会在这个单独的线程中执行
- MySQL5.5之后提供线程池插件
1.1.2优化与执行
- MySQL会解析查询,并创建内部数据结构(解析树),然后对其进行各种优化,包括重写查询、决定表的读取顺序,以及选择合适的索引等。(第6章详细讨论)
- 对于SELECT语句,在解析查询之前,服务器会先检查查询缓存(Query Cache),如果能够在其中找到对应的查询,服务器就不必再执行查询解析、优化和执行的整个过程,而是直接返回查询缓存中的结果集。(第7章详细讨论)
- 存储引擎对于优化查询是有影响的。
1.2并发控制
分为服务器层和存储引擎层的并发控制,读写锁和并发锁。
- 一种提高共享资源并发性的方式就是让锁定对象更有选择性。最理想的方式是,只对会修改的数据片进行精确的锁定。在不发生冲突的情况下,锁定的数据量越小,则系统并发程度越高。
- 锁策略:就是在锁的开销和数据的安全性之间寻求平衡,这种平衡当然也会影响到性能。
- 表锁(table lock):表锁是MySQL中最基本的锁策略,并且是开销最小的策略。
- 行级锁(row lock):行级锁最大程度地支持并发处理(同时也带来了最大的锁开销)。行级锁只在存储引擎层实现,而MySQL服务器层没有实现。
1.3事务
- 理论上,RR级别(MySQL默认隔离级别)是没有解决幻读问题的,但是InnoDB和XtraDB通过多版本并发控制(MVCC)解决了幻读问题。
- 数据库系统实现了各种死锁检测和死锁超时机制。InnoDB处理死锁的方法是,将持有最少行级排他锁的事务进行回滚(相对比较简单的死锁回滚算法)。
事务日志
- 事务日志可以帮助提高事务的效率。使用事务日志,存储引擎在修改表的数据时只需要修改其内存拷贝,再把该修改行为记录到持久在硬盘中的事务日志中,而不用每次都将修改的数据本身持久到硬盘。事务日志持久以后,内存中被修改的数据在后台可以慢慢地刷回磁盘(异步的)。目前大多数存储引擎都是这样实现的,通常称之为预写式日志(Write-Ahead Logging),修改数据需要写两次磁盘。
- 如果数据的修改已经记录到事务日志并持久化,但数据本身还没有写回磁盘,此时系统崩溃,存储引擎在重启时能够自动恢复这部分修改的数据(redo日志)。具体的恢复方式则视存储引擎而定。
AUTOCOMMIT
http://www.cnblogs.com/wingsless/p/6803542.html
autocommit默认是开启的,所以当我们不显示的开启事务时,单个查询语句(只是针对查询么?)结束后会自动执行commit。如果把该选项关闭,那么所有的查询都会在一个事务中,直到显示提交或回滚,所以根据InnoDB里的MVCC,可以做到可重复读。可以用SHOW VARIABLES LIKE "AUTOCOMMIT"查看自动提交模式的状态。
InnoDB采用的是两阶段锁定协议(two-phase locking protocol)。在事务执行过程中,随时都可以执行锁定,锁只有在执行COMMIT或ROLLBACK时才会释放,并且所有的锁是在同一时刻释放。InnoDB会根据隔离级别在需要时自动加锁。
显示加锁就是指在SELECT语句中,加上for update 或 lock in share mode(之前说的锁都是隐式锁)
1.4 多版本并发控制
- MVCC可以认为是行级锁的一个变种,但它在很多情况下避免了加锁操作,因此开销更低。
- MVCC的实现,是通过保存数据在某个时间点的快照来实现的。避免了事务开始的时间不同,而看到不同的数据。
- InnoDB的MVCC是通过在每行记录后面保存两个隐藏的列来实现的。这两列,一列保存了行的创建时间,一个保存了行的过期时间(或删除时间),其实使用的是系统版本号。
- 通过获取适当的版本号的内容来操作数据,保证数据时间上的一致性。对于SELECT操作,选择的数据,创建时间早于或等于当前事务版本的数据号,删除版本要么未定义,要么大于当前事务版本号。
- MVCC只在REPEATABLE READ和READ COMMIT两个隔离级别下工作。其它两个都和MVCC不兼容,因为READ UNCOMMIT总是读取最新的数据行,而不是符合当前事务版本的数据行;而SERIALIZABLE则会对所有读取的行都加锁。
1.5 InnoDB存储引擎
- InnoDB采用MVCC来支持高并发,并且实现了四个标准的隔离级别。其默认级别是可重复读(REPEATABLE READ),并且通过间隙锁(next-key locking)策略防止幻读的出现。间隙锁使得InnoDB不仅仅锁定查询涉及的行,还会对索引中的间隙进行锁定,以防止幻行的插入。
- InnoDB表是基于聚簇索引简历的,InnoDB的索引结构和MySQL的其它存储引擎有很大的不同,聚簇索引对主键查询有很高的性能。不过它的二级索引(secondary index,非主键索引)中必须包含主键列,所以如果主键列很大的话,其它的所有索引都会很大。因此,若表上的索引较多的话,主键应当尽可能的小。
具体一些场景可以看这里。
http://blog.csdn.net/qqqqq1993qqqqq/article/details/75449094
http://blog.csdn.net/qqqqq1993qqqqq/article/details/75519303
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









