









前面两篇文章分别介绍了 Request 与 Respone ,了解知道了HTTP请求与响应的大致结构以及所需的信息。那 Request 与 Respone 之间是如何通过网络进行交互的呢,这时候就需要Client与Server来协助与处理了,此篇文章重点介绍Client部分。
Client这里顾名思义就是HTTP客户端,用于发送HTTP请求( Request ) 并获得响应Respone。
下面我们来详细介绍下在Go语言的net/http包中,Client是如何被定义以及使用的。
Client结构体
Go语言中的http.Client结构体是用于发送HTTP请求并返回响应的组件。它的定义如下:
type Client struct {
Transport RoundTripper
CheckRedirect func(req *Request, via []*Request) error
Jar CookieJar
Timeout time.Duration
}
下面对各个字段进行分别说明:
-
Transport
一个
http.RoundTripper接口类型的对象,只包含一个方法RoundTrip,它接受一个*http.Request类型的参数,表示HTTP请求,返回一个*http.Response类型的响应和一个错误对象,该方法的作用是发送HTTP请求并返回响应,同时处理可能出现的传输错误,如超时、连接错误、重定向等。http.RoundTripper的默认实现是http.Transport,该实现使用TCP连接池,支持HTTP/1.1、HTTP/2协议,同时还支持HTTPS、代理、压缩和连接复用等特性。如果需要更灵活地控制HTTP请求的传输过程,可以自定义实现http.RoundTripper接口,并将其传递给http.Client的Transport字段。 -
CheckRedirect
一个函数类型,用于控制
HTTP重定向。默认情况下,http.DefaultCheckRedirect允许自动跟随HTTP重定向。 -
Jar
一个
http.CookieJar接口类型的对象,用于管理HTTP cookie。默认情况下,http.DefaultCookieJar使用net/http/cookiejar包中的默认cookie实现。 -
Timeout
一个
time.Duration类型的对象,用于控制HTTP请求的超时时间。默认情况下,如果该字段没有设置超时时间,即无限期等待响应。
创建一个 Client也很简单,最简单的创建如下:
Client := &http.Client{}
一行代码搞定,当然也可以带上你自己所需要的参数来创建Client,比如使用http.Client的 Timeout字段创建一个有超时时间的客户端:
Client := &http.Client{
Timeout: 15 * time.Second,
}
有一些更细粒度的超时控制:
Client := &http.Client{
Transport: &Transport{
Dial: (&net.Dialer{
Timeout: 30 * time.Second,
KeepAlive: 30 * time.Second,
}).Dial,
TLSHandshakeTimeout: 10 * time.Second,
ResponseHeaderTimeout: 10 * time.Second,
ExpectContinueTimeout: 1 * time.Second,
}
}
代码当中一些参数,下面列出解释以便理解:
- net.Dialer.Timeout 限制建立
TCP连接的时间 - http.Transport.TLSHandshakeTimeout 限制
TLS握手的时间 - http.Transport.ResponseHeaderTimeout 限制读取
response header的时间 - http.Transport.ExpectContinueTimeout 限制
client在发送包含Expect: 100-continue的header到收到继续发送body的response之间的时间等待
Client 使用
标准请求
使用 http.Client进行发送HTTP请求以及返回响应,基本流程如下:
- 创建
http.Client对象。首先,我们需要创建一个http.Client对象。可以通过http.DefaultClient使用默认的HTTP客户端,也可以通过手动创建一个新的http.Client对象,以便自定义其参数。 - 创建
HTTP请求。有了http.Client对象后,我们需要创建一个HTTP请求。在Request章节中,我们讲述到http.NewRequest函数,我们可以通过该函数创建一个新的请求对象,并设置请求URL、方法、请求体等参数。 - 发送
HTTP请求。有了请求对象后,将请求对象传递给http.Client的Do方法,以便发送HTTP请求。Do方法返回一个响应对象,其中包含服务器的响应信息,如状态码、响应头和响应体等。 - 处理
HTTP响应。我们可以使用响应对象中的方法和属性,如resp.StatusCode、resp.Header、resp.Body等,处理服务器的响应。通常,我们需要读取响应体的内容,并将其解析为合适的数据类型,如JSON或XML。 - 关闭
HTTP响应。获取响应后,我们需要确保关闭HTTP响应的主体。可以使用defer resp.Body.Close()语句在函数退出时自动关闭响应体,以避免内存泄漏。
以下是一个简单的示例代码,演示了使用http.Client发送HTTP GET请求的基本流程:
package main
import (
"fmt"
"net/http"
"io/ioutil"
)
func main() {
// 创建http.Client对象
client := &http.Client{}
// 创建HTTP请求
req, err := http.NewRequest("GET", "http://example.com", nil)
if err != nil {
panic(err)
}
// 发送HTTP请求
resp, err := client.Do(req)
if err != nil {
panic(err)
}
// 处理HTTP响应
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
panic(err)
}
fmt.Println(string(body))
}
上述代码仅仅是以HTTP GET请求为例子作说明重点是突出请求的标准步骤,更多灵活的组合操作马上进行讲解。
自定义Client
一般情况下,我们并不需要自定义http.Client来控制控制HTTP请求的行为和配置,使用net/http包中默认的 http.DefaultClient 即可,http.DefaultClient 在 client.go 文件中是这样定义的:
var DefaultClient = &Client{}
可以看出默认的http.DefaultClient并没有设置Client任何属性值,但是如果我们需要设置HTTP请求的超时时间、代理、连接池等选项,可能就需要我们自己去定义和创建http.Client了。
根据Client结构体内容,我们知道http.Client拥有 Transport、CheckRedirect、 Jar、Timeout 四个属性字段,详细介绍如下:
-
Timeout
它用于设置
HTTP客户端的超时时间,是一个time.Duration类型的值,表示客户端在发送请求后等待服务器响应的最大时间。如果在这个时间内服务器没有响应,客户端会放弃请求并返回一个错误。这个超时时间是一个全局的设置,对于所有的HTTP请求都生效。默认情况下,
http.Client.Timeout的值是零,表示没有超时限制。下面是创建一个10秒超时时间的客户端示例:client := &http.Client{ Timeout: 10 * time.Second, } -
Jar
它是一个
http.CookieJar接口类型的值,表示HTTP客户端使用的cookie容器。这个容器会自动存储服务器发送给客户端的cookie,并在后续的HTTP请求中自动发送这些cookie给服务器。默认情况下,
http.Client.Jar是空的,这意味着HTTP客户端不会发送任何cookie给服务器。可以创建一个自定义的
cookie容器,并将其赋值给http.Client.Jar属性,例如:jar, err := cookiejar.New(nil) if err != nil { // handle error } client := &http.Client{ Jar: jar, } -
CheckRedirect
它是一个可选的回调函数,用于在
HTTP客户端进行重定向时决定是否要遵循该重定向。默认情况下,如果不设置
CheckRedirect函数,HTTP客户端会遵循所有的重定向。对于http.Get和http.Head等高级别的 HTTP 请求函数,它们默认使用一个简单的CheckRedirect函数,该函数会在重定向次数超过10次时返回一个http.ErrUseLastResponse错误。可以通过自定义
http.Client的CheckRedirect函数来控制HTTP客户端的重定向行为。下面是一个简单的例子:func CheckRedirect(eq *http.Request, via []*http.Request) error { if len(via) >= 2 { return fmt.Errorf("too many redirects") } return nil } func main() { client := &http.Client{ CheckRedirect: CheckRedirect, } }上述代码重新定义了重定向函数,设定了只允许重定向2次以免出现重定向循环。
-
Transport
它表示了
http.Client使用的网络传输层。默认情况下,http.Client使用的是http.DefaultTransport,它是一个基于TCP的传输层。http.Client.Transport是一个接口类型,它定义了如下两个方法:RoundTrip(req *Request) (*Response, error):执行一个 HTTP 请求并返回响应结果或者错误。CancelRequest(req *Request):取消一个正在执行的请求
如果你需要创建自己的传输层,你需要实现
http.RoundTripper接口。这个接口只有一个方法:RoundTrip(req *Request) (*Response, error):执行一个 HTTP 请求并返回响应结果或者错误。
解释完
http.Client得几个属性后,我们通过下面几个例子来了解和理解如何进行自定义http.Client:-
通过
Transport字段自定义传输层transport := &http.Transport{ Proxy: http.ProxyFromEnvironment, TLSClientConfig: &tls.Config{ InsecureSkipVerify: true, }, } client := &http.Client{ Transport: transport, } resp, err := client.Get("https://example.com")上述代码自定义一个使用了代理服务器和自签名证书的的传输层。
-
通过自定义函数来进行重新制定重定向规则
func userCheckRedirect(req *http.Request, via []*http.Request) error { //只能执行3次重定向 if len(via) >= 3 { return errors.New("stopped after 3 redirects") } return nil } client := &http.Client{ CheckRedirect: userCheckRedirect, }通过自定义函数
userCheckRedirect来控制重定向次数最多为3次,防止无限循环。如果不进行自定义函数,则默认重定向次数为10次。
例子就简单举这几个把,完成了 http.Client自定义,下面我们再看看 http.Request的自定义。
自定义Request
相当于 http.Client 来说,http.Request的自定义使用频率更高,更为普遍。
http.Request它包含了请求的方法、URL、Header 以及 Body 等信息。我们可以创建一个 http.Request 对象并设置它的http.Request.Header 、 http.Request.Body 、 http.Request.URL等属性。
在 net/http(一)--Request章节中讲到过,创建一个新的 http.Request, 使用的是 http.NewRequest 函数,下面将以代码示例形式讲述各种场景的自定义Request创建:
-
自定义请求
Header:req, err := http.NewRequest("GET", "https://www.example.com", nil) if err != nil { log.Fatal(err) } req.Header.Set("Accept", "application/json") req.Header.Set("Authorization", "Bearer my-token")从上代码可以看出可以使用
Request.Header.Set方法来创建请求头。 -
自定义参数:
query := url.Values{} query.Add("q", "golang") query.Add("page", "1") url := &url.URL{ Scheme: "https", Host: "www.example.com", Path: "/search", RawQuery: query.Encode(), } req, err := http.NewRequest("GET", url.String(), nil) if err != nil { log.Fatal(err) }通过 对
url.Values类型数据的添加,并在最后进行Encode()处理后赋值给url.URL.RawQuery字段,这样就可以完成URL参数的添加。 -
自定义
Basic认证:req, err := http.NewRequest("GET", "https://www.example.com", nil) if err != nil { log.Fatal(err) } username := "my-username" password := "my-password" auth := username + ":" + password base64Encoded := base64.StdEncoding.EncodeToString([]byte(auth)) req.Header.Set("Authorization", "Basic "+base64Encoded)Basic认证是比较常见的API调用认证,此处是通过设置请求头的Authorization完成设置。 -
使用 Cookie :
// Create a cookie cookie := &http.Cookie{ Name: "session_id", Value: "my-session-id", } // Create the request url := "https://www.example.com/api/v1" req, err := http.NewRequest("GET", url, nil) if err != nil { log.Fatal(err) } req.AddCookie(cookie)Cookie 在 HTTP 请求中属实常见,代码中通过
Request.AddCookie方法来设置cookie。 -
发送POST表单数据:
url := "https://www.example.com/api/v1/posts" params := []string{"xjx", "zzz"} req, err := http.NewRequest("POST", url, nil) if err != nil { log.Fatal(err) } data := url.Values{} data.Set("title", title) data.Set("content", content) for _, tag := range params { data.Add("tags", tag) } req.Header.Set("Content-Type", "application/x-www-form-urlencoded") req.Body = ioutil.NopCloser(strings.NewReader(data.Encode()))POST表单数据一般通过设置请求体来发送,而请求体(
Request Body)的数据设置一般跟 请求头的Content-Type值相关。下面列举常见的
Content-Type构造请求体例子:-
application/x-www-form-urlencoded
该类型
Request Body数据一般跟 自定义参数类型,通过将需要发送的表单数据通过url.Values格式添加并Encode进行加编码,不同的是最后需要转化为*Reader对象。示例:
url := "http://www.example.com" contentType := "application/x-www-form-urlencoded" data := "key1=value1&key2=value2" requestBody := strings.NewReader(data) req, _ := http.NewRequest("POST", url, requestBody) req.Header.Set("Content-Type", contentType)也可以
url := "http://www.example.com" contentType := "application/x-www-form-urlencoded" data := "key1=value1&key2=value2" requestBody := strings.NewReader(data) req, _ := http.NewRequest("POST", url, nil) req.Header.Set("Content-Type", contentType) req.Body = io.NopCloser(requestBody) -
application/json
该类型
Request Body数据是json格式,非url.Values类型,其他操作方式差不多,直接看示例:url := "http://www.example.com" contentType := "application/json" data := `{"key1":"xjx","key2":18}` requestBody := strings.NewReader(data) req, _ := http.NewRequest("POST", url, requestBody) req.Header.Set("Content-Type", contentType) -
application/xml
该类型
Request Body数据是xml格式或者[]byte格式,如果是字符串形式跟JSON处理一致,[]byte类型如下:url := "http://www.example.com" contentType := "application/xml" data := []byte(`<?xml version="1.0" encoding="UTF-8"?> <root> <name>John Doe</name> <email>john.doe@example.com</email> </root>`) requestBody := bytes.NewBuffer(data) req, _ := http.NewRequest("POST", url, requestBody) req.Header.Set("Content-Type", contentType) -
multipart/form-data
该类型一般用于上传文件,该类型表单数据一般通过二进制传输,我们转为 []byte或者string类型即可,示例如下:
url := "http://www.example.com" contentType := "multipart/form-data" data, _ := ioutil.ReadFile("post.txt") requestBody := bytes.NewReader(data) req, _ := http.NewRequest("POST", url, requestBody) req.Header.Set("Content-Type", contentType)
-
这些例子涵盖了 http.Request 的一些实际场景自定义使用,包括添加请求头、发送 GET 请求参数和发送 POST 表单数据等。你可以根据自己的需求进行更多自定义组合。
下面我们介绍一些使用 http.Client自带的函数(比如 http.Client.Get/http.Get、http.Client.Post/http.Post、http.Client.PostForm/http.PostForm等)发送HTTP请求操作,这些自带函数基本都是对标请求准流程进行了封装以适应不同场景简便使用。
自带函数请求
net/http包的client.go 文件提供了自带函数来简便的调用Client通过GET、POST等方式请求HTTP,下面来简单举例说明。
http.Get/http.Client.Get
使用net/http包编写一个简单的发送HTTP请求的Client端,可以使用 http.Get 或者 http.Client.Get函数,这两函数本质是一样的,源码如下:
func Get(url string) (resp *Response, err error) {
return DefaultClient.Get(url)
}
func (c *Client) Get(url string) (resp *Response, err error) {
req, err := NewRequest("GET", url, nil)
if err != nil {
return nil, err
}
return c.Do(req)
}
从上面代码可以看出, http.Get最终本质还是调用了 http.Client.Get函数来发送HTTP请求,唯一的区别就是 http.Get使用了默认的DefaultClient来作为Client从而可以不用自主创建一个新的Client,而http.Client.Get则需要自行创建一个新的Client(类似 $Client = $&http.Client{})来调用。
下面看一个 http.Get 函数无参数请求HTTP示例代码如下:
package main
import (
"fmt"
"io/ioutil"
"net/http"
)
func main() {
//Get方式获取URL的展示信息
resp, err := http.Get("https://www.qq.com")
if err != nil {
fmt.Println("get url failed, err:", err)
} else {
defer resp.Body.Close()
//读取body
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println("read from resp.Body failed,err:", err)
} else {
fmt.Println(string(body))
}
}
}
再来一个关于有参数的HTTP请求示例代码:
package main
import (
"fmt"
"io/ioutil"
"net/http"
"net/url"
)
func main() {
apiUrl := "http://www.example.com"
//解析URl字符串获取URL对象
u, err := url.ParseRequestURI(apiUrl)
if err != nil {
fmt.Printf("parse url requestUrl failed,err:%v\n", err)
}
//添加参数
params := url.Values{}
params.Add("age", "10")
params.Add("name", "xjx")
//将参数URL化,生成结果类似:bar=baz&foo=quux格式并赋值给URL.RawQuery
u.RawQuery = params.Encode()
resp, err := http.Get(u.String())
if err != nil {
fmt.Println("get url failed, err:", err)
} else {
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println("read from resp.Body failed,err:", err)
} else {
fmt.Println(string(body))
}
}
}
简易GET请求大致就是这样了,如果需要更复杂的则需要自定义请求来构造相关的Request信息了。
http.Post/http.Client.Post
上面演示了使用net/http包发送GET请求的示例,而发送POST请求则可以使用 http.Post 或者 http.Client.Post函数,源码如下:
func Post(url, contentType string, body io.Reader) (resp *Response, err error) {
return DefaultClient.Post(url, contentType, body)
}
func (c *Client) Post(url, contentType string, body io.Reader) (resp *Response, err error) {
req, err := NewRequest("POST", url, body)
if err != nil {
return nil, err
}
req.Header.Set("Content-Type", contentType)
return c.Do(req)
}
从上面代码可以看出, http.Post最终本质还是调用了 http.Client.Post函数来发送HTTP请求,在此就不再具体分析了。
下面来看下net/http包发送Post请求的示例:
package main
import (
"bytes"
"fmt"
"net/http"
)
func main() {
apiUrl := "http://www.example.com"
// 构造类型为 x-www-form-urlencoded 的请求体数据
// 发送 POST 请求
requestBody := bytes.NewBufferString("key1=value1&key2=value2")
resp, err := http.Post(apiUrl, "application/x-www-form-urlencoded", requestBody)
if err != nil {
// 发生错误
fmt.Println("Error occurred while sending request:", err)
return
}
defer resp.Body.Close()
// 读取响应结果
response, err := io.ReadAll(resp.Body)
if err != nil {
fmt.Println("Error occurred while reading response:", err)
return
}
// 输出响应结果
fmt.Println(string(response))
}
在http.Post 中第二个函数是可以自己控制的,它的值可以是 Request中 Content-Type 字段的允许值范围内,不清楚的可以点击Content-Type取值范围查看。
net/http包发送application/x-www-form-urlencoded类型的Post请求还有一个更简便的函数 http.PostForm或者 http.Client.PostForm:
func PostForm(url string, data url.Values) (resp *Response, err error) {
return DefaultClient.PostForm(url, data)
}
func (c *Client) PostForm(url string, data url.Values) (resp *Response, err error) {
return c.Post(url, "application/x-www-form-urlencoded", strings.NewReader(data.Encode()))
}
代码中已经固定了contentType类型为application/x-www-form-urlencoded,所以只需要传入 url 和 url.Values类型的data即可。
http.Head/http.Client.Head
net/http 包提供了一个名为 http.Head/http.Client.Head 的函数,用于发送 HTTP 的 HEAD 请求并返回响应结果的头部信息。HEAD 请求与 GET 请求类似,但服务器将不会返回响应体,只会返回响应头部信息。
func Head(url string) (resp *Response, err error) {
return DefaultClient.Head(url)
}
func (c *Client) Head(url string) (resp *Response, err error) {
req, err := NewRequest("HEAD", url, nil)
if err != nil {
return nil, err
}
return c.Do(req)
}
http.Head最终本质还是调用了 http.Client.Head函数来发送HTTP请求,以下是一个简单的示例,演示如何使用 http.Head 函数发送 HTTP HEAD 请求并获取响应头部信息:
package main
import (
"fmt"
"net/http"
)
func main() {
url := "https://www.example.com"
resp, err := http.Head(url)
if err != nil {
fmt.Println("Error:", err)
return
}
defer resp.Body.Close()
fmt.Println("Status:", resp.Status)
fmt.Println("Content-Length:", resp.Header.Get("Content-Length"))
fmt.Println("Content-Type:", resp.Header.Get("Content-Type"))
}
在这个示例中,我们首先定义了一个目标 URL,然后调用 http.Head 函数向该 URL 发送 HEAD 请求并获取响应结果。如果函数执行成功,我们打印出响应状态、响应长度以及响应类型。需要注意的是,在获取响应头部信息后,我们需要手动调用 resp.Body.Close() 来关闭响应体,以便释放资源。
做个总结,net/http包中不管 GET ,POST 还是 PostForm函数,观其代码都是通过封装了 创建Client、创建 NewRequest、最后通过``http.Client的Do`发送流程,方便了用户的操作,但也失去了用户自己自定义特殊需求的灵活性,这时候就需要通过基本请求流程,自行去定义请求来解决灵活性问题。
Client核心源码解析
前面已经把自定义 http.Request 梳理完,接下去就要通过Client端将 Request 信息通过HTTP协议发送到Server端去并由Server端返回 Response信息,收到 Response信息后Client解析完成,这样一个来回才是完整的Client的工作流程。
如下图是 Client端发送的核心流程:
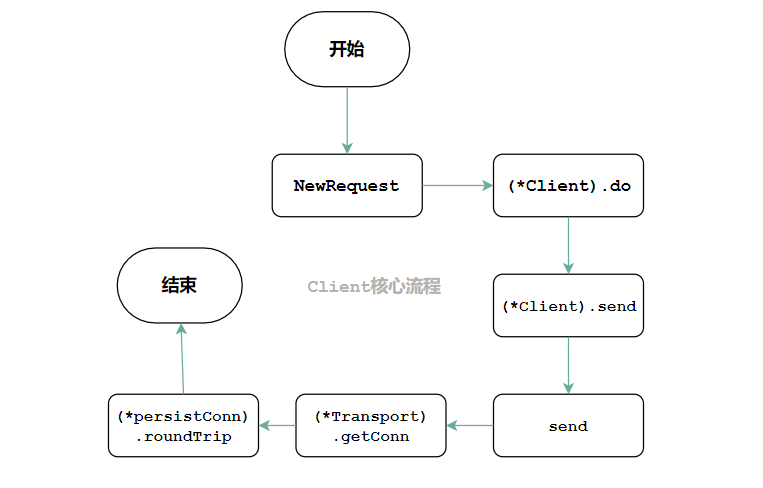
http.newRequest前面章节已经讲过,下面将对剩下的核心点进行逐一分解。
(*Client).do
前面Client标准请求流程中提过,完成 http.Request 对象后,将请求对象传递给http.Client的Do方法完成后续发送任务,而http.Client自带的函数(http.Client.Get/http.Client.Post/http.Client.Head/http.Client.PostForm)中也是如此,如下代码:
func (c *Client) Get(url string) (resp *Response, err error) {
req, err := NewRequest("GET", url, nil)
......
return c.Do(req)
}
func (c *Client) Post(url, contentType string, body io.Reader) (resp *Response, err error) {
req, err := NewRequest("POST", url, body)
......
return c.Do(req)
}
func (c *Client) Head(url string) (resp *Response, err error) {
req, err := NewRequest("HEAD", url, nil)
......
return c.Do(req)
}
从代码得出,所有函数都是在完成 NewRequest对象后,调用 http.Client的Do方法,来看看这个方法:
func (c *Client) Do(req *Request) (*Response, error) {
return c.do(req)
}
原来此函数是个马甲,最终调用的是 http.Client.do函数,该函数的作用是自动处理请求的重定向、超时、代理等操作,并返回响应结果。
来看下函数源码,该函数比较长,主要地方都已经加上了详细的注释:
func (c *Client) do(req *Request) (retres *Response, reterr error) {
// ... 省略部分跟测试相关的代码
//检查req.URL,为空则返回错误,关闭请求主体
if req.URL == nil {
req.closeBody()
return nil, &url.Error{
Op: urlErrorOp(req.Method),
Err: errors.New("http: nil Request.URL"),
}
}
//定义变量,它们的类型和初始值将由 Go 语言的编译器自动推导
var (
deadline = c.deadline() //http客户端截止时间
reqs []*Request //请求列表,用于处理重定向
resp *Response //HTTP 响应结果
copyHeaders = c.makeHeadersCopier(req) //复制请求头部的函数,用于在发起重定向请求时复制原始请求的头部信息。
reqBodyClosed = false //标记请求主体是否已关闭
redirectMethod string //重定向请求的 HTTP 方法
includeBody bool //标记是否包含响应主体。在处理HEAD请求时,这个值通常为 false
)
// 定义一个内部函数,用于在发生错误时生成URL类型错误
uerr := func(err error) error {
// 如果请求主体未关闭,则关闭请求主体
if !reqBodyClosed {
req.closeBody()
}
// 根据 HTTP 请求或响应的 URL 生成 URL 字符串
var urlStr string
if resp != nil && resp.Request != nil {
urlStr = stripPassword(resp.Request.URL)
} else {
urlStr = stripPassword(req.URL)
}
return &url.Error{
Op: urlErrorOp(reqs[0].Method),
URL: urlStr,
Err: err,
}
}
for {
//处理重新定向问题
if len(reqs) > 0 {
//获取返回响应头部Location信息
loc := resp.Header.Get("Location")
//如果Location信息为空,则关闭响应体,返回错误信息
if loc == "" {
resp.closeBody()
return nil, uerr(fmt.Errorf("%d response missing Location header", resp.StatusCode))
}
//解析Location字段得到重定向的地址u
u, err := req.URL.Parse(loc)
//解析错误则关闭响应体,返回错误
if err != nil {
resp.closeBody()
return nil, uerr(fmt.Errorf("failed to parse Location header %q: %v", loc, err))
}
//如果请求的Host字段不为空且与URL字段不同,且u不是绝对地址,则将Host字段的值赋给host变量
host := ""
if req.Host != "" && req.Host != req.URL.Host {
if u, _ := url.Parse(loc); u != nil && !u.IsAbs() {
host = req.Host
}
}
//据请求列表reqs的第一个请求创建一个新的请求req
//并将重定向方法redirectMethod、响应体resp、重定向地址u、空Header、host、取消函数、以及上下文变量等信息赋给这个新请求
ireq := reqs[0]
req = &Request{
Method: redirectMethod,
Response: resp,
URL: u,
Header: make(Header),
Host: host,
Cancel: ireq.Cancel,
ctx: ireq.ctx,
}
//如果需要将原请求的请求体转移到新请求中,则将这个转移的过程交给一个可选的函数GetBody(),将得到的请求体赋给新请求的Body字段
if includeBody && ireq.GetBody != nil {
req.Body, err = ireq.GetBody()
if err != nil {
resp.closeBody()
return nil, uerr(err)
}
//将转移的请求体长度赋给新请求的ContentLength字段
req.ContentLength = ireq.ContentLength
}
//将原请求的所有请求头都拷贝到新请求的请求头中
copyHeaders(req)
//根据重定向前和重定向后的URL设置新请求的Referer请求头
if ref := refererForURL(reqs[len(reqs)-1].URL, req.URL); ref != "" {
req.Header.Set("Referer", ref)
}
//调用c.checkRedirect(req, reqs)函数检查是否应该继续重定向,并返回错误值。
//如果该函数返回的错误是ErrUseLastResponse,则表示应该停止重定向并返回原响应体
err = c.checkRedirect(req, reqs)
if err == ErrUseLastResponse {
return resp, nil
}
//如果响应体的ContentLength为-1或小于等于2KB,则使用io.CopyN()将响应体中的前2KB字节拷贝到io.Discard中,然后关闭响应体
//总的来说,这段代码是为了保证从 HTTP 响应中读取的数据不会过多,避免出现潜在的内存问题
//io.Discard 是一个实现了 io.Writer 接口的类型, 作用是存储需要读取但不需要处理的某些数据,然后将数据丢弃掉,而不会占用任何内存空间
const maxBodySlurpSize = 2 << 10 //2048byte=2kb
if resp.ContentLength == -1 || resp.ContentLength <= maxBodySlurpSize {
io.CopyN(io.Discard, resp.Body, maxBodySlurpSize)
}
resp.Body.Close()
//如果在上述过程中发生了错误,则将错误信息包装成url.Error类型并将重定向地址loc赋值给该错误的URL字段,最后返回响应体和错误
if err != nil {
ue := uerr(err)
ue.(*url.Error).URL = loc
return resp, ue
}
}
// 将请求添加到 reqs 切片中
reqs = append(reqs, req)
var err error
var didTimeout func() bool
//发送请求,获取响应
if resp, didTimeout, err = c.send(req, deadline); err != nil {
reqBodyClosed = true
// 如果在等待响应头时发生超时,则生成 HTTP 错误,表示客户端超时
if !deadline.IsZero() && didTimeout() {
err = &httpError{
err: err.Error() + " (Client.Timeout exceeded while awaiting headers)",
timeout: true,
}
}
// 返回 URL 错误
return nil, uerr(err)
}
// 根据重定向策略获取重定向的 HTTP 方法、是否应该重定向以及是否应该包含请求主体
var shouldRedirect bool
redirectMethod, shouldRedirect, includeBody = redirectBehavior(req.Method, resp, reqs[0])
if !shouldRedirect {
return resp, nil
}
//关闭请求体
req.closeBody()
}
}
来总结下上述函数的主要脉络点:
- 函数接收一个
Request指针类型参数req,用于表示要发送的HTTP请求。 - 函数首先会根据请求信息生成一个新的
HTTP请求对象,并进行必要的身份验证。 - 然后,函数调用
http.send方法,以发送HTTP请求并接收HTTP响应。 - 如果返回的响应状态码需要进行重定向,函数会调用
checkRedirect方法进行处理,并重新发送HTTP请求。 - 如果返回的响应需要进行身份验证,函数会重新发送
HTTP请求。 - 函数读取
HTTP响应的Body,然后关闭Body。 - 如果返回的响应状态码表示请求失败,函数将返回一个
httpError错误。 - 否则,函数将返回响应结果和
nil错误。
在重定向流程中,简单介绍下 checkRedirect 函数:
func (c *Client) checkRedirect(req *Request, via []*Request) error {
fn := c.CheckRedirect
if fn == nil {
fn = defaultCheckRedirect
}
return fn(req, via)
}
func defaultCheckRedirect(req *Request, via []*Request) error {
if len(via) >= 10 {
return errors.New("stopped after 10 redirects")
}
return nil
}
由上可知,如果自定义了http.Client.CheckRedirect函数,则会按着自定义的函数走,否则会执行默认的defaultCheckRedirect函数,该函数主要是规定重定向次数不能超过 10 次。
(*Client).send
在 http.Client.do 函数中是调用 http.Client.send函数将HTTP请求进行发送出去的,我们来看下源码:
func (c *Client) send(req *Request, deadline time.Time) (resp *Response, didTimeout func() bool, err error) {
if c.Jar != nil {
for _, cookie := range c.Jar.Cookies(req.URL) {
req.AddCookie(cookie)
}
}
resp, didTimeout, err = send(req, c.transport(), deadline)
if err != nil {
return nil, didTimeout, err
}
if c.Jar != nil {
if rc := resp.Cookies(); len(rc) > 0 {
c.Jar.SetCookies(req.URL, rc)
}
}
return resp, nil, nil
}
上述代码的主要逻辑是:
- 如果
Client的Jar字段不为nil,表示客户端需要使用cookie来维护与服务器的状态。在这种情况下,该方法会在req中添加来自客户端Jar字段的所有cookie,并在发送请求时将其发送给服务器 - 使用
c.transport()方法从客户端获取底层传输,然后使用send函数发送HTTP请求,并将响应与是否超时的标志一起返回 - 如果
Client的Jar字段不为nil并且响应中包含cookie,则该方法将使用Jar的SetCookies方法将其保存到cookie中。最后,该方法将返回响应和nil错误
在这边我们需要关注http.Client.send调用的两个函数: http.Client.transport() 与 send()函数。
http.Client.transport()函数,代码如下:
func (c *Client) transport() RoundTripper {
if c.Transport != nil {
return c.Transport
}
return DefaultTransport
}
如代码所述,http.Client.transport()函数主要是返回一个能够处理 HTTP 请求和响应的对象,该对象为 http.RoundTripper 类型:
http.Client.Transport为空,则表示没有设置,使用默认的http.DefaultTransporthttp.Client.Transport非空,则调用http.Client.Transport设置的自己实现的HTTP传输层的对象去执行
我们来理理 http.Client.Transport、http.Transport、http.RoundTripper的关系:
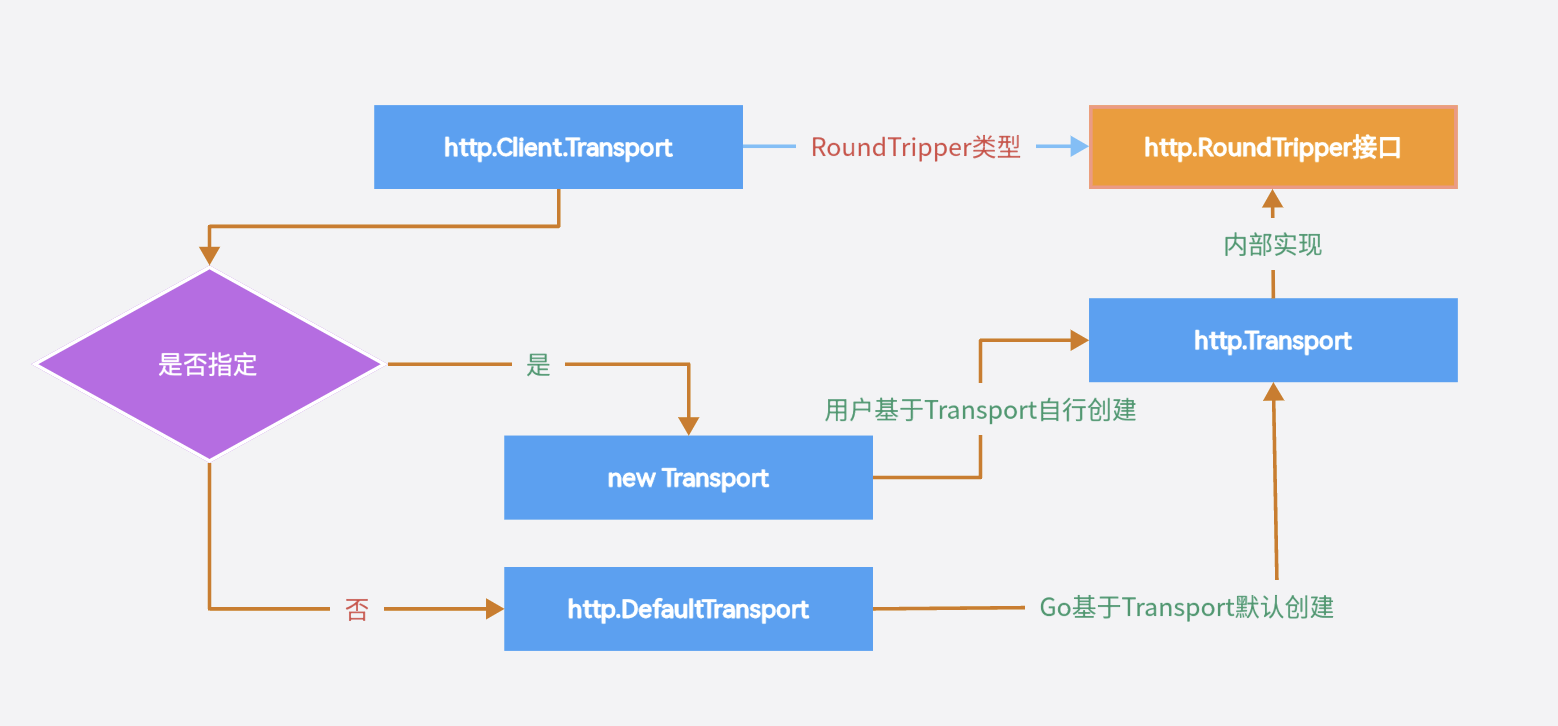
上面是 http.Client、http.Transport 和 http.RoundTripper 等的关系图。
http.Transport
http.Transport 是一个HTTP传输层的实现,实现了 http.RoundTripper 接口,因此可以作为 http.Client 的 Transport 字段的值,http.Transport管理HTTP客户端和服务器之间的连接池,并提供重试机制以处理连接故障和临时错误。
http.Transport 结构体主要字段说明:
type Transport struct {
//idleMu 是一个互斥锁,用于保护 idleConn 和 idleLRU 字段
idleMu sync.Mutex
//closeIdle是一个通道,用于触发关闭空闲连接的操作
closeIdle bool
//idleConn 是一个映射,用于存储每个主机的空闲连接。该映射的键是主机的地址,值是一个空闲连接列表
idleConn map[connectMethodKey][]*persistConn
// idleConnWait 是一个映射,用于存储每个主机的等待连接的通道。该映射的键是主机的地址,值是一个通道,用于等待空闲连接的到来
idleConnWait map[connectMethodKey]wantConnQueue
// idleLRU 是一个双向链表,用于存储所有的空闲连接。连接从链表前面插入,最近使用的连接在链表后面。空闲连接的最大数量由 MaxIdleConns 字段控制。如果空闲连接的数量超过了该值,则最早使用的连接将被关闭
idleLRU connLRU
reqMu sync.Mutex
//reqCanceler 是一个 chan struct{} 类型的通道,用于取消正在执行的请求。
reqCanceler map[cancelKey]func(error)
altMu sync.Mutex
//altProto 是一个 map[string]RoundTripper 类型的映射,用于存储替代协议的 RoundTripper 实现。在 http.Transport 中,只有 HTTP 和 HTTPS 协议被直接支持。如果您想使用其他协议,可以将其添加到 altProto 中
altProto atomic.Value
connsPerHostMu sync.Mutex
//connsPerHost 是一个映射,用于存储每个主机已经建立的连接的数量。该映射的键是主机的地址,值是已经建立的连接数量
connsPerHost map[connectMethodKey]int
//等待建立连接的队列,同样基于切片实现,队列大小无限制
connsPerHostWait map[connectMethodKey]wantConnQueue
//Proxy 指定 HTTP 代理地址,如果非 nil,则发送的请求将通过指定的 HTTP 代理服务器进行转发
Proxy func(*Request) (*url.URL, error)
//用于指定建立 TCP 连接的上下文函数。如果未设置,则使用默认的 net.Dialer
DialContext func(ctx context.Context, network, addr string) (net.Conn, error)
//用于指定建立 TCP 连接的函数。如果未设置,则使用默认的 net.Dial
Dial func(network, addr string) (net.Conn, error)
//用于指定建立 TLS 连接的上下文函数。如果未设置,则使用默认的 tls.Dialer
DialTLSContext func(ctx context.Context, network, addr string) (net.Conn, error)
// 用于指定建立 TLS 连接的函数。如果未设置,则使用默认的 tls.Dial
DialTLS func(network, addr string) (net.Conn, error)
// TLSClientConfig 指定用于 TLS 客户端连接的配置,如果未设置,则使用默认配置
TLSClientConfig *tls.Config
// TLSHandshakeTimeout 指定 TLS 握手超时时间。如果未设置,则默认为 10 秒
TLSHandshakeTimeout time.Duration
// DisableKeepAlives 用于指定是否禁用 HTTP keep-alive 连接。如果为 true,则禁用 keep-alive 连接
DisableKeepAlives bool
// DisableCompression 指定是否禁用 HTTP 压缩
DisableCompression bool
//用于指定每个主机保持的最大空闲连接数。如果未设置,则默认为 100
MaxIdleConns int
// MaxIdleConnsPerHost 指定每个主机每个端口最大空闲连接数,如果未设置,则默认为 2
MaxIdleConnsPerHost int
MaxConnsPerHost int
// IdleConnTimeout 指定空闲连接的超时时间
IdleConnTimeout time.Duration
// ResponseHeaderTimeout 指定从服务器读取响应头的最大时间如果未设置,则默认为 0,即没有超时限制
ResponseHeaderTimeout time.Duration
// ExpectContinueTimeout 指定在发送 Expect: 100-continue 请求头后等待继续请求的最大时间。
ExpectContinueTimeout time.Duration
//TLSNextProto 用于指定在 HTTP/2 之后使用的协议。如果未设置,则默认使用 http.DefaultTransport.TLSNextProto
TLSNextProto map[string]func(authority string, c *tls.Conn) RoundTripper
//ProxyConnectHeader 用于指定在使用代理时,发送到代理的 CONNECT 请求头部。如果未设置,则使用默认的 CONNECT 请求头部
ProxyConnectHeader Header
GetProxyConnectHeader func(ctx context.Context, proxyURL *url.URL, target string) (Header, error)
// MaxResponseHeaderBytes 指定允许读取的响应头的最大字节数,如果为 0,则表示不设定限制
MaxResponseHeaderBytes int64
// WriteBufferSize 指定写入传输层的缓冲区大小,如果为 0,则使用默认值
WriteBufferSize int
// ReadBufferSize 指定从传输层读取的缓冲区大小,如果为 0,则使用默认值
ReadBufferSize int
// nextProtoOnce 是一个 sync.Once 类型的值,用于确保只调用一次 tls.Config.NextProtos
nextProtoOnce sync.Once
// h2transport 是一个 http2.Transport 类型的值,用于处理 HTTP/2 请求。
h2transport h2Transport
//tlsNextProtoWasNil 是一个 bool 类型的值,表示在使用 tls.Config.NextProtos 配置 HTTP/2 时,是否设置了 nil 的下一个协议。
tlsNextProtoWasNil bool
// ForceAttemptHTTP2 指定是否强制使用 HTTP/2,如果设置为 true,则不尝试 HTTP/1.1
ForceAttemptHTTP2 bool
}
上述结构体中只有大写字段开头的是允许设置和指定的,小写字母开头是内部字段。
http.Transport 中重要的一个点是它维护了一个连接池(Connection Pool)用于管理 HTTP 持久连接,以提高网络传输效率。
连接池是一种常见的网络优化技术,它通过预先创建一定数量的连接并保存在连接池中,以便后续的请求可以重复使用这些连接,从而避免每次请求都需要重新创建连接的开销。在 http.Transport 中,连接池由 http.persistConn 类型实现(后续会讲),它用于管理 HTTP 持久连接的创建、维护和关闭等操作。
连接池的大小是通过 http.Transport 中的 MaxIdleConns 和 MaxIdleConnsPerHost 属性来控制的。
其中,MaxIdleConns 表示连接池中连接的最大数量,而 MaxIdleConnsPerHost 则表示每个主机可以保持的最大连接数。在发送请求时,http.Transport 会根据请求的主机地址从连接池中选择一个可用的连接,并将请求发送到该连接上,如果连接池中没有可用的连接,则会创建一个新的连接。
而连接池中的空闲连接通过 idleConn 和 idleConnWait 两个字段来实现连接的管理和维护,当一个连接被获取时,http.Transport 会将一个空结构体(struct{})发送到 idleConnWait 通道中,表示连接池中的连接数量减少了一个。当一个连接空闲时,它会被添加到对应主机地址的空闲连接列表idleConn中,并从 idleConnWait 通道中接收一个空结构体,表示连接池中的连接数量增加了一个。
需要主要的是 idleConn的类型是map[connectMethodKey][]*persistConn,其值是一个persistConn指针的切片,而 idleConnWait类型是一个 map[connectMethodKey]wantConnQueue,其值是一个队列类型,该队列是定义:
type wantConnQueue struct {
head []*wantConn
headPos int
tail []*wantConn
}
该队列是用head 和 tail两个slice构造,入队的时候append到tail中;出队的时候,从head[headPos]中取第一个元素,如果head空了,就交换head和tail。这样head slice为空的时候则与tail slice交换,底层的数组空间可以重用,从而节省内存空间。
除此之外,可以通过以下方式自定义http.Transport行为:
-
调整连接池大小:可以通过修改
http.Transport.MaxIdleConns和http.Transport.MaxIdleConnsPerHost属性来控制连接池的大小。 -
禁用
Keep-Alive:可以通过将http.Transport.DisableKeepAlives属性设置为true来禁用Keep-Alive。 -
自定义代理:可以将
http.Transport.Proxy属性设置为自定义代理函数,以允许使用自定义代理发送请求。 -
自定义
TLS配置:可以通过将http.Transport.TLSClientConfig属性设置为自定义的tls.Config实例来自定义TLS连接配置。 -
自定义重试机制:可以通过设置
http.Transport.RetryMax和http.Transport.RetryOn属性来自定义重试机制的行为。
总之,http.Transport是一个灵活的、可定制的HTTP传输层实现,可以根据应用程序的需求进行自定义配置。
http.RoundTripper
http.RoundTripper 是一个接口,它定义了一个发送 HTTP 请求并返回 HTTP 响应的方法,只有一个方法 RoundTrip(*http.Request) (*http.Response, error),这个方法处理 HTTP 请求并返回 HTTP 响应。http.RoundTripper 接口可以被其他结构体实现,并且可以根据需要进行自定义。
type RoundTripper interface {
RoundTrip(*Request) (*Response, error)
}
http.Client.Transport
http.Client.Transport 则是一个 http.RoundTripper类型的接口,它作为 http.Client 的 Transport 字段使用,其值为 http.Transport 的实例,用来控制 HTTP 请求的发送和响应的处理。如果不设置其值,使用默认的 http.DefaultTransport。
http.DefaultTransport实现如下:
var DefaultTransport RoundTripper = &Transport{
Proxy: ProxyFromEnvironment,
DialContext: (&net.Dialer{
Timeout: 30 * time.Second,
KeepAlive: 30 * time.Second,
}).DialContext,
ForceAttemptHTTP2: true,
MaxIdleConns: 100,
IdleConnTimeout: 90 * time.Second,
TLSHandshakeTimeout: 10 * time.Second,
ExpectContinueTimeout: 1 * time.Second,
}
接下来重点分析 send() 函数。
send
send函数功能是发送HTTP请求并等待响应。源码如下:
func send(ireq *Request, rt RoundTripper, deadline time.Time) (resp *Response, didTimeout func() bool, err error) {
req := ireq
// ****** 省略部分对URL判断的代码 ******
//创建一个新的Request对象,可以确保重试请求使用的是原始请求的参数,而不是修改后的请求参数。
//由于是浅拷贝,所以只会复制 Request 结构体中的值类型字段,而不会复制指针类型字段
//例如 Header 字段,因此可以避免共享相同的请求头部。
forkReq := func() {
if ireq == req {
req = new(Request)
*req = *ireq
}
}
//检查请求对象 req 的 Header 字段是否为 nil
//如果是,则使用 forkReq 函数创建一个新的请求对象,并将 Header 字段设置为一个新创建的空的 Header 对象 ;如果 Header 字段不为 nil,则继续使用现有的 Header 对象
if req.Header == nil {
forkReq()
req.Header = make(Header)
}
//检查 HTTP 请求的 URL 是否包含用户认证信息,并且请求头部中没有设置 Authorization 头部
//如果满足条件,则使用用户认证信息创建一个 Authorization 头部,并将其添加到请求头部中
if u := req.URL.User; u != nil && req.Header.Get("Authorization") == "" {
username := u.Username()
password, _ := u.Password()
forkReq()
req.Header = cloneOrMakeHeader(ireq.Header)
req.Header.Set("Authorization", "Basic "+basicAuth(username, password))
}
//检查是否设置了请求的截止时间(deadline),如果设置了,则使用 forkReq 函数创建一个新的请求对象,以便稍后修改该对象而不影响原始请求
if !deadline.IsZero() {
forkReq()
}
//为rt设置一个请求取消方法,并启动一个定时器用于在请求超时时取消该请求
stopTimer, didTimeout := setRequestCancel(req, rt, deadline)
//使用 RoundTrip函数向服务发送请求req,并阻塞等待该服务的响应
//响应结果会被赋值给resp变量,同时任何错误都会被赋值给err变量
resp, err = rt.RoundTrip(req)
if err != nil {
stopTimer()
// ****** 省略错误处理的代码 ******
return nil, didTimeout, err
}
// ****** 省略错误处理的代码 ******
return resp, nil, nil
}
函数主要步骤如下:
- 检查请求是否符合
HTTP协议的规范,如果不符合则返回错误。 - 检查请求是否已被取消,如果已取消则返回错误。
- 检查发送请求的截止时间是否已过期,如果已过期则返回错误。
- 调用
RoundTripper接口的RoundTrip方法,向服务器发送HTTP请求,并等待响应。 - 在等待响应的过程中,如果发送请求的截止时间已经过期,则会强制中断请求并返回错误。
- 如果在发送请求的过程中遇到了网络错误、服务器错误或其它错误,则会将错误信息返回给调用方。
- 如果没有遇到错误,则将响应结果保存在
resp变量中,并返回它的指针。
这里面重点关注 http.Transport.RoundTrip函数。
(*Transport).RoundTrip
http.Transport 实现了 http.RoundTripper 接口,也是整个请求过程中最重要并且最复杂的结构体,该结构体在 http.Transport.roundTrip中发送 HTTP 请求并等待响应。
而 http.Transport.RoundTrip 的逻辑也很简单,就是调用 http.Transport.roundTrip 方法:
func (t *Transport) RoundTrip(req *Request) (*Response, error) {
return t.roundTrip(req)
}
http.Transport.roundTrip 函数是 Go 语言中实现 HTTP 客户端功能的核心函数之一,它负责发送请求并接收响应,并对请求和响应进行必要的处理,以确保 HTTP 客户端的稳定和可靠性。
http.Transport.roundTrip 函数需要考虑多种情况,如请求和响应的超时设置、请求和响应的流量控制、请求和响应的缓存处理等。因此,这个函数的实现涉及到很多细节,需要对 HTTP 协议和底层网络编程有一定的了解。
http.Transport.roundTrip 函数以及关联函数流程如下:
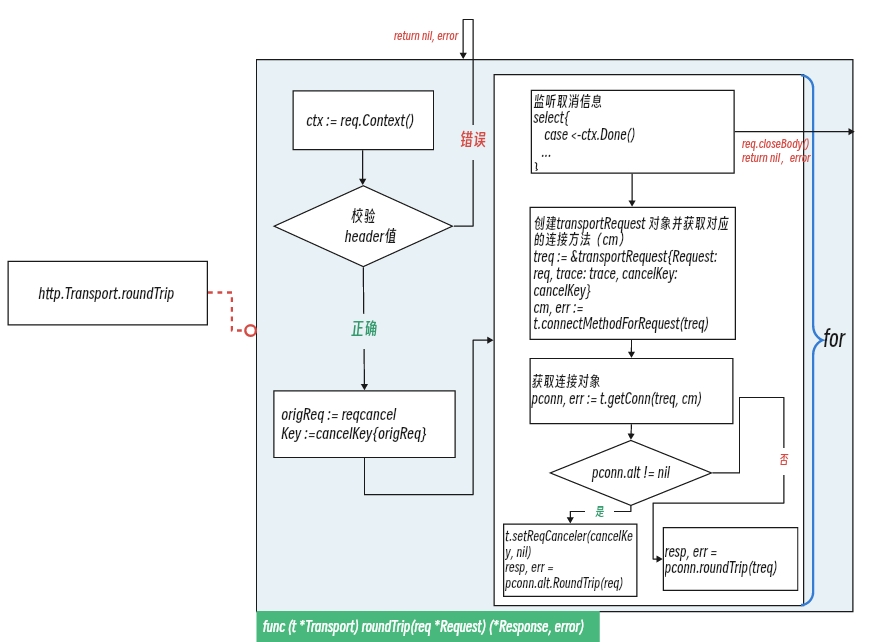
http.Transport.roundTrip 函数源码如下:
func (t *Transport) roundTrip(req *Request) (*Response, error) {
//确保t.onceSetNextProtoDefaults只会被调用一次,即设置Transport对象的默认下一个协议(NPN)
t.nextProtoOnce.Do(t.onceSetNextProtoDefaults)
//从请求req中获取请求上下文ctx
ctx := req.Context()
//从请求上下文ctx中获取HTTP客户端跟踪信息
trace := httptrace.ContextClientTrace(ctx)
// ****** 省略校验URL以及header头和headervalue的错误处理的代码 ******
scheme := req.URL.Scheme
//isHTTP表示是否使用http协议
isHTTP := scheme == "http" || scheme == "https"
// ****** 省略校验header头和headervalue的错误处理的代码 ******
//创建origReq变量,一般作为req的备份
origReq := req
//声明一个cancelKey类型的变量,origReq为参数传入
cancelKey := cancelKey{origReq}
//为请求对象设置一个能够缓存和重用请求体数据的功能
req = setupRewindBody(req)
// ****** 省略校验req信息的错误处理的代码 ******
for {
//如果ctx收到取消信号,就会执行 req.closeBody() 关闭请求体,并返回一个错误信息
select {
case <-ctx.Done():
req.closeBody()
return nil, ctx.Err()
default:
}
//创建了一个 transportRequest 对象,并通过 connectMethodForRequest 方法获取与该请求相对应的连接方法(connect method)
treq := &transportRequest{Request: req, trace: trace, cancelKey: cancelKey}
cm, err := t.connectMethodForRequest(treq)
if err != nil {
req.closeBody()
return nil, err
}
// 通过 t.getConn() 方法获取与服务器通信的连接对象 pconn
// getConn函数主要用于获取一个与服务器通信的连接对象,并进行必要的初始化操作
pconn, err := t.getConn(treq, cm)
if err != nil {
t.setReqCanceler(cancelKey, nil)
req.closeBody()
return nil, err
}
/**
将 HTTP 请求发送到服务器,并返回服务器响应
首先判断 pconn.alt 是否为 nil:
1. 如果 pconn.alt 不为 nil,则表示当前请求使用了 HTTP/2 或 HTTP/3 协议。在这种情况下,Transport.RoundTrip() 方法会将HTTP请求转发到 pconn.alt.RoundTrip(req)方法进行处理
2. 如果 pconn.alt 为 nil,则表示当前请求使用了 HTTP/1.x 协议。在这种情况下,Transport.RoundTrip() 方法会将 HTTP 请求转发到 pconn.roundTrip(treq) 方法进行处理
*/
var resp *Response
if pconn.alt != nil {
t.setReqCanceler(cancelKey, nil)
resp, err = pconn.alt.RoundTrip(req)
} else {
resp, err = pconn.roundTrip(treq)
}
if err == nil {
resp.Request = origReq
return resp, nil
}
// ****** 省略错误处理的代码 ******
//将原始的 req 对象中的 Body 字段读取出来并存储到内存中,然后使用存储了数据的新的请求对象替换原始的请求对象,并将可能发生的错误保存到 err 变量中
req, err = rewindBody(req)
if err != nil {
return nil, err
}
}
}
总结下该函数的大致流程:
- 检查请求的 URL 以及 请求的主体有效性
- 根据传入的
req请求数据创建一个transportRequest结构的请求treq,后调用http.Transport.connectMethodForRequest方法获取与该请求相对应的连接方法(connect method)并赋予变量cm,该连接方法类型为connectMethod - 传入请求
treq与连接方法cm,调用http.Transport.getConn获取或创建到目标主机的连接pconn,该连接类型为persistConn - 检查
pconn.alt参数值确认是否需要升级到HTTP/2 或 HTTP/3协议,如果pconn.alt参数不为空则需要则调用pconn.alt.RoundTrip函数并传入原始req请求参数发送请求且读取响应,然则调用pconn.roundTrip函数并传入新建请求treq发送请求且读取响应
展开流程中的一些结构体来稍微讲一下,这些结构体是: transportRequest、connectMethod:
http.transportRequest
transportRequest 结构体封装了一个 HTTP 请求的相关信息,包括原始请求、额外的请求头信息、客户端跟踪器、取消键值以及错误信息等。该结构体如下:
type transportRequest struct {
*Request //原始的 HTTP 请求信息,类型为 *http.Request
extra Header //需要额外添加的请求头信息,类型为 http.Header。如果没有额外的请求头信息,则为 nil
trace *httptrace.ClientTrace //客户端跟踪器,类型为 *httptrace.ClientTrace。如果没有设置客户端跟踪器,则为 nil
cancelKey cancelKey //用于取消该请求的键值,类型为 cancelKey。该键值在 Transport 结构体中使用,用于取消正在进行的请求
mu sync.Mutex // 用于保护 err 字段的互斥锁,类型为 sync.Mutex
err error //请求过程中出现的错误信息,类型为 error
}
该结构体通常是在 http.Transport 类型中使用,用于描述 HTTP 请求的细节信息,并进行相应的设置。具体来说,当我们使用 http.Client 发送 HTTP 请求时,它会使用 http.Transport 来处理请求。而 http.Transport 又会使用 http.transportRequest 来表示 HTTP 请求的细节信息,如请求头、取消请求的键值、客户端跟踪器等。
在实际使用中,我们一般不会直接使用 http.transportRequest,而是通过设置 http.Request 中的相关字段来设置 HTTP 请求的细节信息。例如,我们可以使用 http.Request 中的 Header 字段来设置请求头信息,使用 httptrace.WithClientTrace 函数来设置客户端跟踪器等。http.Transport 会根据 http.Request 中的信息,自动生成对应的 http.transportRequest 对象,并将其用于处理 HTTP 请求。
http.connectMethod
http.connectMethod 主要是在 http.Transport 类型中使用,用于描述 HTTP 请求的目标服务器地址和协议。
源码定义如下:
type connectMethod struct {
_ incomparable
proxyURL *url.URL //该字段的值是一个 *url.URL 类型的指针,表示代理服务器的地址。如果该字段为 nil,则表示不使用代理服务器,直接连接目标服务器,如果该字段不为 nil,则表示使用代理服务器连接目标服务器。
targetScheme string //连接的目标协议,可以是 "http" 或 "https"
targetAddr string //连接的目标服务器地址。如果使用代理服务器,该字段表示代理服务器连接的目标服务器地址;否则,该字段表示直接连接的目标服务器地址
onlyH1 bool //该字段用于指定是否强制使用 HTTP/1 协议。如果该字段为 true,则表示只使用 HTTP/1 协议;否则,表示使用默认的协议(通常是 HTTP/2)
}
在 http.Transport 类型中,connectMethod 主要用于唯一标识一个 HTTP连接。http.Transport 会根据 connectMethod 中的字段信息,选择适当的连接方式来与目标服务器建立连接。在 http.Request 发起 HTTP 请求时,http.Transport 会将请求的目标地址解析为一个 connectMethod,并使用该 connectMethod 来建立连接和发送请求。
该函数还调用了需要关注的函数是 http.Transport.getConn 和 http.persistConn.roundTrip,下面进行分析。
(*Transport).getConn
getConn方法是 Transport 结构体的一个方法,用于从连接池中获取一个 persistConn 对象,如果没有可用的连接则创建新的连接。在 HTTP 请求过程中,可以重复使用同一连接来提高效率。
http.Transport.getConn以及其函数涉及到的重要函数逻辑流程导图如下:
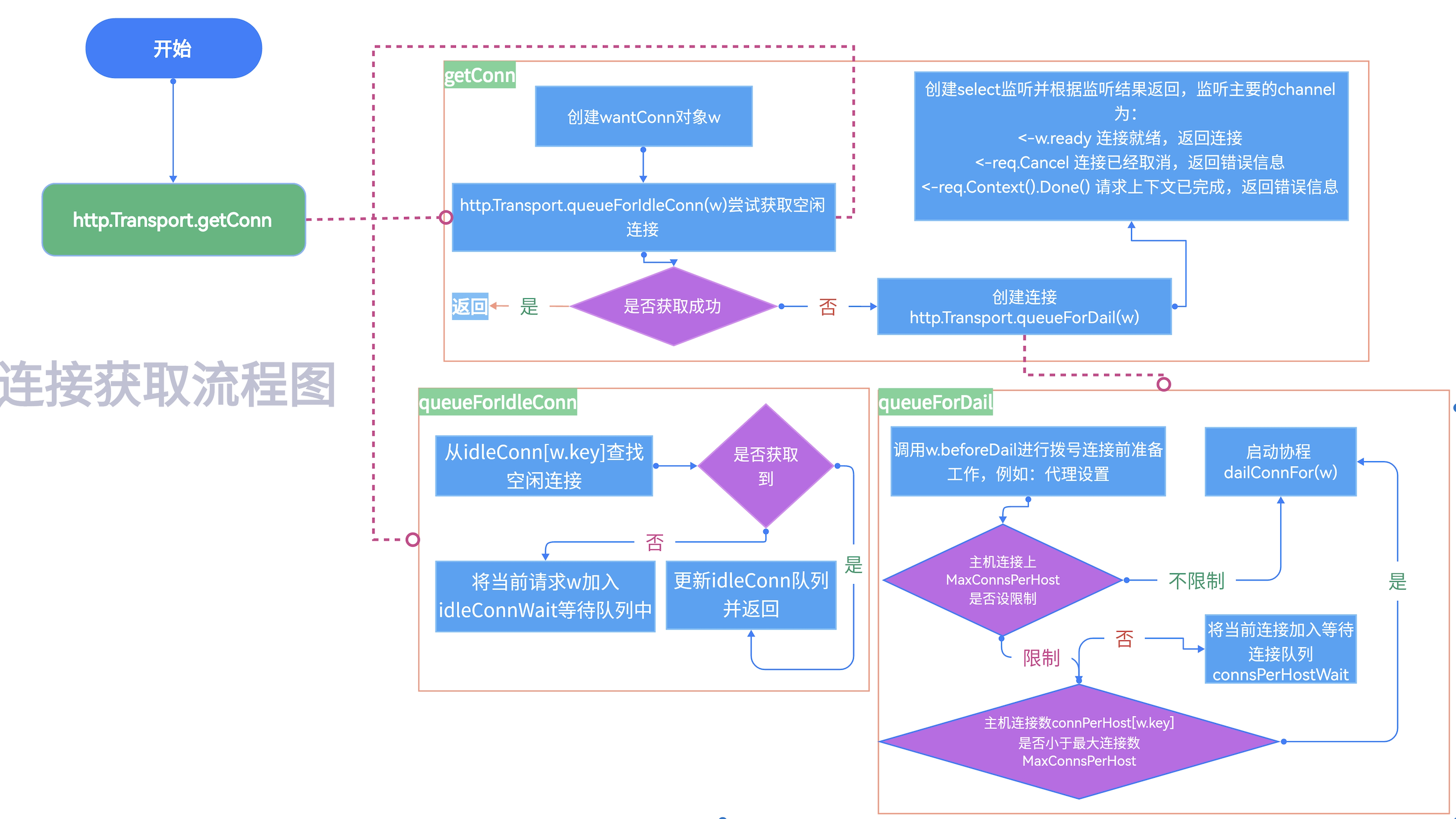
http.Transport.getConn 源码如下:
func (t *Transport) getConn(treq *transportRequest, cm connectMethod) (pc *persistConn, err error) {
//从treq中获取原始请求信息req
req := treq.Request
//获取req的上下文
ctx := req.Context()
//创建了一个 wantConn对象w,代表期望获得一个连接
w := &wantConn{
cm: cm,
key: cm.key(), //返回连接池的key
ctx: ctx,
ready: make(chan struct{}, 1), //带缓冲的通道,用于通知连接已准备好
beforeDial: testHookPrePendingDial,
afterDial: testHookPostPendingDial,
}
// ...此处省略代码...
//调用queueForIdleConn方法,将wantConn对象w排队等待可用的连接
if delivered := t.queueForIdleConn(w); delivered {
//从w.pc获取一个persistConn类型的对象 pc
pc := w.pc
// ...此处省略代码...
return pc, nil
}
//使用make函数创建了一个带有缓冲的 chan error 类型的通道 cancelc,缓冲区大小为 1,表示该通道可以缓冲一个 error 类型的值
cancelc := make(chan error, 1)
//调用 setReqCanceler 方法,将 treq.cancelKey 对应的取消函数设置为一个匿名函数,该函数将会向cancelc通道发送一个err值
t.setReqCanceler(treq.cancelKey, func(err error) { cancelc <- err })
//调用queueForDial发起新的连接请求。如果在等待期间获取到了空闲连接,会直接使用该连接,否则会等待queueForDial返回一个新连接或者错误
t.queueForDial(w)
//等待连接处理
select {
//监听连接就绪的 channel,当该 channel 接收到消息时,表示已经获取到了连接,并且连接处于就绪状态
case <-w.ready:
if w.err != nil {
// ...此处省略错误处理代码...
}
return w.pc, w.err
//监听请求取消的 channel,当该 channel 接收到消息时,表示请求已经被取消,此时返回 nil 连接和请求取消连接错误
case <-req.Cancel:
return nil, errRequestCanceledConn
//监听请求上下文结束的 channel,当该 channel 接收到消息时,表示请求上下文已经结束,此时返回 nil 连接和请求上下文错误
case <-req.Context().Done():
return nil, req.Context().Err()
//监听取消连接的 channel,当该 channel 接收到消息时,表示连接获取过程被取消,此时返回 nil 连接和取消连接错误
case err := <-cancelc:
if err == errRequestCanceled {
err = errRequestCanceledConn
}
return nil, err
}
}
按着惯例,总结流程:
- 使用
treq.Request.Context()获取当前请求的上下文信息ctx, - 创建一个
wantConn结构体w,并初始化它的各个字段 - 调用
http.Transport.queueForIdleConn在队列中等待闲置的连接,如果有空闲连接则返回,否则下一步 - 调用
http.Transport.queueForDial在队列中等待建立新的连接 - 在等待连接可用的过程中,通过
select语句监听多个信道的状态,包括:w.ready信道,当有连接可用时,会往该信道写入一个空结构体,从而唤醒当前请求。req.Cancel信道,当请求被取消时,会从该信道读到一个信号,此时应该取消正在进行的网络连接,并返回错误信息。req.Context().Done()信道,当请求的上下文被取消或者超时时,会从该信道读到一个信号,此时应该取消正在进行的网络连接,并返回错误信息。cancelc信道,当请求的上下文被取消或者超时时,同时已经有连接正在进行,则会从该信道读到一个信号,此时应该取消正在进行的网络连接,并返回错误信息。
对于 http.Transport.getConn 函数重点来分析下 persistConn结构体 以及 连接的获取的两种方式:http.Transport.queueForIdleConn 和 http.Transport.queueForDial。
http.persistConn
http.persistConn 结构体通过一些内部方法和属性来实现 HTTP 持久连接的管理,它的主要作用是管理 HTTP 持久连接,包括创建、维护和关闭连接等操作。在 http.TransportgetConn() 方法中作为一个返回值返回,代表获取的一个可用的连接对象。
persistConn结构体定义如下:
type persistConn struct {
alt RoundTripper //指向可选的 RoundTripper 接口的实现,用于处理当前持久连接中的所有请求和响应
t *Transport //指向当前持久连接所属的 Transport 对象
cacheKey connectMethodKey //表示当前持久连接对应的缓存键
conn net.Conn //表示当前持久连接使用的底层网络连接
tlsState *tls.ConnectionState //表示当前持久连接所使用的 TLS 连接状态
br *bufio.Reader //表示当前持久连接的读缓冲区
bw *bufio.Writer //表示当前持久连接的写缓冲区
nwrite int64 //表示自连接创建以来已经写入的字节数
reqch chan requestAndChan //用于传递请求和响应通道
writech chan writeRequest //用于传递写请求通道
closech chan struct{} //用于通知连接关闭的通道
isProxy bool //表示当前持久连接是否为代理连接
sawEOF bool //表示是否已经读到了连接的 EOF
readLimit int64 //表示读取数据的限制,即最大可读字节数
writeErrCh chan error //用于同步连接的写入过程
writeLoopDone chan struct{} //用于同步连接的写入过程
idleAt time.Time //表示连接空闲的时间
idleTimer *time.Timer //表示连接空闲的定时器
mu sync.Mutex
numExpectedResponses int //表示当前持久连接还有多少个响应没有被读取
closed error //表示当前持久连接的关闭状态
canceledErr error //表示连接已取消的错误
broken bool //表示连接是否已经损坏
reused bool //表示连接是否被复用表示连接是否被复用
mutateHeaderFunc func(Header) //用于修改请求头的函数
}
通过http.persistConn.writeLoop() 方法可以向该类型的连接对象写入数据,也可通过http.persistConn.readLoop() 方法可以从连接读取数据等等。它还有一些内部属性用于控制连接的行为,如 closech 用于关闭连接,isBroken 表示连接是否已经断开等等。
(*Transport).queueForIdleConn
http.Transport.queueForIdleConn 函数是 http.Transport 中的一个私有方法,用于从idleConn列表中获取一个空闲请求,如果获取不到则将请求添加到等待连接队列idleConnWait中,等待空闲连接的释放。代码如下:
func (t *Transport) queueForIdleConn(w *wantConn) (delivered bool) {
//如果禁止长连接就直接返回false
if t.DisableKeepAlives {
return false
}
//加锁
t.idleMu.Lock()
defer t.idleMu.Unlock()
t.closeIdle = false
if w == nil {
return false
}
//计算出来的旧时间值,用于判断空闲连接是否超时
var oldTime time.Time
if t.IdleConnTimeout > 0 {
oldTime = time.Now().Add(-t.IdleConnTimeout)
}
//循环从连接池中获取空闲连接列表
if list, ok := t.idleConn[w.key]; ok {
stop := false
delivered := false
//如果空闲连接列表大于0并且stop为false,则执行循环
for len(list) > 0 && !stop {
//获取链接列表最后一个值赋值给pconn
pconn := list[len(list)-1]
//tooold变量表示空闲超时情况,true代表超时
tooOld := !oldTime.IsZero() && pconn.idleAt.Round(0).Before(oldTime)
//如果空闲连接已经过期,则异步关闭空闲连接
if tooOld {
go pconn.closeConnIfStillIdle()
}
//如果空闲连接是否已经损坏或者已经过期,则从空闲连接列表中移除该连接,并继续检查下一个空闲连接
if pconn.isBroken() || tooOld {
list = list[:len(list)-1]
continue
}
//尝试将请求分配给当前空闲连接,并返回分配结果
delivered = w.tryDeliver(pconn, nil)
//如果请求已经成功分配给当前空闲连接,则将当前空闲连接从空闲连接列表中移除,同时更新 idleLRU 中的连接信息
//如果当前空闲连接是一个备用连接,则不需要从 idleLRU 中移除该连接
if delivered {
if pconn.alt != nil {
} else {
t.idleLRU.remove(pconn)
list = list[:len(list)-1]
}
}
//设置 stop 变量的值为 true,表示已经找到了可用的空闲连接,不需要再继续查找
stop = true
}
//判断空闲连接列表是否还有剩余连接
//如果有,则更新连接池中对应的空闲连接列表;否则直接从连接池中删除对应的空闲连接列表
if len(list) > 0 {
t.idleConn[w.key] = list
} else {
delete(t.idleConn, w.key)
}
//如果stop为true,返回delivered值
if stop {
return delivered
}
}
//检查 idleConnWait 是否为空,如果为空则创建一个新的 wantConnQueue 映射表
if t.idleConnWait == nil {
t.idleConnWait = make(map[connectMethodKey]wantConnQueue)
}
//获取当前请求对应的等待队列
q := t.idleConnWait[w.key]
//清空等待队列中已经超时的请求
q.cleanFront()
//将当前请求添加到等待队列的尾部
q.pushBack(w)
//更新等待队列
t.idleConnWait[w.key] = q
return false
}
基本流程可以总结为:
-
从
http.Transport中获取连接池(idleConn),如果连接池为空,直接返回 -
尝试从连接池(
idleConn)中获取一个空闲连接,如果成功获取到了空闲连接,将当前请求分配给该连接并返回true -
如果连接池中没有可用的空闲连接,则将当前请求添加到等待连接队列中(
idleConnWait)并返回false,表示当前请求没有分配到连接
整个流程的主要作用是在连接池中获取可用连接或将请求加入到等待队列中,等待连接池中的连接释放后再重新尝试获取可用连接。在高并发场景中,这样的等待机制可以有效地降低请求失败率和提高系统性能。
(*Transport).queueForDial
当使用http.Transport.queueForIdleConn 不能获取到一个空闲连接的时候,这时候使用 http.Transport.queueForDial 将请求加入等待队列,以等待连接可用。而如果 MaxConnsPerHost 不限制或者当前主机连接数没有达到 MaxConnsPerHost 设置数则可以直接创建一个新的连接。
http.Transport.queueForDial 代码如下:
func (t *Transport) queueForDial(w *wantConn) {
//在拨号之前对请求进行准备工作,例如设置代理等
w.beforeDial()
//如果同一主机上的连接数量不限制,则创建新的连接并将请求分配给该连接
if t.MaxConnsPerHost <= 0 {
go t.dialConnFor(w)
return
}
//加锁
t.connsPerHostMu.Lock()
defer t.connsPerHostMu.Unlock()
//如果当前同一个主机连接数小于最大连接数,则则创建新连接,并将请求分配给该连接
if n := t.connsPerHost[w.key]; n < t.MaxConnsPerHost {
if t.connsPerHost == nil {
t.connsPerHost = make(map[connectMethodKey]int)
}
//连接数+1
t.connsPerHost[w.key] = n + 1
//新建连接
go t.dialConnFor(w)
return
}
//判断 connsPerHostWait 是否为空,如果为空则说明还没有请求等待分配,因此需要先创建一个空的 connsPerHostWait map
if t.connsPerHostWait == nil {
t.connsPerHostWait = make(map[connectMethodKey]wantConnQueue)
}
//加入等待连接队列
q := t.connsPerHostWait[w.key]
//清空等待连接队列中已经超时的请求
q.cleanFront()
//将当前请求添加到等待连接队列的尾部
q.pushBack(w)
t.connsPerHostWait[w.key] = q
}
代码总结如下:
- 当同一个主机的连接数没有达到了
MaxConnsPerHost的上限或者主机连接数不限制的时候,直接创建新连接 - 当同一个主机的连接数已经达到了
MaxConnsPerHost的上限,无法创建新的连接时,请求需要加入connsPerHostWait等待队列中。当连接空闲时,等待队列中的请求将被唤醒,并分配到可用的连接上 - 如果等待队列已经存在,则将请求加入队列尾部;否则,先创建一个空的队列,并将请求加入队列尾部。最后将更新后的等待队列保存到
connsPerHostWaitmap 中
而在整个函数中,http.Transport.dialConnFor 创建新的连接至关重要的函数。
(*Transport).dialConnFor
http.Transport.dialConnFor 方法被用于在HTTP客户端中创建新的 TCP 连接。它的输入参数是一个指向wantConn类型的指针,其中wantConn是一个包含了一些连接属性的结构体类型。dialConnFor方法会根据wantConn中的属性创建一个新的TCP连接,并且在连接创建成功后会调用putOrCloseIdleConn方法将连接放入连接池中。
http.Transport.dialConnFor 函数以及关联函数的大致流程图如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JY37tj94-1680703730203)(https://xjxpicgo.oss-cn-hangzhou.aliyuncs.com/%E6%B5%81%E7%A8%8B%E5%9B%BE-%E5%AF%BC%E5%87%BA.jpg)]
http.Transport.dialConnFor 函数代码很简单,如下:
func (t *Transport) dialConnFor(w *wantConn) {
//在函数返回前执行 w.afterDial() 函数
defer w.afterDial()
// 发起连接
pc, err := t.dialConn(w.ctx, w.cm)
// 尝试将连接交付给请求
delivered := w.tryDeliver(pc, err)
// 如果连接未被交付或者是替代连接,则放入闲置连接池中
if err == nil && (!delivered || pc.alt != nil) {
t.putOrCloseIdleConn(pc)
}
// 如果连接发生错误,则将连接计数器减1
if err != nil {
t.decConnsPerHost(w.key)
}
}
代码就不多解释了,讲重点放在 http.Transport.dialConn 、http.Transport.putOrCloseIdleConn、http.Transport.decConnsPerHost、http.wantConn.tryDeliver中,逐一过一遍。
(*Transport).dialConn
http.Transport.dialConn 函数用于建立网络连接并返回一个 net.Conn 对象,该对象将被用于后续的HTTP请求和响应通信。
下面是该函数大致代码:
func (t *Transport) dialConn(ctx context.Context, cm connectMethod) (pconn *persistConn, err error) {
//创建一个连接对象
pconn = &persistConn{
t: t,
cacheKey: cm.key(),
reqch: make(chan requestAndChan, 1),
writech: make(chan writeRequest, 1),
closech: make(chan struct{}),
writeErrCh: make(chan error, 1),
writeLoopDone: make(chan struct{}),
}
// ...此处省略代码...
/**
检查连接方法的协议是否是https
1. 如果是,将连接器(pconn)的连接字段(conn)设置为自定义的TLS拨号器连接到目标地址的结果
2. 如果不是则跳过此逻辑
*/
if cm.scheme() == "https" && t.hasCustomTLSDialer() {
// ...此处省略代码...
} else {
//调用了 t.dial() 方法连接到服务器。如果连接成功,将连接赋值给 pconn.conn
conn, err := t.dial(ctx, "tcp", cm.addr())
if err != nil {
return nil, wrapErr(err)
}
pconn.conn = conn
//如果连接地址的协议是 HTTPS,则会调用 pconn.addTLS() 方法,为连接设置 TLS,以便进行加密通信
if cm.scheme() == "https" {
// ...此处省略代码...
}
}
//switch分支是处理代理相关的细节
switch {
case cm.proxyURL == nil: //不需要代理,不处理
case cm.proxyURL.Scheme == "socks5": //如果 proxyURL 的 scheme 为 "socks5",则需要通过 SOCKS5 代理连接目标地址
/** ...此处省略代码... */
case cm.targetScheme == "http": //如果连接目标的方案是HTTP,则说明要通过代理服务器建立连接
/** ...此处省略代码... */
case cm.targetScheme == "https": //当连接目标等于 "https" 时,会进行代理的建立
/** ...此处省略代码... */
}
//检查代理URL是否存在并且目标协议是否为HTTPS,如果是,则使用addTLS方法为pconn添加TLS配置,以便进行加密通信
if cm.proxyURL != nil && cm.targetScheme == "https" {
if err := pconn.addTLS(cm.tlsHost(), trace); err != nil {
return nil, err
}
}
//如果pconn的TLS握手协议是相互协商且协商后的协议不为空,则检查TLSNextProto字段是否存在这个协议的值
//如果存在,则调用该值的函数,并返回新的持久连接persistConn,以便进一步处理请求
if s := pconn.tlsState; s != nil && s.NegotiatedProtocolIsMutual && s.NegotiatedProtocol != "" {
if next, ok := t.TLSNextProto[s.NegotiatedProtocol]; ok {
alt := next(cm.targetAddr, pconn.conn.(*tls.Conn))
if e, ok := alt.(erringRoundTripper); ok {
return nil, e.RoundTripErr()
}
return &persistConn{t: t, cacheKey: pconn.cacheKey, alt: alt}, nil
}
}
//创建读写通道,pconn.br为读通道 pconn.bw为写通道
//启动读写协程,writeLoop用于写入,readLoop用于接收响应
//roundTrip函数中会通过chan给writeLoop发送 request,通过chan从readLoop接口response,每个连接都有一个readLoop和writeLoop,连接关闭后,这2个Loop也会退出。
//pconn.br给readLoop使用,pconn.bw给writeLoop使用,注意此时已经建立了tcp连接。
pconn.br = bufio.NewReaderSize(pconn, t.readBufferSize())
pconn.bw = bufio.NewWriterSize(persistConnWriter{pconn}, t.writeBufferSize())
go pconn.readLoop()
go pconn.writeLoop()
return pconn, nil
}
该函数主要有以下几个步骤:
- 使用
net.Dialer建立TCP连接,获取一个net.Conn对象pconn。 - 如果是
HTTPS连接,调用pconn.addTLS方法进行TLS握手,建立安全连接。 - 如果协商的协议支持
HTTP/2,调用t.dialConnH2方法建立HTTP/2连接。 - 否则,使用
HTTP/1.1持久连接,调用t.dialConnKeepAlive方法进行处理。 - 在建立
TCP连接之后,http.Transport.dialConn函数会返回一个persistConn对象,该对象实现了RoundTripper接口,可以处理HTTP请求和响应的发送和接收。同时,该函数还会启动两个goroutine分别处理persistConn对象的读取和写入操作。
(*wantConn).tryDeliver
http.wantConn.tryDeliver 函数用于向 http.Transport 中的 wantConn 发送 persistConn 或 error,以使等待中的请求可以获得一个可用连接或错误信息。
这个函数会尝试加锁并将 persistConn 或 error 赋值给 wantConn 中的 pc 和 err 字段,如果已经存在一个 persistConn 或 error,则函数直接返回 false。如果成功设置 pc 和 err,则关闭 ready 通道并返回 true,通知等待中的请求可以获取连接或错误信息。
代码如下:
func (w *wantConn) tryDeliver(pc *persistConn, err error) bool {
//加锁
w.mu.Lock()
defer w.mu.Unlock()
// 如果已经存在一个 persistConn 或 error,则返回 false
if w.pc != nil || w.err != nil {
return false
}
// 设置 persistConn 或 error,并关闭 ready 通道
w.pc = pc
w.err = err
if w.pc == nil && w.err == nil {
panic("net/http: internal error: misuse of tryDeliver")
}
close(w.ready)
return true
}
(*Transport).putOrCloseIdleConn
http.Transport.putOrCloseIdleConn 函数主要是调用 http.Transport.tryPutIdleConn函数,作用是尝试将一个空闲的 http.PersistentConn 连接加入到 http.Transport 的空闲连接池中。如果连接池已满或者空闲连接的超时时间已到,该连接会被关闭并从连接池中移除。
代码如下:
func (t *Transport) putOrCloseIdleConn(pconn *persistConn) {
if err := t.tryPutIdleConn(pconn); err != nil {
pconn.close(err)
}
}
func (t *Transport) tryPutIdleConn(pconn *persistConn) error {
//是否禁用了长连接(Keep-Alive)或最大空闲连接数小于0,如果是则返回一个errKeepAlivesDisabled错误
if t.DisableKeepAlives || t.MaxIdleConnsPerHost < 0 {
return errKeepAlivesDisabled
}
//检查该连接是否已经破坏。如果是,则返回 errConnBroken 错误
if pconn.isBroken() {
return errConnBroken
}
//标记该连接已经被复用过
pconn.markReused()
// 这里加锁,避免并发读写
t.idleMu.Lock()
defer t.idleMu.Unlock()
//如果 pconn.alt不为nil并且连接池中有这个 pconn,则不需要将其放回到连接池中,直接返回 nil
if pconn.alt != nil && t.idleLRU.m[pconn] != nil {
return nil
}
//等待队列中已经存在pconn连接,那么遍历等待队列,将其中所有等待请求尝试分配给pconn
key := pconn.cacheKey
if q, ok := t.idleConnWait[key]; ok {
done := false
/**
如果 pconn.alt == nil,则说明此时使用的是 HTTP/1.x 协议,因此,对于每个空闲连接的等待队列,只需要将第一个等待请求与该连接匹配,并尝试将连接传递给该请求,以便可以重用该连接;
如果 pconn.alt 不为 nil,则说明此连接在执行 HTTP/2 请求时被标记为闲置连接,而 HTTP/2 协议的流(stream)是由连接内部的处理程序来管理的,因此无法将连接直接传递给等待请求。
因此,在这种情况下,只需要循环遍历所有等待队列,并将连接传递给每个等待请求,以便可以重用该连接。
*/
if pconn.alt == nil {
for q.len() > 0 {
w := q.popFront()
if w.tryDeliver(pconn, nil) {
done = true
break
}
}
} else {
for q.len() > 0 {
w := q.popFront()
w.tryDeliver(pconn, nil)
}
}
/**
如果空闲连接等待队列为空,则从 HTTP Transport 的空闲连接等待队列中删除此 key
否则,将空闲连接等待队列中剩余的 wantConn 再次放回队列中
*/
if q.len() == 0 {
delete(t.idleConnWait, key)
} else {
t.idleConnWait[key] = q
}
//如果成功分配了连接,则返回 nil,否则继续执行
if done {
return nil
}
}
/**
这段代码用于判断当前是否允许将连接放入空闲连接池中。
如果连接的空闲数量已经达到上限,则返回errTooManyIdleHost,表示已达到空闲连接数的最大上限;
如果空闲连接池为空,则初始化空闲连接池;
之后检查是否存在重复的空闲连接,如果出现重复连接,使用log.Fatalf输出日志,说明当前代码的实现出现了错误
*/
if t.closeIdle {
return errCloseIdle
}
if t.idleConn == nil {
t.idleConn = make(map[connectMethodKey][]*persistConn)
}
idles := t.idleConn[key]
if len(idles) >= t.maxIdleConnsPerHost() {
return errTooManyIdleHost
}
for _, exist := range idles {
if exist == pconn {
log.Fatalf("dup idle pconn %p in freelist", pconn)
}
}
//将连接存入空闲连接池中
t.idleConn[key] = append(idles, pconn)
t.idleLRU.add(pconn)
//判断当前空闲连接的数量是否已经超过了最大的空闲连接数,如果超过了则会把最旧的空闲连接移除掉,同时关闭这个连接并从缓存中删除
if t.MaxIdleConns != 0 && t.idleLRU.len() > t.MaxIdleConns {
oldest := t.idleLRU.removeOldest()
oldest.close(errTooManyIdle)
t.removeIdleConnLocked(oldest)
}
//判断检查这个连接是否设置了空闲超时时间,如果设置了,则会开启一个定时器,到达超时时间后会自动关闭这个连接
if t.IdleConnTimeout > 0 && pconn.alt == nil {
if pconn.idleTimer != nil {
pconn.idleTimer.Reset(t.IdleConnTimeout)
} else {
pconn.idleTimer = time.AfterFunc(t.IdleConnTimeout, pconn.closeConnIfStillIdle)
}
}
//将 pconn 的 idleAt 字段设置为当前时间,表示该连接的最后活跃时间为当前时间,用于之后连接空闲超时的判断
pconn.idleAt = time.Now()
return nil
}
具体来说,该函数会进行以下操作:
-
检查当前
http.Transport是否禁用了长连接或者每个主机的最大空闲连接数小于 0,如果是则返回errKeepAlivesDisabled。 -
检查当前连接是否已经损坏,如果是则返回
errConnBroken。 -
根据
http.PersistentConn的alt字段是否为空判断当前连接是否是一个闲置连接(即没有被升级为http2.Transport的连接),如果是,则:
- 检查连接池中是否已经存在相同的连接,如果是则直接返回。
- 检查连接池中空闲连接的数量是否已经达到了该主机的最大空闲连接数,如果是则返回
errTooManyIdleHost。 - 检查连接池中是否已经存在当前连接,如果是则记录错误日志并终止程序。
- 将当前连接加入到连接池中,记录连接的闲置时间,并启动一个定时器,如果在指定的空闲时间内没有被重用,则将该连接从连接池中移除。
-
如果当前连接是一个已经被升级为
http2.Transport的连接,则:- 检查该连接是否已经被关闭,如果是则返回。
- 将该连接标记为已被重用,但不会将其加入到连接池中,因为
http2.Transport不使用空闲连接池。
总之,http.Transport.tryPutIdleConn 函数主要是用来管理 http.PersistentConn 的空闲连接池,并确保连接的重用和闲置连接的及时清理。
(*Transport).decConnsPerHost
http.Transport.decConnsPerHost 函数用于在连接闲置或关闭时,将与特定主机和端口组合的连接计数器减一。
代码如下:
func (t *Transport) decConnsPerHost(key connectMethodKey) {
if t.MaxConnsPerHost <= 0 {
return
}
//加锁
t.connsPerHostMu.Lock()
defer t.connsPerHostMu.Unlock()
// 获取当前主机连接数
n := t.connsPerHost[key]
if n == 0 {
panic("net/http: internal error: connCount underflow")
}
// 如果有等待队列,则处理等待队列中的请求
if q := t.connsPerHostWait[key]; q.len() > 0 {
done := false
for q.len() > 0 {
w := q.popFront()
if w.waiting() {
go t.dialConnFor(w) // 为等待队列中的请求创建新连接
done = true
break
}
}
// 如果当前等待队列为0,则删除该主机的等待队列
if q.len() == 0 {
delete(t.connsPerHostWait, key)
} else {
t.connsPerHostWait[key] = q
}
if done {
return
}
}
// 如果当前连接数减1后为0,则删除该主机的连接计数记录
if n--; n == 0 {
delete(t.connsPerHost, key)
} else {
t.connsPerHost[key] = n
}
}
具体来说,该函数实现了以下操作:
- 如果
MaxConnsPerHost为 0,则不执行任何操作。 - 获取锁
connsPerHostMu。 - 从连接计数器
connsPerHost中获取与指定主机和端口组合的当前连接数n。 - 如果当前连接数
n已经为 0,则出现内部错误(应该不可能)。 - 检查是否有等待连接的请求,如果有则处理第一个等待请求(创建新连接),并返回。
- 如果当前连接数
n减一后为 0,则从计数器connsPerHost中删除该主机和端口组合。 - 否则将更新后的连接数
n保存回connsPerHost中。 - 释放锁
connsPerHostMu。
(*persistConn).roundTrip
roundTrip 方法是 http1.1 请求的核心之一,该方法在这里获取真实的 Response 并返回给上层。
而 http.persistConn.roundTrip是用于在持久连接上执行一次 HTTP 请求,并返回响应结果。
该函数以及关联函数的相关流程图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e8DGcp8O-1680703730204)(https://xjxpicgo.oss-cn-hangzhou.aliyuncs.com/%E5%87%BD%E6%95%B01%E6%B5%81%E7%A8%8B-%E5%AF%BC%E5%87%BA.jpg)]
源码如下:
func (pc *persistConn) roundTrip(req *transportRequest) (resp *Response, err error) {
//调用replaceReqCanceler来探测Request是否已经触发了删除行为,如果是,就把persistConn放入putOrCloseIdleConn中处理
if !pc.t.replaceReqCanceler(req.cancelKey, pc.cancelRequest) {
pc.t.putOrCloseIdleConn(pc)
return nil, errRequestCanceled
}
//加锁
pc.mu.Lock()
//期望接收到的HTTP响应的数量+1
pc.numExpectedResponses++
headerFn := pc.mutateHeaderFunc
pc.mu.Unlock()
//如果headerFn不为空,则执行headerFn
if headerFn != nil {
headerFn(req.extraHeaders())
}
/**
如果DisableCompression未被设置为 true,请求头中不包含 Accept-Encoding 和 Range 字段,并且请求方法不是 HEAD
则会在请求头中添加 Accept-Encoding 字段,值为 "gzip",表示可以接受 Gzip 压缩的响应
*/
requestedGzip := false
if !pc.t.DisableCompression &&
req.Header.Get("Accept-Encoding") == "" &&
req.Header.Get("Range") == "" &&
req.Method != "HEAD" {
requestedGzip = true
req.extraHeaders().Set("Accept-Encoding", "gzip")
}
//用于处理 HTTP 请求中的 Expect 请求头字段。
//当请求头中包含 Expect: 100-continue 且使用的 HTTP 版本是 1.1 或以上,同时还需要有请求体 req.Body,则会创建一个 continueCh 的无缓冲的通道,以等待服务器返回 100 Continue 响应
var continueCh chan struct{}
if req.ProtoAtLeast(1, 1) && req.Body != nil && req.expectsContinue() {
continueCh = make(chan struct{}, 1)
}
// HTTP1.1默认使用长连接,当transport设置DisableKeepAlives时会导致处理每个request时都会 新建一个连接。
// 此处的处理逻辑是:如果transport设置了DisableKeepAlives,而request没有设置 "Connection: close",则为request设置该首部。将底层表现与上层协议保持一致。
if pc.t.DisableKeepAlives &&
!req.wantsClose() &&
!isProtocolSwitchHeader(req.Header) {
req.extraHeaders().Set("Connection", "close")
}
//创建gone通道,作用是在后续处理中通知当前 goroutine 已经结束
gone := make(chan struct{})
/**
当函数执行结束前,做一些清理工作:
1. 使用 close() 函数关闭 gone 通道;
2. 如果函数返回了错误 err,则设置 req.cancelKey 的请求取消器为 nil
*/
defer close(gone)
defer func() {
if err != nil {
pc.t.setReqCanceler(req.cancelKey, nil)
}
}()
const debugRoundTrip = false
//表示发送了多少个字节的request
startBytesWritten := pc.nwrite
//将请求通过writeRequest结构体封装,并将其发送到连接的writech通道中,等待连接将请求写入网络连接
writeErrCh := make(chan error, 1)
pc.writech <- writeRequest{req, writeErrCh, continueCh}
//将请求通过requestAndChan结构体封装,并将其发送到连接的reqch通道中,等待连接收到响应
resc := make(chan responseAndError)
pc.reqch <- requestAndChan{
req: req.Request,
cancelKey: req.cancelKey,
ch: resc,
addedGzip: requestedGzip,
continueCh: continueCh,
callerGone: gone,
}
//一个类型为 <-chan time.Time 的 channel,它被用于在超时时刻取消一个正在进行的HTTP请求
var respHeaderTimer <-chan time.Time
//是一个 channel,用于在取消一个 HTTP 请求时通知客户端
cancelChan := req.Request.Cancel
//是一个 channel,用于在请求的上下文被取消时通知客户端
ctxDoneChan := req.Context().Done()
//是一个 channel,用于在 HTTP 持久连接被关闭时通知客户端
pcClosed := pc.closech
//表示 HTTP 请求是否已被取消
canceled := false
// 该循环主要用于处理获取response超时和request取消时的条件跳转。正常情况下收到reponse
for {
select {
//当从 writeErrCh 通道接收到错误时
case err := <-writeErrCh:
if err != nil {
pc.close(fmt.Errorf("write error: %v", err))
return nil, pc.mapRoundTripError(req, startBytesWritten, err)
}
//如果连接处于可用状态并且已经设置了响应头超时时间(pc.t.ResponseHeaderTimeout 大于 0),则会创建一个计时器并将其传递给 respHeaderTimer 变量
//计时器将在响应头读取完成后超时,以防止读取响应体时出现死锁情况
if d := pc.t.ResponseHeaderTimeout; d > 0 {
if debugRoundTrip {
req.logf("starting timer for %v", d)
}
timer := time.NewTimer(d)
defer timer.Stop() // prevent leaks
respHeaderTimer = timer.C
}
//处理底层连接关闭
case <-pcClosed:
//如果连接被取消或者replaceReqCanceler返回true,就会返回一个与连接关闭相关的错误,否则继续等待连接关闭
//这个逻辑主要是为了确保返回的错误与连接关闭有关,并避免在连接关闭之前返回错误
pcClosed = nil
if canceled || pc.t.replaceReqCanceler(req.cancelKey, nil) {
if debugRoundTrip {
req.logf("closech recv: %T %#v", pc.closed, pc.closed)
}
return nil, pc.mapRoundTripError(req, startBytesWritten, pc.closed)
}
// 等待获取response超时,关闭连接
case <-respHeaderTimer:
if debugRoundTrip {
req.logf("timeout waiting for response headers.")
}
pc.close(errTimeout)
return nil, errTimeout
// 接收到readLoop返回的response结果
case re := <-resc:
if (re.res == nil) == (re.err == nil) {
panic(fmt.Sprintf("internal error: exactly one of res or err should be set; nil=%v", re.res == nil))
}
if debugRoundTrip {
req.logf("resc recv: %p, %T/%#v", re.res, re.err, re.err)
}
if re.err != nil {
return nil, pc.mapRoundTripError(req, startBytesWritten, re.err)
}
return re.res, nil
// request取消
case <-cancelChan:
//将关闭之后的chan置为nil,用来防止select一直进入该case(close的chan不会阻塞读,读取的数据为0)
canceled = pc.t.cancelRequest(req.cancelKey, errRequestCanceled)
cancelChan = nil
//当请求的上下文被取消时,会触发这个分支
case <-ctxDoneChan:
//调用 Transport.cancelRequest 函数,将该请求对应的 canceler 标记为取消状态
//然后将 cancelChan 和 ctxDoneChan 置为 nil。同时,将 canceled 置为 true
canceled = pc.t.cancelRequest(req.cancelKey, req.Context().Err())
cancelChan = nil
ctxDoneChan = nil
}
}
}
函数大致流程为:
- 如果请求中需要
gzip压缩,则添加Accept-Encoding: gzip请求头。 - 如果请求中需要
Expect: 100-continue,则发送请求前先发送一个包含该头部的空请求体,等待服务器的确认,确认后再发送实际请求。 - 将请求通过
writech发送到连接中,如果写入失败,直接返回错误。 - 等待响应,如果设置了
ResponseHeaderTimeout则会启动定时器,等待超时时间内得到服务器响应头部,超时则直接返回错误。 - 等待连接的读取协程将响应体读取完成,并将响应传递给
resc通道。 - 如果收到
resc通道传来的响应体,则将其返回给上层调用者。如果收到cancelChan或ctxDoneChan通道传来的信号,则主动关闭连接,返回错误信息。
总体来说,roundTrip 方法实现了从请求发送到响应接收的整个过程,包括处理请求头部、请求体,发送请求,接收响应等。如果在任何阶段出现错误,则直接返回错误信息。
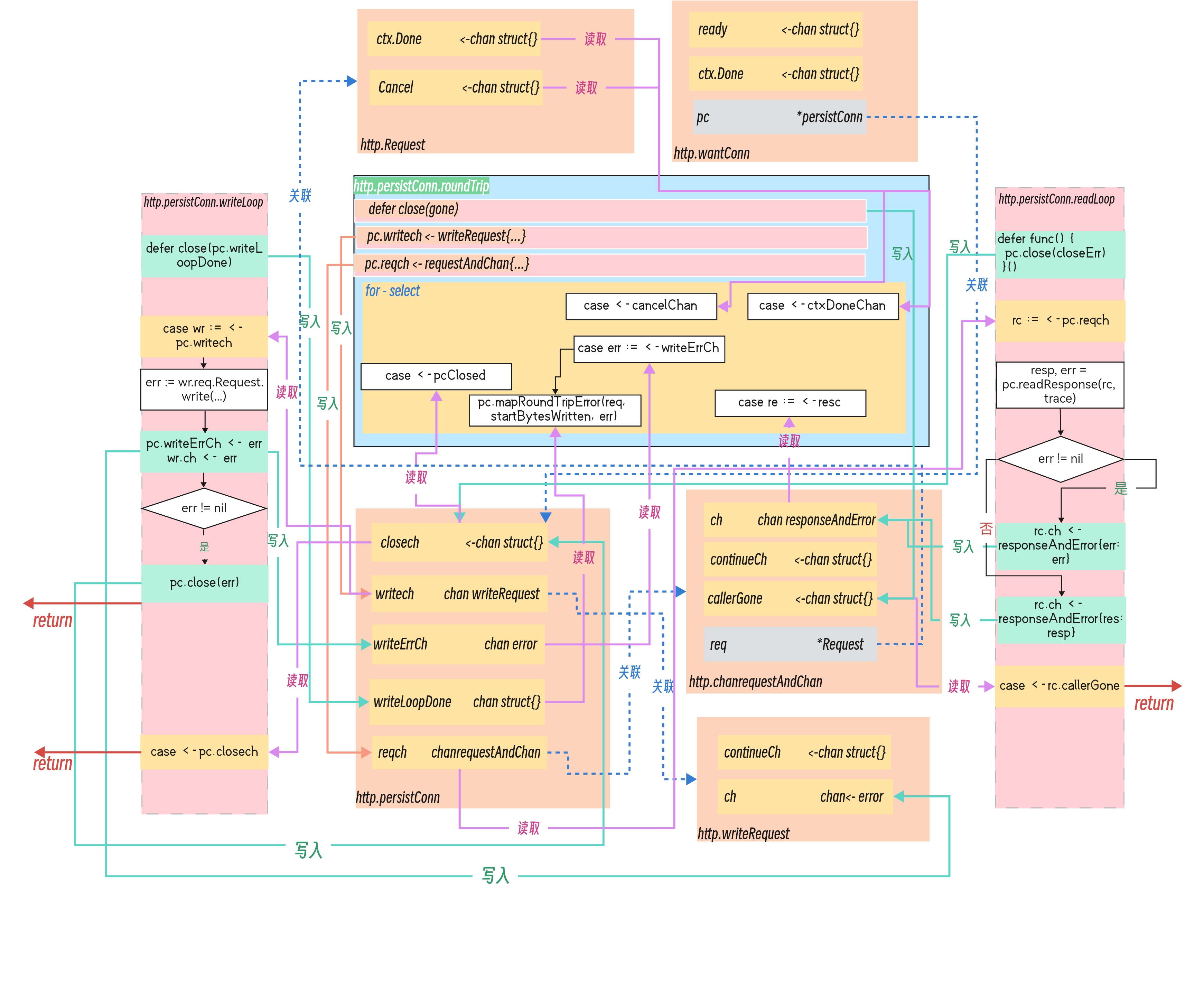
而在这个关键的roundTrip 方法中,写入writech管道的数据则会都由一个 Goroutine 中的 http.persistConn.writeLoop循环写入的,而http.persistConn.readLoop循环接收response响应,成功获得response后会将连接返回连接池,便于后续复用。当readLoop正常处理完一个response之后,会将连接重新放入到连接池中;当readloop退出后,该连接会被关闭移除。
(*persistConn).writeLoop
该函数是persistConn结构体的一个方法,主要作用是用于维护HTTP的长连接,通过不断地接收来自writech通道的请求,在长连接上发送请求,并将发送结果发送回writeErrCh通道和requestAndChan中的ch通道。
该函数大致流程图如下:

http.persistConn.writeLoop代码如下:
func (pc *persistConn) writeLoop() {
//当该函数结束时,关闭pc.writeLoopDone通道
defer close(pc.writeLoopDone)
for {
select {
//从writech通道接收一个请求
case wr := <-pc.writech:
//记录当前的起始写入字节数
startBytesWritten := pc.nwrite
//构造request并发送request请求。waitForContinue用于处理首部含"Expect: 100-continue"的request
err := wr.req.Request.write(pc.bw, pc.isProxy, wr.req.extra, pc.waitForContinue(wr.continueCh))
//如果err是一个requestBodyReadError类型的错误
//则将err修改为其内部错误,将请求的err字段设置为err
if bre, ok := err.(requestBodyReadError); ok {
err = bre.error
wr.req.setError(err)
}
//将缓冲区中的数据写入连接中
if err == nil {
err = pc.bw.Flush()
}
if err != nil {
//如果当前写入的字节数与开始写入时的字节数相同,则将err包装成nothingWrittenError类型的错误
if pc.nwrite == startBytesWritten {
err = nothingWrittenError{err}
}
}
//将错误信息发送到writeErrCh通道
pc.writeErrCh <- err
//将错误信息发送到ch通道
wr.ch <- err
//如果有错误,关闭连接
if err != nil {
pc.close(err)
return
}
//从closech通道接收到关闭请求,直接return
case <-pc.closech:
return
}
}
}
当我们调用 http.Request.write 向请求中写入数据时,实际上直接写入了 http.persistConnWriter 中的 TCP 连接中,TCP 协议栈会负责将 HTTP 请求中的内容发送到目标服务器上:
func (t *Transport) dialConn(ctx context.Context, cm connectMethod) (pconn *persistConn, err error) {
......
pconn.bw = bufio.NewWriterSize(persistConnWriter{pconn}, t.writeBufferSize())
......
}
type persistConnWriter struct {
pc *persistConn
}
func (w persistConnWriter) Write(p []byte) (n int, err error) {
n, err = w.pc.conn.Write(p)
w.pc.nwrite += int64(n)
return
}
(*persistConn).readLoop
readLoop函数是用来处理HTTP请求的核心部分之一。该函数的主要作用是从连接中读取数据,并将其转换为HTTP请求。
具体来说,readLoop函数会首先从连接中读取请求行,即HTTP请求中的方法、URL和协议版本等信息。然后,它会解析请求头部,以获取其他关键信息,如Content-Length(如果请求体存在)和Cookie等。接下来,如果请求体存在,则会从连接中读取请求体,并将其存储到缓冲区中。
读取完成后,readLoop函数会将请求交给处理器处理,并将响应写回到连接中。如果在读取或处理请求时发生错误,则readLoop函数将关闭连接。
下图为该函数以及关联函数的主要流程:
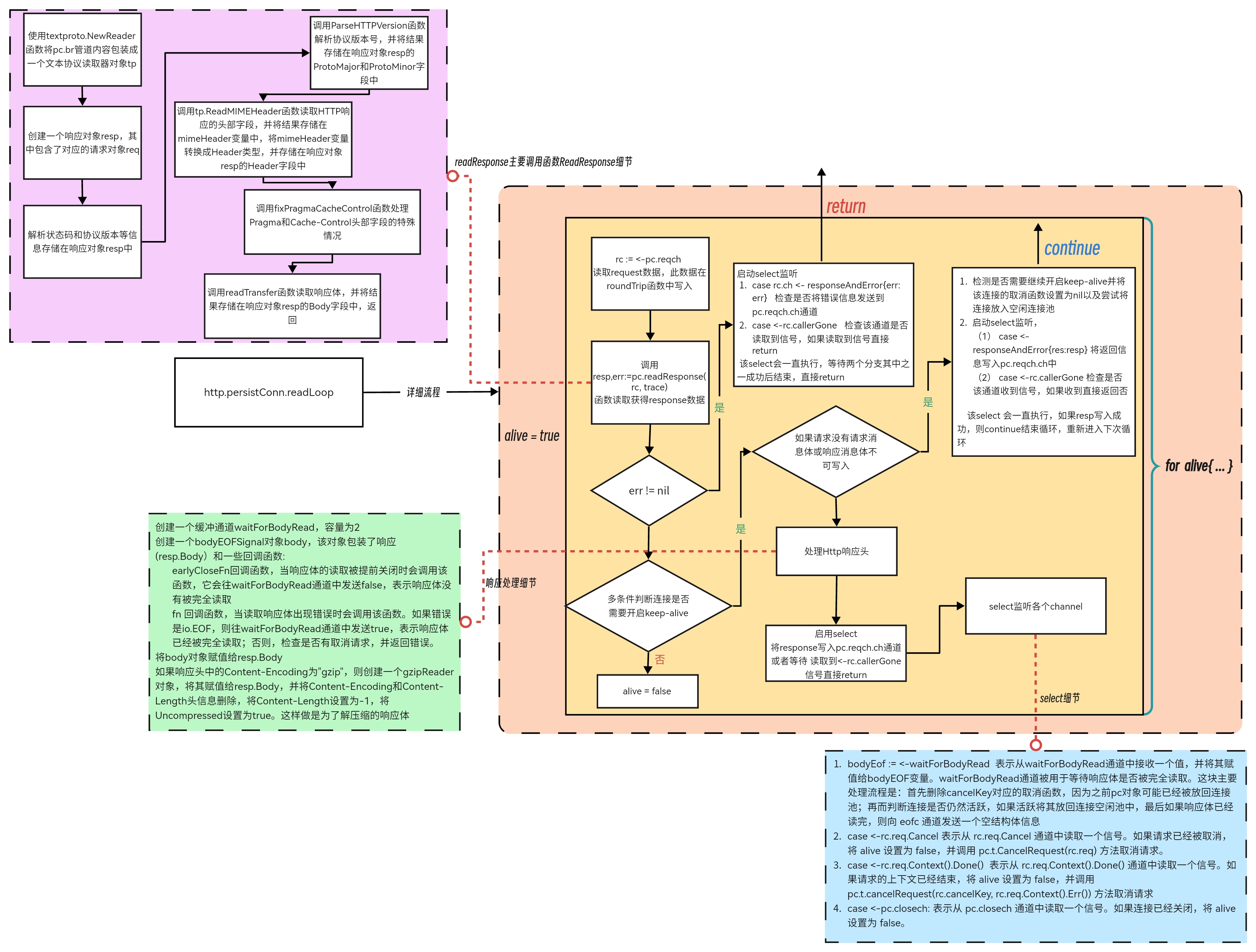
下面为该函数的源码,经过精简,梳理主要逻辑为:
func (pc *persistConn) readLoop() {
// ......省略代码
alive := true
for alive {
rc := <-pc.reqch //读取request,此数据在roundTrip函数中写入
resp, err = pc.readResponse(rc, trace) //返回response
//response的body是否可写,服务器code101才可写,所以正常这个是false
bodyWritable := resp.bodyIsWritable()
//response.Close设置循环结束,退出协程
if resp.Close || rc.req.Close || resp.StatusCode <= 199 || bodyWritable {
alive = false
}
//把response写入通道,在roundTrip函数中会监听此channel
select {
case rc.ch <- responseAndError{res: resp}:
case <-rc.callerGone:
return
}
//循环结束的一些情况
select {
case bodyEOF := <-waitForBodyRead: //读完body也会自动结束
case <-rc.req.Cancel:
case <-rc.req.Context().Done():
case <-pc.closech:
alive = false
pc.t.CancelRequest(rc.req)
}
}
持久连接中的另一个读循环 http.persistConn.readLoop 会负责从 TCP 连接中读取数据并将数据发送会 HTTP 请求的调用方,真正负责解析 HTTP 协议的还是 http.ReadResponse:
func ReadResponse(r *bufio.Reader, req *Request) (*Response, error) {
//使用textproto.NewReader函数将输入流r包装成一个文本协议读取器对象tp, 可以处理HTTP, NNTP, SMTP协议的内容,方便读取
tp := textproto.NewReader(r)
//创建一个响应对象resp,其中包含了对应的请求对象req
resp := &Response{
Request: req,
}
//调用tp.ReadLine()函数读取输入流的第一行
line, err := tp.ReadLine()
//如果读取出错,会先判断错误类型是否为io.EOF(表示已到达文件末尾),如果是则将err赋值为io.ErrUnexpectedEOF(表示读取到了意外的文件末尾),然后返回nil和err
if err != nil {
if err == io.EOF {
err = io.ErrUnexpectedEOF
}
return nil, err
}
//使用strings.Cut函数将line字符串按照空格分割成两个部分,分别为协议版本和状态码
proto, status, ok := strings.Cut(line, " ")
if !ok {
return nil, badStringError("malformed HTTP response", line)
}
//将解析出来的状态码和协议版本等信息存储在响应对象resp中
resp.Proto = proto
resp.Status = strings.TrimLeft(status, " ")
//使用strings.Cut函数将响应对象resp的状态码字符串按照空格分割为协议版本和状态码两个部分
statusCode, _, _ := strings.Cut(resp.Status, " ")
//判断状态码字符串的长度是否为3。如果长度不为3,则返回一个错误,表示读取到了格式错误的HTTP状态码
if len(statusCode) != 3 {
return nil, badStringError("malformed HTTP status code", statusCode)
}
//将statusCode赋值给resp
resp.StatusCode, err = strconv.Atoi(statusCode)
if err != nil || resp.StatusCode < 0 {
return nil, badStringError("malformed HTTP status code", statusCode)
}
//调用ParseHTTPVersion函数解析协议版本号,并将结果存储在响应对象resp的ProtoMajor和ProtoMinor字段中
//如果解析失败,则返回一个错误,表示读取到了格式错误的HTTP协议版本号
if resp.ProtoMajor, resp.ProtoMinor, ok = ParseHTTPVersion(resp.Proto); !ok {
return nil, badStringError("malformed HTTP version", resp.Proto)
}
//调用tp.ReadMIMEHeader函数读取HTTP响应的头部字段,并将结果存储在mimeHeader变量中
mimeHeader, err := tp.ReadMIMEHeader()
//如果读取出错,会先判断错误类型是否为io.EOF(表示已到达文件末尾),如果是则将err赋值为io.ErrUnexpectedEOF(表示读取到了意外的文件末尾),然后返回nil和err
if err != nil {
if err == io.EOF {
err = io.ErrUnexpectedEOF
}
return nil, err
}
//将mimeHeader变量转换成Header类型,并存储在响应对象resp的Header字段中
resp.Header = Header(mimeHeader)
//调用fixPragmaCacheControl函数处理Pragma和Cache-Control头部字段的特殊情况
fixPragmaCacheControl(resp.Header)
//调用readTransfer函数读取响应体,并将结果存储在响应对象resp的Body字段中
err = readTransfer(resp, r)
if err != nil {
return nil, err
}
return resp, nil
}
我们在上述方法中可以看到 HTTP 响应结构的大致框架,其中包含状态码、协议版本、请求头等内容,响应体还是在读取循环 ç中根据 HTTP 协议头进行解析的。
最后一个图来结尾,总结下 http.persistConn.readLoop 、http.persistConn.writeLoop、http.persistConn.roundTrip之间的channel关系:
参考资料:
chatGPT https://chat.openai.com/
施主画个猿 https://www.jianshu.com/p/18d7b0c08393
AllardZhao https://blog.csdn.net/qq_37189082/article/details/98642450
draveness https://draveness.me/golang/docs/part4-advanced/ch09-stdlib/golang-net-http/
Gopher指北 https://xie.infoq.cn/article/6107cc8ccba566d1bcb4b2159















 206
206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









