










前置理论
巧用映射
来看一个例子, 给定一个数组数据: [30, 5, 10, 13, 18, 100, 999, 22, 29], 求该组数据中是否有元素100
首先我们来分析一下从一组数据中查找某个元素的效率:
- 如果顺序查找,则需要从头开始查找,时间复杂度为
O(N); - 如果使用
BST(二叉搜索树)进行查找,时间复杂度也为O(log N);
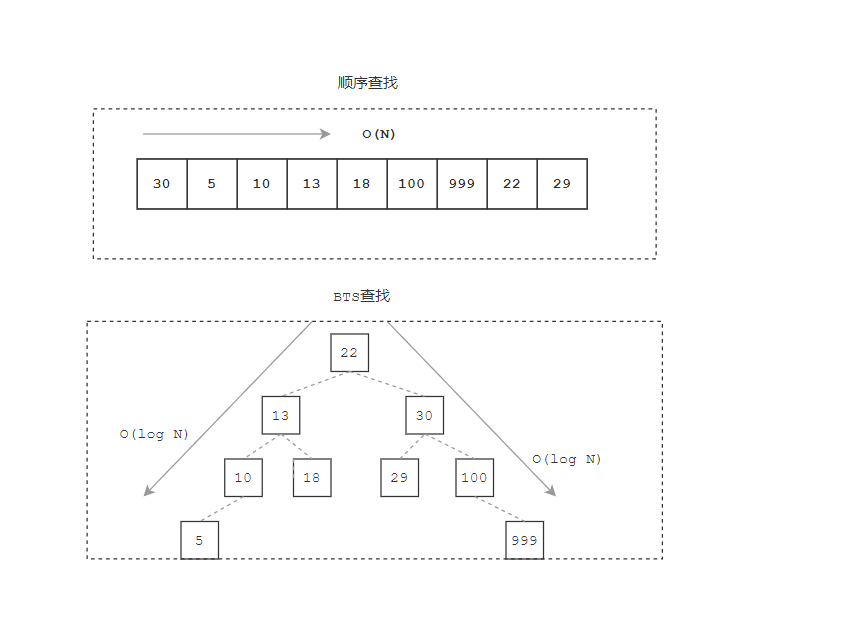
那么有没有一种方法使查找效率更高呢?
我们的一种思路是这样的:
-
创建一个以数组最大值作为长度的的数组
temp; -
以原数组中值作为数组
temp的键值 -
最后查找哪个元素是否存在就直接返回
temp数组中该索引下标位置即可
实现代码如下:
func main() {
arr := []int{30, 5, 10, 13, 18, 100, 999, 22, 29}
var temp [1000]bool
for i := 0; i < len(arr); i++ {
temp[arr[i]] = true
}
fmt.Println(temp[100])
}
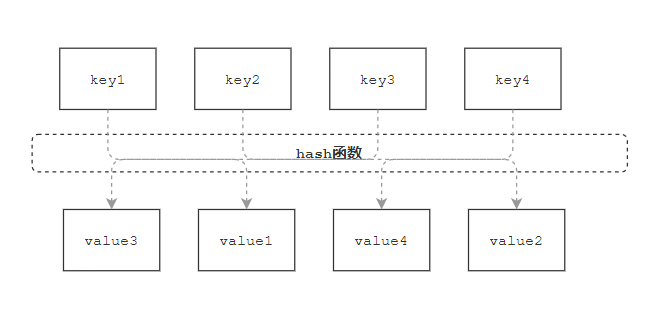
这边我们巧妙借助了数组的索引下标,直接返回某元素对应的索引下标值即可,于是我们想到构造一种存储结构,使元素的存储位置与它的关键码之间能够建立一一映射的关系,这样依据存储位置直接便查找到了该元素。
这就是哈希表(hashmap)的最原始思路。哈希表实则就是由数组衍生而来的,借助数组的随机访问性,由索引下标即可快速查找,使得哈希表的查找操作时间复杂度可为O(1),大大提高了效率,是典型的用空间换时间。
哈希函数
对于哈希表的最原始思路,有很多不足,例如:
- 对于元素分散的数据,直接元素数据对应索引下标必然会带来很多空间浪费,例如前面的例子中数据:
[]int{30, 5, 10, 13, 18, 100, 999, 22, 29}, 只有9个数据足足浪费了1000个数组空间 - 对于非数字类型的数据,实现起来不够友好,稳定性也不足
因为 哈希函数 便是解决这些不足的办法。
哈希函数 指将哈希表中元素的关键键值映射为元素存储位置的函数。
实现哈希表的关键点在于哈希函数的选择,哈希函数的选择在很大程度上能够决定哈希表的读写性能。在理想情况下,哈希函数应该能够将不同键映射到不同的索引上,这要求哈希函数的输出范围大于输入范围,但是由于键的数量会远远大于映射的范围,所以在实际使用时,这个理想的效果是不可能实现的。
比较实际的方式是让哈希函数的结果能够尽可能的均匀分布,然后通过工程上的手段解决哈希碰撞的问题。哈希函数映射的结果一定要尽可能均匀,结果不均匀的哈希函数会带来更多的哈希冲突以及更差的读写性能。
如果使用结果分布较为均匀的哈希函数,那么哈希的增删改查的时间复杂度为 O(1);但是如果哈希函数的结果分布不均匀,那么所有操作的时间复杂度可能会达到 O(n),由此看来,使用好的哈希函数是至关重要的。
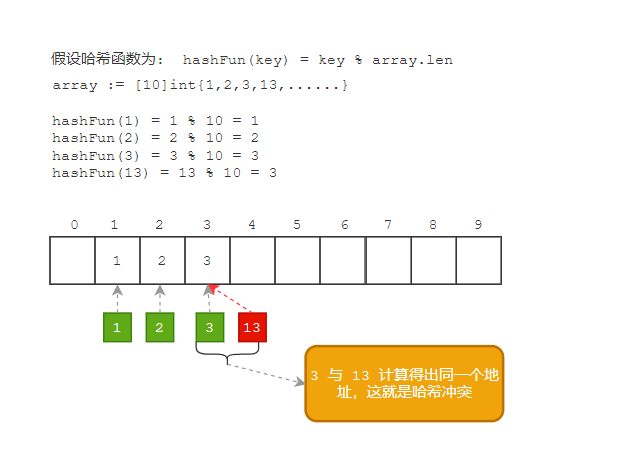
实现哈希表底层的数据结构就是数组,不过因为数组的长度有限(假设长度为m), 向哈希表写入这个键值对时会计算出该键值应该存入数组[0 ~ m-1]的哪个索引中,最常见的计算方式是如下两种:
-
取模法
取模法就是用
hash值与存储数组长度m进行取模得到一个存储数组的编号,公式:hash % m -
与运算法
与运算法就是用
hash值与存储数组长度减一 ,即m-1进行与运算,得到一个存储的编号,公式为:hash & (m-1); 若想确保结果落在[0,m-1]之间,就要限制数组长度m必须为2的整数次幂,否则将出现某些索引永远不会被选用。如图所示:
哈希冲突
Hash冲突 指的是在向Hash表中存数据时,首先要用Hash函数计算出该数据要存放的地址。但是在这个地址中已经有值存在,所以这个时候就发生了Hash冲突。也就是一句话:key值不同的元素可能会映象到哈希表的同一地址上。哈希冲突如下图:
一般Hash冲突解决有两大类方法:
-
开放寻址法(闭散列)
开放地址法也叫做闭散列,当发生哈希冲突的时候,如果哈希表未被填满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置的"下一个"空位置中去,寻找下一个空位置的方法有线性探测法 和 二次探测法。
-
线性探测法
从发生冲突的位置开始,依次向后探测,直到寻找到下一个位置为止。
优点:实现非常简单
缺点:一旦发生哈希冲突,所有的冲突连在一起,容易产生数据"堆积",即不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要进行多次比较,导致搜索效率降低。
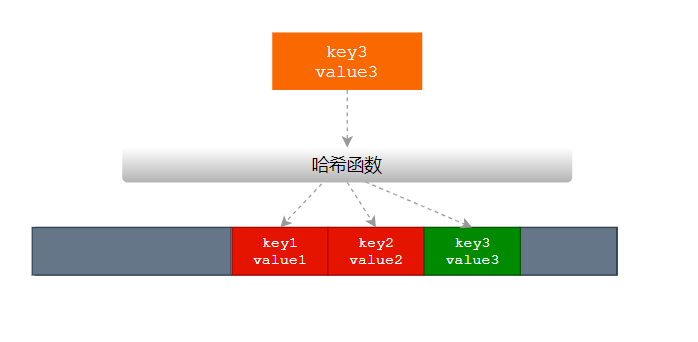
如上图,当
Key3与已经存入哈希表中的两个键值对Key1和Key2发生冲突时,Key3会被写入Key2后面的空闲位置。当我们再去读取Key3对应的值时就会先获取键的哈希并取模,这会先帮助我们找到Key1,找到Key1后发现它与Key 3不相等,所以会继续查找后面的元素,直到内存为空或者找到目标元素。 -
二次探测法
线性探测的缺陷是产生哈希冲突,容易导致冲突的数据堆积在一起,这是因为线性探测是逐个的找下一个空位置。
二次探测为了缓解这种问题(不是解决),对下一个空位置的查找进行了改进(跳跃式查找):
hash(key) = (hash(key)+i^2^)%m,如图:
-
-
拉链法(开散列)
与开放地址法相比,拉链法是哈希表中最常见的实现方法,大多数的编程语言都是用拉链法实现哈希表,它的实现相对比较简单,平均查找的长度也比较短,而且各个用于存储节点的内存都是动态申请的,可以节省比较多的存储空间。
实现拉链法一般会使用数组加上链表,不过一些编程语言会在拉链法的哈希中引入红黑树以优化性能,拉链法会使用链表数组作为哈希底层的数据结构:
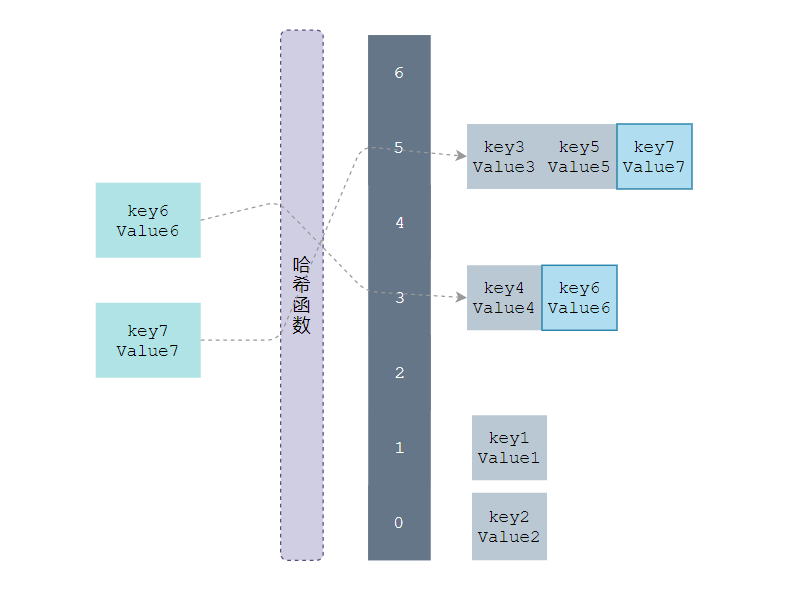
如上图所示,当我们需要将一个键值对 (Key6, Value6) 写入哈希表时,键值对中的键 Key6 都会先经过一个哈希函数,哈希函数返回的哈希会帮助我们选择一个桶,和开放地址法一样,选择桶的方式是直接对哈希返回的结果取模,选择了3 号桶后就可以遍历当前桶中的链表了,在遍历链表的过程中会遇到以下两种情况:
- 找到键相同的键值对 — 更新键对应的值;
- 没有找到键相同的键值对 — 在链表的末尾追加新的键值对
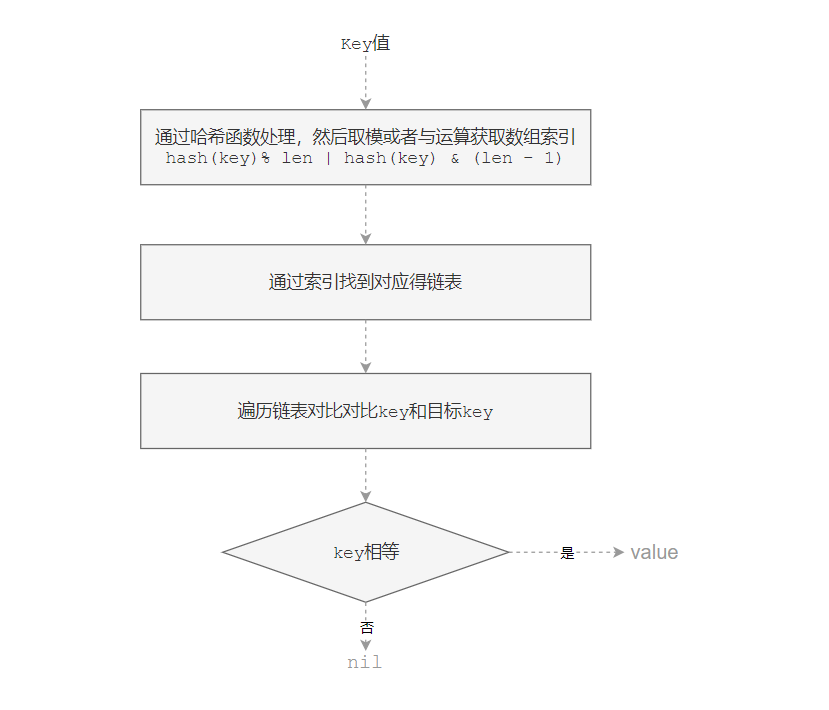
如果要在哈希表中获取某个键对应的值,则先经过一个哈希函数,哈希函数返回的哈希会帮助我们选择一个桶,它会依次遍历桶中的链表,然而遍历到链表的末尾也没有找到期望的键,所以哈希表中没有该键对应的值。如下图:
装载因子
在一个性能比较好的哈希表中,每一个桶中都应该有 0~1 个元素,有时会有 2~3 个,很少会超过这个数量。计算哈希、定位桶和遍历链表三个过程是哈希表读写操作的主要开销,使用拉链法实现的哈希也有装载因子这一概念:
装载因子
:
=
元素数量
÷
桶数量
装载因子:=元素数量÷桶数量
装载因子:=元素数量÷桶数量
与开放地址法一样,拉链法的装载因子越大,哈希的读写性能就越差。在一般情况下使用拉链法的哈希表装载因子都不会超过 1,当哈希表的装载因子较大时会触发哈希的扩容,创建更多的桶来存储哈希中的元素,保证性能不会出现严重的下降。如果有 1000 个桶的哈希表存储了 10000 个键值对,它的性能是保存 1000 个键值对的 1/10,但是仍然比在链表中直接读写好 1000 倍。
基础使用
在Go语言中,map是一种内置的数据结构,用于存储键值对。它是一种哈希表的实现,因此可以被看作是一种哈希映射(hashmap)。map是一种强大且方便的数据结构,用于关联和索引数据。它简单易用,具有快速查找和动态大小调整的优点,适用于各种数据存储和检索的场景。
以下列举map的基本使用方法:
-
创建和初始化
map:可以使用make函数来创建一个空的map,并指定键和值的类型。//直接使用 var创建使用map var m map[string]int m = map[string]int{"one": 1, "two": 2} //:=方式创建并初始化map m1 := map[int]int{0: 0, 1: 1, 2: 4, 3: 9, 4: 16} // 创建一个映射字符串键到整数值的空map ages := make(map[string]int) -
添加和更新键值对:通过使用键来添加或更新
map中的键值对。如果键已经存在,则会更新对应的值;如果键不存在,则会添加新的键值对。ages["Alice"] = 28 // 添加键值对 ages["Bob"] = 32 // 添加另一个键值对 ages["Alice"] = 29 // 更新Alice的值为29 -
访问键值对:可以使用键来访问
map中的值。如果键存在,则返回对应的值;如果键不存在,则返回值类型的零值。fmt.Println(ages["Alice"]) // 输出: 29 fmt.Println(ages["Bob"]) // 输出: 32 fmt.Println(ages["Eve"]) // 输出: 0 (int类型的零值) -
删除键值对:使用
delete函数可以从map中删除指定的键值对。delete(ages, "Alice") // 删除键为"Alice"的键值对 -
检查键是否存在:可以使用多赋值语法检查键是否存在。当通过
map[key]访问值时,第二个返回值表示该键是否存在。value, ok := ages["Bob"] if ok { fmt.Println("Bob's age:", value) } else { fmt.Println("Bob not found") } -
迭代
map:使用for range循环可以遍历map中的键值对。每次迭代都会返回键和对应的值。for key, value := range ages { fmt.Println(key, "is", value, "years old") }
这些是在Go语言中使用map的基本操作方法。map提供了一种方便的方式来存储和检索键值对数据,并且可以根据具体的需求进行各种操作和扩展。
在实际应用中,map在各种场景中都有广泛的应用。下面是一些常见的场景和相应的例子:
-
统计元素出现次数:使用
map可以统计元素在集合中出现的次数。func countElements(elements []string) map[string]int { counts := make(map[string]int) for _, element := range elements { counts[element]++ } return counts } elements := []string{"apple", "banana", "apple", "orange", "banana", "apple"} result := countElements(elements) fmt.Println(result) // 输出: map[apple:3 banana:2 orange:1] -
缓存数据:使用
map作为缓存可以避免重复计算或频繁的IO操作。var cache = make(map[string]string) func getData(key string) string { if val, ok := cache[key]; ok { return val } data := fetchDataFromDatabase(key) cache[key] = data return data } -
存储配置信息:使用
map可以存储和访问配置项。var config = map[string]string{ "database.host": "localhost", "database.username": "admin", "database.password": "password123", } func getConfig(key string) string { return config[key] } dbHost := getConfig("database.host") -
数据分组:
map可以用于将具有相同属性或特征的数据进行分组。type Person struct { Name string Age int } func groupByAge(people []Person) map[int][]Person { groups := make(map[int][]Person) for _, person := range people { age := person.Age groups[age] = append(groups[age], person) } return groups } people := []Person{ {Name: "Alice", Age: 28}, {Name: "Bob", Age: 32}, {Name: "Charlie", Age: 28}, {Name: "Dave", Age: 32}, } result := groupByAge(people) fmt.Println(result) // 输出: // map[28:[{Alice 28} {Charlie 28}] 32:[{Bob 32} {Dave 32}]]
这些是map常见的使用场景和例子。map是一种灵活而强大的数据结构,可以应用于各种需要键值对映射的问题和场景中。
底层分析
Go语言中的map是基于哈希表(Hash Table)的数据结构,通过计算键的哈希值,然后根据哈希值找到对应的桶,最后在桶中进行操作使用了拉链法去解决hash冲突。
数据结构
Go语言 map在语言底层编译是通过如下的抽象结构来表征,结构如下:
type Map struct {
Key *Type
Elem *Type
Bucket *Type
Hmap *Type
Hiter *Type
}
- Key Elem 键和元素值所属得类型,由于 go map 支持多种数据类型, go 会在编译期推断其具体的数据类型
- Bucket 哈希桶的内部结构类型,对应的运行时(
runtiime)结构体表示是bmap结构体 - Hmap Hmap(
map header对象)的内部结构类型,对应的运行时(runtiime)结构体表示是hmap结构体 - Hiter 哈希迭代器状态的内部结构类型,用作
range map使用
Map结构体定义了Go语言中map的内部实现细节,包括哈希计算、键值对的存储、桶的处理以及迭代操作等。 该结构体字段都是编译器在编译期间自动生成的,它允许我们访问底层结构体的字段,但它并不是公开可用的,无法直接在应用程序中使用。这是因为它属于Go语言的内部实现,通常由Go语言的运行时系统和编译器进行处理和管理。
通过Map的结构体,我们可以得出,go语言的map实现重要的底层结构是: hmap 与 bmap结构,他们分表代表着map的头部对象(用于管理 map 的整体状态和元信息)以及桶结构(存储具体的键值对数据,并处理哈希冲突)。
hmap
hmap 结构体是 Golang 中 map 的头部对象,用于管理 map 的整体状态和元信息。
该结构体的定义为:
// go 1.20.3 path:runtime/map.go
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
- count 当前
map中存储的键值对数量。调用len(map)时, 返回值的就是该字段值 - flags 标志位,用于记录
map的状态信息,如是否正在扩容等。四种状态如下:- iterator = 1 可能有迭代器(遍历)在使用
buckets - oldIterator = 2 可能有迭代器(遍历)在使用
oldbuckets,用于扩容期间 - hashWriting = 4 一个
goroutine正在写入map操作,用于并发读写检测 - sameSizeGrow = 8 表示正在进行相同大小的扩容,即
buckets的数量不变,只是增加溢出桶的数量
- iterator = 1 可能有迭代器(遍历)在使用
- B 表示当前哈希表持有的
buckets数量,但是因为哈希表中桶的数量都2的倍数,所以该字段会存储对数,也就是 len(buckets) == 2B(最多容纳loadFactor * 2B个元素); - noverflow 溢出桶的数量,表示当前
map中存在的溢出桶的个数。溢出桶是处理哈希冲突时创建的额外桶。 - hash0 哈希计算的种子,用于哈希函数,使哈希结果更加随机化,减少哈希碰撞的几率。
- buckets 指向桶数组的指针,存储实际的键值对数据。每个桶存储一组具有相同哈希值的键值对。
- oldbuckets 在
map扩容时,用于临时存储旧的桶数组。扩容过程中会逐渐将键值对从旧的桶迁移到新的桶。如果发生扩容,oldbuckets是指向老的buckets数组的指针, 老的buckets数组大小是新的buckets的1/2. 非扩容状态下, 它为nil. 它是判断是否处于扩容状态的标识 - nevacuate 用来记录渐进式扩容阶段下一个要迁移的旧桶编号。当
map的负载因子超过一定阈值时,会触发扩容操作,此时会分配新的 buckets 数组,并将旧的buckets数组保存在oldbuckets字段中。为了避免一次性搬迁所有的键值对,造成性能下降,Go语言采用了渐进式扩容的方式,即每次插入或删除键值对时,都会尝试搬迁部分旧桶到新桶中。hmap.nevacuate就是用来指示下一次搬迁的旧桶的索引,它的初始值为0,每次搬迁后会递增,直到等于旧桶的数量,表示扩容完成。 - extra 指向
mapextra结构体的指针,存储额外的位标志,如迭代器状态和特殊标志等。这个字段是为了优化GC扫描而设计的。
bmap
在 map 的实现中,hmap.buckets 指向一个桶数组,这个数组中的每个元素都是一个 bmap 结构体,表示一个哈希桶。每个桶中存储了具有相同哈希值的键值对,通过哈希函数计算键的哈希值,可以快速定位到对应的桶。
bmap 结构体定义如下:
// go 1.20.3 path:runtime/map.go
const (
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
)
// go 1.20.3 path:runtime/map.go
type bmap struct {
tophash [bucketCnt]uint8
}
从bmap结构体代码来看,貌似很简单,就是每个哈希桶都含有是一个名为tophash的数组,定长为 8 。
那tophash有什么用呢?
// go 1.20.3 path:runtime/map.go
func tophash(hash uintptr) uint8 {
top := uint8(hash >> (goarch.PtrSize*8 - 8))
if top < minTopHash {
top += minTopHash
}
return top
}
从代码上分析,tophash数组存储的元素是key键值hash后的哈希值的高8字节。这样就表明一个bmap(哈希桶)可以存储8组高 8 位 hash 值。如图:
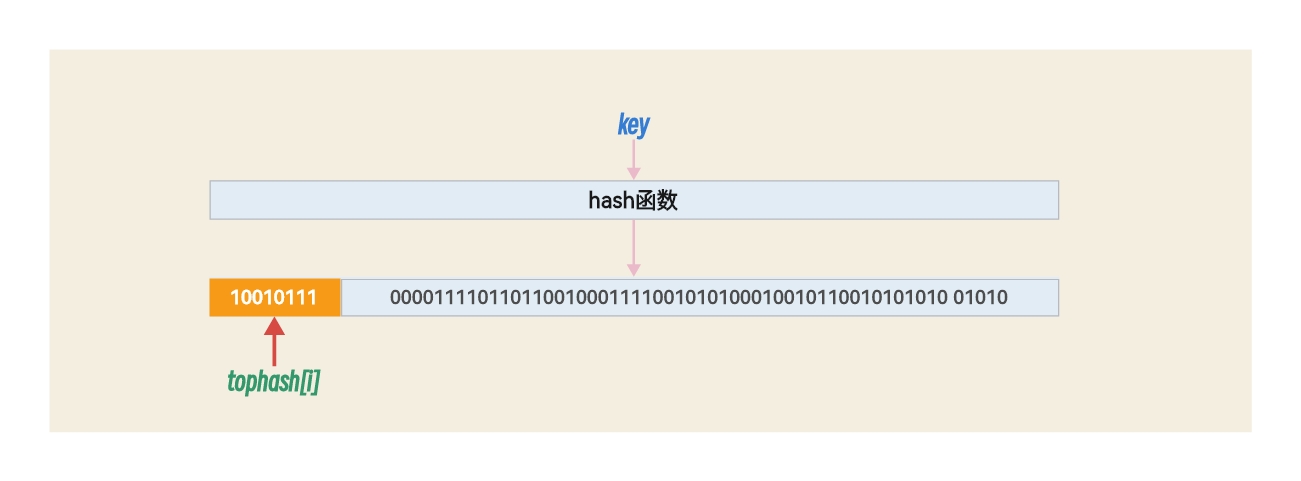
tophash除了拿来存hash值,还可以用来表示桶的疏散状态,当 tophash[i]>5时,tophash[i]则为正常hash值,当tophash[i]<5时,tophash[i]则为状态值。
桶的状态值有下列五种:
// go 1.20.3 path:runtime/map.go
const (
emptyRest = 0 //表示此桶单元为空,其更高索引或者溢出桶也为空,即后面没有任何键值对存储在此桶中;
emptyOne = 1 //表示此桶单元为空,但更高索引的单元可能不为空,即后面可能还有键值对存储在此桶中;
evacuatedX = 2 //表示此桶单元已经被迁移,且迁移到新桶的前半段区间,即新桶的索引为旧桶索引左移一位;
evacuatedY = 3 //表示此桶单元已经被迁移,且迁移到新桶的后半段区间,即新桶的索引为旧桶索引左移一位加一;
evacuatedEmpty = 4 //表示此桶单元已经被迁移,且原来是空的,即没有任何键值对需要迁移;
minTopHash = 5 //用来区分键的哈希值的高位和桶状态的标识位值
)
这几种状态特中的 evacuatedX 和evacuatedY理解起来有点小麻烦,后面扩容部分会进行讲解。
到此,桶的结构就这样吗?都知道map是key/value形式,有了key的hash值,查找value,那value值存哪里?
哈希表中桶的真正结构其实是在编译期间运行的函数 MapBucketType 中被『动态』创建的:
// go 1.20.3 path:/src/cmd/compile/internal/reflectdata/reflect.go
func MapBucketType(t *types.Type) *types.Type {
// ...
// 获取 map 的键类型和值类型
keytype := t.Key()
elemtype := t.Elem()
// 计算键和值的大小
types.CalcSize(keytype)
types.CalcSize(elemtype)
// 如果键的大小超过了 MAXKEYSIZE,则将其变为指针类型
if keytype.Size() > MAXKEYSIZE {
keytype = types.NewPtr(keytype)
}
// 如果值的大小超过了 MAXELEMSIZE,则将其变为指针类型
if elemtype.Size() > MAXELEMSIZE {
elemtype = types.NewPtr(elemtype)
}
// 创建桶类型的字段
field := make([]*types.Field, 0, 5)
// 创建包含 topbits 的数组字段
arr := types.NewArray(types.Types[types.TUINT8], BUCKETSIZE)
field = append(field, makefield("topbits", arr))
// 创建包含键的数组字段
arr = types.NewArray(keytype, BUCKETSIZE)
arr.SetNoalg(true)
keys := makefield("keys", arr)
field = append(field, keys)
// 创建包含值的数组字段
arr = types.NewArray(elemtype, BUCKETSIZE)
arr.SetNoalg(true)
elems := makefield("elems", arr)
field = append(field, elems)
// 创建溢出字段,根据键和值是否有指针来确定类型
otyp := types.Types[types.TUNSAFEPTR]
if !elemtype.HasPointers() && !keytype.HasPointers() {
otyp = types.Types[types.TUINTPTR]
}
overflow := makefield("overflow", otyp)
field = append(field, overflow)
// 创建桶类型
bucket := types.NewStruct(types.NoPkg, field[:])
bucket.SetNoalg(true)
types.CalcSize(bucket)
// 将桶类型赋值给 map 类型的 Bucket 字段
t.MapType().Bucket = bucket
// 设置桶类型的 Map 字段为当前的 map 类型
bucket.StructType().Map = t
// 返回桶类型
return bucket
}
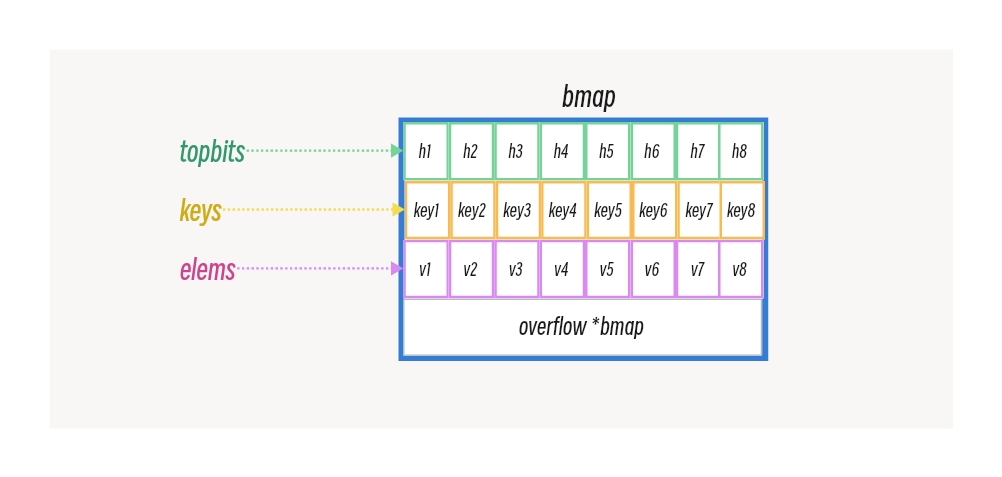
通过上述函数实现对结构体 bmap 进行重建:
type bmap struct {
topbits [8]uint8
keys [8]keytype
elems [8]elemtype
overflow uintptr
}
这里编译期间的 topbits 字段,其实对应的就是runtime时的tophash字段,下面用图来表示bmap的结构会更直观些:
到这里就大致了解了 bmap的结构,那如何在bucket(哈希桶,即单个 bmap)里面通过key/value模式查找值呢?我们这边可以通过计算偏移量来定位,代码如下:
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)
//key定位公式
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
//value定位公式
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
首选通过 unsafe.Offsetof函数计算出 bmap中的tophash或者说是 topbits所占用的空间大小,即命名为 dataOffset,然后通过对比tophash数组里的元素值获取需要查找的key键的所在的索引 i。因此bucket里key的起始地址就是unsafe.Pointer(b)+dataOffset;第i个key的地址就要此基础上加i个key大小;value的地址是在key之后,所以第i个value,要加上所有的key的偏移。
mapextra
在 Golang 中,“溢出桶”(overflow bucket)是指在处理哈希冲突时,当一个桶(bucket)已经达到一定容量限制后,无法再存储更多的键值对时,额外创建的桶。
当一个桶中的键值对数量超过了一定的阈值(在 Golang 的实现中通常为 8),就会发生哈希冲突。为了解决冲突,Golang 使用开放定址法(open addressing)的线性探测(linear probing)策略,在桶内的连续位置中寻找空闲的位置来存储新的键值对。
但是,当桶已经满了,而且无法找到可用的空闲位置时,就需要创建一个溢出桶。溢出桶是一个额外的桶,用于存储原始桶中无法容纳的键值对。
在 Golang 中,溢出桶的实现是通过在桶类型中添加一个名为 overflow 的字段来实现的。而溢出桶的信息则使用 mapextra 结构体来记录。
mapextra 结构体定义如下:
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
- overflow 溢出桶,和
hmap.buckets的类型一样也是数组[]*bmap,当正常桶bmap存满了的时候就使用hmap.extra.overflow的bmap - oldoverflow 扩容时存放之前的
overflow - nextOverflow 指向溢出桶里下一个可以使用的
bmap
当map底层创建时,会初始化一个hmap结构体,同时分配一个足够大的内存空间A。其中A的前段用于hash数组,A的后段预留给溢出的桶。于是hmap.buckets指向hash数组,即A的首地址;hmap.extra.nextOverflow初始时指向内存A中的后段,即hash数组结尾的下一个桶,也即第1个预留的溢出桶。
结构关联
完成了对 hmap 、 bmap 以及 mapextra单结构体的了解后,我们就将这些结构体进行串联起来,展现完整的map结构。我们用图来表示,这样更加直观些,完整的map结构图如下:
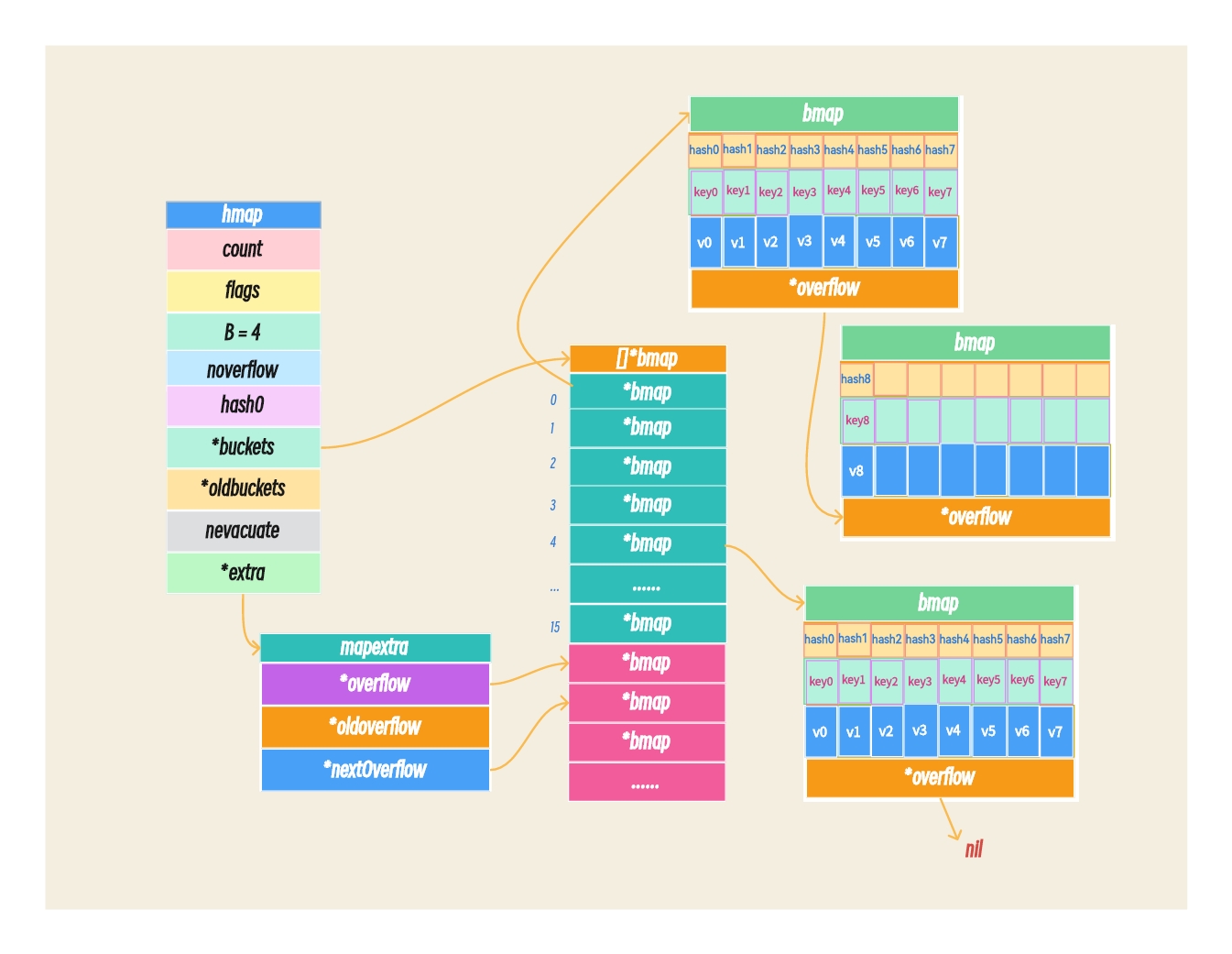
总结起来来说:
hmap(hash map)是map的头部结构体,用于存储map的元信息和管理桶(buckets)。bmap(bucket map)是哈希表中的一个桶(bucket),用于存储键值对。mapextra是用于扩展hmap结构的辅助结构体。
这些结构体之间的关联如下:
hmap结构体中的buckets字段指向存储桶的内存区域,其中的每个桶都是一个bmap结构体。hmap结构体中的extra字段指向存储额外溢出桶信息的mapextra结构体。
通过这种关联,hmap 结构体管理着整个哈希表的元信息,并且通过 buckets 字段引用了实际的存储桶。每个存储桶都是一个 bmap 结构体,用于存储键值对。如果发生扩容并产生了溢出桶,那么溢出桶的信息会存储在 mapextra 结构体中,并通过 extra 字段引用。这种组合的结构体设计使得 Golang 的 map 实现具备高效的查找和存储特性,并且能够动态调整容量以适应数据的变化。
初始化
运行时
map初始化有以下两种方式:
// 不指定初始化map大小
make(map[k]v)
// 指定初始化map大小为hint
make(map[k]v, hint)
对于这两种初始化方式在底层编译处理有什么不同,我们进行了反汇编查看,如下列例子:
func main() {
m := make(map[string]int, 2)
m1 := make(map[string]int, 8)
m2 := make(map[string]int, 9)
fmt.Println(m, m1, m2)
}
我们对例子执行 go build -gcflags=-S main.go >& 1.txt 操作,得到如下汇编代码:
main.main STEXT size=185 args=0x0 locals=0x70 funcid=0x0 align=0x0
0x0000 00000 TEXT main.main(SB), ABIInternal, $112-0
0x0000 00000 CMPQ SP, 16(R14)
0x0004 00004 PCDATA $0, $-2
0x0004 00004 JLS 175
0x000a 00010 PCDATA $0, $-1
0x000a 00010 SUBQ $112, SP
0x000e 00014 MOVQ BP, 104(SP)
0x0013 00019 LEAQ 104(SP), BP
0x0018 00024 FUNCDATA $0, gclocals·ykHN0vawYuq1dUW4zEe2gA==(SB)
0x0018 00024 FUNCDATA $1, gclocals·I76sKbn5RubBl1jweLet5Q==(SB)
0x0018 00024 FUNCDATA $2, main.main.stkobj(SB)
0x0018 00024 PCDATA $1, $0
0x0018 00024 CALL runtime.makemap_small(SB)
0x001d 00029 MOVQ AX, main.m+48(SP)
0x0022 00034 PCDATA $1, $1
0x0022 00034 CALL runtime.makemap_small(SB)
0x0027 00039 MOVQ AX, main.m1+40(SP)
0x002c 00044 MOVL $9, BX
0x0031 00049 XORL CX, CX
0x0033 00051 LEAQ type:map[string]int(SB), AX
0x003a 00058 PCDATA $1, $2
0x003a 00058 CALL runtime.makemap(SB)
0x003f 00063 MOVUPS X15, main..autotmp_11+56(SP)
0x0045 00069 MOVUPS X15, main..autotmp_11+72(SP)
0x004b 00075 MOVUPS X15, main..autotmp_11+88(SP)
......
结合例子以及汇编代码,我们可以得出:
- 对于不指定初始化大小和初始化值
hint<=8(bucketCnt)时,go会调用makemap_small函数,并直接从堆上进行分配; - 对于
hint > 8的情况,go会调用makemap函数处理
makemap_small
makemap_small 函数源码如下:
func makemap_small() *hmap {
h := new(hmap)
h.hash0 = fastrand()
return h
}
makemap_small 函数是 Go 语言中用于创建小型 map 的内部函数。
该函数的作用是根据给定的键值对类型 maptype 和初始化大小 hint 创建一个 hmap 结构的实例,且该函数并不直接创建桶(bmap),当map中插入第一个键值对时,才会调用makemapbucket函数来创建第一个桶。
在Go 语言编译阶段,编译器还会使用如下方式快速初始化哈希,这也是编译器对小容量的哈希做的优化:
var h *hmap
var hv hmap
var bv bmap
h := &hv
b := &bv
h.buckets = b
h.hash0 = fashtrand0()
makemap
makemap函数源码如下:
// go 1.20.3 path:/runtiime/map.go
func makemap(t *maptype, hint int, h *hmap) *hmap {
// 计算需要分配的内存大小
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
// 检查是否发生溢出或超过最大可分配内存
if overflow || mem > maxAlloc {
hint = 0
}
// 如果传入的 hmap 为空,则创建一个新的 hmap
if h == nil {
h = new(hmap)
}
// 初始化 hmap 的一些字段
h.hash0 = fastrand() // 设置 hash0 字段为一个随机数
B := uint8(0)
// 根据负载因子计算 B 值,用于确定桶的数量
for overLoadFactor(hint, B) {
B++
}
h.B = B // 设置 hmap 的 B 字段,即桶的数量
// 如果 B 不为 0,说明需要创建桶
if h.B != 0 {
var nextOverflow *bmap
// 创建存储桶的数组,并返回下一个溢出桶的指针
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// 如果有下一个溢出桶,创建 mapextra 结构体,并将其赋值给 hmap 的 extra 字段
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h // 返回创建或更新后的 hmap
}
该函数的主要流程可以概括如下:
- 计算需要分配的内存大小,如果溢出或超过最大可分配内存,则将
hint设置为 0。 - 如果传入的
hmap为空,则创建一个新的hmap。 - 初始化
hmap的hash0字段为一个随机数。 - 根据负载因子计算
B值,用于确定桶的数量。通过循环逐步递增B值,直到满足负载因子条件。 - 设置
hmap的B字段为计算得到的桶的数量。 - 如果 B 不为
0,说明需要创建桶。- 创建存储桶的数组,并返回下一个溢出桶的指针。
- 如果存在下一个溢出桶,创建
mapextra结构体,并将其赋值给hmap的extra字段。
- 返回创建或更新后的
hmap。
流程就是这么个流程,下面将对函数中出现的一些重要结构或者函数进行逐步分析。
maptype
maptype 结构体用于描述 map 类型的元信息,它的作用是定义 map 类型的属性和行为,以及存储与 map 相关的类型信息。
定义如下:
// go 1.20.3 path:/runtiime/type.go
type maptype struct {
typ _type // 表示 map 类型本身的 _type 元信息,包括类型的名称、大小、对齐方式等
key *_type // 表示 map 的键类型的 _type 元信息
elem *_type // 表示 map 的值类型的 _type 元信息
bucket *_type // 表示内部表示哈希桶的 _type 元信息
hasher func(unsafe.Pointer, uintptr) uintptr // 是一个哈希函数,用于计算键的哈希值
keysize uint8 // 键的大小(以字节为单位)
elemsize uint8 // 值的大小(以字节为单位)
bucketsize uint16 // 哈希桶的大小(以字节为单位)
flags uint32 // 一些标志位,用于表示 map 的特性或配置
}
这个结构体主要用于编译器和运行时系统来处理 map 类型的创建、赋值、访问和操作等操作。它提供了 map 类型的元信息,以便在运行时正确地分配内存、计算哈希值、查找键值对等。在运行时,通过使用 maptype 结构体中的信息,可以实现对 map 类型的正确处理和操作。
在开发过程中,通常不需要直接使用或操作 maptype 结构体,而是通过 map 类型的声明和使用来间接使用这些信息。只有在需要深入了解 map 类型的底层实现或进行高级编程技巧时,才会涉及到对 maptype 结构体的直接操作和使用。
这里只是知道下这个结构体存在以及作用,更详细的后续会在接口单元进行细说。
overLoadFactor
overLoadFactor 函数用于判断给定的负载因子是否超过预定阈值。负载因子表示哈希表中已存储键值对的数量与哈希桶总数之间的比率,是用来判断一个map是否需要扩容的重要因素。
函数定义如下:
// go 1.20.3 path:/runtiime/map.go
const(
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
loadFactorNum = 13
loadFactorDen = 2
)
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
该函数判断条件有两个,必须同时满足:
map元素总数count需超过8(bucketCnt,即一个桶的数量),因为在map总元素数量少于等于8时,会调用makemap_small函数,该函数只初始创建了一个hmap结构,并未创建桶空间;map元素总数count与桶的数量的除法结果大于负载因子,即count/bucketShift(B) > loadFactorNum/loadFactorDen; 其中负载因子相关的常量:loadFactorNum和loadFactorDen,loadFactorNum/loadFactorDen的结果就是触发扩容的阈值负载因子,当前版本中负载因子为13/2 = 6.5
在这里顺带给出bucketShift函数代码,该函数是根据桶指数b,计算总桶数2^b^的方法:
func bucketShift(b uint8) uintptr {
return uintptr(1) << (b & (goarch.PtrSize*8 - 1))
}
makeBucketArray
runtime.makeBucketArray 的主要作用是创建存储桶的数组,并为每个桶分配内存和初始化状态。这是 map 实现中关键的一步,用于支持哈希表的基本功能。
runtime.makeBucketArray源码如下:
// go 1.20.3 path:/runtiime/map.go
/**
* @Description: 通过make创建map
* @param t map的元类型
* @param b map的哈希桶的数量的log2值
* @param dirtyalloc 可选参数,表示存放桶的内存地址
*/
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
//计算基础桶数量,即2^b
base := bucketShift(b)
//将基础桶的数量赋值给nbuckets
nbuckets := base
//如果b>=4,即桶的数量大于等于16,则nbuckets数量加上2^(b-4)个,多加的桶作为溢出桶使用
if b >= 4 {
//则nbuckets数量加上2^(b-4)个,多加的桶作为溢出桶使用
nbuckets += bucketShift(b - 4)
//计算创建nbuckets个桶所需的内存大小
sz := t.bucket.size * nbuckets
//取整对齐内存
up := roundupsize(sz)
if up != sz {
nbuckets = up / t.bucket.size
}
}
/**
如果dirtyalloc为空,则分配新的内存;否则表示内存已经分配好了,直接使用并内存清零
*/
if dirtyalloc == nil {
//调用newarray函数分配一个新的数组作为桶的内存
buckets = newarray(t.bucket, int(nbuckets))
} else {
//直接使用dirtyalloc作为桶的内存
buckets = dirtyalloc
//计算所有桶所需要的内存大小
size := t.bucket.size * nbuckets
if t.bucket.ptrdata != 0 {
//如果桶的元素有指针,则调用memclrHasPointers函数将桶的内存清零
memclrHasPointers(buckets, size)
} else {
//如果桶的元素没有指针,则调用memclrNoHeapPointers函数将桶的内存清零
memclrNoHeapPointers(buckets, size)
}
}
//如果base不等于nbuckets,说明分配了多余的桶作为溢出桶
if base != nbuckets {
//计算溢出桶的位置和设置溢出桶的链接
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize)))
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize)))
last.setoverflow(t, (*bmap)(buckets))
}
//返回桶的内存地址和溢出桶的地址
return buckets, nextOverflow
}
函数的重要流程如下:
-
根据输入的桶数量
b,计算基础桶数量base(2b);在桶数组的指数b >= 4时,则需要提前创建好 2(b-4) 个溢出桶;基础桶+溢出桶相加从而得到总桶数量nbuckets; -
根据总桶数
nbuckets计算出所需内存大小,分配内存并将桶的内存清零。内存分配步骤如下:- 提供了已分配的内存
dirtyalloc,则使用该内存, - 否则调用
newarray分配新的数组内存,由此也可以知道nbuckets对应的是一个数组指针
根据内存分配代码来看,在正常情况下,正常桶和溢出桶在内存中的存储空间是连续的,只是被
hmap中的不同字段引用而已。 - 提供了已分配的内存
-
如果存在溢出桶(
base != nbuckets),计算溢出桶的位置和设置溢出桶的链接; -
返回桶的内存地址和溢出桶的地址。
字面量
目前的现代编程语言基本都支持使用字面量的方式初始化哈希,一般都会使用 key: value 的语法来表示键值对,Go 语言中也不例外:
hash := map[string]int{
"1": 2,
"3": 4,
"5": 6,
}
我们需要在初始化哈希时声明键值对的类型,这种使用字面量初始化的方式最终都会通过 maplit 函数初始化,我们来分析一下该函数初始化哈希的过程:
// go 1.20.3 path:/src/cmd/compile/internal/walk/complit.go
func maplit(n *ir.CompLitExpr, m ir.Node, init *ir.Nodes) {
......
//如果字面量超过25个
if len(entries) > 25 {
//根据 n 的键类型和值类型,创建键类型数组 tk 和值类型数组 te,数组长度为 entries 的长度
tk := types.NewArray(n.Type().Key(), int64(len(entries)))
te := types.NewArray(n.Type().Elem(), int64(len(entries)))
//调用 types.CalcSize 计算键类型数组和值类型数组的大小
types.CalcSize(tk)
types.CalcSize(te)
//创建用于存储静态数组,变量名为 vstatk 和 vstate
vstatk := readonlystaticname(tk)
vstate := readonlystaticname(te)
//创建两个空的 ir.CompLitExpr 表达式 datak 和 datae,表示键类型和值类型的静态数组
datak := ir.NewCompLitExpr(base.Pos, ir.OARRAYLIT, nil, nil)
datae := ir.NewCompLitExpr(base.Pos, ir.OARRAYLIT, nil, nil)
//遍历 entries,将每个键和值表达式添加到对应的静态数组中
for _, r := range entries {
r := r.(*ir.KeyExpr)
datak.List.Append(r.Key)
datae.List.Append(r.Value)
}
//使用 fixedlit 函数将键类型和值类型的静态数组转化为静态初始值,并将其赋值给对应的静态变量 vstatk 和 vstate
//最终将静态初始值的设置添加到 init 列表中
fixedlit(inInitFunction, initKindStatic, datak, vstatk, init)
fixedlit(inInitFunction, initKindStatic, datae, vstate, init)
......
return
}
tmpkey := typecheck.Temp(m.Type().Key()) // 创建临时变量 tmpkey,用于存储键的值
tmpelem := typecheck.Temp(m.Type().Elem()) // 创建临时变量 tmpelem,用于存储值的值
// 遍历 entries 中的键值对
for _, r := range entries {
r := r.(*ir.KeyExpr)
index, elem := r.Key, r.Value
ir.SetPos(index) // 设置当前位置为键表达式的位置
appendWalkStmt(init, ir.NewAssignStmt(base.Pos, tmpkey, index)) // 构造赋值语句,将键的值赋给临时变量 tmpkey
ir.SetPos(elem) // 设置当前位置为值表达式的位置
appendWalkStmt(init, ir.NewAssignStmt(base.Pos, tmpelem, elem)) // 构造赋值语句,将值的值赋给临时变量 tmpelem
ir.SetPos(tmpelem)
// 类型检查器将 OINDEX 重写为 OINDEXMAP
lhs := typecheck.AssignExpr(ir.NewIndexExpr(base.Pos, m, tmpkey)).(*ir.IndexExpr)
base.AssertfAt(lhs.Op() == ir.OINDEXMAP, lhs.Pos(), "want OINDEXMAP, have %+v", lhs)
lhs.RType = n.RType
// 构造赋值语句,将键值对存入 map
var a ir.Node = ir.NewAssignStmt(base.Pos, lhs, tmpelem)
a = typecheck.Stmt(a) // 进行类型检查
a = orderStmtInPlace(a, map[string][]*ir.Name{}) // 进行语句排序
appendWalkStmt(init, a) // 将赋值语句添加到初始化语句列表 init 中
}
......
}
当哈希表中的元素数量少于或者等于 25 个时,编译器会将字面量初始化的结构体转换成以下的代码,将所有的键值对一次加入到哈希表中:
hash := make(map[string]int, 3)
hash["1"] = 2
hash["3"] = 4
hash["5"] = 6
这种初始化的方式与的数组和切片几乎完全相同,由此看来集合类型的初始化在 Go 语言中有着相同的处理逻辑。
一旦哈希表中元素的数量超过了 25 个,编译器会创建两个数组分别存储键和值,这些键值对会通过如下所示的 for 循环加入哈希:
hash := make(map[string]int, 26)
vstatk := []string{"1", "2", "3", ... , "26"}
vstatv := []int{1, 2, 3, ... , 26}
for i := 0; i < len(vstak); i++ {
hash[vstatk[i]] = vstatv[i]
}
这里展开的两个切片 vstatk 和 vstatv 还会被编辑器继续展开,不过无论使用哪种方法,使用字面量初始化的过程都会使用 Go 语言中的关键字 make 来创建新的哈希并通过最原始的 [] 语法向哈希追加元素。
读取
map 查询元素值有下面两种写法:
v := m[key]
v, ok := m[key]
我们通过一个例子,通过反汇编,看看对于这两种不同的写法,编译器是如何工作的:
import (
"fmt"
"time"
)
type TimeStruct struct {
Date time.Time
Id int64
}
func main() {
dat, _ := time.Parse("2006-01-02", "2019-01-01")
m := map[string]int{"one": 1, "two": 2, "three": 3}
m2 := map[TimeStruct]int{TimeStruct{Date: dat, Id: 1}: 1, TimeStruct{Date: dat, Id: 2}: 2, TimeStruct{Date: dat, Id: 3}: 3}
v1 := m["two"]
v2, ok := m["two"]
v3 := m2[TimeStruct{Date: dat, Id: 2}]
fmt.Println(v1, v2, v3, ok)
}
执行 go build -gcflags=-S main.go >& 1.txt,得到汇编代码:
# command-line-arguments
main.main STEXT size=1002 args=0x0 locals=0x348 funcid=0x0 align=0x0
......
0x025b 00603 LEAQ type:map[string]int(SB), AX
0x0262 00610 LEAQ main..autotmp_22+176(SP), BX
0x026a 00618 LEAQ go:string."two"(SB), CX
0x0271 00625 MOVL $3, DI
0x0276 00630 CALL runtime.mapaccess1_faststr(SB)
0x027b 00635 MOVQ (AX), DX
0x027e 00638 MOVQ DX, main.v1+64(SP)
0x0283 00643 LEAQ type:map[string]int(SB), AX
0x028a 00650 LEAQ main..autotmp_22+176(SP), BX
0x0292 00658 LEAQ go:string."two"(SB), CX
0x0299 00665 MOVL $3, DI
0x029e 00670 PCDATA $1, $3
0x029e 00670 NOP
0x02a0 00672 CALL runtime.mapaccess2_faststr(SB)
0x02a5 00677 MOVB BL, main.ok+47(SP)
0x02a9 00681 MOVQ (AX), DX
0x02ac 00684 MOVQ DX, main.v2+56(SP)
0x02b1 00689 MOVQ main..autotmp_55+80(SP), SI
0x02b6 00694 MOVQ SI, main..autotmp_19+96(SP)
0x02bb 00699 MOVQ main..autotmp_56+72(SP), SI
0x02c0 00704 MOVQ SI, main..autotmp_19+104(SP)
0x02c5 00709 MOVQ main..autotmp_57+88(SP), SI
0x02ca 00714 MOVQ SI, main..autotmp_19+112(SP)
0x02cf 00719 MOVQ $2, main..autotmp_19+120(SP)
0x02d8 00728 LEAQ type:map[main.TimeStruct]int(SB), AX
0x02df 00735 LEAQ main..autotmp_19+96(SP), CX
0x02e4 00740 LEAQ main..autotmp_31+128(SP), BX
0x02ec 00748 PCDATA $1, $0
0x02ec 00748 CALL runtime.mapaccess1(SB)
0x02f1 00753 MOVQ (AX), DX
0x02f4 00756 MOVQ DX, main.v3+48(SP)
0x02f9 00761 MOVUPS X15, main..autotmp_45+224(SP)
0x0302 00770 MOVUPS X15, main..autotmp_45+240(SP)
......
通过汇编代码,我们可以看出针对不同的写法,在运行时调用不同的函数:
//go 1.20.3 path:/src/cmd/complie/internal/typecheck/_builtin/runtime.go
func mapaccess1(mapType *byte, hmap map[any]any, key *any) (val *any)
func mapaccess1_fast32(mapType *byte, hmap map[any]any, key uint32) (val *any)
func mapaccess1_fast64(mapType *byte, hmap map[any]any, key uint64) (val *any)
func mapaccess1_faststr(mapType *byte, hmap map[any]any, key string) (val *any)
func mapaccess1_fat(mapType *byte, hmap map[any]any, key *any, zero *byte) (val *any)
func mapaccess2(mapType *byte, hmap map[any]any, key *any) (val *any, pres bool)
func mapaccess2_fast32(mapType *byte, hmap map[any]any, key uint32) (val *any, pres bool)
func mapaccess2_fast64(mapType *byte, hmap map[any]any, key uint64) (val *any, pres bool)
func mapaccess2_faststr(mapType *byte, hmap map[any]any, key string) (val *any, pres bool)
func mapaccess2_fat(mapType *byte, hmap map[any]any, key *any, zero *byte) (val *any, pres bool)
这里做一个总结,赋值语句左侧接受参数的个数会决定使用的运行时方法:
- 当接受一个参数时(
v := m[key]),编译器会根据会使用不同键值类型调用不同函数,该函数仅会返回一个指向目标值的指针,调用函数情况如下:mapaccess1是一个通用的map访问函数,适用于任意键类型的map。它会进行动态的类型检查和键比较操作,以确保正确地访问和返回对应的值;mapaccess1_fast32和mapaccess1_fast64是用于在键类型为int32和int64的map中进行快速访问的函数。它们在内部会对键进行哈希计算,并使用快速路径进行查找;mapaccess1_faststr是用于在键类型为string的map中进行快速访问的函数。它在内部会对键进行哈希计算,并使用快速路径进行查找;mapaccess1_fat是一个通用的map访问函数,与mapaccess1类似,但处理更复杂的键类型。它针对键类型具有指针或包含指针的结构体时的情况进行了优化;
- 当接受两个参数时(
v, ok := m[key]),编译器会调用mapaccess2以及mapaccess2_***系列函数,除了返回目标值之外,它还会返回一个用于表示当前键对应的值是否存在的bool值,调用函数情况参考mapaccess1以及系列。
对于map的元素读取查找,选用 mapaccess1源码作为标准分析,其他函数流程都类似,不一一解析源码。
mapaccess1源码实现如下:
// go 1.20.3 path:/runtiime/map.go
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
//如果哈希表为空,或者哈希表的元素个数为0,那么直接零值对应的指针
if h == nil || h.count == 0 {
// 根据 Go 语言规范,传入非 comparable 类型时候,应该 panic,而不是返回空值
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
//如果正在进行并发读写操作,那么直接报错
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
//根据key计算哈希值
hash := t.hasher(key, uintptr(h.hash0))
//计算哈希值对应的桶的最大索引
m := bucketMask(h.B)
//计算哈希值对应的桶的地址
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
/**
如果 oldbuckets 不为空, 说明那么map发生了扩容,
如果有扩容发生,老的buckets中的数据可能还未搬迁至新的buckets里
所以需要先在老的buckets中找
*/
if c := h.oldbuckets; c != nil {
/**
如果当前不是等大扩容(后面扩容部分会详细介绍),就是桶的数量增加了一倍,这里直接除 2 (即 >> 1)缩小回来,就能对应到在老 bucket 中的位置
*/
if !h.sameSizeGrow() {
m >>= 1
}
// 计算老的 bucket 的地址
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
/**
判断 bucket 是否已经迁移
如果在oldbuckets中tophash[0]的值,为evacuatedX、evacuatedY,evacuatedEmpty其中之一,则evacuated()返回为true,代表搬迁完成
因此,只有当搬迁未完成时,才会从此oldbucket中遍历
*/
if !evacuated(oldb) {
b = oldb
}
}
//获取哈希值对应桶中的tophash,桶内的 hash定位仅使用 hash的高 8 位
top := tophash(hash)
/**
下面这个循环会遍历 key 对应的所有桶中的数据。一次循环找一个桶,找不到就沿着 overflow 指针找下一个溢出桶
双重循环遍历:外层循环是从桶到溢出桶遍历;内层是桶中的cell遍历
跳出循环的条件有三种:
第一种是已经找到key值;
第二种是当前桶再无溢出桶;
第三种是当前桶中有cell位的tophash值是emptyRest,这个值在前面解释过,它代表此时的桶后面的cell还未利用,所以无需再继续遍历。
*/
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
// 通过对比 tophash 来做初步定位
if b.tophash[i] != top {
/**
emptyRest 是特殊的 tophash,该值表明该位置为空,且后面也为空,无需再向后找。
*/
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// 直接计算偏移量找到 key 的地址
//因为在bucket中key是用连续的存储空间存储的,因此可以通过bucket地址+数据偏移量(bmap结构体的大小)+ keysize的大小,得到k的地址
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
//如果key值是间接引用的,那么就获取实际key值指针
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
//tophash相同也可能是hash碰撞,因此这里要确定当前键值与目标键值相等,如果相同则表示找到了
if t.key.equal(key, k) {
// 和找 key 一样,直接计算偏移量找到 value
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
//如果value值是间接引用的,那么就获取实际value值指针
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
//返回value值指针
return e
}
}
}
// 没找到的情况下,返回类型零值
return unsafe.Pointer(&zeroVal[0])
}
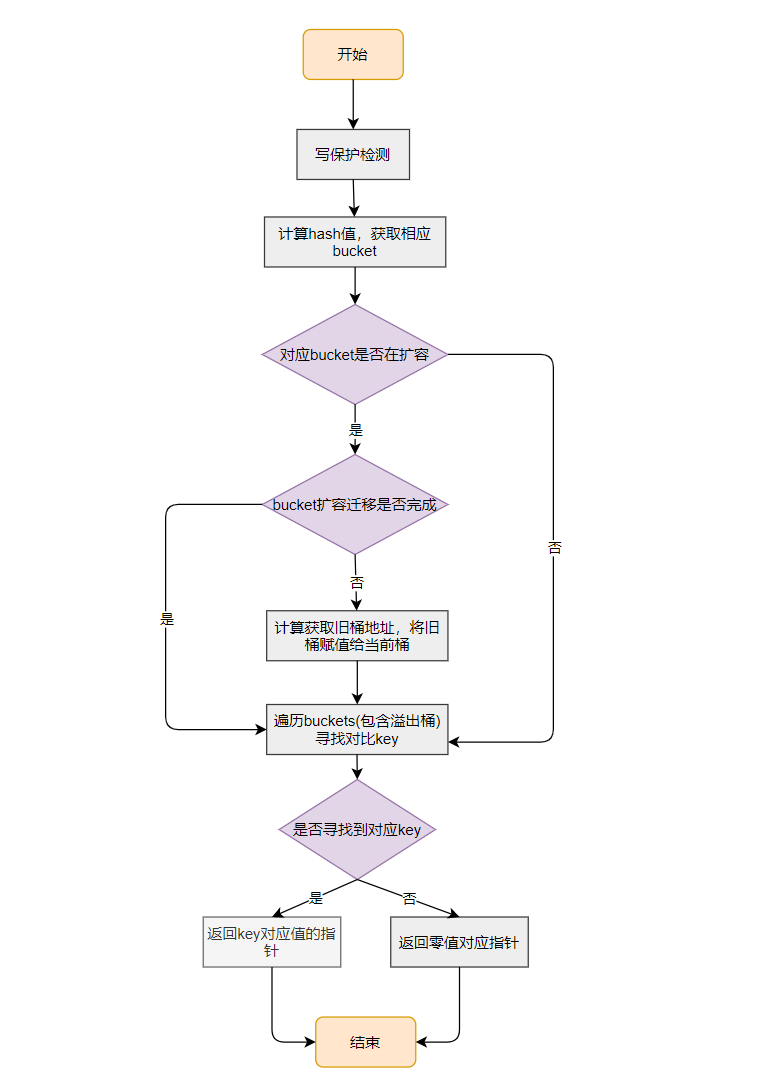
根据上面代码可以梳理出 map 定位元素的逻辑大概是这样:
-
计算 hash 值,获取相应的桶索引和地址;
-
如果当前桶正在扩容,判断桶是否已经迁移,从而判断应该在哪个桶中查询
- 如果当前旧桶中不为空,并且迁移并未完成,则计算旧桶的地址,从旧桶开始查询
- 其他情况下,从当前的桶开始查询
-
使用
hash的高8位,在桶中依次和tophash的元素对比,如果遇到相同的tophash,取出key进行二次确认,如果命中就返回,没有命中继续比完; -
桶中元素都遍历后,如果还没找到,就在接着溢出桶指针找链接的溢出桶,直到再无溢出桶或者当前桶中有
cell位的tophash值是emptyRest为止。
mapaccess2 等的逻辑类似,这里不再解释。
下面对mapaccess1 函数中涉及到一些函数或者技术问题点进行单独分析。
问题一: 知道hmap.B,求map中拥有的bucket的数量以及bucket的索引取值范围?
这个可以使用函数 bucketShift来处理:
func bucketShift(b uint8) uintptr {
return uintptr(1) << (b & (goarch.PtrSize*8 - 1))
}
对于 32 位系统,goarch.PtrSize 为 4,因此表达式简化为 uintptr(1) << (b & 31) ,即 2^(b & 31)^。
对于 64 位系统,goarch.PtrSize 为 8,因此表达式简化为 uintptr(1) << (b & 63),即 2^(b & 63)^。
而 bucket 的最大索引则可以使用函数bucketMask:
func bucketMask(b uint8) uintptr {
return bucketShift(b) - 1
}
这样就可以得到 bucket的索引取值范围: [0, bucketMask(b)]
问题二: 知道hmap.B以及hash值,求此hash所在bucket的索引?
这个问题,来看看 mapaccess1 函数中是怎么做的,代码如下:
hash := t.hasher(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
关键的代码是: hash&m,看到这个想起来了没,这就是与运算法,与运算法的公式就是: hash(key)&(bucket_nums - 1)。
与运算法其实就是将 hash值的低hmap.B位与bucket的最大索引进行&运算,例如hmap.B = 5, hash值为: 1001011100001111011011001000111100101010001001011001010101001010 ,可以得出,该map的bucket最大索引为31(可使用bucketMask函数得出), 则所落入的桶索引为:
hash值: 10010111000011110110110010001111001010100010010110010101010 01010
bucket最大索引: & 11111
----------------------------------------------------------------------------------------
01010 = 10
最终该hash会落入10号bucket。
问题三: 知道hash值,求此hash的 tophash 数组值?
前面讲述过,tophash数组存储的元素是key键值hash后的哈希值的高8字节,例如hash值为:1001011100001111011011001000111100101010001001011001010101001010 ,可以得出该hash值的tophash存储值为该hash高8位:10010111。
最后总结下mapaccess1 函数基本流程,如下图:
写入
Map 的赋值操作会被编译成不同函数调用,函数列表如下:
//go 1.20.3 path:/src/cmd/complie/internal/typecheck/_builtin/runtime.go
func mapassign(mapType *byte, hmap map[any]any, key *any) (val *any)
func mapassign_fast32(mapType *byte, hmap map[any]any, key uint32) (val *any)
func mapassign_fast32ptr(mapType *byte, hmap map[any]any, key unsafe.Pointer) (val *any)
func mapassign_fast64(mapType *byte, hmap map[any]any, key uint64) (val *any)
func mapassign_fast64ptr(mapType *byte, hmap map[any]any, key unsafe.Pointer) (val *any)
func mapassign_faststr(mapType *byte, hmap map[any]any, key string) (val *any)
编译器根据与不同类型调用不同函数,我们只用研究最一般的赋值函数 mapassign,其他函数大致流程一致。
mapassign函数源码如下:
//go 1.20.3 path: /src/runtime/map.go
//根据key值寻找一个用于存放 value 的内存地址
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
//h 为 nil,则panic返回,因为后续涉及存储以及操作,必须保证map已经初始化
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
//hashWriting 是个 flag 位,如果为 1 表示当前有一个 goroutine 正在写入,这是个 unrecoverable 的错误,读取时候如果遇到该状态,会直接崩
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
//计算hash
hash := t.hasher(key, uintptr(h.hash0))
//将h.flags设置 hashWriting 以标识当前正在写入
h.flags ^= hashWriting
//假如桶空间为nil,则初始化桶空间
if h.buckets == nil {
// 因为只有 B=0 时候会懒加载,所以这里值仅请了一个桶的空间
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
//根据与运算计算得出桶的index
bucket := hash & bucketMask(h.B)
// 如果当前正在扩容,那么就负责将当前命中的桶迁移掉,后面扩容部分详细介绍
if h.growing() {
growWork(t, h, bucket)
}
//计算出当前桶的地址
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
//获取 hash 的高 8 位
top := tophash(hash)
var inserti *uint8 // 记录 tophash 地址,判断空槽等使用
var insertk unsafe.Pointer // 记录 key 地址
var elem unsafe.Pointer //记录 value 地址
bucketloop:
for {
// 遍历 bucket 中的空位
for i := uintptr(0); i < bucketCnt; i++ {
//当前tophash不等于查询的tophash
if b.tophash[i] != top {
//如果当前槽位的tophash经过isEmpty判断返回emptyOne 或 emptyRest 并且 inserti == nil,则当前槽位为空槽位
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i] //记录tophash
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) //记录 key 地址
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) //记录 value 地址
}
// emptyRest 是特殊的 tophash,该值表明该位置为空,且后面也为空,可以拿来直接用
if b.tophash[i] == emptyRest {
//跳出bucketloop, goto done
break bucketloop
}
continue
}
//获取key,走到这里说明 tophash 已经找到, 那就把 key 拿出来确认下
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// 存储时候被转成指针存储的数据,需要取出指向的数据
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
//对比key值是否相等,如果不相等就跳出本次循环,进入下一个槽点
if !t.key.equal(key, k) {
continue
}
//key 原本就已经存在,判断下是否要更新 key,需要的话更新一下
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
//计算出value的地址
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
goto done
}
//当前桶未找到相关key,则获取溢出桶,从溢出桶中查找
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
/**
到达此处,说明未找到空桶并且没找到相关key值一致的相关槽点,需要新增元素
判断新增元素会触发扩容机制,扩容机制需要满足下列条件:
1. 当前map未在扩容中
2. 当前map的装载因子是否达到设定的6.5阈值或者当前map的溢出桶数量是否过多
如果满足扩容条件,进行扩容并且跳转到again处,重新尝试一次前面的查找流程
*/
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
// 循环并没有找到能用的空间,说明当前桶已满,需要创建溢出桶
if inserti == nil {
// 创建新的溢出桶
newb := h.newoverflow(t, b)
//获取新溢出桶的 tophash 数组的起始地址
inserti = &newb.tophash[0]
//获取新溢出桶的键的起始地址
insertk = add(unsafe.Pointer(newb), dataOffset)
// 获取新溢出桶的值的起始地址
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
// 如果键是指针类型,需要为键分配内存,并将指针存储到 insertk 中
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
// 如果值是指针类型,需要为值分配内存,并将指针存储到 elem 中
if t.indirectelem() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(elem) = vmem
}
// 将 key 复制到 insertk 中
typedmemmove(t.key, insertk, key)
//将 tophash 值设置为 top
*inserti = top
// 更新 hmap 的键值对数量加一
h.count++
done:
// 如果当前哈希表没有正在进行写操作,抛出致命错误
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
// 清除 hashWriting 标志位,表示写操作结束
h.flags &^= hashWriting
if t.indirectelem() {
// 如果值是指针类型,需要解引用获取真实的值
elem = *((*unsafe.Pointer)(elem))
}
// 返回最终的值
return elem
}
mapassign 的代码当中, 没有直接将 value 写入内存, 而是将 value 在内存当中的对应地址返回, 后续对内存地址写入 进行操作
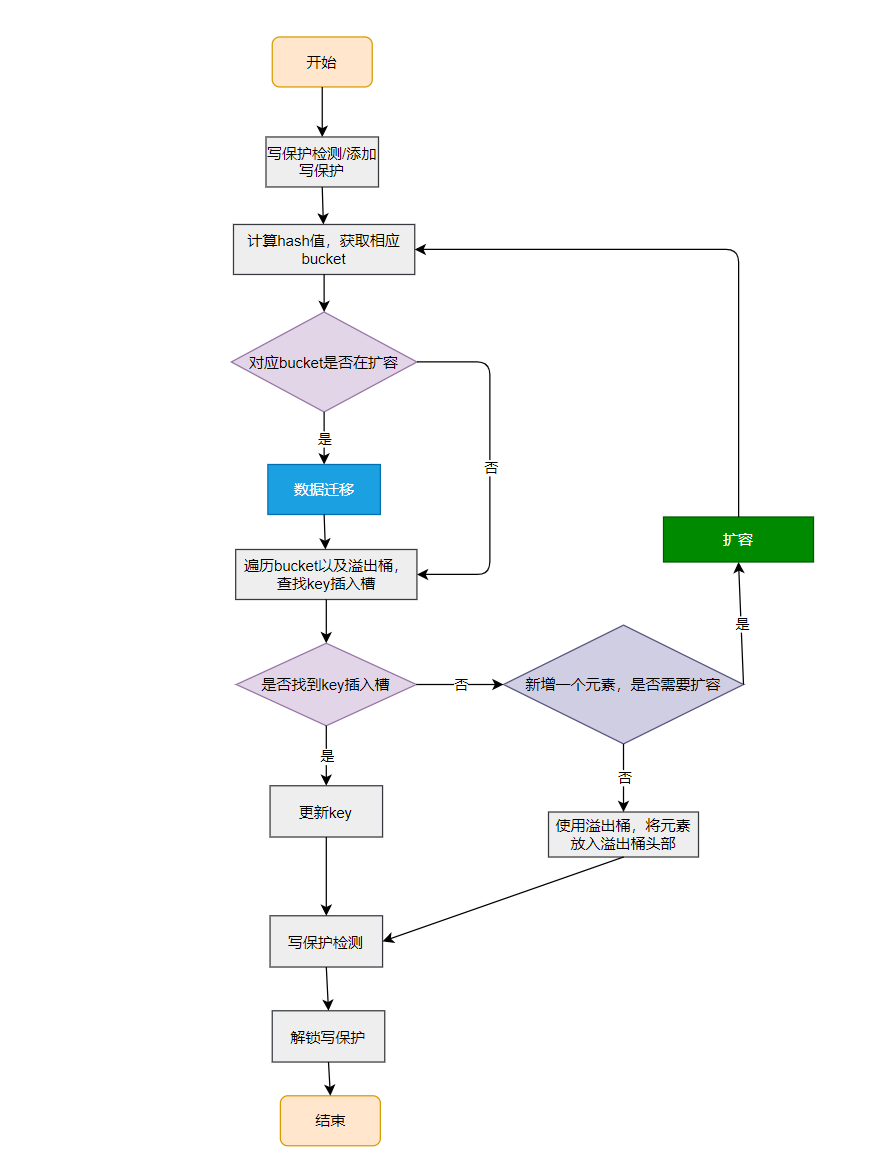
根据上面代码其这里总结一下流程:
- 检查哈希表是否为空。如果为空,抛出一个错误。
- 检查哈希表是否正在进行写操作。如果是,并发写操作将导致致命错误。
- 使用键值
key计算哈希值。 - 切换哈希表的写操作标志。
- 如果哈希表的桶为空,分配一个新的桶。
- 循环遍历桶和溢出桶,查找匹配的键值对:
- 如果找到匹配的键值对,更新对应的值并返回。
- 如果遇到空槽,准备插入新的键值对。
- 检查是否需要进行哈希表的扩容操作,如果需要,则执行扩容操作,并重新开始整个过程。
- 如果是没有找到插入位置,则说明需要创建溢出桶,插入新的键值对并分配内存并复制键值到对应的位置。
- 如果需要间接引用键或值,分配内存并将值写入对应的指针。
- 将新的键值对写入桶。
- 增加哈希表的计数。
- 检查哈希表的写操作标志,并取消标记。
- 如果需要,返回键对应的值。
下面对mapassign函数代码中涉及到一些辅助函数以及技术点进行分析。
辅助函数:
【1】isEmpty函数
func isEmpty(x uint8) bool {
return x <= emptyOne
}
isEmpty 函数用来判断map桶中的cell的元素是否为空,利用比较运算符 <= 来判断可以将条件判断简化为一行代码,并提高代码的可读性和简洁性。
【2】needkeyupdate函数
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
func (mt *maptype) needkeyupdate() bool {
return mt.flags&8 != 0
}
在对map做插入时,当发现插入的key已经存在时,正常流程只需要更新value的值,但当needkeyupdate函数返回为true时,还需要更新key的值,这是为什么呢?
在 Go 语言中,当使用非指针类型作为 map 的键时,键的值通常用于计算哈希值和进行键的比较操作。如果允许直接修改键的值,那么在修改后的值与原来的值不同时,就会导致哈希值和比较结果的不一致,进而破坏了 map 的内部数据结构的一致性。
为了避免这种情况发生,非指针类型的键被设计为不可变的。这意味着一旦创建了一个键值对并将其插入到 map 中,就不应该再修改键的值。如果需要更新键的值,通常的做法是创建一个新的键值对,使用新的键值对替换原来的键值对。
通过将非指针类型的键设计为不可变,可以确保 map 在进行哈希计算和键的比较时始终使用一致的值,从而保持 map 的正确性和一致性。此外,这也提醒了开发者在使用 map 时需要注意键的不可变性,避免可能的错误和意外行为。
【3】map扩容条件判断
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
从此代码可以看到,触发扩容有2种情况: overLoadFactor(h.count+1, h.B) == true 或者 tooManyOverflowBuckets(h.noverflow, h.B)) == true ,这分别对应下列两种情况:
-
负载因子超标
负载因子超标主要使用函数
overLoadFactor进行判断,该函数在【初始化】章节中已经详细分析过,可以回头看看,再次不再重复。 -
使用溢出桶过多
溢出桶过多,主要判断的函数
tooManyOverflowBuckets,源码如下://go 1.20.3 path: /src/runtime/map.go func tooManyOverflowBuckets(noverflow uint16, B uint8) bool { if B > 15 { B = 15 } return noverflow >= uint16(1)<<(B&15) }从代码判断溢出桶是否太多的规则如下:
- 当桶总数 < 2 15 时,如果溢出桶总数 >= 桶总数,则认为溢出桶过多。
- 当桶总数 >= 2 15 时,直接与 215 比较,当溢出桶总数 >= 2 15 时,即认为溢出桶太多了
其实 [使用溢出桶过多] 这个条件是对 [负载因子超标] 条件的补充,因为在负载因子比较小的情况下,有可能 map 的查找和插入效率也很低,而 [负载因子超标条件] 无法识别不出来这种情况。表面现象就是计算负载因子的分子比较小,即 map 里元素总数少,但是桶数量多(真实分配的桶数量多,包括大量的溢出桶),什么操作才会产生这种现象呢?不断的增删,这样会造成overflow的bucket数量增多,但负载因子又不高,未达到 [负载因子超标] 临界值,就不能触发扩容来缓解这种情况,这样会造成桶的使用率不高,值存储得比较稀疏,查找插入效率会变得非常低,因此有了 [使用溢出桶过多判断] 指标。这就像是一座空城,房子很多,但是住户很少,都分散了,找起人来很困难。
【4】溢出桶的函数
overflow以及setoverflow函数:
//go 1.20.3 path: /src/runtime/map.go
//bmap的溢出桶的指针定位
func (b *bmap) overflow(t *maptype) *bmap {
return *(**bmap)(add(unsafe.Pointer(b), uintptr(t.bucketsize)-goarch.PtrSize))
}
//bmap的溢出桶的指针设置
func (b *bmap) setoverflow(t *maptype, ovf *bmap) {
*(**bmap)(add(unsafe.Pointer(b), uintptr(t.bucketsize)-goarch.PtrSize)) = ovf
}
overflow 方法接收一个 maptype 参数,用于确定桶的大小,并返回当前桶的溢出桶指针。它通过将当前桶的地址加上桶的大小减去指针大小的偏移量,然后通过类型转换来获取溢出桶的指针。这个函数在遍历桶时,可以使用该方法获取当前桶的溢出桶。
setoverflow 方法接收一个 maptype 参数和一个溢出桶指针 ovf,用于设置当前桶的溢出桶指针。它通过将当前桶的地址加上桶的大小减去指针大小的偏移量,然后通过类型转换来设置溢出桶的指针。这个函数在创建新的溢出桶并将其链接到当前桶时使用。
这两个方法通过指针操作实现了溢出桶的获取和设置,用于在哈希表中处理溢出桶的相关操作。
createOverflow函数:
//go 1.20.3 path: /src/runtime/map.go
//创建hmap.extra结构
func (h *hmap) createOverflow() {
if h.extra == nil {
h.extra = new(mapextra)
}
if h.extra.overflow == nil {
h.extra.overflow = new([]*bmap)
}
}
这个函数的主要作用是创建 hmap.extra的结构,结构的创建目的是确保在需要创建溢出桶时,哈希表的 extra 字段和 overflow 字段都被正确地初始化。这样,在需要使用溢出桶时,可以直接使用 extra 和 overflow 字段来操作溢出桶的相关信息。
incrnoverflow函数:
//go 1.20.3 path: /src/runtime/map.go
//根据一定规则增加哈希表 hmap 的溢出桶计数, noverflow是一个近似计数
func (h *hmap) incrnoverflow() {
if h.B < 16 {
// 如果桶数小于16,则每次调用都增加溢出桶计数
h.noverflow++
return
}
// 计算掩码,用于确定是否增加溢出桶计数
mask := uint32(1)<<(h.B-15) - 1
// 通过与掩码进行按位与运算来决定是否增加溢出桶计数
if fastrand()&mask == 0 {
h.noverflow++
}
}
该函数的作用是根据一定规则增加哈希表 hmap 的溢出桶计数。
在 h.B < 16 的情况下,每次调用函数 incrnoverflow() 都会增加溢出桶计数 h.noverflow 的值。
在 h.B >= 16 的情况下,根据掩码 mask 和随机数的按位与运算结果,决定是否增加溢出桶计数。掩码 mask 是根据桶数 B 计算得到的,它具有以下特点:
mask在二进制表示中,第B-15位之前都为 1,之后都为 0。- 例如,当
B为 16 时,掩码mask的二进制表示为1111111111111110。
函数会调用 fastrand() 生成一个随机数,并与掩码 mask 进行按位与运算。按位与运算的结果为 0,表示随机数的二进制表示的第 B-15 位之前都为 0。
通过这种机制,当桶数较大时,每次调用函数 incrnoverflow() 增加溢出桶计数的概率较小。这样可以在一定程度上控制溢出桶的数量,以保持哈希表的负载均衡和性能。具体的规律是根据掩码和随机数的按位与运算结果决定的,这取决于具体的随机数生成算法和掩码的设置。
newoverflow函数:
//go 1.20.3 path: /src/runtime/map.go
func (h *hmap) newoverflow(t *maptype, b *bmap) *bmap {
var ovf *bmap
// 检查是否存在额外的溢出桶列表
if h.extra != nil && h.extra.nextOverflow != nil {
ovf = h.extra.nextOverflow
// 如果当前溢出桶的下一个溢出桶为空,则将下一个溢出桶设置为当前溢出桶之后的地址
// 否则,将当前溢出桶的下一个溢出桶设为nil,并重置下一个溢出桶为nil
if ovf.overflow(t) == nil {
h.extra.nextOverflow = (*bmap)(add(unsafe.Pointer(ovf), uintptr(t.bucketsize)))
} else {
ovf.setoverflow(t, nil)
h.extra.nextOverflow = nil
}
} else {
// 创建新的溢出桶
ovf = (*bmap)(newobject(t.bucket))
}
// 增加溢出桶计数
h.incrnoverflow()
// 如果桶中的键值对不包含指针数据,则需要创建溢出桶列表
if t.bucket.ptrdata == 0 {
h.createOverflow()
*h.extra.overflow = append(*h.extra.overflow, ovf)
}
// 设置桶的溢出指针为新的溢出桶
b.setoverflow(t, ovf)
return ovf
}
该函数的目的是管理哈希表中的溢出桶,确保当哈希表中的键值对数量超过桶的容量时,能够动态地创建新的溢出桶,并将其链接到正确的位置,以保持哈希表的正确性和性能。
技术点:
关于h.flags的位运算,在mapassign 函数中涉及到的代码如下:
// flags
const = (
iterator = 1 // there may be an iterator using buckets
oldIterator = 2 // there may be an iterator using oldbuckets
hashWriting = 4 // a goroutine is writing to the map
sameSizeGrow = 8 // the current map growth is to a new map of the same
)
//与运算
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
//异或运算
h.flags ^= hashWriting
代码中关于 h.flags值有四种,转换成二进制如下:
flags: 1 2 4 8
二进制: 0001 0010 0100 1000
--------------------------------------------------------------------------------------------------------------
从转换的对比可以看出,h.flags取值为了方便位运算,采取了不同二进制位上取1,其余位置取0后的结果。
对于 h.flags 这个表达式来说,& 和 ^ 的作用如下:
h.flags & hashWriting会将h.flags的值与hashWriting进行按位与操作,得到的结果是h.flags中只保留与hashWriting相对应的位的值,其它位都被清零。在mapassign函数中主要用来判断h.flags是否处于Writing状态。h.flags ^= hashWriting会将h.flags的值与hashWriting进行按位异或操作,得到的结果是h.flags中与hashWriting相对应的位取反,其它位保持不变。在mapassign函数中主要用来将h.flags值的状态更改为非Writing状态。
总结下mapassign 函数相关流程,如下图:
扩容
在前面写入章节中已经提到触发扩容的时机在这段代码:
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
......
}
从此代码可以看到,触发扩容有2种情况: overLoadFactor(h.count+1, h.B) == true 或者 tooManyOverflowBuckets(h.noverflow, h.B)) == true ,这分别对应下列两种情况:
-
负载因子超标
-
使用溢出桶过多
这边具体就不展开了,详情看前面【写入】章节的讲述。
针对触发扩容有两种情况,扩容算法根据这两种情况也做了区分:
-
针对 负载因子超标,将
B + 1,新建一个buckets数组,新的buckets大小是原来的2倍,然后旧buckets数据搬迁到新的buckets。该方法我们称之为增量扩容。 -
针对 使用溢出桶过多,并不扩大容量,
buckets数量维持不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取。该方法我们称之为等量扩容。其实存在一个极端的情况:如果插入 map 的 key 哈希都一样,那么它们就会落到同一个 bucket 里,超过 8 个就会产生 overflow bucket,结果也会造成 overflow bucket 数过多。移动元素其实解决不了问题,因为这时整个哈希表已经退化成了一个链表,操作效率变成了
O(n)。但 Go 的每一个 map 都会在初始化阶段的 makemap时定一个随机的哈希种子,所以要构造这种冲突是没那么容易的。
在源码中,扩容相关的主要是hashGrow()函数与growWork()函数。
hashGrow
扩容的开始逻辑在 runtime.hashGrow 函数之中,让我们看源码:
//go 1.20.3 path: /src/runtime/map.go
//分配内存地址,做好了迁移准备,并没有真正迁移数据
func hashGrow(t *maptype, h *hmap) {
/**
bigger 保存了本次操作 B 的增量,等量扩容设置为 0,增量扩容设置为 1
下面判断是否负载因子超标,如果超标则使用增量扩容,未超标则使用等量扩容,并标注h.flags
*/
bigger := uint8(1)
//map元素比例并未超过负载因子,做等量扩容
if !overLoadFactor(h.count+1, h.B) {
//则将 `bigger` 设置为 0,表示不增加桶的数量,并标记哈希表为 `sameSizeGrow`,表示扩容后的桶数量与原桶数量相同
bigger = 0
h.flags |= sameSizeGrow
}
/**
将当前buckets地址赋值给oldbuckets
调用 `makeBucketArray` 函数创建新的桶数组,并计算下一个溢出桶
*/
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
//将哈希表的标志位中的 iterator 和 oldIterator 标记清除
flags := h.flags &^ (iterator | oldIterator)
// 如果哈希表正在进行迭代操作,则保留 `iterator` 和 `oldIterator` 的标记
if h.flags&iterator != 0 {
flags |= oldIterator
}
//更新哈希表的桶数量和标志位
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets // 换桶
h.nevacuate = 0 //迁移进度为0
h.noverflow = 0 //溢出桶数量为0
// 处理额外的溢出桶
if h.extra != nil && h.extra.overflow != nil {
// 如果旧的溢出桶不为空,抛出异常,表示不应该存在旧的溢出桶
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
// 将当前的溢出桶作为旧的溢出桶,并清空当前溢出桶
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
//如果 makeBucketArray 函数创建了新的溢出桶,将下一个溢出桶设置为新的溢出桶
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}
函数的主要流程:
- 判断是否需要增大哈希表的大小:
- 如果当前哈希表的负载因子不超过阈值,则不需要增大大小,将
bigger设置为 0,同时将sameSizeGrow标志位置为 1。 - 否则,需要增大双倍大小,将
bigger设置为 1,同时清除sameSizeGrow标志位。
- 如果当前哈希表的负载因子不超过阈值,则不需要增大大小,将
- 保存旧的桶数组和迁移溢出桶:
- 将旧的桶数组保存在
oldbuckets变量中。 - 调用
makeBucketArray函数创建新的桶数组newbuckets(桶数组大小根据bigger决定,如果bigger为1则新桶数组为原来桶数组2倍,否则等于原桶数组长度),并返回下一个迁移的溢出桶。 - 更新哈希表的相关字段:
B值增加bigger,更新标志位flags,将oldbuckets设置为保存的旧桶数组,将buckets设置为新的桶数组,将nevacuate和noverflow重置为 0。
- 将旧的桶数组保存在
- 处理额外的溢出桶:
- 如果存在额外的溢出桶,并且旧的溢出桶为空,将旧的溢出桶设置为当前溢出桶,并清空当前溢出桶。
- 如果存在下一个迁移的溢出桶,则创建新的
mapextra结构,并将其设置为哈希表的extra字段,将下一个迁移的溢出桶链接到extra的nextOverflow字段。
流程如图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4XvhWQlS-1684891129811)(https://xjxpicgo.oss-cn-hangzhou.aliyuncs.com/1%20(1)].jpg)
hashGrow() 函数实际上并没有真正地“搬迁”,它只是分配好了新的 buckets,并将老的 buckets 挂到了 oldbuckets 字段上。因为map 采用的是渐进扩容的方式,避免因为一次性的全量数据迁移引发性能抖动。
growWork
而真正搬迁 buckets 的动作在 growWork() 函数中,而调用 growWork() 函数的动作是在mapassign() 和 mapdelete() 函数中。也就是插入(包括修改)、删除 key 的时候,都会尝试进行搬迁 buckets 的工作。
growWork 函数调用:
//go 1.20.3 path: /src/runtime/map.go
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
......
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
......
}
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
......
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
......
}
growWork 函数源码如下:
func growWork(t *maptype, h *hmap, bucket uintptr) {
/**
bucket 是新桶的位置
oldbucketmask 返回的是扩容之前的哈希掩码,而传入的 bucket 参数是新桶中的位置
bucket & oldbucketmask 算出了目标桶在旧桶中的位置
*/
evacuate(t, h, bucket&h.oldbucketmask())
//如果搬迁任务还没完成,需要肩负额外迁移一个 bucket 的任务,以加快进度
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
当每次触发写、删操作时,会先检查 oldbuckets 是否搬迁完毕(检查 oldbuckets 是否为 nil),再决定是否进行搬迁工作。搬迁也只会为处于扩容流程中的 map 最多完成两组桶的数据迁移:
- 一组桶是当前写、删操作所命中的桶;
- 另一组桶是,当前未迁移的桶中,索引最小的那个桶。
evacuate
实际迁移逻辑在 evacuate 里,runtime.evacuate代码较长,将分为几块内容去说明。
为了准备进行桶迁移操作,runtime.evacuate会将一个旧桶中的数据分流到两个新桶,其中 x 表示主目标桶,y 表示备用目标,该步骤代码为:
//go 1.20.3 path: /src/runtime/map.go
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
//定位当前bucket在旧桶的起始地址
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
//获取旧桶的数量
newbit := h.noldbuckets()
//如果b桶尚未被迁移过
if !evacuated(b) {
//声明一个长度为2的数组xy,数组元素为evacDst类型
var xy [2]evacDst
//x指向xy数组的第一个元素,用于存放旧桶迁移后的目标新桶
x := &xy[0]
//x.b指向当前bucket在新桶的起始地址
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
//x.k指向新桶键数组的起始地址
x.k = add(unsafe.Pointer(x.b), dataOffset)
//x.e指向新桶值数组的起始地址
x.e = add(x.k, bucketCnt*uintptr(t.keysize))
//如果当前bucket不是等量扩容,即新桶的大小不等于旧桶的大小,则需要为y分配新桶
if !h.sameSizeGrow() {
//y指向xy数组的第二个元素,属于扩容后旧桶需要迁移到的第二个目标新桶
y := &xy[1]
//y.b指向当前bucket在新桶的起始地址
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
//y.k指向新桶键数组的起始地址
y.k = add(unsafe.Pointer(y.b), dataOffset)
//y.e指向新桶值数组的起始地址
y.e = add(y.k, bucketCnt*uintptr(t.keysize))
}
......
}
该代码块的目的是为了进行桶迁移操作前做的准备,迁移过程中数据会根据情况分流到不同桶中,而迁移前需要确立数据被分流到哪个桶,就是这步骤做的工作。而记录分流桶信息,保存分配上下文的则用的是 evacDst结构体,上面说的 x和 y桶,就是属于evacDst结构,他们并不是真正用来存储数据的桶,而是记录分配信息的用来。
来看evacDst结构:
type evacDst struct {
b *bmap // 表示目标桶的指针。在哈希表的扩容过程中,旧桶中的元素需要被迁移到对应的目标桶中。
i int // 表示目标桶中元素的索引位置。通过索引位置可以确定元素在目标桶中的存储位置。
k unsafe.Pointer // 表示键(key)的指针。在迁移过程中,需要将元素的键从旧桶复制到目标桶的相应位置。
e unsafe.Pointer // 表示值(value)的指针。在迁移过程中,需要将元素的值从旧桶复制到目标桶的相应位置。
}
这个结构体用于记录迁移目标的信息,方便进行元素的复制和存储操作。通过 evacDst 结构体的实例,可以知道元素应该被迁移到哪个目标桶的哪个索引位置,并且可以获取键和值的指针,实现迁移操作。
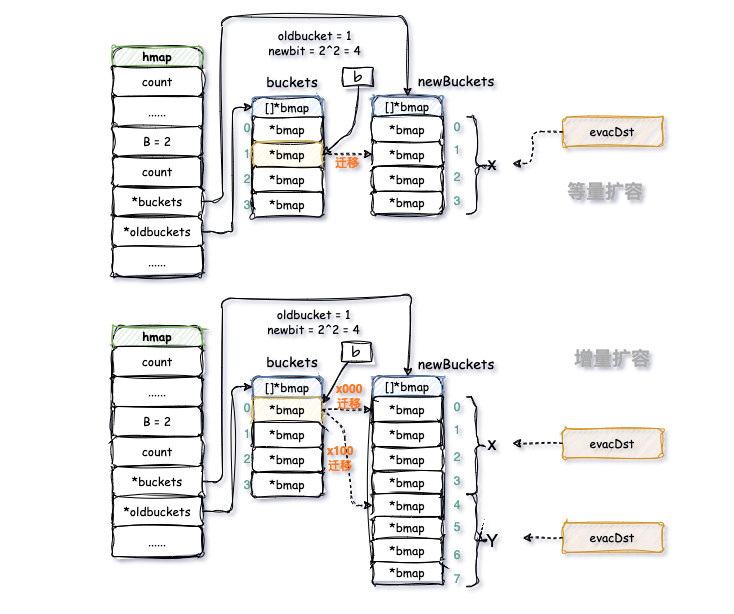
再来说说分桶的算法策略:
- 如果
map等量扩容,那么旧桶与新桶之间是一对一的关系,所以只会初始化x记录桶信息,我们成为x桶; - 如果
map增量扩容,那么每个旧桶的元素会可能会分流到新创建的两个桶中,初始化x和y记录桶信息,我们成为x桶和y桶。
我们举个例子说明下这两种算法策略,便于更好的理解他们。
(1)等量扩容
这个很好理解,假如扩容前该key所在的是1号桶,那么扩容后,该key在新桶的位置不变,也是1号桶。这个没啥好解释,就是所属桶的索引不变。
(2)增量扩容
假如有个hash值尾号为:xxxx00,我们旧桶数量是4个,新桶数量就是8个。
那么之前获取桶索引的方式如下:
hash值: xxxx00
桶索引最大值3: & 11
----------------------
00
这样的话原本这个 hash值的 key 就会存储到 0 号桶,扩容后新桶树变成8,获取桶索引的方式如下:
hash值: xxxx00
桶索引最大值7: & 111
----------------------
x00
得到的值x00,具体到底哪个桶,取决于x值。:
如果hash的末尾三位是 000 ,则与运算值为000 ,则分配到0号桶;
如果hash的末尾三位是 100 ,则与运算值为100 ,则分配到4号桶。
这个原理就是: 扩容后,由于容量翻倍 B 会 +1,在做与运算定位时候,就会多释放出一位掩码,与运算的结果除了多释放出的这一位,其余位应该和元本意义,而多释放出的这一位,会用来决定元素放在 x,还是 y。
用图来直观的表示下:
继续往下看evacuate 代码,接下来是关于迁移部分内容代码:
//go 1.20.3 path: /src/runtime/map.go
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
......
if !evacuated(b) {
......
//遍历旧桶以及溢出桶的每个元素
for ; b != nil; b = b.overflow(t) {
//获取当前桶的键起始的指针
k := add(unsafe.Pointer(b), dataOffset)
//获取当前桶的值起始的指针
e := add(k, bucketCnt*uintptr(t.keysize))
//遍历当前桶的每个元素
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {
//获取当前元素的tophash
top := b.tophash[i]
//如果当前元素的tophash为empty,则将当前元素的tophash设置为evacuatedEmpty(已搬迁空元素)
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
//如果当当前元素tophash小于minTopHash,则抛出异常
if top < minTopHash {
throw("bad map state")
}
k2 := k
//如果键是间接存储的,则获取键的实际指针
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
// 定义一个变量,用来表示当前键值对应该迁移到哪个新桶(x或y)
var useY uint8
//如果当前map为增量扩容
if !h.sameSizeGrow() {
//获取当前元素的hash值
hash := t.hasher(k2, uintptr(h.hash0))
// 如果有迭代器正在遍历,并且键不是自反的,并且键不相等,就需要保持原来的新桶位置
if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) {
/**
有一个特殊情况: 有一种 key, 每次对它计算 hash, 得到的结果都不一样.
这个 key 就是 math.NaN() 的结果, 它的含义是 not a number, 类型是 float64.
当它作为 map 的 key时, 会遇到一个问题: 再次计算它的哈希值和它当初插入 map 时的计算出来的哈希值不一样
这个 key 是永远不会被 Get 操作获取的! 当使用 m[math.NaN()] 语句的时候, 是查不出来结果的,这个 key 只有在遍历整个 map 的时候, 才能被找到
并且, 可以向一个 map 插入多个数量的 math.NaN() 作为 key, 它们并不会被互相覆盖
当搬迁碰到 math.NaN() 的 key 时, 只通过 tophash 的最低位决定分配到 X part 还 Y part (如果扩容后是原来 buckets 数量的 2 倍).
如果 tophash 的最低位是 0, 分配到 X part; 如果是 1, 则分配到 Y part.
*/
//取原来的哈希值高8位的最低位作为新桶位置
useY = top & 1
//更新哈希值高8位
top = tophash(hash)
} else {
// 否则根据哈希值的最高位来确定新桶位置
if hash&newbit != 0 {
//如果最高位为1,就迁移到y桶
useY = 1
}
}
}
// 检查迁移标记是否合法
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// 将当前键值对标记为已迁移,并记录新桶位置
b.tophash[i] = evacuatedX + useY
// 获取新桶的地址和索引
dst := &xy[useY]
// 如果新桶已满,就分配一个溢出桶,并更新地址和索引
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.keysize))
}
// 将当前键值对的哈希值高8位写入新桶中
dst.b.tophash[dst.i&(bucketCnt-1)] = top
// 将当前键复制到新桶中,如果是间接存储的话,就复制指针,否则就复制实际数据
if t.indirectkey() {
*(*unsafe.Pointer)(dst.k) = k2
} else {
typedmemmove(t.key, dst.k, k)
}
// 将当前元素复制到新桶中,如果是间接存储的话,就复制指针,否则就复制实际数据
if t.indirectelem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.elem, dst.e, e)
}
// 更新新桶的地址和索引,准备下一次迁移
dst.i++
dst.k = add(dst.k, uintptr(t.keysize))
dst.e = add(dst.e, uintptr(t.elemsize))
}
}
// 如果没有协程在使用老的桶, 就对老的桶进行清理, 用于帮助gc
if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {
//定义变量 b,指向旧桶数组中的指定旧桶(根据 oldbucket 计算得到)
//这里的 b 是私有局部变量. 要和循环当中的 b 区别开来
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
// 定义变量 ptr,指向旧桶中键值对数据的起始位置(偏移 dataOffset)
ptr := add(b, dataOffset)
// 计算需要清零的字节数,即桶中键值对数据的总大小减去偏移 dataOffset
// 只清除bucket 的 key,value 部分, 保留 top hash 部分, 指示搬迁状态
n := uintptr(t.bucketsize) - dataOffset
// 使用 memclrHasPointers 函数将 ptr 指向的内存区域清零,该内存区域包含指针数据
memclrHasPointers(ptr, n)
}
}
// 更新搬移进度
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
这块代码主要流程为:
- 遍历旧桶中的每个键值对,进行迁移操作:
- 如果键值对的
tophash为evacuatedEmpty,表示该位置的键值对已被迁移,无需处理,继续下一个位置。 - 否则,获取键的指针
k和元素的指针e。 - 判断桶的类型
t是否为间接键类型,如果是,则从指针k中获取实际键的指针。 - 根据哈希值计算新桶的索引,并确定新桶中的位置信息。
- 将旧桶中的键值对迁移到新桶中的对应位置,并更新迁移后的
tophash值。 - 更新新桶中位置信息的计数器,并移动指针
k和e到下一个位置。
- 如果键值对的
- 迁移完成后,更新哈希表
h的相关状态:- 清空旧桶中的键值对数据。
- 更新桶的数量和溢出桶的数量。
- 如果存在额外的溢出桶链表,则将其更新到哈希表的
extra字段。
runtime.evacuate最后会调用runtime.advanceEvacuationMark 增加哈希的 nevacuate 计数器并在所有的旧桶都被分流后清空哈希的 oldbuckets 和 oldoverflow:
//go 1.20.3 path: /src/runtime/map.go
// 更新搬移进度
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
// 搬迁桶的进度加一
h.nevacuate++
// 实验表明, 1024至少会比newbit高出一个数量级 (newbit代表扩容之前老的bucket个数).
// 所以, 用当前进度加上1024用于确保O(1)行为.
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
//bucketEvacuated 内部通过判断 tophash 是否在迁移标示的范围:tophash[0] > emptyOne && tophash[0] < minTopHash,来确定是否已经迁移过了
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
// 这个等式成立,表明已全部迁移,可以清理旧数据了
if h.nevacuate == newbit {
h.oldbuckets = nil
if h.extra != nil {
// 释放掉溢出桶的指针
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}
至此搬迁工作完成,流程基本上注释很明了,不多说了。
简单总结一下哈希表扩容的设计和原理,哈希在存储元素过多时会触发扩容操作,每次都会将桶的数量翻倍,扩容过程不是原子的,而是通过 runtime.growWork增量触发的,在扩容期间访问哈希表时会使用旧桶,向哈希表写入/删除数据时会触发旧桶元素的分流。除了这种正常的扩容之外,为了解决大量写入、删除造成的内存泄漏问题,哈希引入了 sameSizeGrow 这一机制,在出现较多溢出桶时会整理哈希的内存减少空间的占用。
删除
如果想要删除哈希中的元素,就需要使用 Go 语言中的 delete 关键字,这个关键字的唯一作用就是将某一个键对应的元素从哈希表中删除,无论是该键对应的值是否存在,这个内建的函数都不会返回任何的结果。
在编译期间,delete 关键字会被转换成操作为 ODELETE 的节点,会将 ODELETE 节点转换成 runtime.mapdelete函数簇中的一个,包括 runtime.mapdelete、mapdelete_faststr、mapdelete_fast32 和 mapdelete_fast64:
//go 1.20.3 path: /src/cmd/compile/internal/typecheck/_builtin/runtime.go
func mapdelete(mapType *byte, hmap map[any]any, key *any)
func mapdelete_fast32(mapType *byte, hmap map[any]any, key uint32)
func mapdelete_fast64(mapType *byte, hmap map[any]any, key uint64)
func mapdelete_faststr(mapType *byte, hmap map[any]any, key string)
这些函数的实现其实差不多,我们挑选其中的 runtime.mapdelete分析一下。哈希表的删除逻辑与写入逻辑很相似,只是触发哈希的删除需要使用关键字,如果在删除期间遇到了哈希表的扩容,就会分流桶中的元素,分流结束之后会找到桶中的目标元素完成键值对的删除工作。
看下 runtime.mapdelete 源码:
//go 1.20.3 path: /src/runtime/map.go
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
......
//如果哈希表为空或者没有元素,直接返回
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734
}
return
}
//如果哈希表正在被写入,报错并退出
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
//计算hash值
hash := t.hasher(key, uintptr(h.hash0))
//开启写保护
h.flags ^= hashWriting
//通过与运算计算bucket索引
bucket := hash & bucketMask(h.B)
// 如果哈希表正在扩容状态,执行扩容操作,负责该桶搬迁工作
if h.growing() {
growWork(t, h, bucket)
}
//找到对应的桶指针地址(bmap结构体)
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
bOrig := b
//获取hash的tophash值(高8位)
top := tophash(hash)
search:
//遍历b桶以及溢出桶
for ; b != nil; b = b.overflow(t) {
//遍历该桶的每个元素
for i := uintptr(0); i < bucketCnt; i++ {
/**
槽点tophash值不等于要删除的tophash值,进行下面操作:
1. 如果当前tophash值为emptyRest,则表示后续都是空槽点,跳出搜索
2. 否则跳出本次搜索,进行下一个槽点搜索
*/
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break search
}
continue
}
//走到这里说明 tophash 是匹配的,取出 key 看看,计算得到该key的指针地址
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
k2 := k
//如果键是间接存储的,获取键的实际地址
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
//判断键值是否一致,不一致则跳出本次搜索
if !t.key.equal(key, k2) {
continue
}
// 如果键是间接存储的,将指针置为nil,否则,如果值包含指针,清除内存
if t.indirectkey() {
*(*unsafe.Pointer)(k) = nil
} else if t.key.ptrdata != 0 {
memclrHasPointers(k, t.key.size)
}
//获取value指针地址
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
// 如果值是间接存储的,将指针置为nil,否则,如果值包含指针,清除内存
if t.indirectelem() {
*(*unsafe.Pointer)(e) = nil
} else if t.elem.ptrdata != 0 {
memclrHasPointers(e, t.elem.size)
} else {
memclrNoHeapPointers(e, t.elem.size)
}
//将桶哈希值置为emptyOne,表示已删除
b.tophash[i] = emptyOne
// 判断是否是桶中最后一个元素
if i == bucketCnt-1 {
// 如果有溢出桶,并且溢出桶不为空,说明不是最后一个元素,跳转到notLast
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
//如果后面还有元素,说明不是最后一个元素,跳转到notLast
if b.tophash[i+1] != emptyRest {
goto notLast
}
}
/**
到此流程,说明该槽位后续槽位也是emptyRset值
此处是将一堆emptyOne状态结束的桶的槽位值更改为emptyRest状态
跳出本循环的两种情况:
1. 遇到桶内的第一个 bucket. 注意: 桶实质上就是一个单向的链表.
2. 遇到 cell 的 tophash 非删除状态(emptyOne)
*/
for {
b.tophash[i] = emptyRest
// 如果是桶的第一个元素,并且不是原始桶,回退到上一个桶
if i == 0 {
if b == bOrig {
break
}
c := b
//获取当前 bucket 的前面的 prev bucket(即 prev bucket 的 overflow 是当前 bucket)
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
// 如果遇到非空元素,结束循环
if b.tophash[i] != emptyOne {
break
}
}
notLast:
// 哈希表的元素个数减一
h.count--
// 如果哈希表为空,重新生成哈希种子
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}
//再次判断写屏障
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
//去除写保护
h.flags &^= hashWriting
}
这个函数的流程大致如下:
- 检查哈希表是否为空或者没有元素,如果是,直接返回。
- 检查哈希表是否正在被写入,如果是,报错并退出。
- 计算键的哈希值,并根据哈希值找到对应的桶。
- 检查哈希表是否正在扩容,如果是,执行扩容操作。
- 在桶中查找键值对,如果找到,删除它们,并更新桶的顶部哈希值。
- 更新哈希表的元素个数和哈希种子。
- 清除哈希表的写入标志位。
遍历
经常听说过这样一句话,map遍历是无序的,它并不按照存入先后输出,而是随机输出的,这是为什么呢?带着这个问题,我们来了解map遍历。
示例:
func main() {
m := map[int]int{1: 1, 2: 2, 3: 3}
for k, v := range m {
fmt.Println(k, v)
}
}
反编译代码 go build -gcflags=-S main.go >& 1.txt,得到汇编代码:
main.main STEXT size=497 args=0x0 locals=0x178 funcid=0x0 align=0x0
0x0000 00000 TEXT main.main(SB), ABIInternal, $376-0
......
0x0113 00275 LEAQ type:map[int]int(SB), AX
0x011a 00282 LEAQ main..autotmp_12+224(SP), BX
0x0122 00290 LEAQ main..autotmp_9+272(SP), CX
0x012a 00298 PCDATA $1, $2
0x012a 00298 CALL runtime.mapiterinit(SB)
0x012f 00303 JMP 454
0x0134 00308 MOVQ main..autotmp_9+280(SP), DX
0x013c 00316 MOVQ (CX), AX
0x013f 00319 MOVQ (DX), CX
0x0142 00322 MOVQ CX, main.v+40(SP)
0x0147 00327 MOVUPS X15, main..autotmp_22+192(SP)
0x0150 00336 MOVUPS X15, main..autotmp_22+208(SP)
......
从汇编代码上看,是runtime.mapiterinit的作用,这个函数什么作用呢?一起分析下源码:
func mapiterinit(t *maptype, h *hmap, it *hiter) {
// 将迭代器的类型和哈希表指针赋值。
it.t = t
// 如果哈希表为空或者没有元素,直接返回。
if h == nil || h.count == 0 {
return
}
// 检查迭代器结构体的大小是否正确。
if unsafe.Sizeof(hiter{})/goarch.PtrSize != 12 {
throw("hash_iter size incorrect")
}
it.h = h
// 将迭代器的桶数和桶数组指针赋值。
it.B = h.B
it.buckets = h.buckets
// 如果桶结构体不包含指针,创建溢出桶。
if t.bucket.ptrdata == 0 {
h.createOverflow()
// 将迭代器的溢出桶和旧溢出桶指针赋值。
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}
// 生成一个随机数,用于确定迭代器的起始桶和偏移量。
var r uintptr
if h.B > 31-bucketCntBits {
r = uintptr(fastrand64())
} else {
r = uintptr(fastrand())
}
// 根据随机数和哈希表的桶数,计算起始桶的索引。
it.startBucket = r & bucketMask(h.B)
// 根据随机数和每个桶的元素个数,计算偏移量。
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// 将迭代器的当前桶赋值为起始桶。
it.bucket = it.startBucket
// 如果哈希表的标志位没有表示有迭代器或者有旧迭代器,将其设置为有迭代器和有旧迭代器。
if old := h.flags; old&(iterator|oldIterator) != iterator|oldIterator {
atomic.Or8(&h.flags, iterator|oldIterator)
}
// 调用mapiternext函数,开始迭代哈希表。
mapiternext(it)
}
在代码中,系统生成了生成一个随机数,用于确定迭代器的起始桶和偏移量,就是这个随机数,让map变成了无序。那为什么明明逻辑上可以有序,却要加入随机数?
其实主要是因为 map 在扩容后,可能会将部分 key 移至新内存,那么这一部分实际上就已经是无序的了。而遍历的过程,其实就是按顺序遍历内存地址,同时按顺序遍历内存地址中的 key。但这时已经是无序的了。所以GO开发者 才在源码中加上随机的元素,将遍历 map 的顺序随机化,用来防止使用者用来顺序遍历。而这是有风险的代码,在GO 的严格语法规则下,是坚决不提倡的。
小结
Go 语言中的 Map 的底层实现,下面是一个简要总结:
Map是Go语言中的一种数据结构,用于存储键值对。它提供了高效的查找、插入和删除操作。Map的底层实现是一个哈希表(Hash Table),也被称为散列表。哈希表基于键来进行快速查找和存储。- 哈希表由一个桶(
Bucket)数组组成,每个桶存储一个或多个键值对。 - 在哈希表中,键通过哈希函数转换为桶的索引位置。哈希函数将键的内容映射为一个整数值,用于确定键值对在桶数组中的位置。
- 如果多个键映射到相同的桶索引位置,称为哈希冲突。为了解决冲突,每个桶中使用了一个链表或者平衡树来存储具有相同桶索引的键值对。
- 为了提高性能,在桶数组大小和键值对数量之间保持一个负载因子(
Load Factor)的阈值。当负载因子超过阈值时,哈希表会进行扩容操作,重新分配更大的桶数组,以减少哈希冲突并保持高效性能。 - 扩容操作涉及到重新哈希,即重新计算所有键的哈希值和桶索引。这可能会导致整个哈希表的重建,因此在扩容过程中需要重新分配内存和迁移键值对。
Map的迭代顺序是随机的,不保证顺序稳定性。如果需要按照特定顺序迭代Map,可以使用额外的数据结构(如Slice)来保存键,并根据需要进行排序。- 在并发环境下使用
Map需要采取适当的同步措施,例如使用互斥锁(Mutex)来保护对Map的并发访问。
总的来说,Map 是一种高效的键值对存储结构,基于哈希表实现。它提供了快速的查找和插入操作,并可以自动扩容以适应键值对的增长。使用 Map 时需要注意并发访问的安全性,以及迭代顺序的不确定性。
参考资料:
【Go 语言设计与实现】https://draveness.me/golang/docs/part2-foundation/ch03-datastructure/golang-hashmap/#33-%E5%93%88%E5%B8%8C%E8%A1%A8
【机器铃砍菜刀】https://zhuanlan.zhihu.com/p/273666774
【bunnier】https://juejin.cn/post/7079964047893856293















 319
319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









