






第六章 存储器层次结构
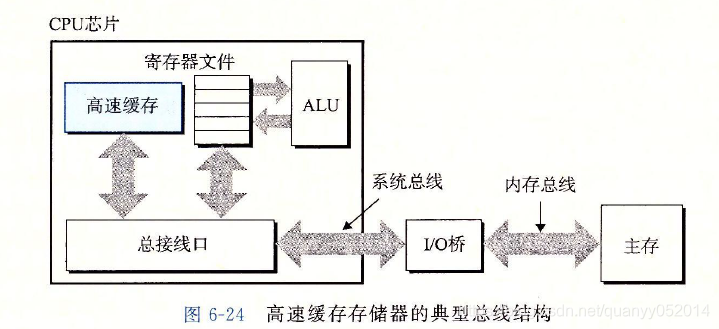
标准的CPU架构
CPU主要由以下几部分组成,参考下图
- 一系列寄存器,部分处理地址相关的寄存器,和其他一些用于处理数据的寄存器
- ALU,算数逻辑运算单元
- CU,控制单元,控制多个寄存器传输之间的时序等
- 内部一些寄存器之间的连线
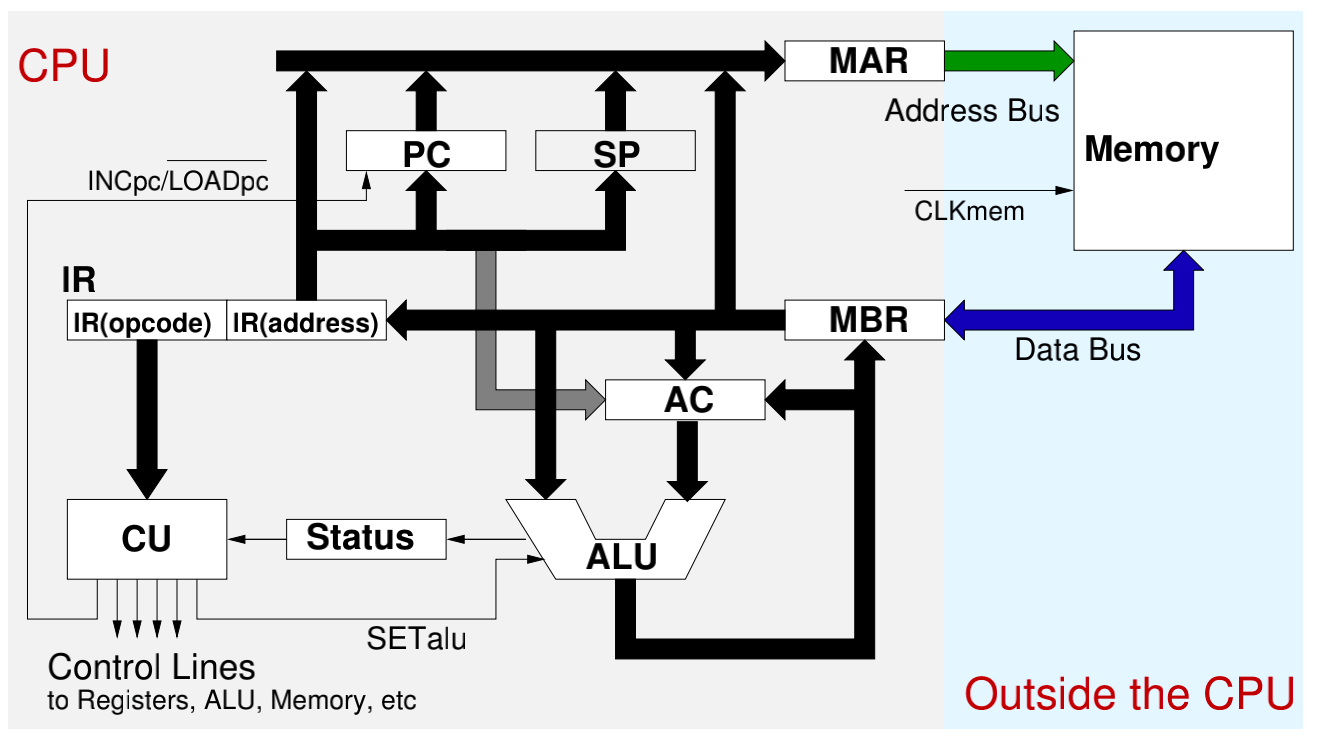
CPU寄存器介绍
MAR(Memory Address Register):保存需要访问的内存的地址;
MBR(Memory Buffer Register):保存需要写入寄存器或从内存中读取的数据;
PC(Programmer Counter):程序计数器(Program Counter,PC)用来指出下一条指令在主存储器中的地址。
在程序执行之前,首先必须将程序的首地址,即程序第一条指令所在主存单元的地址送入PC,因此PC的内容即是从主存提取的第一条指令的地址。
当执行指令时,CPU能自动递增PC的内容,使其始终保存将要执行的下一条指令的主存地址,为取下一条指令做好准备。若为单字长指令,则(PC)+1àPC,若为双字长指令,则(PC)+2àPC,以此类推。
但是,当遇到转移指令时,下一条指令的地址将由转移指令的地址码字段来指定,而不是像通常的那样通过顺序递增PC的内容来取得。
IR(Instruction Register):读取内存的时候,首先会从MBR寄存器中读取数据;如果读取的数据是一条指令的话,从IR里面读取;
IR包含下面两个部分:
1.IR(opcode):每一条指令的opcode都是唯一的,也是一条指令最重要的组成部分,CPU通过opcode了解当前指令到底干什么事情
2.IR(address):另一个重要的部分就是address部分
指令寄存器(Instruction Register,IR)用来保存当前正在执行的一条指令。
当执行一条指令时,首先把该指令从主存读取到数据寄存器中,然后再传送至指令寄存器。
指令包括操作码和地址码两个字段,为了执行指令,必须对操作码进行测试,识别出所要求的操作,指令译码器(Instruction Decoder,ID)就是完成这项工作的。指令译码器对指令寄存器的操作码部分进行译码,以产生指令所要求操作的控制电位,并将其送到微操作控制线路上,在时序部件定时信号的作用下,产生具体的操作控制信号。
指令寄存器中操作码字段的输出就是指令译码器的输入。操作码一经译码,即可向操作控制器发出具体操作的特定信号。
SP(Stack Pointer):栈指针,存放了当前程序的执行过程中内存中的栈地址
1.2 CPU内部单元
CU(Control Unit):控制单元,控制时序和指令的执行之后寄存器的变化
ALU(Arithmetic Logic Unit):算术运算单元,包含算术运算所需的逻辑与、逻辑或等模块
SR(Status Register):状态寄存器,根据ALU的计算结果控制状态寄存器中的一些状态标志,包括一些溢出(Overflow)、零(Zero)、负(Negative)等标识位
AC(Accumulator) 累加寄存器通常简称累加器,是一个通用寄存器。
累加器的功能是:当运算器的算术逻辑单元ALU执行算术或逻辑运算时,为ALU提供一个工作区,可以为ALU暂时保存一个操作数或运算结果。
显然,运算器中至少要有一个累加寄存器。
2.提取、解码和执行指令
2.1 CPU如何处理指令
处理指令的步骤主要包括以下几步:
1.从内存中提取(Fetch)指令,并把指令放到IR中;
2.解码(Decode)当前指令
3.执行(Execute)当前指令
执行的执行流程一般遵循以下步骤:
1.将PC的值存入MAR寄存器,
MAR<---PC
2.读取MAR中的值,将数据放入MBR寄存器中
MBR<---{MAR}
3.下一步需要将MBR中的值拷贝到IR寄存器中,IR解释执行当前指令后PC加1(本文介绍的指令为8位指令指令,因此PC加1,对于16位及32位指令,PC需要加对应的字节数)
PC<----PC + 1
列举一条指令(LDA x)的执行过程 (LDA 将存储器装入累加器或变址X指定的存储器)
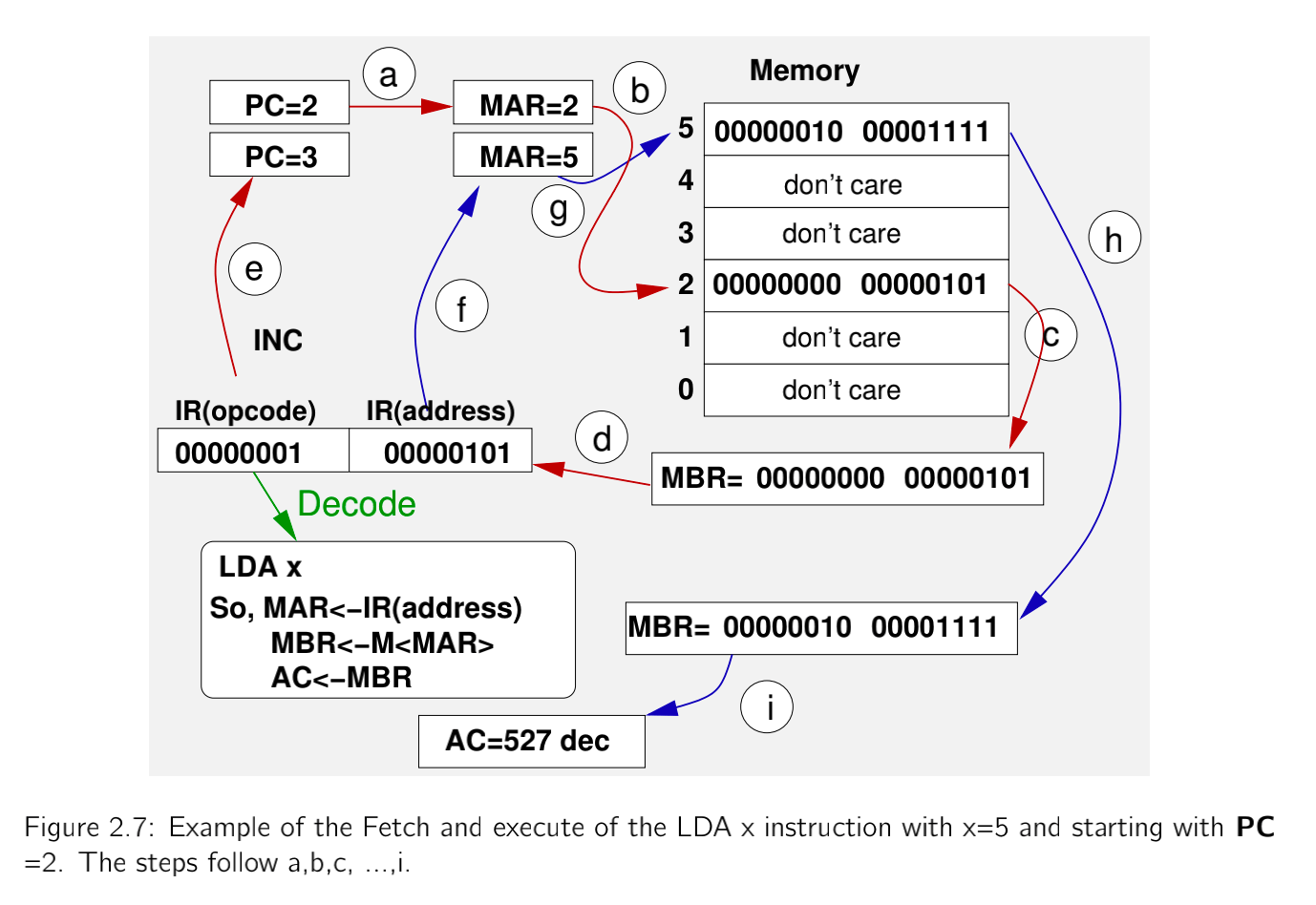
以上图为例可归结为以下几个步骤:
a.指令提取阶段,将PC值先赋值给MAR
b.地址的值为"2"
c.从内存为"2" 的地方将指令提取出来,存入MBR中
d.MBR的值写入IR寄存器
e.PC需要加一
f.解码当前IR中的指令,获取到opcode部分的值为1
g.Address部分的值为"5"
h.从内存地址为"5"提取出数据
i.由于LDA操作的是AC寄存器,最终将数据放入AC中
CPU执行这些操作依赖CPU的时钟
CPU里可以粗略的认为是很多很多很多小电容。充满电了算1,没充电算0。每次计算就是这些小电容翻来覆去的充电放电。电容要充电放电,这个需要时间。
模块各种连接,组成复杂的功能。也就是前面小模块的输出会被后面模块当成输入。
那就有问题了,一方面,后面的模块要如何知道前面的模块到底是已经完成充电/放电了呢,还是正在充电放电呢?另一方面,路径越长从最开始输入到最终的输出的时间就越长,也就是路径长度不同延迟就不同,所以你很难保证每个针脚上的数据严格的同时到达。
所以就引入了时钟机制。
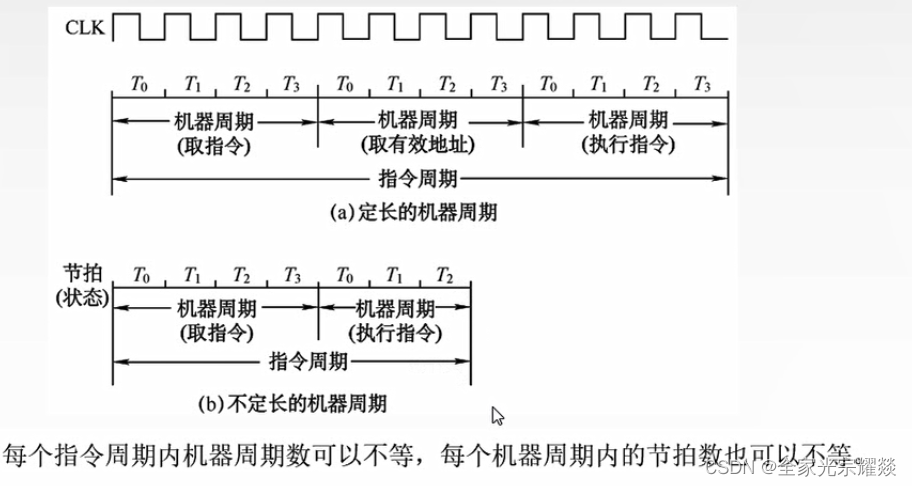
用一个统一的时钟脉冲来同步各个小模块。脉冲没来,大家抓紧时间充电放电,脉冲来了,大家一起动。
一个时钟脉冲为一个时钟周期。 指令周期常常有若干个CPU周期,CPU周期也称为机器周期,由于CPU访问一次内存所花费的时间较长,因此通常用内存中读取一个指令字的最短时间来规定CPU周期。这就是说,一条指令取出阶段(通常为取指)需要一个CPU周期时间。而一个CPU周期时间又包含若干个时钟周期

扩展:
数据运算基本单位,与或非门
0和1的艺术,与、或、非基本逻辑门电路_码出钞能力的博客-CSDN博客
【笔记】逻辑门图解—与门、或门、非门、与非门、或非门、异或门、同或门_Zhou_LC的博客-CSDN博客_与或非门电路图
加法和加法的实现——算术逻辑电路——计算机组成原理_想吃猪蹄的博客-CSDN博客_加法逻辑电路
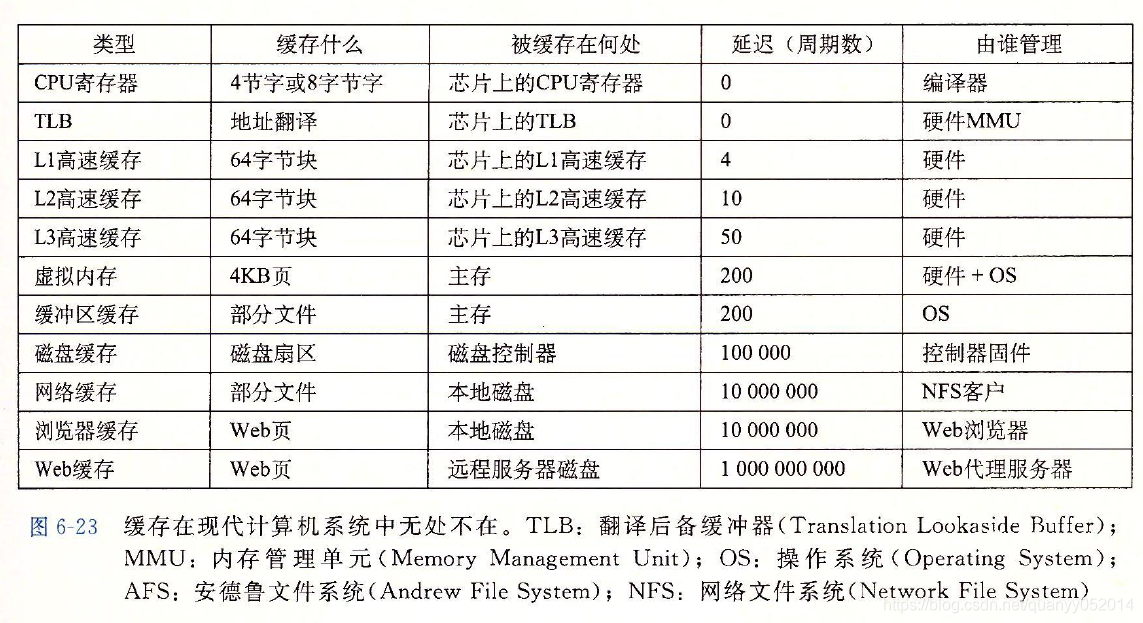
1. 存储技术
随机访问存储器(RAM)分为两类:静态RAM(SRAM)和动态RAM(DRAM)。
SRAM:结构相对复杂,成本高;双稳态特性,只要有电,它就会永远保持它的值(抗干扰性强);容量小,速度较快,一般用作CPU与内存的缓存。
DRAM:结构相对简单,成本低;存储器单元对干扰非常敏感(抗干扰性弱),容量较大,速度较慢,一般用作系统内存。
RAM是易失性存储器,断电数据丢失。
磁盘存储:属于外部I/O设备,其特点是存储容量大,但读取速度更慢,价格也更加便宜。
磁盘的构造是一个圆盘,盘上分布着一条条磁道(不同半径就有不同的磁道),每次访问都要找到相应的磁道,磁盘旋转到对应的位置,再用读写头读取或者修改值,所以磁盘扇区访问时间=寻道时间+旋转时间+传输时间。
固态硬盘:基于闪存的存储技术,与机械磁盘相比,读写速度快,价格较高,使用寿命较短。
2. 局部性
在程序中,程序倾向于引用邻近于其他最近引用过的数据项的数据项,或者就是最近引用的数据项本身,这种倾向,称为局部性原理。一个良好的程序倾向于展示出,良好的局部性。
局部性原理又分为时间局部性(temporal locality) 和空间局部性 (spatial locality) 。
时间局部性(temporal locality)
时间局部性指的是:被引用过一次的存储器位置在未来会被多次引用(通常在循环中)。
空间局部性(spatial locality)
如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。
程序局部性可以总结为以下:
- 重复引用一个变量的程序有良好的时间局部性。
- 对于具有步长为k的引用模式的程序,步长越小,空间局部性越好。相对得,在存储器中以大步长跳来跳去的程序空间局部性会很差。
- 对于取指令来说,循环有好的时间和空间局部性。循环体越小,循环迭代次数越多,局部性越好。
3. 存储器层次结构
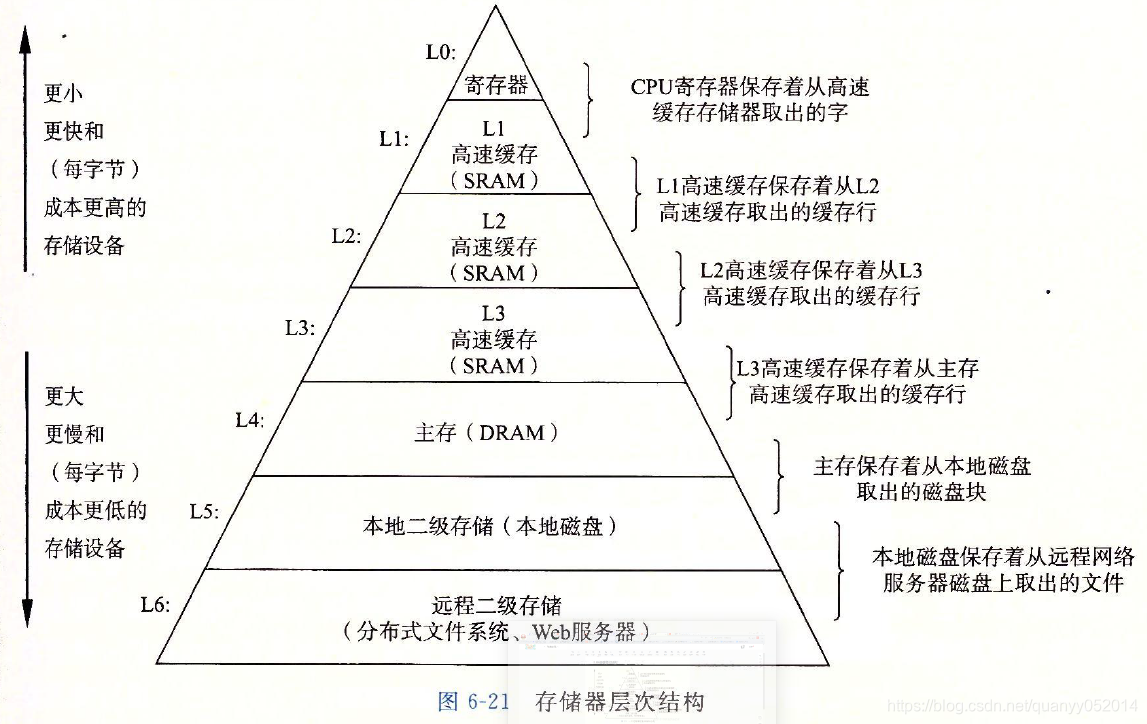
基本缓存原理

缓存命中:当程序需要第k+1层数据块n的时候,程序会在当前存储的k层,寻找块n的数据,刚好n在k层的话,就是一个缓存命中,这比从k+1层读取的速度要快很多。
缓存不命中:当程序需要访问到块n的时候,在k层没有该数据块,就是一个缓存不命中,这时候就会从k+1层中读取块n将其替换到k层的一个数据块(覆盖或驱逐一个已有的数据块)。程序还是从k层访问块n。
冷不命中:也称强制性不命中,一个空的缓存,被访问时不命中的情况。
冲突不命中:缓存足够大,理论上能够保持被引用的全部数据对象,但是因为这个对象映射到了同一个缓存块中,导致缓存一直不命中。
放置策略:当缓存不命中时,我们需要从k+1层中获得的数据放置在k层缓存中,以什么样的策略放置,称为放置策略。LRU:最近最少使用,把数据加入一个链表中,按访问时间排序,发生淘汰的时候,把访问时间最旧的淘汰掉。MRU:与LRU相比,发生淘汰的时候,把访问时间最新的淘汰掉。等(Cache replacement policies(缓存替换策略)/ LRU 和 LFU等算法_Jeff_的博客-CSDN博客_lru替换策略)
4. 高速缓存存储器
算术逻辑单元(arithmetic and logic unit) 是能实现多组算术运算和逻辑运算的组合逻辑电路,简称ALU。
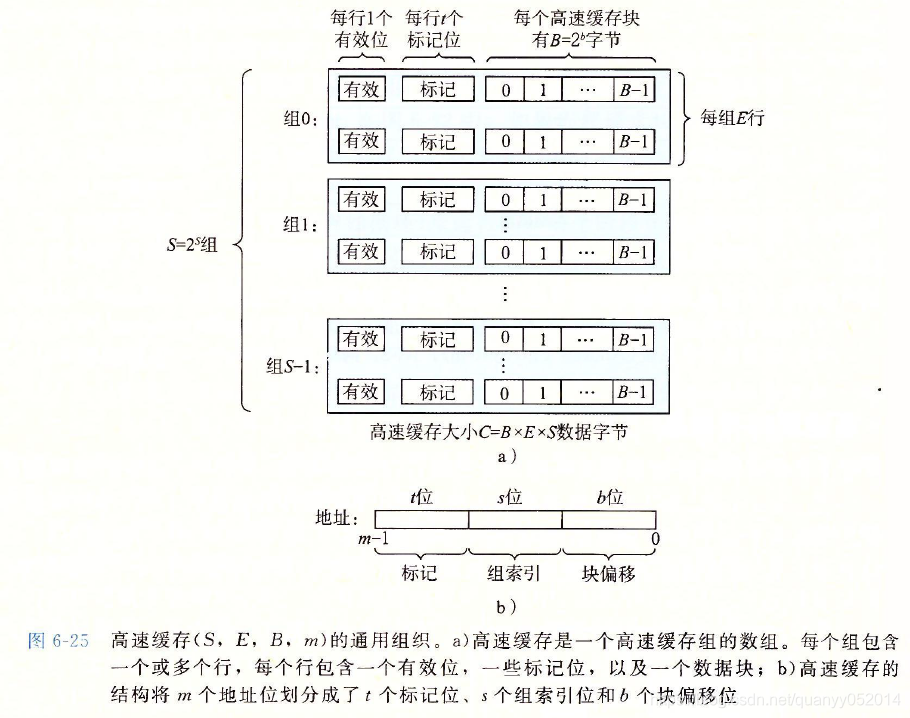
高速缓存大小(容量)C = S*E*B。

高速缓存种类:三种
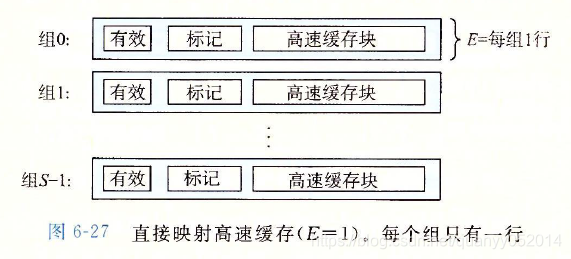
1.直接映射高速缓存
2,组相连高速缓存
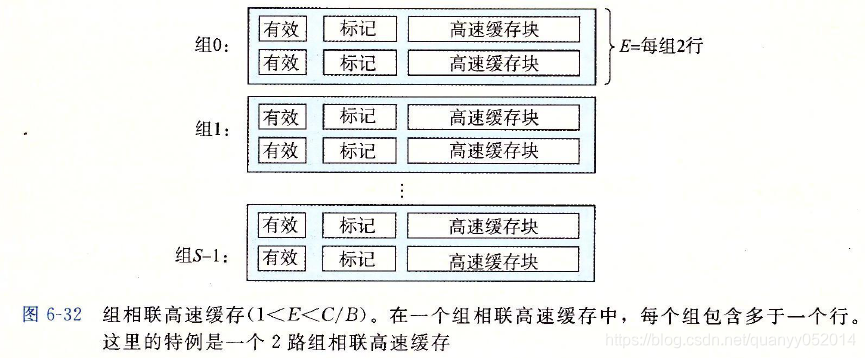
3.全相连高速缓存
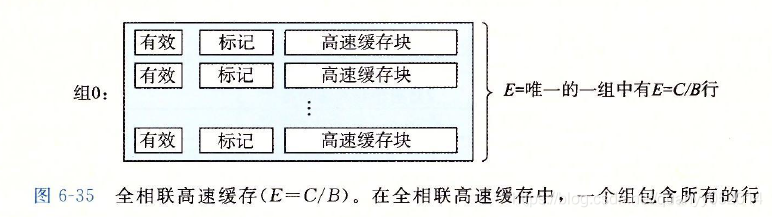
工作原理:以直接映射高速缓存为例
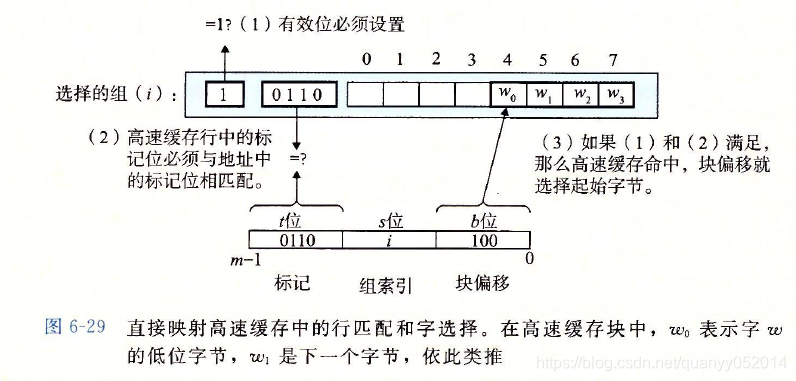
1.组索引s位数据转换成无符号的组号,定位到高速缓存所在组。
2.由于直接映射高速缓存每组只有一行,只需检查有效位是否=1,标记号是否与地址的标记位一致。是则进行第三步;否则进行第四步。
3.此时高速缓存命中,由于直接映射高速缓存每个组只有一行,则直接根据块偏移来定位行中的起始地址(有多行的高速缓存需要根据标记的t位定位到具体行),从该地址中读取n个字节(n为字的大小)返回给上层。
4.此时高速缓存不命中,需要从下一层取出被访问的块,然后存放到对应的缓存组(行)中,再返回字给上一层,如果缓存组(行)中已有有效数据,则需要驱逐一个行数据,在组内有多行的缓存器中,驱逐哪一个会根据制定好的策略进行。
写数据:

真实的高速缓存层次结构

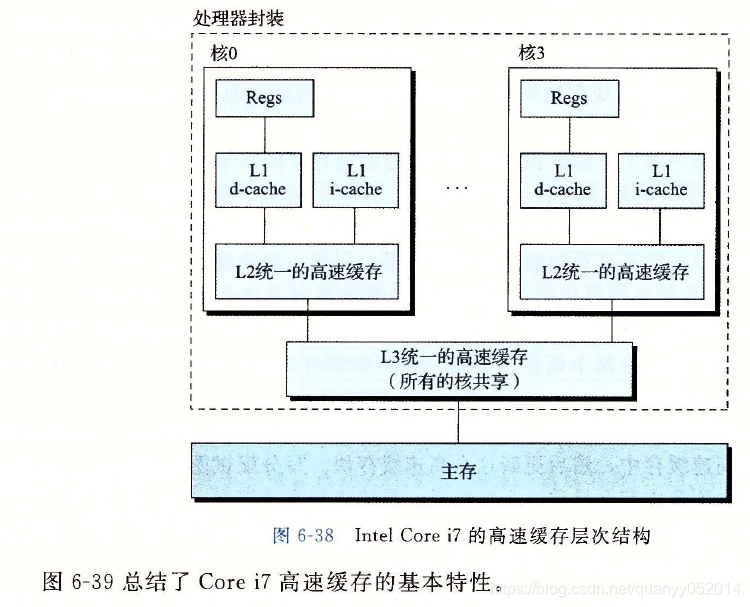
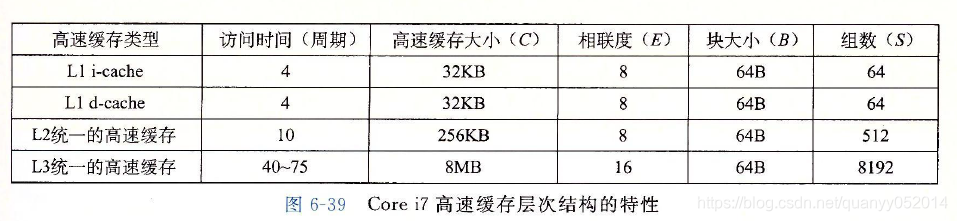
高速缓存参数的性能影响

1.高速缓存大小的影响:较大的高速缓存可能会提高命中率,但是会增加命中时间。
2.块大小的影响:会提高空间局部性好的程序的命中率,但是会损害时间局部性好的程序的命中率;并且较大的块会使不命中的处罚更大。
3.相联度的影响:即高速缓存每组的行数,较高的相联度降低了由于冲突不命中出现的抖动的可能性,但是成本较高,并且由于复杂性的增加,会增加命中时间和不命中处罚。
4.写策略的影响:直写比较容易实现,使用独立与高速缓存的独立写缓冲区;写回减少传送次数,提高效率。
5. 编写高速缓存友好的代码

例子:假设高速缓存块大小位4个字,字大小为4个字节,一开始缓存为空。
二维数组以行优先求和


由于一开始缓存为空,所以每读取一个字,必然会出现一次不命中。C语言程序以行优先顺序存储数组,所以读出来一个字后,步长为1的引用,后三个字节都能命中。
二维数组以列优先求和


由于一开始缓存为空,所以每读取一个字,必然会出现一次不命中。以一列的大小为步长引用,当列大小大于字大小时,前面读取出来的字则不包含下一次需要引用的字节。
总之:

6. 高速缓存对程序性能的影响
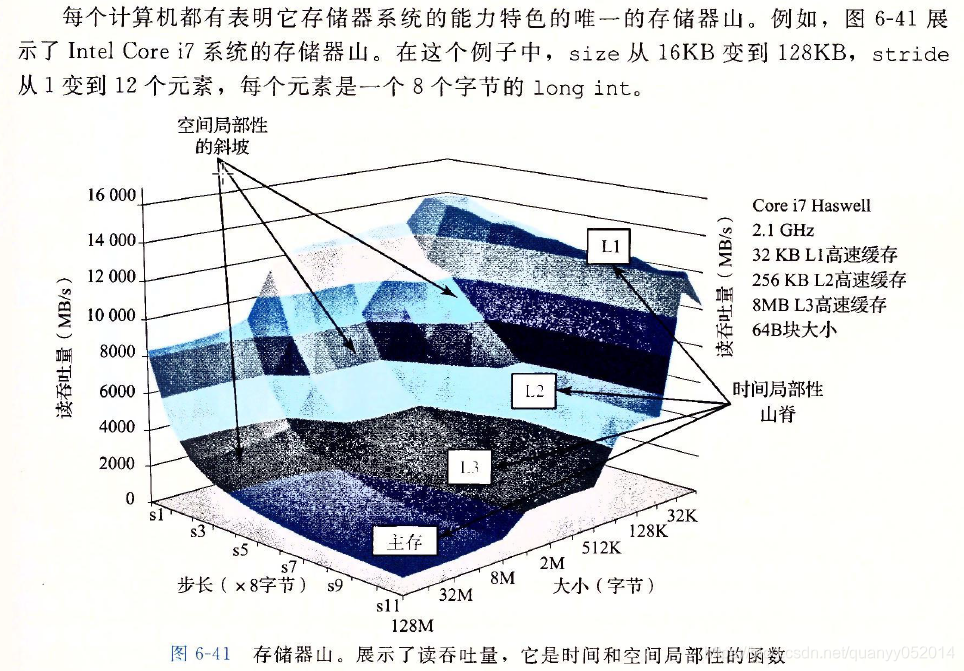

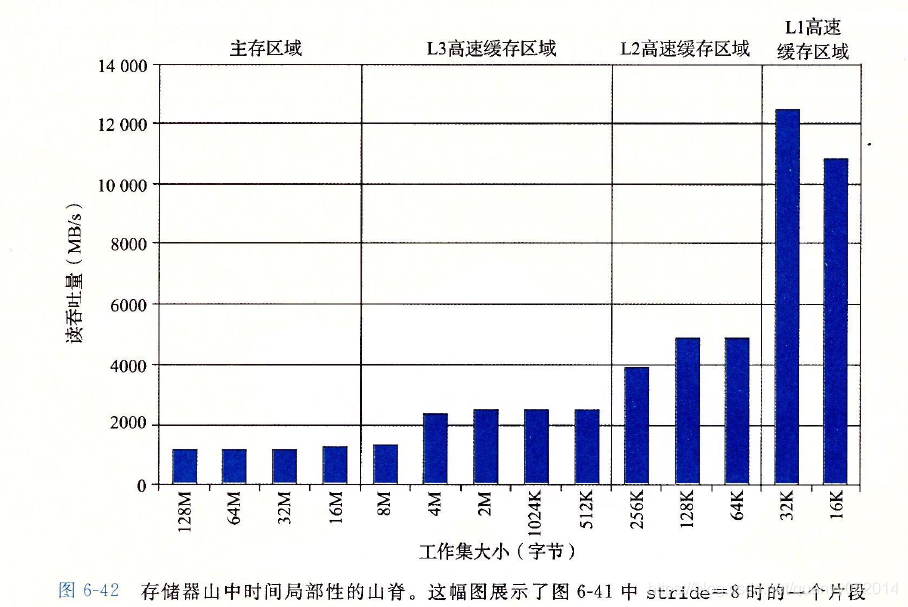

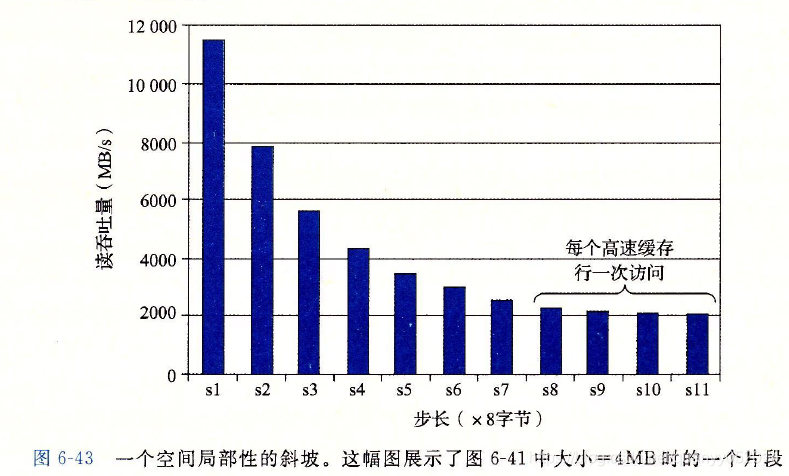


习题:


解答:
A:由S=2^s,S=4得出s为2;由B=2^b,B=4得出b为2;那么t=12-s-b=8。按照
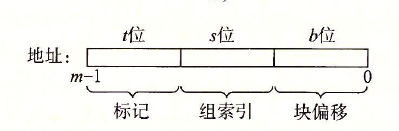
可得:0-1为CO,2-3为CI,4-12为CT。
B:1.地址0x834转换为二进制(1000 0011 0100)可得标记为0x83,组索引为1,块偏移为0;由表可得缓存中该租有效位为0,所以不命中,值未知。
2.地址0x836转换为二进制(1000 0011 0110)可得标记为0x83,组索引为1,块偏移为2;由表可得缓存中该租有效位为0,但是由于第一步对地址0x834的读取,会更新该组数据,且有效位为1,所以命中,值未知。
3.地址0xFFD转换为二进制(1111 1111 1101)可得标记为0xFF,组索引为3,块偏移为1;由表可得缓存中该租有效位为1,所以命中,值为0写C0。


解答:由块大小为16字节的b=4;由直接映射可得E=1;由总共32个字节可得S=2(C=S*E*B),s=1;
dst开始地址64= 100 0000b
src开始地址0 = 000 0000b
dst[0][0]:100 0000b src[0][0]:000 0000b
dst[1][0]:101 0000b src[0][1]:000 0100b
dst[2][0]:110 0000b src[0][2]:000 1000b
dst[3][0]:111 0000b src[0][3]:000 1100b
dst[0][1]:100 0100b src[1][0]:001 0000b
dst[1][1]:101 0100b src[1][1]:001 0100b
dst[2][1]:110 0100b src[1][2]:001 1000b
dst[3][1]:111 0100b src[1][3]:001 1100b
dst[0][2]:100 1000b src[2][0]:010 0000b
dst[1][2]:101 1000b src[2][1]:010 0100b
dst[2][2]:110 1000b src[2][2]:010 1000b
dst[3][2]:111 1000b src[2][3]:010 1100b
dst[0][3]:100 1100b src[3][0]:011 0000b
dst[1][3]:101 1100b src[3][1]:011 0100b
dst[2][3]:110 1100b src[3][2]:011 1000b
dst[3][3]:111 1100b src[3][3]:011 1100b
所以最终结果为:
| m | m | m | m |
| m | m | m | m |
| m | m | m | m |
| m | m | m | m |
| m | m | h | m |
| m | h | m | h |
| m | m | h | m |
| m | h | m | h |

解答:
A:E=1,B=16,C=512;b=4,S=32,s=5;i取值为0-127
x[0][i] : 000 0 0000 0000b + i*100b
x[1][i] : 001 0 0000 0000b + i*100b
由于依次读取x[0][i]和x[1][i]的i值一样,所以导致他们的组索引一直都是一样的,但标记不一样,造成了冲突不命中。所以不命中率为100%。
B:E=1,B=16,C=1024;S=64,s=6;i取值为0-127
x[0][i] : 00 00 0000 0000b + i*100b
x[1][i] : 00 10 0000 0000b + i*100b
由于s=6,所以x[0][i]和x[1][i]不管当i取何值,组索引都不一样,所以不存在冲突不命中,块大小为16字节,每次读4字节,所以得不命中率为25%。
C:E=2,B=16,C=512;S=16,s=4;i取值为0-127
x[0][i] : 0000 0000 0000b + i*100b
x[1][i] : 0010 0000 0000b + i*100b
当i取值为0-63,每四次就会有一次冷不命中,所以不命中率为25%。
当i取值为64-127,同样每四次就会有一次不命中,需要置换之前的缓存,所以不命中率为25%。
综合起来,不命中率为25%。
D:不会,因为此时缓存块大小是限制因素(每四次读取第一次都会不命中)。
E:会,更大的缓存块会降低不命中率,因为不命中只发生在第一次读入块的时候,增加块的大小,使得读取一个块后,该块的命中次数增加。所以更大的块会使得不命中占总读取的比例降低。

















 1321
1321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









