







(许野平的 Watson Explorer 笔记)
创建集合后,可以看到如下界面:
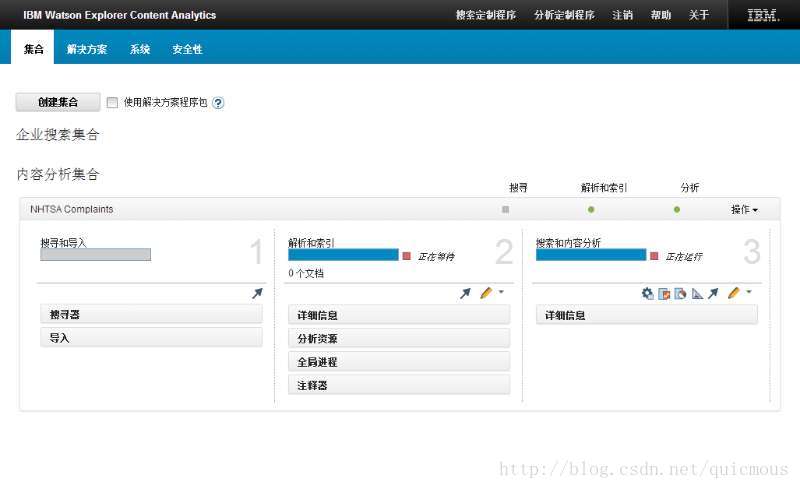
我们可以看到三个面板:1-搜寻与导入;2-解析和索引;3-搜索和内容分析。本练习讨论搜寻器的创建和配置,以及如何导入数据。
“搜寻器”的英文是 crawler,俗称爬虫,用于从网络、硬盘等数据源自动抓取数据。因为创建界面很直观,步骤不一一细说了,这里说一下几个需要注意的问题。
数据源问题
前几天在一次培训课程中,不少同学提到这个问题。实际上,Watson Explorer 有些类似数据库,能从很多类型数据源获取数据。还没仔细研究它的系统架构设计,但是我想,这个架构中一定会提供一个开放式接口处理这件事情。
NHTSA数据
在这个练习中,我们选择了 NHTSA 投诉数据,数据是 XML 格式的。所以,数据源类型在这个练习中选择的是 Windows 本地文件系统。但是我翻遍了所有可能的位置,都没能找到这些文档。最后找到一份Excel格式的文件,里面的数据正是 NHTSA 投诉数据,内容很多,于是这里就拿来做练习。
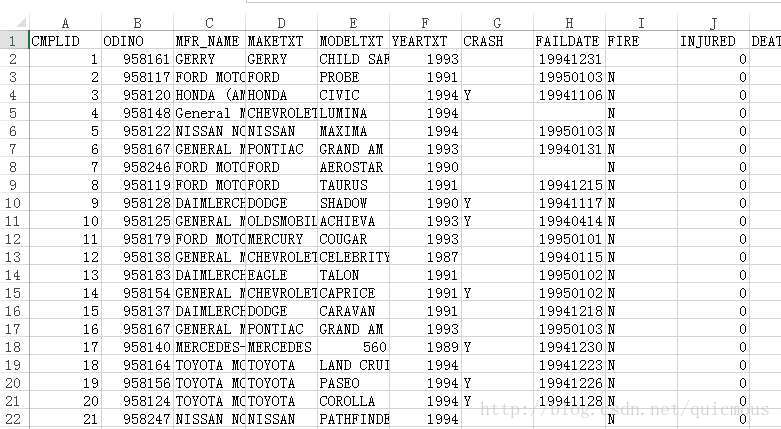
为了确保兼容性,我把数据存成了 .csv 格式。
数据源文件夹设置
Web操作界面,有些不太习惯。反复操作了几遍,发现熟悉后还是挺方便操作。操作要点如下:
- 可以指定子文件夹的搜索层次。我找到的这些文件分布在用日期命名的多个子文件夹内,导入的时候,只需要指定他们的根文件夹和子文件夹搜索深度就行了,这个确实很方便。
- 可以指定文件类型。这里,我直接指定 .csv 扩展名。
数据直接导入
.csv 格式的文件可以直接导入,这样就不需要爬虫来做这个任务了。这个练习中,因为没有XML数据,所以我选择了直接导入的方式建立的集合(Collection)。
小结
本练习设定了搜寻器。但是我们只设定了数据来源,目标数据还没设定。接下来设定目标数据后,就可以启动搜寻器,自动抓取并上传数据了。
(未完待续 … …)















 3923
3923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











