






import matplotlib.pyplot as plt import numpy as np from sklearn.cluster import KMeans from sklearn import datasets iris = datasets.load_iris() X=iris.data estimator =KMeans(n_clusters=3) estimator.fit(X) label_pred =estimator.labels_ x0 = X[label_pred==0] x1= X[label_pred==1] x2=X[label_pred==2] plt.scatter(x0[:,2],x0[:,3],c='red',marker='o',label='label0') plt.scatter(x1[:,2],x1[:,3],c='green',marker='*',label='label1') plt.scatter(x2[:,2],x2[:,3],c='blue',marker='+',label='label2') plt.legend(loc=2) plt.show()
在这里我做了可视化的应用
运行结果:
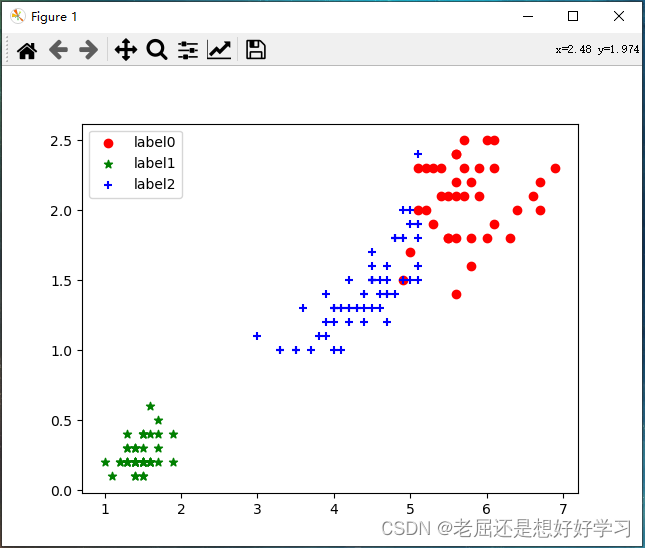
所以,处理该类型的数据有多种方法可以使用















 7183
7183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









