






What's C-End Service? C meas Consumer, so it's used to provide services for Consumer, such as buyers, in which there are many important issues , such as efficiency, reliablity and so on. The article refers to how to get a more efficiency C-End Service through the storage architecture. For C-End, all services latency in a request shouldn't be more than 500ms, otherwise it'll produce very bad customer experience and the user wouldn't like to use it any more. In order to get an efficient service, the most important solution is to improve the storage architecture. In general, the following three level storage architecture, which are local cache, remote cache and persistent DB, such as mysql, will be used in C-End Service.
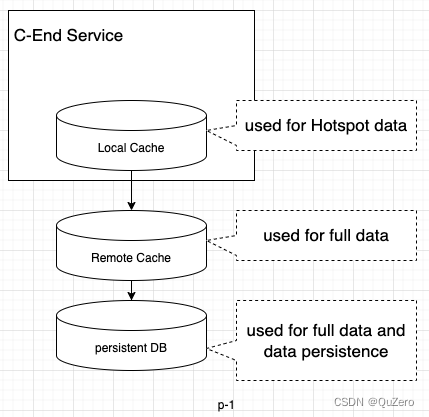
Because local cache uses the memory of the service host and it has the size limit, it's better to store the hotspot data, which will expire after some time, then it can avoid using too much memory and negatively impacting service performance. For remote cache, such as redis, which has its own memory and has a cluster to manage it, the full data could be stored, then it can get better performance for the service.
Although remote cache can also do data persistence, it would slow down the service performance and these persistent data has no business value here except data reliablity, in other words, the data could only be used by C-end services and won't be accessed by some services with low real-time requests, such as offline services, because it's too expensive for there serivices.
Persistent DB is used to store full data and all data will be persisted into hard disk to avoid data loss. Although its performance is much lower than remote cache, its access cost is also much lower, so it's suitable for a small number of penetrating cache requests and non-real-time offline requests.
Now, Local cache contains two kinds of products, which are Guava and Caffeine. They are all K/V structures and based on ConcurrentHashmap principle. Their difference are shown in the tabel below.
| Guava | Caffeine | |
| Lock | Segment Reentrantlock | synchronized+CAS |
| Eviction Strategy | Sync | Async |
| Default Eviction Algorithm | S-LRU | W-TinyLFU |
| Data Structure | HashMap | HashMap |
| Cumulative Statistic | yes | yes |
| spring default cache | spring4 and earlier | spring5 |
| Automic Load | Y | Y |
For remote Cache, there are two products, such as Redis and Tair, They are all K/V data structure, but they have some difference, Redis has four modes, such as Single, Master-slave, Sentinel and Cluster. Tair supports several storage engine, for example, mde, rdb and so on, whichi is used for different use case. The following table are their difference.
| Redis cluster | Tair | |
| Write latency | 1-2ms | 5~8ms(write through),1ms(write back) |
| Read latency | 1-2ms | 1ms(memory), 5-8ms( disk) |
| Throughput per host | 5W | 8W-10W(key+value=1k) |
| V size | no more than 1G(Preferably no mroe than 1M ) | no more than 256M |
| V data structure | String/Hash/List/Set/ZSet | |
| Cluster hosts size | 1000+ | no limit |
| CAP | AP | CP or AP |
| Language | java、ruby | php,restful,java,c/c++ |
| Automic Expiration | Yes | Yes |
| Extension | Manual | Automic |
| Reliability | Per user demands | Story |
| Business Isolation | No | Per Group or name in a Group |
For persistent DB, there are Mysql, DDB, whose data is stored on Disk to avoid data loss. Although there are other persistent DB, such as ES, HBase and so on, we focus on data storage in C End, so only Mysql and DDB are more important for us and the followingt table are their difference,
| Mysql(InnoDB) | DDB | |
| Data Structure | Relational DB | K/V DB |
| TPS | 900 per second | 1000 per partition per second(WCU) |
| QPS | 3-4W per second | 3000 per partition per second(RCU) |















 976
976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









