







介绍
kafka是最初由Linkedin公司开发,使用scala语言编写,运行在jvm虚拟机上,kafka是一个分布式、分区的、多副本的、多订阅者,基于zookpeeper协调的分布式日志系统(分布式MQ系统),常见可以用于web/nginx日志,搜索日志,监控日志,访问日志,消息服务等等。
整体设计的几个特点:
- 默认使用持久化
- 优先考虑吞吐量
- 信息的消费状态在consumer端记录而不是server端
- kafka完全是分布式的,producer broker consumer都认为是分布式的
适用场景
- push发送
- 高吞吐量
- 可以作为大缓冲区使用
- Hadoop或传统的数据仓库中存储消息用于离线分析
- nginx日志收集
架构
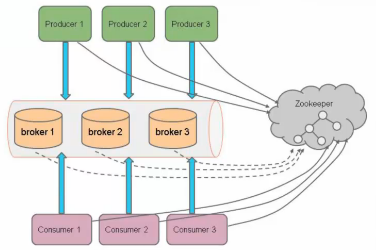
Producer:向kafka发布消息的进程;
Consumer:从kafka中订阅Topic的进程;
Consumer Group:同一个Consumer Group中的Consumers,kafka将相应Topic中的每个消息只发送给其中一个Consumer;
Broker:kafka集群中的每一个kafka服务;
架构图一:
架构图二:
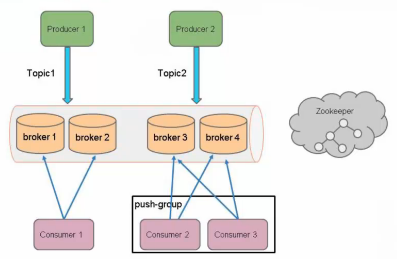
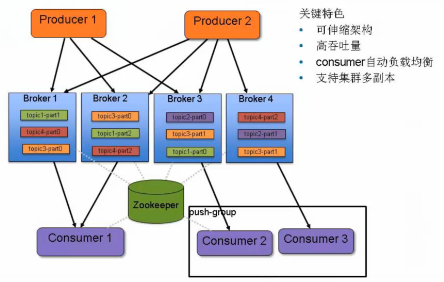
架构图三:
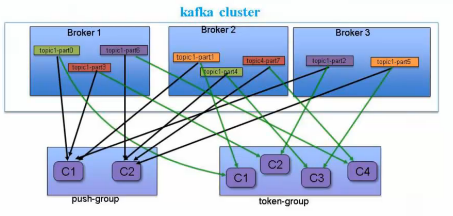
Consumer负载均衡
性能
系统级性能优化
- Disk:随机读写慢,顺序读写快;
- OS推测读写:read-ahead & write-ahead;
- Append messages:顺序读写msgs数据;
- tcp参数优化:调整缓冲区大小,滑动窗口等;
- sendfile & zero copy:减少字节copy;
应用架构系统优化
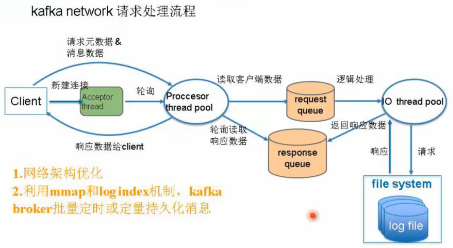
应用架构性能优化-broker
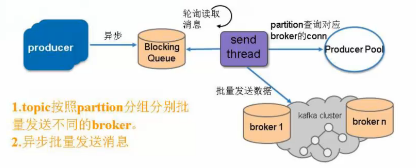
应用架构性能优化-producer
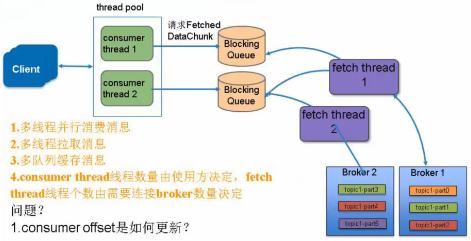
应用架构性能优化-consumer
监控
kafka服务节点数监控
- zookeeper上xxx/mafka01/broker/ids目录下节点数量
kafka broker监控
- broker是否存活/broker是否提供服务
- 数据流量(流入和流出)
- Producer的请求数/请求响应时间
- Consumer的请求数/请求响应时间
topic监控
- 数据量大小
- offset
- 数据流量(流入和流出)















 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









