






1. 数据校验
drf中为我们提供了Serializer,他主要有两大功能:
- 对请求数据校验(底层调用Django的Form和ModelForm)
- 对数据库查询到的对象进行序列化
示例一: 基于Serializer
# models.py
class UserInfo(models.Model):
username = models.CharField(verbose_name='用户名', max_length=32)
age = models.CharField(verbose_name='年龄', max_length=32)
level_choice = ((1, 'VIP'), (2, 'SVIP'), (3, 'PARTNER'))
level = models.CharField(verbose_name='级别', choices=level_choice, max_length=32)
email = models.CharField(verbose_name='邮箱', max_length=32)
# views.py 基于Serializer
class UserSerializers(serializers.Serializer):
username = serializers.CharField(label='用户名', max_length=32)
age = serializers.CharField(label='年龄', max_length=32)
level = serializers.ChoiceField(label='级别', choices=models.UserInfo.level_choice)
email = serializers.CharField(label='用户名', min_length=6, max_length=32, validators=[EmailValidator, ])
email1 = serializers.CharField(label='用户名', min_length=6, max_length=32)
email2 = serializers.CharField(label='用户名', min_length=6, max_length=32)
def validate_email2(self, value):
""" 钩子函数, 用于验证某个字段 """
if re.match('^\w+@\w+\.\w+$', value):
return value
raise exceptions.ValidationError('邮箱格式错误')
class UserView(APIView):
""" 用户管理 """
def post(self, request):
""" 添加用户 """
ser = UserSerializers(data=request.data) # 将请求体数据传入, 这个request.data可以解析各种数据
if not ser.is_valid():
return Response({'code': 1006, 'data': ser.errors})
print(ser.validated_data)
# 将数据保存到数据库
return Response({'code': 0, 'data': 'xxxx'})
示例二: 基于ModelSerializer
# models.py
from django.db import models
class Role(models.Model):
""" 角色表 """
title = models.CharField(verbose_name='名称', max_length=32)
class Department(models.Model):
""" 部门表 """
title = models.CharField(verbose_name='名称', max_length=32)
class UserInfo(models.Model):
username = models.CharField(verbose_name='用户名', max_length=32)
age = models.CharField(verbose_name='年龄', max_length=32)
level_choice = ((1, 'VIP'), (2, 'SVIP'), (3, 'PARTNER'))
level = models.CharField(verbose_name='级别', choices=level_choice, max_length=32)
email = models.CharField(verbose_name='邮箱', max_length=32)
# 创建外键
depart = models.ForeignKey(verbose_name="部门", to="Department", on_delete=models.CASCADE)
# 多对多
roles = models.ManyToManyField(verbose_name="角色", to="Role")
# views.py
# 基于ModelSerializer
class UserModelSerializer(serializers.ModelSerializer):
email1 = serializers.CharField(label='邮箱1', validators=[EmailValidator, ])
class Meta:
model = models.UserInfo
fields = ['username', 'age', 'email', 'email1', 'roles'] # 需要传入的数据, 多对多
extra_kwargs = {
'username': {'min_length': 4, 'max_length': 32},
'age': {'max_length': 3}
}
def valicate_email(self, value):
....
return value
class UserView(APIView):
""" 用户管理 """
def post(self, request):
""" 添加用户 """
ser = UserModelSerializer(data=request.data) # 将请求体数据传入, 这个request.data可以解析各种数据
if not ser.is_valid():
return Response({'code': 1006, 'data': ser.errors})
print(ser.validated_data)
# 将数据保存到数据库
ser.validated_data.pop('email1') # 删除不需要存入数据库的数据
ser.save(level=1, depart_id=1) # 加入初始化数据
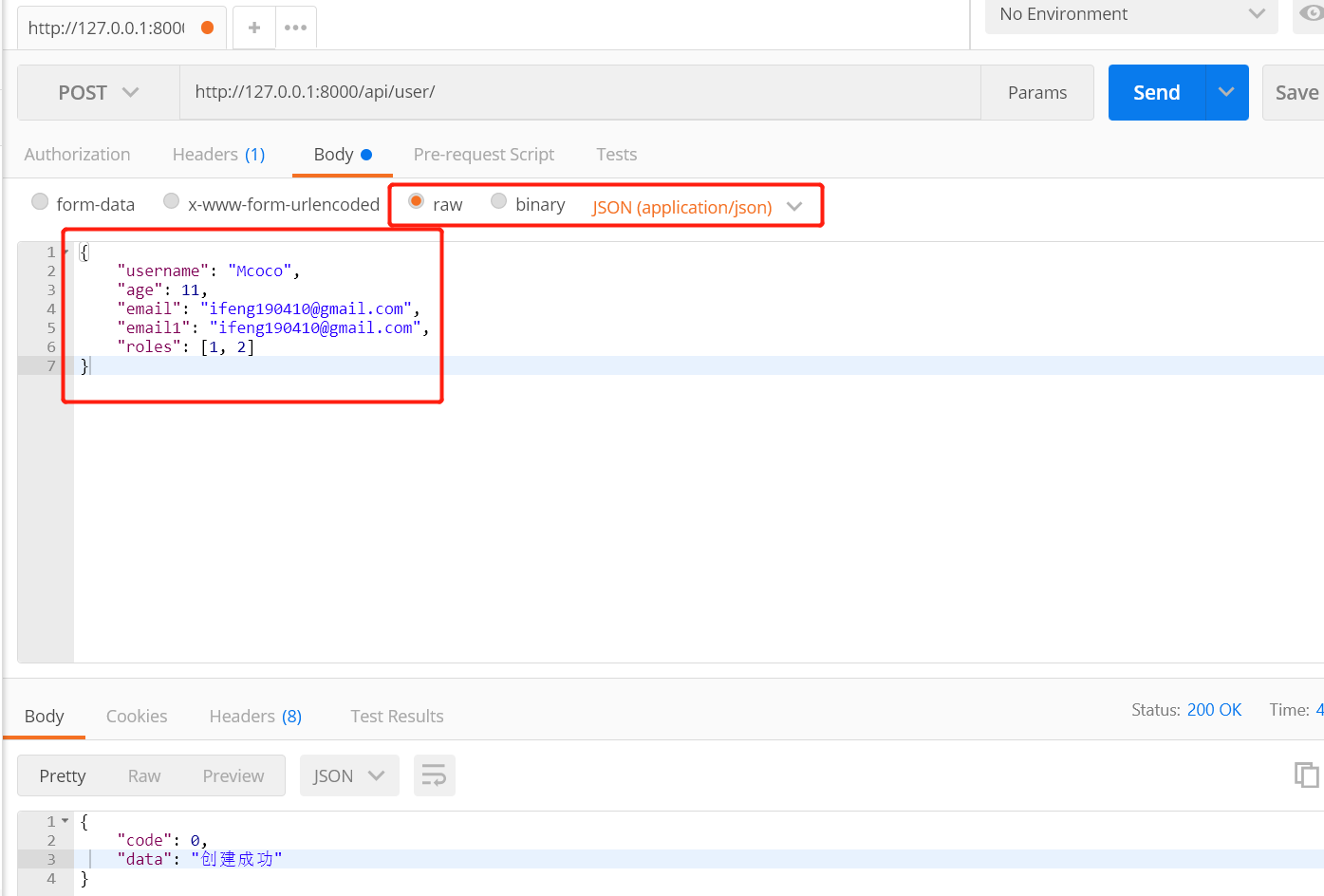
return Response({'code': 0, 'data': '创建成功'})
2. 序列化
示例一: 序列化基本字段
class UserModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserInfo
fields = ['username', 'age', 'level', 'email', 'depart', 'roles'] # 序列化基本字段
class UserView(APIView):
""" 用户管理 """
def get(self, request):
""" 序列化数据 """
queryset = models.UserInfo.objects.all()
ser = UserModelSerializer(instance=queryset, many=True)
print(ser.data)
return Response({'code': 0, 'data': ser.data})
返回值:
HTTP 200 OK Allow: GET, HEAD, OPTIONS Content-Type: application/json Vary: Accept { "code": 0, "data": [ { "username": "ifeng", "age": "11", "level": 1, "email": "ifeng190410@gmail.com", "depart": 1, "roles": [] }, { "username": "Mcoco", "age": "11", "level": 1, "email": "ifeng190410@gmail.com", "depart": 1, "roles": [ 1, 2 ] } ] }
示例二: 自定义字段
from django.forms.models import model_to_dict
from rest_framework import serializers
from rest_framework.response import Response
from rest_framework.views import APIView
from api import models
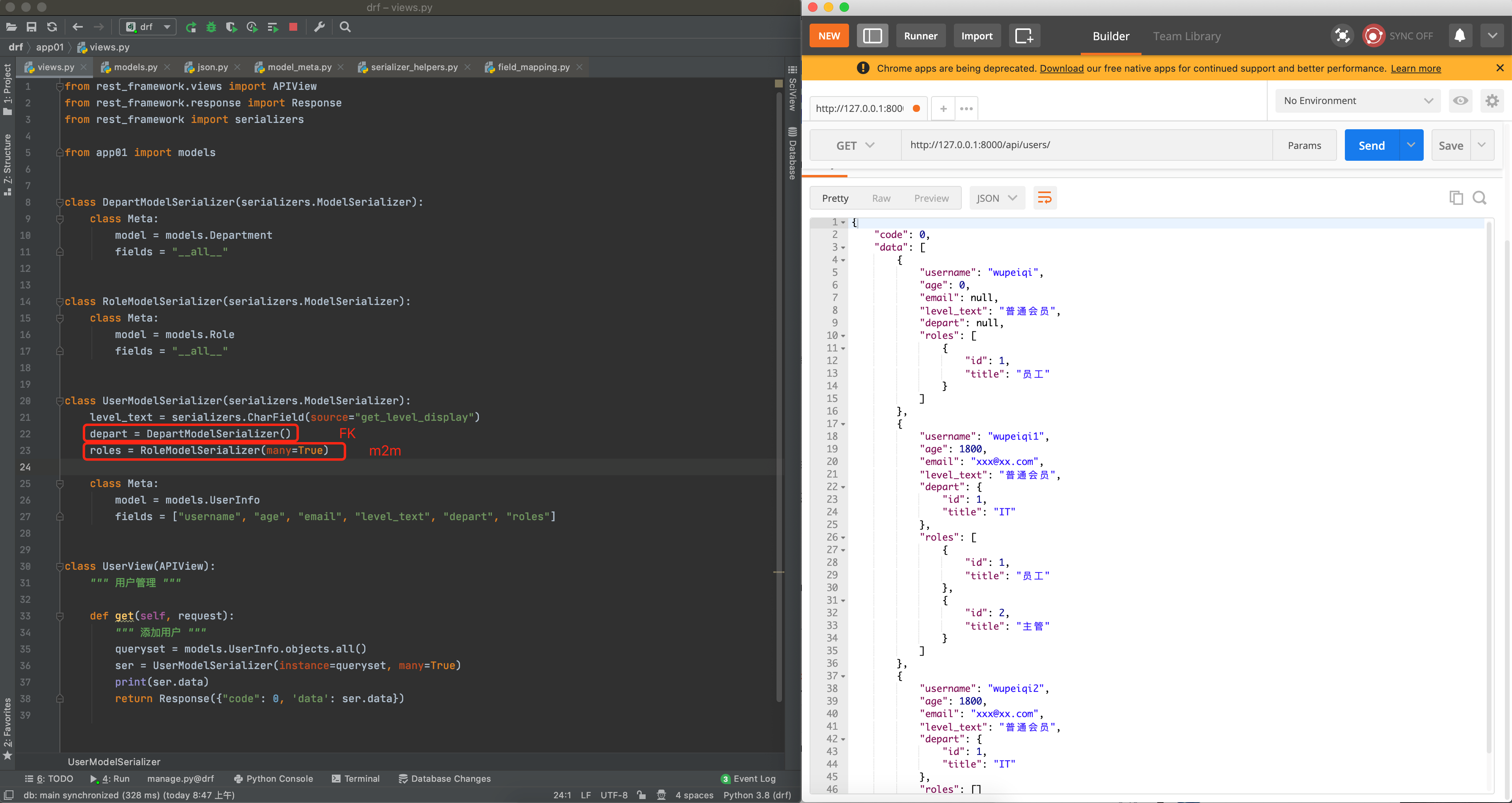
class UserModelSerializer(serializers.ModelSerializer):
# 自定义字段
level_text = serializers.CharField(source="get_level_display")
depart = serializers.CharField(source='depart.title')
roles = serializers.SerializerMethodField()
extra = serializers.SerializerMethodField()
class Meta:
model = models.UserInfo
fields = ['username', 'age', 'level_text', 'email', 'depart', 'roles', 'extra']
def get_roles(self, obj):
data_list = obj.roles.all()
return [model_to_dict(item, ['id', 'title']) for item in data_list]
def get_extra(self, obj):
return 666
class UserView(APIView):
""" 用户管理 """
def get(self, request):
""" 序列化数据 """
queryset = models.UserInfo.objects.all()
ser = UserModelSerializer(instance=queryset, many=True)
print(ser.data)
return Response({'code': 0, 'data': ser.data})
返回值:
{ "code": 0, "data": [ { "username": "ifeng", "age": "11", "level_text": "SVIP", "email": "ifeng190410@gmail.com", "depart": "后端", "roles": [], "extra": 666 }, { "username": "Mcoco", "age": "11", "level_text": "VIP", "email": "ifeng190410@gmail.com", "depart": "销售", "roles": [ { "id": 1, "title": "CEO" }, { "id": 2, "title": "CFO" } ], "extra": 666 } ] }
示例三: 序列化类的嵌套
嵌套主要是面向外键和多对多表的时候
3. 数据校验&序列化
注意点:
我们在做多对多数据校验的时候, 后面如果需要新增数据, 则需要重写create方法, 如果需要更新数据, 则需要重写update方法
# mdoels.py
from django.db import models
# Create your models here.
class Role(models.Model):
""" 角色表 """
title = models.CharField(verbose_name='名称', max_length=32)
class Department(models.Model):
""" 部门表 """
title = models.CharField(verbose_name='名称', max_length=32)
class UserInfo(models.Model):
username = models.CharField(verbose_name='用户名', max_length=32)
age = models.CharField(verbose_name='年龄', max_length=32)
level_choice = ((1, 'VIP'), (2, 'SVIP'), (3, 'PARTNER'))
level = models.SmallIntegerField(verbose_name='级别', choices=level_choice) # 类型为Int
email = models.CharField(verbose_name='邮箱', max_length=32)
# 创建外键
depart = models.ForeignKey(verbose_name="部门", to="Department", on_delete=models.CASCADE)
# 多对多
roles = models.ManyToManyField(verbose_name="角色", to="Role")
# views.py
# 数据校验&序列化
class DepartModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Department
fields = ['id', "title"]
extra_kwargs = {
"id": {"read_only": False}, # 数据验证, 需传入id, 为后续的create做准备
"title": {"read_only": True} # 序列化
}
class RoleModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Role
fields = ['id', "title"]
extra_kwargs = {
"id": {"read_only": False}, # 数据校验, 需传入id, 为后续的create做准备
"title": {"read_only": True} # 序列化
}
class UserModelSerializer(serializers.ModelSerializer):
level_text = serializers.CharField(source="get_level_display", read_only=True) # read_only -> 只序列化, 但是不数据校验
# Serializer嵌套,如果不设置read_only,一定要自定义create和update,自定义新增和更新的逻辑。
depart = DepartModelSerializer(many=False)
roles = RoleModelSerializer(many=True)
extra = serializers.SerializerMethodField(read_only=True)
email2 = serializers.EmailField(write_only=True) # write_only -> 只数据校验不序列化
# 数据校验:username、email、email2、部门、角色信息
class Meta:
model = models.UserInfo
# username, age, email是即read_only也write_only
fields = [
"username", "age", "email", "level_text", "depart", "roles", "extra", "email2"
]
# 给字段添加额外参数
extra_kwargs = {
"age": {"read_only": True},
"email": {"validators": [EmailValidator, ]},
}
def get_extra(self, obj):
return 666
def validate_username(self, value): # 钩子方法
return value
# 新增加数据时, 因为无法解决m2m的储存问题. 所以需要重写create方法
def create(self, validated_data):
"""
如果有嵌套的Serializer,在进行数据校验时,只有两种选择:
1. 将嵌套的序列化设置成 read_only
2. 自定义create和update方法,自定义新建和更新的逻辑
注意:用户端提交数据的格式。
"""
"""
validated_data:
OrderedDict([('username', 'xiaoergu'), ('email', 'xiaoergu@gmail.com'), ('depart', OrderedDict([('id', 2)])), ('roles', [OrderedDict([('id', 1)]), OrderedDict([('id', 2)])]), ('email2', 'budianlong@gmail.com')])
"""
depart_id = validated_data.pop('depart')['id'] # 拿到depart的id
role_id_list = [ele['id'] for ele in validated_data.pop('roles')] # 拿到roles的所有id
# 新增用户表
validated_data['depart_id'] = depart_id
user_object = models.UserInfo.objects.create(**validated_data)
# 在用户表和角色表的关联表中添加对应关系, django-orm知识
user_object.roles.add(*role_id_list)
return user_object
class UserView(APIView):
""" 用户管理 """
def get(self, request):
""" 添加用户 """
queryset = models.UserInfo.objects.all()
ser = UserModelSerializer(instance=queryset, many=True)
return Response({"code": 0, 'data': ser.data})
def post(self, request):
""" 添加用户 """
ser = UserModelSerializer(data=request.data)
if not ser.is_valid():
return Response({'code': 1006, 'data': ser.errors})
print(ser.validated_data)
ser.validated_data.pop('email2')
instance = ser.save(age=18, level=3)
# 新增之后的一个对象(内部调用UserModelSerializer进行序列化)
print(instance)
# ser = UserModelSerializer(instance=instance, many=False)
# ser.data
return Response({'code': 0, 'data': ser.data})
返回值:
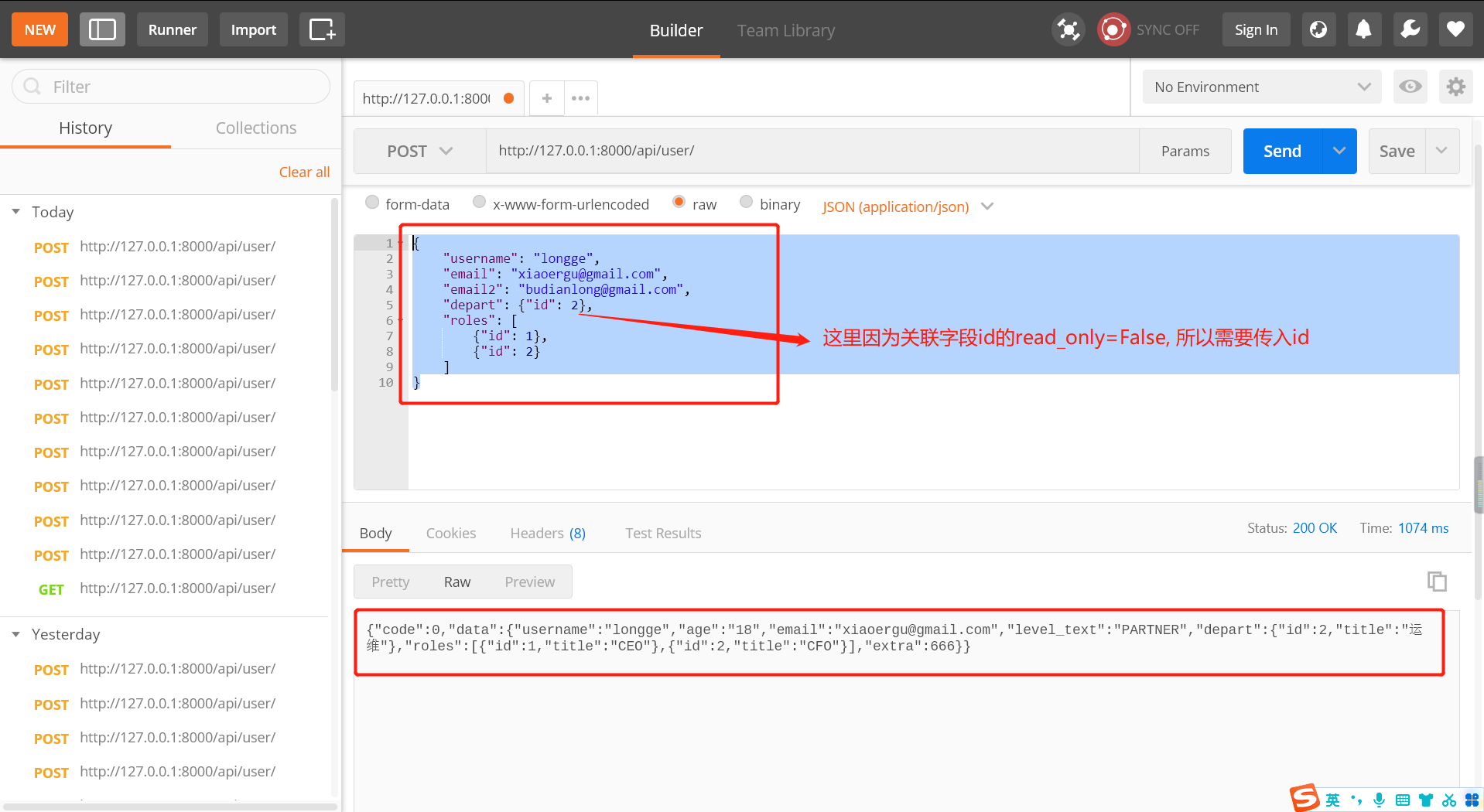
4. 源码分析
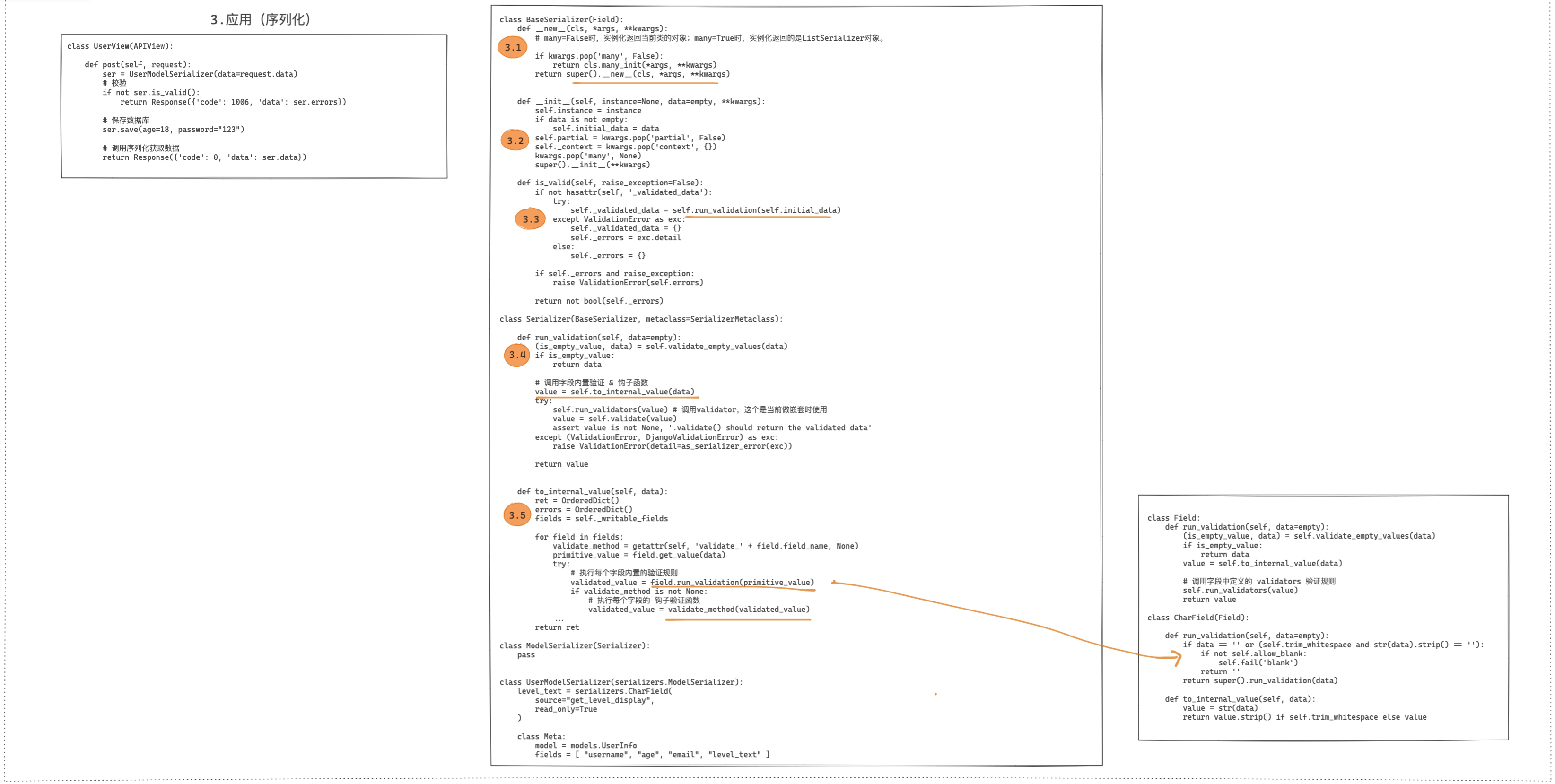
底层源码实现:
序列化的底层源码实现有别于上述其他的组件,序列化器相关类的定义和执行都是在视图中被调用的,所以源码的分析过程可以分为:定义类、序列化、数据校验。
源码1:序列化过程

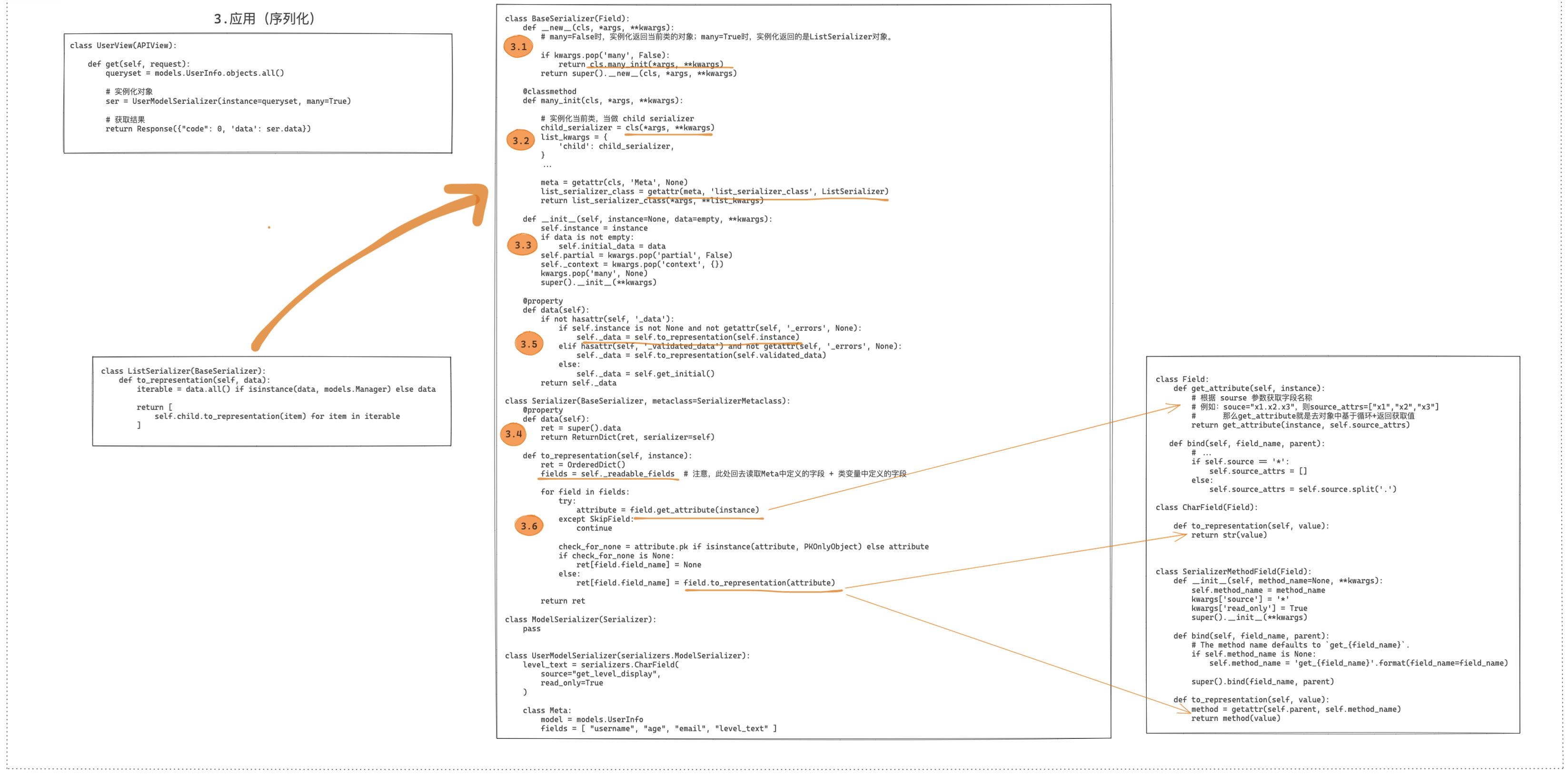
源码2:数据校验过程
















 215
215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











