网页中有用的信息通常存在于网页中的文本或各种不同标签的属性值,为了获得这些网页信息,有必要有一些查找方法可以获取这些文本值或标签属性。而Beautiful Soup中内置了一些查找方式:
- find()
- find_all()
- find_parent()
- find_parents()
- find_next_sibling()
- find_next_siblings()
- find_previous_sibling()
- find_previous_siblings()
- find_previous()
- find_all_previous()
- find_next()
- find_all_next()
使用find()查找
以下这段HTML是例程要用到的参考网页
- <html>
- <body>
- <div class="ecopyramid">
- <ul id="producers">
- <li class="producerlist">
- <div class="name">plants</div>
- <div class="number">100000</div>
- </li>
- <li class="producerlist">
- <div class="name">algae</div>
- <div class="number">100000</div>
- </li>
- </ul>
- <ul id="primaryconsumers">
- <li class="primaryconsumerlist">
- <div class="name">deer</div>
- <div class="number">1000</div>
- </li>
- <li class="primaryconsumerlist">
- <div class="name">rabbit</div>
- <div class="number">2000</div>
- </li>
- <ul>
- <ul id="secondaryconsumers">
- <li class="secondaryconsumerlist">
- <div class="name">fox</div>
- <div class="number">100</div>
- </li>
- <li class="secondaryconsumerlist">
- <div class="name">bear</div>
- <div class="number">100</div>
- </li>
- </ul>
- <ul id="tertiaryconsumers">
- <li class="tertiaryconsumerlist">
- <div class="name">lion</div>
- <div class="number">80</div>
- </li>
- <li class="tertiaryconsumerlist">
- <div class="name">tiger</div>
- <div class="number">50</div>
- </li>
- </ul>
- </body>
- </html>
以上代码是一个生态金字塔的简单展示,为了找到其中的第一生产者,第一消费者或第二消费者,我们可以使用Beautiful Soup的查找方法。一般来说,为了找到BeautifulSoup对象内任何第一个标签入口,我们可以使用find()方法。
找到第一生产者
可以明显看到,生产者在第一个<ul>标签里,因为生产者是在整个HTML文档中第一个<ul>标签中出现,所以可以简单的使用find()方法找到第一生产者。下图HTML树代表了第一个生产者所在位置。
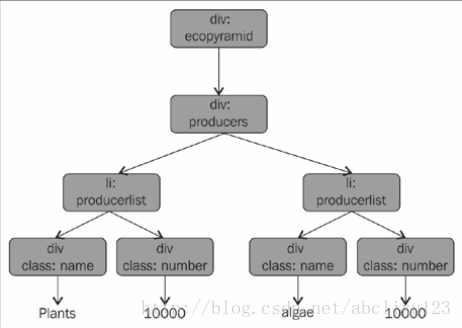
然后在ecologicalpyramid.py中写入下面一段代码,使用ecologicalpyramid.html文件创建BeautifulSoup对象。
- from bs4 import BeautifulSoup
- with open("ecologicalpyramid.html","r") as ecological_pyramid:
- soup = BeautifulSoup(ecological_pyramid)
- producer_entries = soup.find("ul")
- print(producer_entries.li.div.string)
输出得到:plants
find()说明
find()函数如下:
find(name,attrs,recursive,text,**wargs)
这些参数相当于过滤器一样可以进行筛选处理。
不同的参数过滤可以应用到以下情况:
- 查找标签,基于name参数
- 查找文本,基于text参数
- 基于正则表达式的查找
- 查找标签的属性,基于attrs参数
- 基于函数的查找
通过标签查找
我们可以传递任何标签的名字来查找到它第一次出现的地方。找到后,find函数返回一个BeautifulSoup的标签对象。
- from bs4 import BeautifulSoup
-
- with open("ecologicalpyramid.html", "r") as ecological_pyramid:
- soup = BeautifulSoup(ecological_pyramid,"html")
- producer_entries = soup.find("ul")
- print(type(producer_entries))
输出的得到 <class 'bs4.element.Tag'>
通过文本查找
直接字符串的话,查找的是标签。如果想要查找文本的话,则需要用到text参数。如下所示:
- from bs4 import BeautifulSoup
-
- with open("ecologicalpyramid.html", "r") as ecological_pyramid:
- soup = BeautifulSoup(ecological_pyramid,"html")
- plants_string = soup.find(text="plants")
- print(plants_string)
输出:plants
通过正则表达式查找
有以下HTML代码:
- <br/>
- <div>The below HTML has the information that has email ids.</div>
- abc@example.com
- <div>xyz@example.com</div>
- <span>foo@example.com</span>
如果想找出第一个邮箱地址,但是由于第一个邮箱地址没有标签包含,所以通过其他方式很难找到。但是我们可以把邮箱地址进行正则表达式处理,这样就容易多了。
参考如下代码:
- import re
- from bs4 import BeautifulSoup
-
- email_id_example =
-
-
-
-
-
-
- soup = BeautifulSoup(email_id_example)
- emailid_regexp = re.compile("\w+@\w+\.\w+")
- first_email_id = soup.find(text=emailid_regexp)
- print(first_email_id)
输出:abc@example.com
通过标签属性进行查找
观看例程HTML代码,其中第一消费者在ul标签里面且id属性为priaryconsumers.
因为第一消费者出现的ul不是文档中第一个ul,所以通过前面查找标签的办法就行不通了。现在通过标签属性进行查找,参考代码如下:
- from bs4 import BeautifulSoup
-
- with open("ecologicalpyramid.html", "r") as ecological_pyramid:
- soup = BeautifulSoup(ecological_pyramid,"html")
- primary_consumer = soup.find(id="primaryconsumers")
- print(primary_consumer.li.div.string)
输出:deer
通过标签属性查找的方式适用于大多数标签属性,包括id,style,title,但是有一组标签属性例外。
此时,我们需要借助attrs参数来进行传递。
基于定制属性的查找
比如我们HTML5标签中的data-custom属性,如果我们这样
- customattr = ""'<p data-custom="custom">custom attribute
- example</p>"""
- customsoup = BeautifulSoup(customattr,'lxml')
- customSoup.find(data-custom="custom")
那么则会报错。原因是在Python中变量不能呢含有-这个字符,而我们传递的data-custom有-这个字符。
解决的办法是在attrs属性用字典进行传递参数。
- using_attrs = customsoup.find(attrs={'data-custom':'custom'})
- print(using_attrs)
基于CSS类的查找
因为class是Python的保留关键字,所以无法使用class这个关键字。所以解决办法类似上面。
- css_class = soup.find(attrs={'class':'primaryconsumerlist'})
- print(css_class)
还有另一个办法。BeautifulSoup有一个特别的关键字参数class_。示例:
方法1:
- css_class = soup.find(class_ = "primaryconsumers" )
方法2:
- css_class = soup.find(attrs={'class':'primaryconsumers'})
基于定义的函数进行查找
可以传递函数到find()来基于函数定义的条件进行查找。函数值必须返回true或者false。
例子:
- def is_secondary_consumers(tag):
- return tag.has_attr('id') and tag.get('id') ==
- 'secondaryconsumers'
- secondary_consumer = soup.find(is_secondary_consumers)
- print(secondary_consumer.li.div.string)
输出:fox
把方法进行组合后进行查找
可以用其中任何方法进行组合来进行查找,比如同时基于标签名和id号。
使用find_all查找
find()用来查找第一个匹配结果出现的地方,而find_all()正如名字所示,将会找到所有匹配结果出现的地方。应用到find()中的不同过滤参数同理可以用到find_all()中,实际上,过滤参数可以用于任何查找函数,如find_parents()或和find_siblings()。
查找所有三级消费者
- all_tertiaryconsumers =
- soup.find_all(class_="tertiaryconsumerslist")
其all_tertiaryconsumers的类型是列表。
所以我们对其列表进行迭代,循环输出三级消费者的名字。
- for tertiaryconsumer in all_tertiaryconsumers:
- print(tertiaryconsumer.div.string)
输出:
lion
tiger
理解用于find_all()的参数
相比find(),find_all()有个额外的参数limit,如下所示:
find_all(name,attrs,recursive,text,limit,**kwargs)
limit参数可以限制我们想要得到结果的数目。参照前面的邮件地址例子,我们可以得到所有右键地址通过:
- email_ids = soup.find_all(text=emailid_regexp)
- print(email_ids)
输出:[u'abc@example.com',u'xyz@example.com',u'foo@example.com']
当我们使用limit参数,效果如下:
- email_ids_limited = soup.find_all(text=emailid_regexp,limit=2)
- print(email_ids_limited)
限制得到两个结果,所以输出为:
[u'abc@example.com',u'xyz@example.com']
说白了,find()也就是当limit=1时的find_all()。
可以向find函数传递True或False参数,如果我们传递True给find_all(),则返回所有soup对象的标签。对于find()来说,则返回第一个标签。
举例查找文本,传递True将会返回所有文本。
- all_texts = soup.find_all(text=True)
- print(all_texts)
输出:
[u'\n', u'\n', u'\n', u'\n', u'\n', u'plants', u'\n', u'100000',
u'\n', u'\n', u'\n', u'algae', u'\n', u'100000', u'\n', u'\n',
u'\n', u'\n', u'\n', u'deer', u'\n', u'1000', u'\n', u'\n',
u'\n', u'rabbit', u'\n', u'2000', u'\n', u'\n', u'\n',
u'\n', u'\n', u'fox', u'\n', u'100', u'\n', u'\n', u'\n',
u'bear', u'\n', u'100', u'\n', u'\n', u'\n', u'\n',
u'\n', u'lion', u'\n', u'80', u'\n', u'\n', u'\n',
u'tiger', u'\n', u'50', u'\n', u'\n', u'\n', u'\n',
u'\n']
同样的,我们可以在传递text参数时传递一个字符串列表,那么find_all()会找到诶个在列表中定义过的字符串。
- all_texts_in_list = soup.find_all(text=["plants","algae"])
- print(all_texts_in_list)
输出:
这个同样适用于查找标签,标签属性,定制属性和CSS类。如:
- div_li_tags = soup.find_all(["div","li"])
find()和find_all()都会查找一个对象所有后辈们,不过我们可以控制它通过recursive参数。如果recursive=False,那么超找只会找到该对象的最近后代。
通过标签之间的关系进行查找
我们可以通过find()和find_all()来查找到想要内容。但有时候,我们需要查看的与之内容相关先前的标签或者后面的标签来获取额外的信息。比如方法find_parents()和find_next_siblings()等等。一般的,在find()和find_all()方法后使用上述方法,因为find()和find_all()可以找到特殊的一个标签,然后我们可以通过这个特殊的标签找到其他的想要的与之有关系的标签。
查找父标签
通过find_parents()或find_parent()。它们之间的不同就类似于find()和find_all()的区别。find_parents()返回全部的相匹配的父标签,而find_paret()返回最近的一个父标签。适用于find()的方法同样也使用于这两个方法。
在前面的第一消费者例子中,我们可以找到离Primaryconsumer最近的ul父标签。
- primaryconsumers = soup.find_all(class_="primaryconsumerlist")
- primaryconsumer = primaryconsumers[0]
- parent_ul = primaryconsumer.find_parents('ul')
- print(parent_ul)
一个简单的找到一个标签的父标签的方法就是使用find_parent()却不带任何参数。
- immediateprimary_consumer_parent = primary_consumer.find_parent()
查找同胞
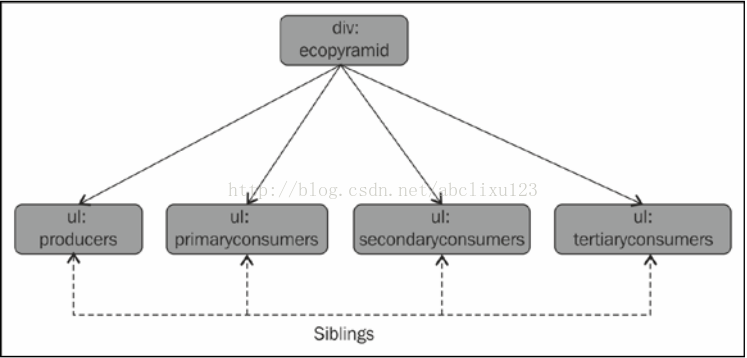
如果标签在同一个等级的话,我们可以说这些标签是同胞的关系,比如参照上面金字塔例子,所有ul标签就是同胞的关系。
上图ul标签下的producers,primaryconsumers,secondaryconsumers,teriaryconsumers就是同胞关系。
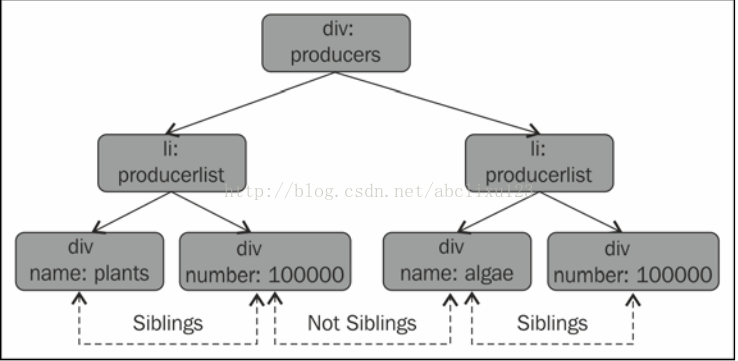
再看下面这个图:
div下的plants和algae不是同胞关系,但是plants和临近的number是同胞关系。
Beautiful Soup自带有查找同胞的方法。
比如find_next_siblings()和find_next_sibling()查找对象下面的同胞。举例:
- producers= soup.find(id='producers')
- next_siblings = producers.find_next_siblings()
- print(next_siblings)
将会输出与之临近的下面的所有同胞HTML代码。
查找下一个
对每一个标签来说,下一个元素可能会是定位字符串,标签对象或者其他BeautifulSoup对象。我们定义下一个元素为与当前元素最靠近的元素。这个不同于同胞定义。我们有方法可以找到我们想要标签的下一个其他元素对象。find_all_next()找到与当前元素靠近的所有对象。而find_next()找到离当前元素最接近的对象。
比如,找到在第一个div标签后的所有li标签
- first_div = soup.div
- all_li_tags = first_div.find_all_next("li")
输出“:
[<li class="producerlist">
<div class="name">plants</div>
<div class="number">100000</div>
</li>, <li class="producerlist">
<div class="name">algae</div>
<div class="number">100000</div>
</li>, <li class="primaryconsumerlist">
<div class="name">deer</div>
<div class="number">1000</div>
</li>, <li class="primaryconsumerlist">
<div class="name">rabbit</div>
<div class="number">2000</div>
</li>, <li class="secondaryconsumerlist">
<div class="name">fox</div>
<div class="number">100</div>
</li>, <li class="secondaryconsumerlist">
<div class="name">bear</div>
<div class="number">100</div>
</li>, <li class="tertiaryconsumerlist">
<div class="name">lion</div>
<div class="number">80</div>
</li>, <li class="tertiaryconsumerlist">
<div class="name">tiger</div>
<div class="number">50</div>
</li>]
查找上一个
与查找下一个相反的是查找前一个。同理用于find_all_previous()和find_all_previous()























 55万+
55万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









