







最近需要用到,根据营业执照来查询企业的名称和地址,首先想到的是企查查之类的网页版,在手动查询几十条之后,发现跳出了个账号登录的页面,无法继续查询,且网页每天每个IP的查询量有限制,遂想到了写个爬虫脚本,使用代理的方式来查。
一、urllib实现
依据fillder抓包,发现在请求qcc.com网址时(GET),会发送相关的6个cookie信息给服务器,之后由服务器返回2个cookie值(包括CDN节点acw_tc、以及企查查服务器QCCSESSID)。由于本人能力有限,无法查到GET请求中,cookie值是通过哪个JS来实现的,只好将浏览器正常访问的cookie值复制下来,所幸这些cookie值的有效期还是挺长的(至少半年的有效期)。
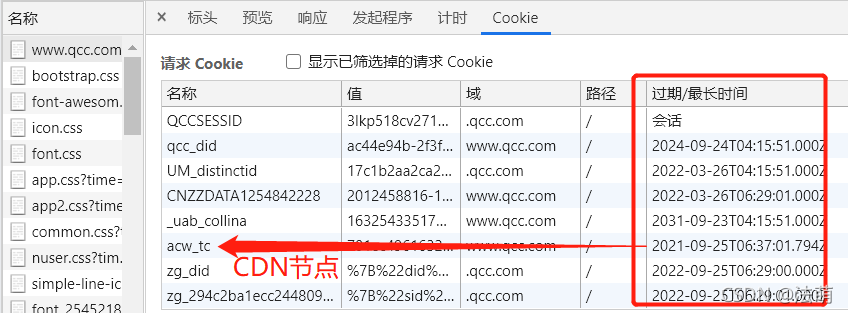
之后,就通过之前的文章:静态网页爬取,写代码来获取相关的数据。
#coding:utf-8
import urllib.request
import http.cookiejar
from lxml import etree
import socket
# 由于Accept-Encoding为gzip,需要解压
from io import BytesIO
import gzip
#设置超时时间为20s
#利用socket模块,使得每次重新下载的时间变短
socket.setdefaulttimeout(10)
header={ 'Host': 'www.qcc.com',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie': 'qcc_did=a18a6f68-1260-4022-a6a7-8dab19625aab; UM_distinctid=17c02f16b7d5a3-0f9813bd7a7761-581e311d-144000-17c02f16b7e4d1; _uab_collina=163213694895228480784965; CNZZDATA1254842228=88823110-1632136235-https%253A%252F%252Fwww.baidu.com%252F%7C1632362960; zg_did=%7B%22did%22%3A%20%2217c02f16ba7466-0272837b64f905-581e311d-144000-17c02f16ba84af%22%7D; zg_294c2ba1ecc244809c552f8f6fd2a440=%7B%22sid%22%3A%201632368833885%2C%22updated%22%3A%201632369586240%2C%22info%22%3A%201632136948658%2C%22superProperty%22%3A%20%22%7B%7D%22%2C%22platform%22%3A%20%22%7B%7D%22%2C%22utm%22%3A%20%22%7B%7D%22%2C%22referrerDomain%22%3A%20%22%22%2C%22cuid%22%3A%20%22undefined%22%2C%22zs%22%3A%200%2C%22sc%22%3A%200%2C%22firstScreen%22%3A%201632368833885%7D',
}
def open_url(url:str, header:dict):
request = urllib.request.Request(url=url, headers=header)
try:
response = opener.open(request)
except:
count = 1
while count <= 5:
try:
response = opener.open(request)
break
except:
err_info = url+'\nReloading for %d time'%count if count == 1 else 'Reloading for %d times'%count
print(err_info)
count += 1
else:
return response
if count > 5:
print("connection fialed!")
else:
return response
def set_proxy(proxy:dict, use_proxy:bool):
opener = None
cjar = http.cookiejar.CookieJar()
cookie = urllib.request.HTTPCookieProcessor(cjar)
if use_proxy:
proxy = urllib.request.ProxyHandler(proxy)
opener = urllib.request.build_opener(proxy, cookie)
else:
opener = urllib.request.build_opener(cookie)
urllib.request.install_opener(opener)
# 获取平台返回的两个cookie信息(acw_tc、QCCSESSID)
url="https://www.qcc.com"
open_url(url, header)
return opener
def get_one_addr(key:str):
# 查询访问
link = "https://www.qcc.com/search?key="+key
print(link)
response = open_url(link, header)
html = response.read()
buff = BytesIO(html)
f = gzip.GzipFile(fileobj=buff)
htmls = f.read().decode('utf-8')
# 解析
content = etree.HTML(htmls)
addr = content.xpath('//div[@class="contact"]//ul[@class="list-unstyled"]//li[last()]//text()')[0].split(":")[-1]
return addr, response.getcode()
def main_get_addr(proxy:dict, key:list, use_proxy=True):
code = 200
opener = set_proxy(proxy, use_proxy)
address = []
for k in key:
if code != 200:
# 获取新的proxy
opener = set_proxy(proxy, use_proxy)
addr, code = get_one_addr(k)
address.append((k, addr))
return address
proxy = {'https':"211.24.95.49:47615"}
key = ['923308*****', '92330******', '9233****', '9233***']
addr = main_get_addr(proxy, key, True)
print(addr)问题:在多次变更代理IP之后,qcc.com返回了一个405错误页面,应该是服务器的反爬措施,猜测是cookie中有些字段的问题,但无法找到问题点,遂打算使用selenium来实现。
二、selenium实现
使用selenium的好处是,避免了cookie的问题,在使用时,参考之前的文章,selenium爬取网页,并借鉴了几篇别人的反爬措施,对相应字段进行设置,包括时区、地理位置、WebRTC、自动控制、超时重连等。
from selenium import webdriver
import requests
from lxml import etree
import socket
from queue import Queue
from selenium.webdriver.chrome.service import Service
#设置超时时间
#利用socket模块,使得每次重新下载的时间变短
socket.setdefaulttimeout(20)
addr_queue = Queue(maxsize=1000)
def main_get_addr(proxy:str, key_queue, use_proxy:bool):
"""proxy = 'http://27.192.200.7:9000'"""
global addr_queue
chrome_options = webdriver.ChromeOptions()
# v78版本及以上chrome解决受自动控制软件的提示
# https://www.cnblogs.com/dream66/p/12522252.html
chrome_options.add_experimental_option( "excludeSwitches", ["enable-automation"])
chrome_options.add_experimental_option('useAutomationExtension', False)
if use_proxy:
print('using proxy: '+proxy)
# 使用代理
chrome_options.add_argument("--proxy-server={}".format(proxy))
# 关闭WebRTC,避免代理被发现
# https://mp.weixin.qq.com/s/zqW2cN2dNJoRjOfVsNUONA
preferences = {
"webrtc.ip_handling_policy": "disable_non_proxied_udp",
"webrtc.multiple_routes_enabled": False,
"webrtc.nonproxied_udp_enabled": False
}
chrome_options.add_experimental_option("prefs", preferences)
# 告诉chrome去掉webdriver痕迹
# https://mp.weixin.qq.com/s/U45x8HCPpNe-22LRtXYaNQ
chrome_options.add_argument("disable-blink-features=AutomationControlled")
# 浏览器驱动下载 https://blog.csdn.net/kenny_pj/article/details/103646745
chrome_options.binary_location = r'F:\360极速浏览器\360Chrome\Chrome\Application\360chrome.exe'
# driver.quit()无法关闭
# https://blog.csdn.net/yangfengjueqi/article/details/84338167
c_service = Service('./chromedriver.exe')
c_service.command_line_args()
c_service.start()
driver = webdriver.Chrome('./chromedriver.exe', options=chrome_options)
if use_proxy:
# 设置时区和地理位置,避免代理被发现
# https://mp.weixin.qq.com/s/bs4FHpWvh1VEhcylgcNUTA
def get_timezone_geolocation(ip):
import requests
url = f"http://ip-api.com/json/{ip}"
response = requests.get(url)
return response.json()
res_json = get_timezone_geolocation(proxy.split(':')[1][2:])
print(res_json)
geo = {
"latitude": res_json["lat"],
"longitude": res_json["lon"],
"accuracy": 1
}
tz = {
"timezoneId": res_json["timezone"]
}
driver.execute_cdp_cmd("Emulation.setGeolocationOverride", geo)
driver.execute_cdp_cmd("Emulation.setTimezoneOverride", tz)
retry_num = 2
# 处理1:获取数据,超时重连
try:
driver.get('https://www.baidu.com')
driver.get('https://www.qcc.com')
except:
count = 1
while count <= retry_num:
try:
driver.get('https://www.baidu.com')
driver.get('https://www.qcc.com')
break
except:
err_info = 'Reloading for %d time'%count if count == 1 else 'Reloading for %d times'%count
print(err_info)
count += 1
if count > retry_num:
print("connection fialed!")
driver.quit() #关闭浏览器
c_service.stop()
return True
while not key_queue.empty():
key = key_queue.get()
url = "https://www.qcc.com/web/search?key="+key
# 处理1:获取数据,超时重连
try:
driver.get(url)
except:
count = 1
while count <= retry_num:
try:
driver.get(url)
break
except:
err_info = url+'\nReloading for %d time'%count if count == 1 else 'Reloading for %d times'%count
print(err_info)
count += 1
if count > retry_num:
print("connection fialed!")
key_queue.put(key)# 因为未查询,添加到待查列表中
driver.quit() #关闭浏览器
c_service.stop()
return True
# 处理2:405页面
if driver.current_url == 'http://diag.qichacha.com/405.html':
print("405 page error!")
key_queue.put(key)# 因为未查询,添加到待查列表中
driver.quit() #关闭浏览器
c_service.stop()
return True
# 处理3:页面内容,可能会跳转到登录页面
content = etree.HTML(driver.page_source)
addr =content.xpath('//span[@class="val long-text"]//text()')[0]
if addr == []:
print("address is none!")
key_queue.put(key)# 因为未查询,添加到待查列表中
driver.quit() #关闭浏览器
c_service.stop()
return True
addr_queue.put((key, addr))
driver.quit() #关闭浏览器
c_service.stop()
return False
if __name__=="__main__":
key_queue = Queue(maxsize=1000)
for k in ['923302*****', '9233****', '9233021****', '92330***']:
key_queue.put(k)
for p in ['http://211.65.197.93:80', 'http://182.84.145.38:3256']:
is_change_proxy = main_get_addr(proxy=p, key_queue=key_queue, use_proxy=True)
while not addr_queue.empty():
print(addr_queue.get())
问题:
1、似乎是我选的proxy有问题,使用代理的时候,都打不开网页;不使用代理的话,能顺利打开;
2、因代理问题,需要频繁的打开关闭浏览器,导致driver.quit()有时超时无响应,虽然跟使用了service的方式,但有时还会有问题;
三、使用多查询网址
截止目前,cookie的问题可以使用selenium来解决,但是proxy的问题没有好的解决办法。因此打算通过使用不同的查询网址,每个网站查几条的方式(所幸数据量不是很大,1天也就200条左右)。有以下几种可以通过营业执照ID来查询的网页:
- 企查查(无需登录,有数量限制,www.qcc.com/web/search?key=92***);
- 天眼查(无需登录,有数量限制,www.tianyancha.com/search?key=92***);
- 爱企查(无需登录,有数量限制,aiqicha.baidu.com/s?q=92***);
- 企查猫(要登录,ww.qichamao.com);
- 企信宝(要登录,www.qixin.com);
- 国家企业信用信息公示系统(以上网页的数据来源,有图形验证码,似乎不稳定,我查询的时候出现500错误);
PS:批量查询仅支持上传的excel中为企业名称。
每个不同的网页,所使用Xpath不同,需要定制。
后续将进行cookie的解析

















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









