






实验内容或者文献情况介绍
实验内容为理解并利用主成份分析(PCA)和鲁棒主成份分析(RPCA),对mnist数据集进行分类处理。
在这次实验中,我在利用PCA以及RPCA进行无监督的无标签样本降维后,均使用了Knn算法进行分类,并进行准确度(Accuracy)计算并输出。
算法简介及其实现细节
样本降维的本质就是将高维样本数据嵌入到低维空间中,去除噪声和不重要的特征,并保留大部分的本质信息,以提升数据处理速度,使得数据集更易使用,降低算法的计算开销,去除噪声,并使得结果容易理解。
这些优点使其常应用于可视化,分类,视觉,NLP等等的数据预处理。它可以分为三类,分别为有监督的维数缩减,即样本有类别标签,如LDA;无监督维数缩减,即样本没有类别标签,如PCA;线性和非线性维数缩减,如FDA。
在这次实验中,我们是对无标签的MINIST数据集进行分类,应用的是PCA和RPCA算法,因此以下我将对这两个降维算法进行介绍,并写出实现细节。
2.1 PCA原理简介
PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。
PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。
PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。[1]
通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
关于具有最大差异性的主成分方向的寻找,我们一般通过计算数据矩阵的协方差矩阵,然后得到协方差矩阵的特征值特征向量,选择特征值最大(即方差最大)的k个特征所对应的特征向量组成的矩阵。这样就可以将数据矩阵转换到新的空间当中,实现数据特征的降维。
由于得到协方差矩阵的特征值特征向量有两种方法:特征值分解协方差矩阵、奇异值分解协方差矩阵,所以PCA算法有两种实现方法:基于特征值分解协方差矩阵实现PCA算法、基于SVD分解协方差矩阵实现PCA算法。

图1 基于特征值分解协方差矩阵实现PCA算法的基本思想

图2 基于SVD分解协方差矩阵实现PCA算法
在PCA降维中,我们需要找到样本协方差矩阵的最大k个特征向量,然后用这最大的k个特征向量组成的矩阵来做低维投影降维。可以看出,在这个过程中需要先求出协方差矩阵。而利用SVD的一些算法可以先不求出协方差矩阵,这也就大大减少了计算量,提高了计算速度[1]。比如我使用的sklearn库中的PCA算法的背后真正的实现就是用的SVD,而不是特征值分解。
在本次实验中我直接使用了python的sklearn库里自带的PCA算法提取出了数据的主要特征,它属于基于SVD分解协方差矩阵实现PCA算法。
2.2 PCA实现细节
PCA能够降低数据的复杂性、识别重要的多个特征,但也可能损失有用信息,其适用数据类型主要为数值型数据等。
PCA将数据转换成前N个主成分大致流程:
1.去除平均值;
2.计算协方差矩阵;
3.计算协方差矩阵的特征值和特征向量;
4.将特征值从大到小排序;
5.保留最上面的N个特征向量;
6.将数据转换到上述N个特征向量构建的新空间中.(实现数据降维)
函数:实现数据降维[2]
输入:datMat进行降维的数据,topNfeat选取的特征数目
输出:返回降维后的数据矩阵及该矩阵重构出原始数据矩阵
示例代码和注释如下:
def pca(dataMat, topNfeat=9999999):
meanVals = mean(dataMat, axis=0) #求数据矩阵每列的均值
meanRemoved = dataMat - meanVals #数据矩阵每列特征减去该列的特征均值
covMat = cov(meanRemoved, rowvar=0)
#计算协方差矩阵,除数n-1是为了得到协方差的无偏估计, cov(X,0) = cov(X) 除数是n-1(n为样本个数),cov(X,1) 除数是n
eigVals,eigVects = linalg.eig(mat(covMat)) #计算协方差矩阵的特征值和特征向量
eigValInd = argsort(eigVals)
#对特征值矩阵进行由小到大排序,返回对应排序后的索引
eigValInd = eigValInd[:-(topNfeat+1):-1]
#从排序后的矩阵最后一个开始自下而上选取最大的N个特征值,返回其对应的索引
redEigVects = eigVects[:,eigValInd]
#将特征值最大的N个特征值对应索引的特征向量提取出来,组成降维矩阵
lowDDataMat = meanRemoved * redEigVects
#将去除均值后的数据矩阵*压缩矩阵,转换到新的空间,使维度降低为N
reconMat = (lowDDataMat * redEigVects.T) + meanVals
#利用降维后的矩阵反构出原数据矩阵(用作测试,可跟未降维的原矩阵比对)
return lowDDataMat, reconMat
#返回降维后的数据矩阵及该矩阵重构出原始数据矩阵
但方便起见,我在MINIST数据集分类的代码里直接使用了sklearn库里自带的基于SVD分解的PCA算法,而没有自己进行PCA的编写。
2.3 RPCA原理简介

2.4 RPCA实现细节
代码中RPCA函数部分如下,我是在PCA的实现基础上进行了矩阵分解从而实现RPCA。
def RPCA(X, lmbda = 0.01, tol = 1e-7, maxIter = 1000):
Y = X
norm_two = norm(Y.ravel(), 2)
norm_inf = norm(Y.ravel(), np.inf) / lmbda
dual_norm = np.max([norm_two, norm_inf])
Y = Y /dual_norm
A = np.zeros(Y.shape)
E = np.zeros(Y.shape)
dnorm = norm(X, 'fro')
mu = 1.25 / norm_two
rho = 1.5
sv = 10.
n= Y.shape[0]
itr = 0
while True:
Eraw = X - A + (1/mu) * Y
Eupdate = np.maximum(Eraw - lmbda / mu, 0) + np.minimum(Eraw + lmbda / mu, 0)
U, S, V = svd(X - Eupdate + (1 / mu) * Y, full_matrices=False)
svp = (S > 1 / mu).shape[0]
if svp < sv:
sv = np.min([svp + 1, n])
else:
sv = np.min([svp + round(0.05 * n), n])
Aupdate = np.dot(np.dot(U[:, :svp], np.diag(S[:svp] - 1 / mu)), V[:svp, :])
A = Aupdate
E = Eupdate
Z = X - A - E
Y = Y + mu * Z
mu = np.min([mu * rho, mu * 1e7])
itr += 1
if ((norm(Z) / dnorm) < tol) or (itr >= maxIter):
break
print("iteration: %d" % (itr))
return A, E
实验具体步骤及结果
我使用的实验数据集是MINIST数据集,其保存方式是.gz的压缩包形式。
同时我也试图对结果进行可视化,但没有太成功,就删掉了,在此只输出Accuracy等数据。
3.1 PCA+Knn进行MINIST数据集分类
算法的基本思路包含加载数据集(此处选择加载本地路径的MINIST数据集,形式为.gz的压缩包形式),之后将每张图片展开到一维,然后调用sklearn库中的PCA函数,利用主成分分析对数据进行降维。
降维的主要原因是在原有数据的784维特征空间内进行KNN聚类的计算开销过大,因此采用PCA算法提取出原有数据的主要特征。此具体算法中提取了原有图片的100个主要特征,并构建了100维的特征空间。
最后调用sklearn库中的K邻接分类函数对降维后的mnist进行KNN分类,并计算score,输出其值(Accuracy)即可。[5]
代码见附录1,运行结果如下:
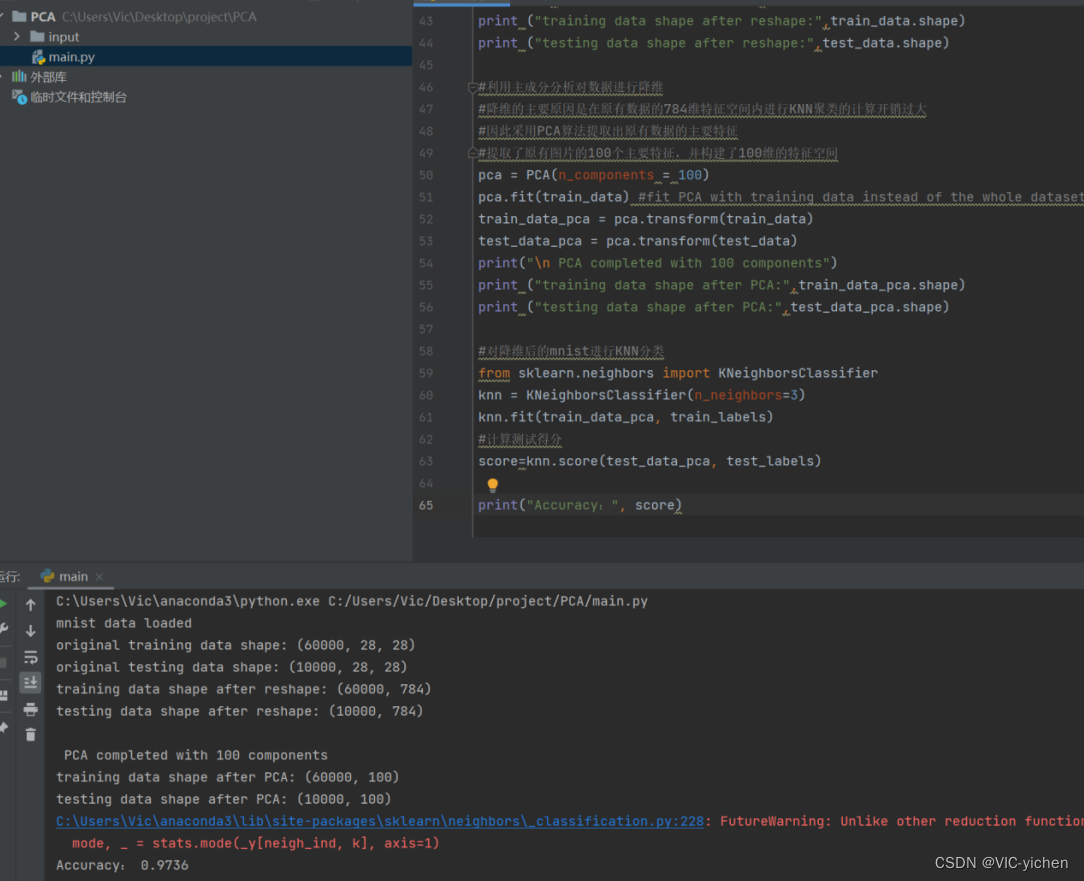
3.2 RPCA+Knn进行MINIST数据集分类
算法的基本思路大部分和PCA类似,包含加载数据集(此处选择加载本地路径的MINIST数据集,形式为.gz的压缩包形式),之后将每张图片展开到一维,然后调用在代码中已经写出的RPCA函数,利用RPCA对数据矩阵分解,数据进行降维。
最后同样调用sklearn库中的K邻接分类函数对降维后的mnist进行KNN分类,k=3,并计算score,输出其值(Accuracy)即可。
运行结果如下:
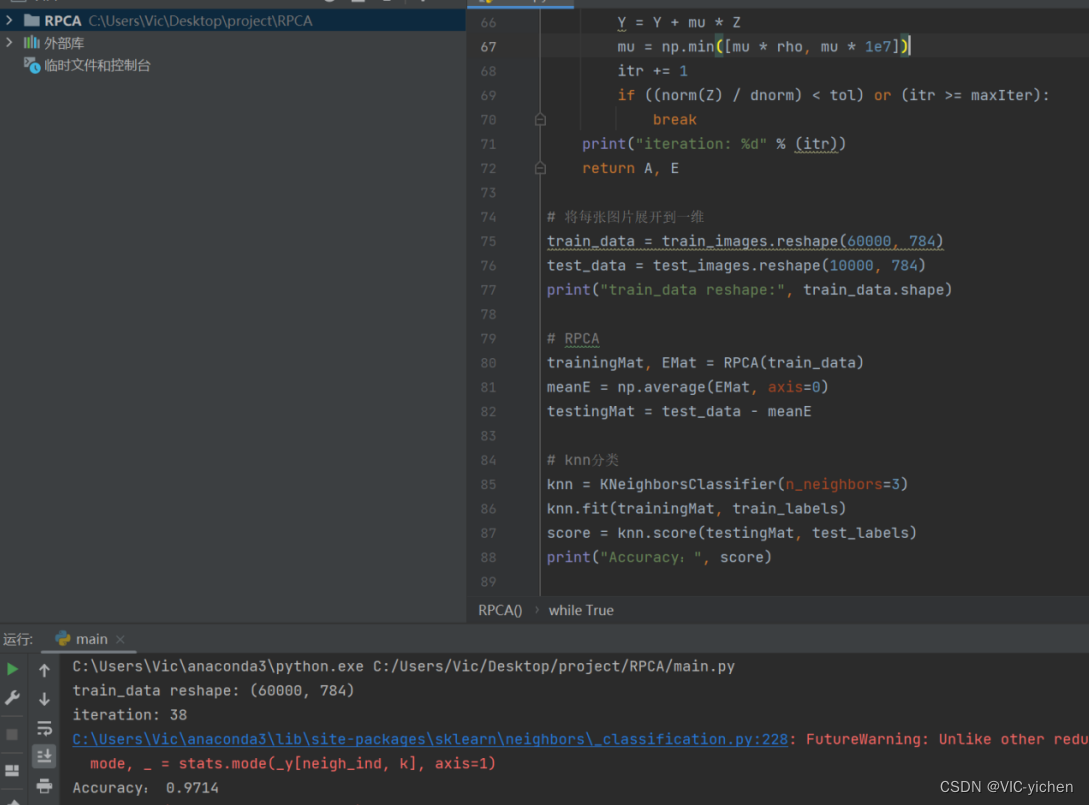
结论
由实验可见,由于数据集不大,结果准确度都很高且接近。
下面是对区别的分析,Robust PCA与经典PCA问题一样,Robust PCA本质上也是寻找数据在低维空间上的最佳投影问题。对于低秩数据观测矩阵D,假如D受到随机(稀疏)噪声的影响,则D的低秩性就会破坏,使D变成满秩的。所以就需要将D分解成包含其真实结构的低秩矩阵A和稀疏噪声矩阵E之和。找到了低秩矩阵,实际上就找到了数据的本质低维空间。同时因为PCA前提假设的数据的噪声是高斯的,对于大的噪声或者严重的离群点,PCA会被它影响,导致其无法正常工作。而Robust PCA则不存在这个假设(Robust PCA假设噪声是稀疏的,而不管噪声的强弱)[3]。但由于MINIST数据集没有这些问题,就会导致都可以较准确的工作。
参考文献
- YongqiangGao. 主成分分析(PCA). 2017-08-31. [DB/OL]. 主成分分析(PCA)_主成分分析csdn_YongqiangGao的博客-CSDN博客
- Microstrong. 主成分分析(PCA)原理详解. 2018-06-08. [DB/OL]. 主成分分析(PCA)原理详解 - 知乎
- YongqiangGao. PCA 与 Robust PCA区别. 2017-09-02. [DB/OL]. PCA 与 Robust PCA区别_YongqiangGao的博客-CSDN博客
- mk12306. 主成分分析(PCA)原理和鲁棒主成分分析(RPCA)详解. 2019-10-21. [DB/OL]. 主成分分析(PCA)原理和鲁棒主成分分析(RPCA)详解_mk12306的博客-CSDN博客
- becatjd. python mnist数据集PCA降维后KNN分类 97%准确率. 2020-05-15. [DB/OL]. https://blog.csdn.net/becatjd/article/details/106146338?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168578804316800180657438%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=168578804316800180657438&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-106146338-null-null.142^v88^insert_down38v5,239^v2^insert_chatgpt&utm_term=%E7%94%A8pca%E5%92%8Crpca%E7%94%A8%E6%9D%A5%E5%AF%B9mnist%E6%95%B0%E6%8D%AE%E9%9B%86%E8%BF%9B%E8%A1%8C%E5%88%86%E7%B1%BB&spm=1018.2226.3001.4187
附录1 PCA+Knn MINIST数据集分类代码[5]
- # 导入mnist数据集
- import numpy as np
- import os, gzip
- from sklearn.decomposition import PCA
- # 加载本地mnist数据集
- def load_data(data_folder):
- files = [
- 'train-labels-idx1-ubyte.gz', 'train-images-idx3-ubyte.gz',
- 't10k-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz'
- ]
- paths = []
- for fname in files:
- paths.append(os.path.join(data_folder, fname))
- with gzip.open(paths[0], 'rb') as lbpath:
- y_train = np.frombuffer(lbpath.read(), np.uint8, offset=8)
- with gzip.open(paths[1], 'rb') as imgpath:
- x_train = np.frombuffer(
- imgpath.read(), np.uint8, offset=16).reshape(len(y_train), 28, 28)
- with gzip.open(paths[2], 'rb') as lbpath:
- y_test = np.frombuffer(lbpath.read(), np.uint8, offset=8)
- with gzip.open(paths[3], 'rb') as imgpath:
- x_test = np.frombuffer(
- imgpath.read(), np.uint8, offset=16).reshape(len(y_test), 28, 28)
- return (x_train, y_train), (x_test, y_test)
- (train_images, train_labels), (test_images, test_labels) = load_data('C:\\Users\\Vic\\Desktop\\project\\RPCA\\MNIST_Data')
- print("mnist data loaded")
- print("original training data shape:", train_images.shape)
- print("original testing data shape:", test_images.shape)
- #将每张图片展开到一维
- train_data=train_images.reshape(60000,784)
- test_data=test_images.reshape(10000,784)
- print ("training data shape after reshape:",train_data.shape)
- print ("testing data shape after reshape:",test_data.shape)
- #利用主成分分析对数据进行降维
- #降维的主要原因是在原有数据的784维特征空间内进行KNN聚类的计算开销过大
- #因此采用PCA算法提取出原有数据的主要特征
- #提取了原有图片的100个主要特征,并构建了100维的特征空间
- pca = PCA(n_components = 100)
- pca.fit(train_data)
- train_data_pca = pca.transform(train_data)
- test_data_pca = pca.transform(test_data)
- print("\n PCA completed with 100 components")
- print ("training data shape after PCA:",train_data_pca.shape)
- print ("testing data shape after PCA:",test_data_pca.shape)
- #对降维后的mnist进行KNN分类
- from sklearn.neighbors import KNeighborsClassifier
- knn = KNeighborsClassifier(n_neighbors=3)
- knn.fit(train_data_pca, train_labels)
- #计算测试得分
- score=knn.score(test_data_pca, test_labels)
- print("Accuracy:", score)
附录2 RPCA+Knn MINIST数据集分类代码
- import numpy as np
- import os, gzip
- from sklearn.neighbors import KNeighborsClassifier
- from numpy.linalg import norm, svd
- # 加载本地mnist数据集
- def load_data(data_folder):
- files = [
- 'train-labels-idx1-ubyte.gz', 'train-images-idx3-ubyte.gz',
- 't10k-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz'
- ]
- paths = []
- for fname in files:
- paths.append(os.path.join(data_folder, fname))
- with gzip.open(paths[0], 'rb') as lbpath:
- y_train = np.frombuffer(lbpath.read(), np.uint8, offset=8)
- with gzip.open(paths[1], 'rb') as imgpath:
- x_train = np.frombuffer(
- imgpath.read(), np.uint8, offset=16).reshape(len(y_train), 28, 28)
- with gzip.open(paths[2], 'rb') as lbpath:
- y_test = np.frombuffer(lbpath.read(), np.uint8, offset=8)
- with gzip.open(paths[3], 'rb') as imgpath:
- x_test = np.frombuffer(
- imgpath.read(), np.uint8, offset=16).reshape(len(y_test), 28, 28)
- return (x_train, y_train), (x_test, y_test)
- (train_images, train_labels), (test_images, test_labels) = load_data('C:\\Users\\Vic\\Desktop\\project\\RPCA\\MNIST_Data')
- #RPCA
- def RPCA(X, lmbda = 0.01, tol = 1e-7, maxIter = 1000):
- Y = X
- norm_two = norm(Y.ravel(), 2)
- norm_inf = norm(Y.ravel(), np.inf) / lmbda
- dual_norm = np.max([norm_two, norm_inf])
- Y = Y /dual_norm
- A = np.zeros(Y.shape)
- E = np.zeros(Y.shape)
- dnorm = norm(X, 'fro')
- mu = 1.25 / norm_two
- rho = 1.5
- sv = 10.
- n= Y.shape[0]
- itr = 0
- while True:
- Eraw = X - A + (1/mu) * Y
- Eupdate = np.maximum(Eraw - lmbda / mu, 0) + np.minimum(Eraw + lmbda / mu, 0)
- U, S, V = svd(X - Eupdate + (1 / mu) * Y, full_matrices=False)
- svp = (S > 1 / mu).shape[0]
- if svp < sv:
- sv = np.min([svp + 1, n])
- else:
- sv = np.min([svp + round(0.05 * n), n])
- Aupdate = np.dot(np.dot(U[:, :svp], np.diag(S[:svp] - 1 / mu)), V[:svp, :])
- A = Aupdate
- E = Eupdate
- Z = X - A - E
- Y = Y + mu * Z
- mu = np.min([mu * rho, mu * 1e7])
- itr += 1
- if ((norm(Z) / dnorm) < tol) or (itr >= maxIter):
- break
- print("iteration: %d" % (itr))
- return A, E
- # 将每张图片展开到一维
- train_data = train_images.reshape(60000, 784)
- test_data = test_images.reshape(10000, 784)
- print("train_data reshape:", train_data.shape)
- # RPCA
- trainingMat, EMat = RPCA(train_data)
- meanE = np.average(EMat, axis=0)
- testingMat = test_data - meanE
- # knn分类
- knn = KNeighborsClassifier(n_neighbors=3)
- knn.fit(trainingMat, train_labels)
- score = knn.score(testingMat, test_labels)
- print("Accuracy:", score)
附录3 运行注释
- MINIST数据集下载地址:MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
- 代码运行前需要将本地代码地址修改成本机数据集所在文件夹地址














 773
773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









