







 主成分分析(principal component analysis)是一种常见的数据降维方法,其目的是在“信息”损失较小的前提下,将高维的数据转换到低维,从而减小计算量。这里的“信息”指的是数据所包含的有用的信息。主要思路:从原始特征中计算出一组按照“重要性”从大到小排列的新特征,它们是原始特征的线性组合(或者说它们是原始特征在某个方向的映射,线性组合是多个特征乘以一个系数,在某个方向的映射也相...
主成分分析(principal component analysis)是一种常见的数据降维方法,其目的是在“信息”损失较小的前提下,将高维的数据转换到低维,从而减小计算量。这里的“信息”指的是数据所包含的有用的信息。主要思路:从原始特征中计算出一组按照“重要性”从大到小排列的新特征,它们是原始特征的线性组合(或者说它们是原始特征在某个方向的映射,线性组合是多个特征乘以一个系数,在某个方向的映射也相...
主成分分析(principal component analysis)是一种常见的数据降维方法,其目的是在“信息”损失较小的前提下,将高维的数据转换到低维,从而减小计算量。这里的“信息”指的是数据所包含的有用的信息。
主要思路:从原始特征中计算出一组按照“重要性”从大到小排列的新特征,它们是原始特征的线性组合(或者说它们是原始特征在某个方向的映射,线性组合是多个特征乘以一个系数,在某个方向的映射也相当于每个特征与该方向的内积,是一样的道理),并且相互之间互不相关。
因此,关键点就在于:1.特征的“重要性”指的是什么?如何衡量?2.将原始数据降到多少维才能保证损失的“信息”较少?
1.数据“重要性”的衡量
数据的“重要性”指的是特征变换后样本的方差。方差越大,则样本在该特征上的差异就越大,因此该特征就越重要。以《机器学习实战》上的图说明。
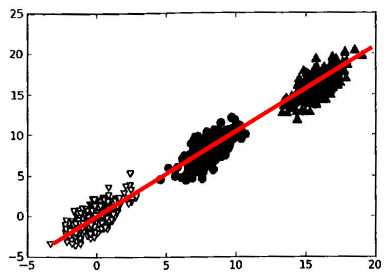
图中共有3个类别的数据,很显然,方差越大,越容易分开不同类别的点。样本在X轴上的投影方差较大,在Y轴的投影方差较小。方差最大的方向应该是中间斜向上的方向。如果将样本按照中间斜向上的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 427
427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









