







文章目录
前言
本文仅供参考,爬取豆瓣电影等内容可能涉及法律问题。请遵循相关使用条款,若涉及任何违法行为产生的后果,请您自行承担。
本篇文章讲述了在提取豆瓣电影TOP250信息中,利用多种技术手段可以有效地提高数据提取的效率与安全性。首先,使用 requests 库发送 HTTP 请求并设置 User-Agent 以避免被网站识别,同时采用代理 IP 隐藏真实地址,降低被封禁的风险。通过 threading 库实现多线程并发请求,加速爬取过程。数据解析方面,使用 lxml 的 etree 结合 XPath 表达式提取目标信息,尽量避免异常的出现,并在出错时重试。最终,通过 pymysql 将数据安全存储到 MySQL 数据库中,确保数据的有效管理。
提示:以下是本篇文章正文内容,下面案例可供参考
一、相关技术概述
- HTTP请求
使用 requests 库发送 HTTP 请求,获取网页内容。
通过设置 User-Agent 模拟浏览器请求,以避免被网站识别为爬虫。 - 代理IP
使用代理IP列表 (proxy_list) 来随机选择代理进行请求。这有助于隐藏真实IP地址,减少被网站封禁的风险。 - 多线程
使用 threading 库实现多线程并发请求,提升爬取效率。每个页面的爬取都在独立线程中进行,从而加快整体爬取速度。 - HTML解析
使用 lxml 库中的 etree 进行 HTML 解析,提取所需数据。
通过 XPath 表达式查找特定元素(如电影标题、评分、排名、评价人数、影片主页链接)。 - 异常处理
使用 try-except 语句捕获请求异常(如网络错误、超时等),并在出现错误时进行重试。 - 数据库操作(mysql数据库存储信息)
使用 pymysql 库连接 MySQL 数据库,将爬取的数据存储到数据库中。
在数据库中插入数据时,使用参数化查询(%s)来防止 SQL 注入攻击。
二、前期准备工作
在正式开始项目之前,我们需要完成以下准备工作:
1.Python 安装
下载并安装最新版本的 Python(推荐使用 Python 3.12.1)以确保我们可以利用其最新功能和库。可以访问Python 官方网站进行下载。
我自己的python版本:Python 3.12.1

2.MySQL 安装
安装 MySQL 数据库,以便管理和存储项目所需的数据。你可以从 MySQL 官方网站 获取安装包和相关文档。我推荐使用小皮面板 phpStudy v8.1版本,它的界面对新手非常友好,操作简单,安装过程也很轻松,环境配置不复杂。
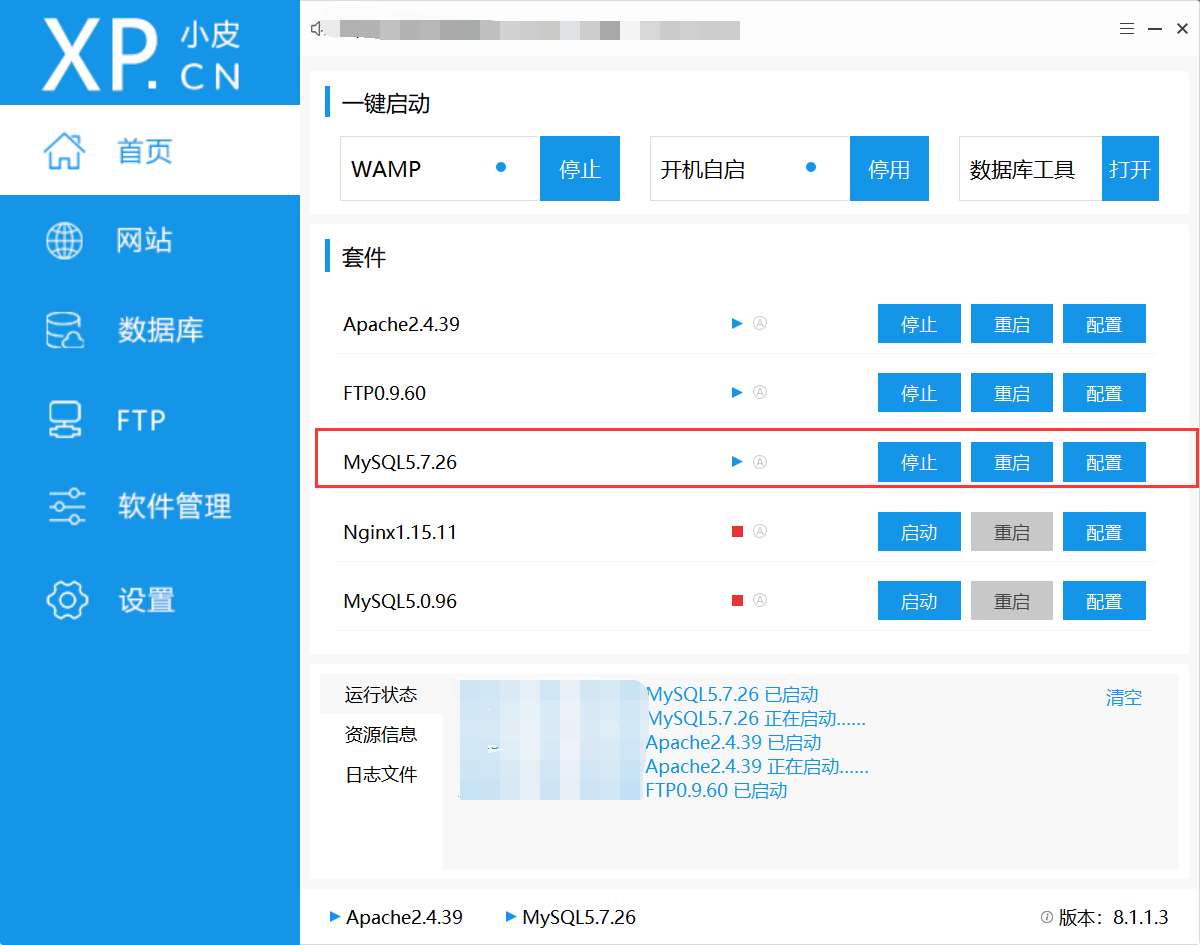
3.需要的库
以下库需通过终端使用pip进行安装:
requests
lxml
pymysql
requests:用于发送 HTTP 请求。
lxml:用于解析和处理 XML 和 HTML 文档。
pymysql:用于连接和操作 MySQL 数据库。
其他的库,如 time、threading 和 random是 Python 的内置库,不需要单独安装。
因此,你可以使用以下命令在终端安装所需的库:
pip install requests lxml pymysql
二、分析网页,实现爬取逻辑
我们要爬取的网页是豆瓣电影Top250:https://movie.douban.com/top250
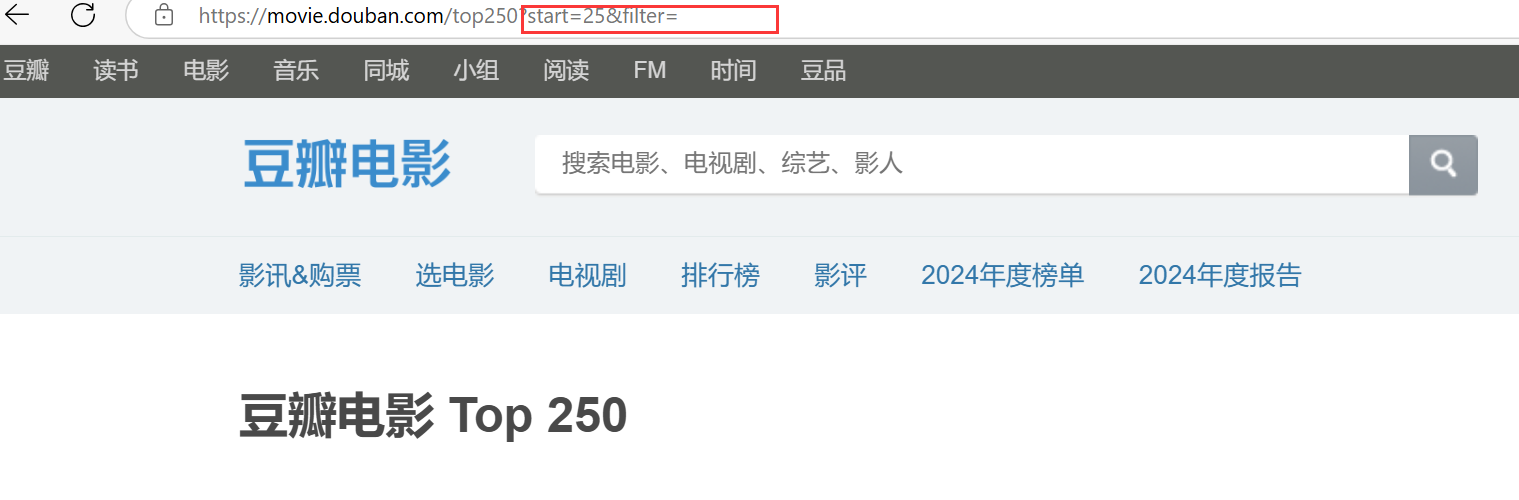
通过分析页面可以知道每页显示25部电影,start=0 时从第1部开始显示,start=25时从第26部开始显示。所以需要爬取的网页链接:“https://movie.douban.com/top250?start={page * 25}&filter=”,使用这个链接时,通过替换 {page * 25} 的值可以获取不同页码的电影数据,从而逐页爬取豆瓣电影Top 250的相关信息。
例如:
如果 page 为0,start=0,获取第一页的电影。
如果 page 为1,start=25,获取第二页的电影,以此类推。
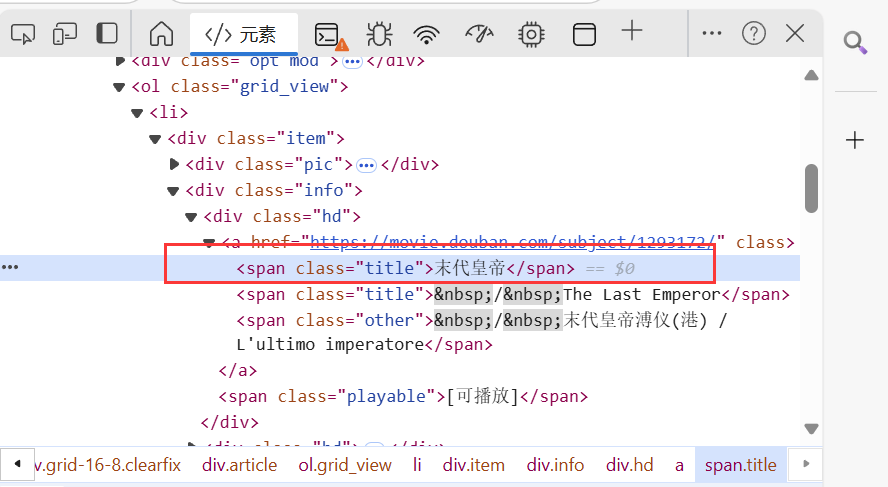
浏览器显示了豆瓣电影top250相关信息,包括电影标题、评分、排名、评价人数等。通过浏览器开发者工具(F12)还可看到视频对应的链接地址。这里的电影标题、评分、排名、评价人数、影片主页链接就是我们需要提取的目标数据。
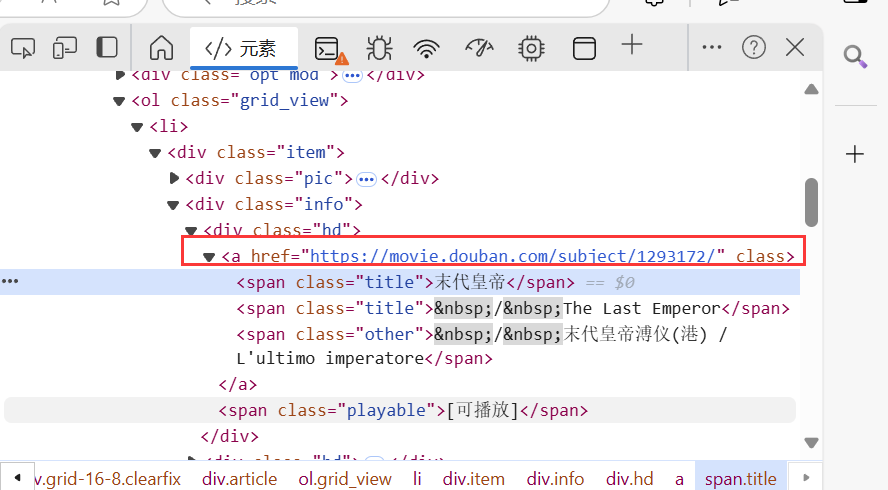
找到所需提取的信息,然后右键单击以复制其XPath。
比如电影标题://*[@id=“content”]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]
三、 规划数据存储方式
将提取到的信息保存到mysql数据库中
启动小皮
在数据库那创建数据库

连接数据库,我选择默认的root用户进行连接。
创建数据库douban
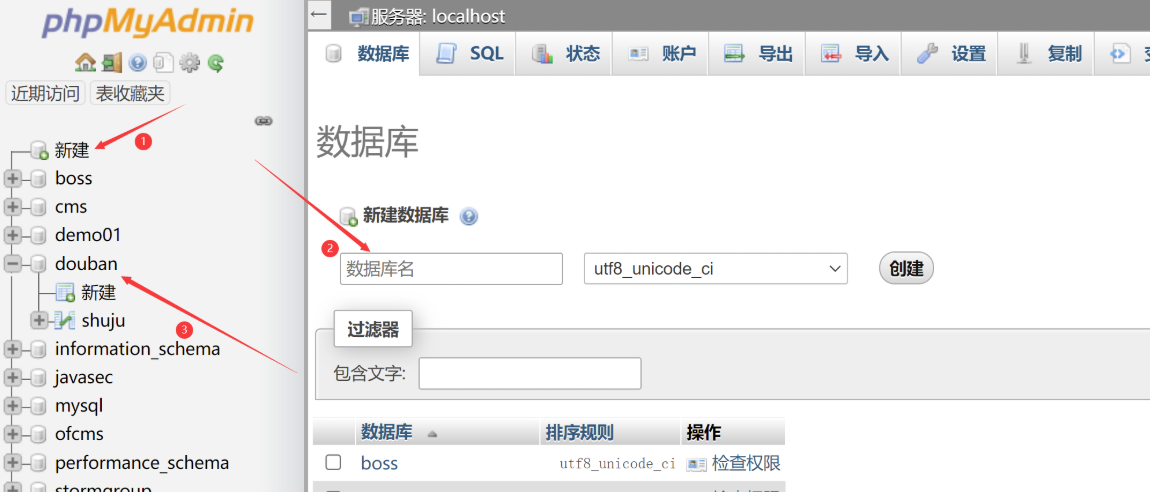
创建表shuju
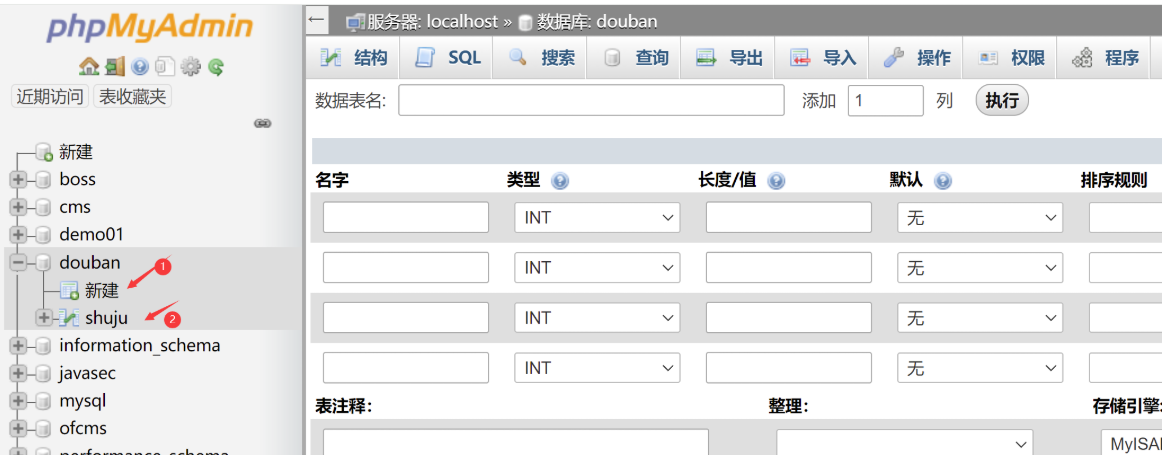
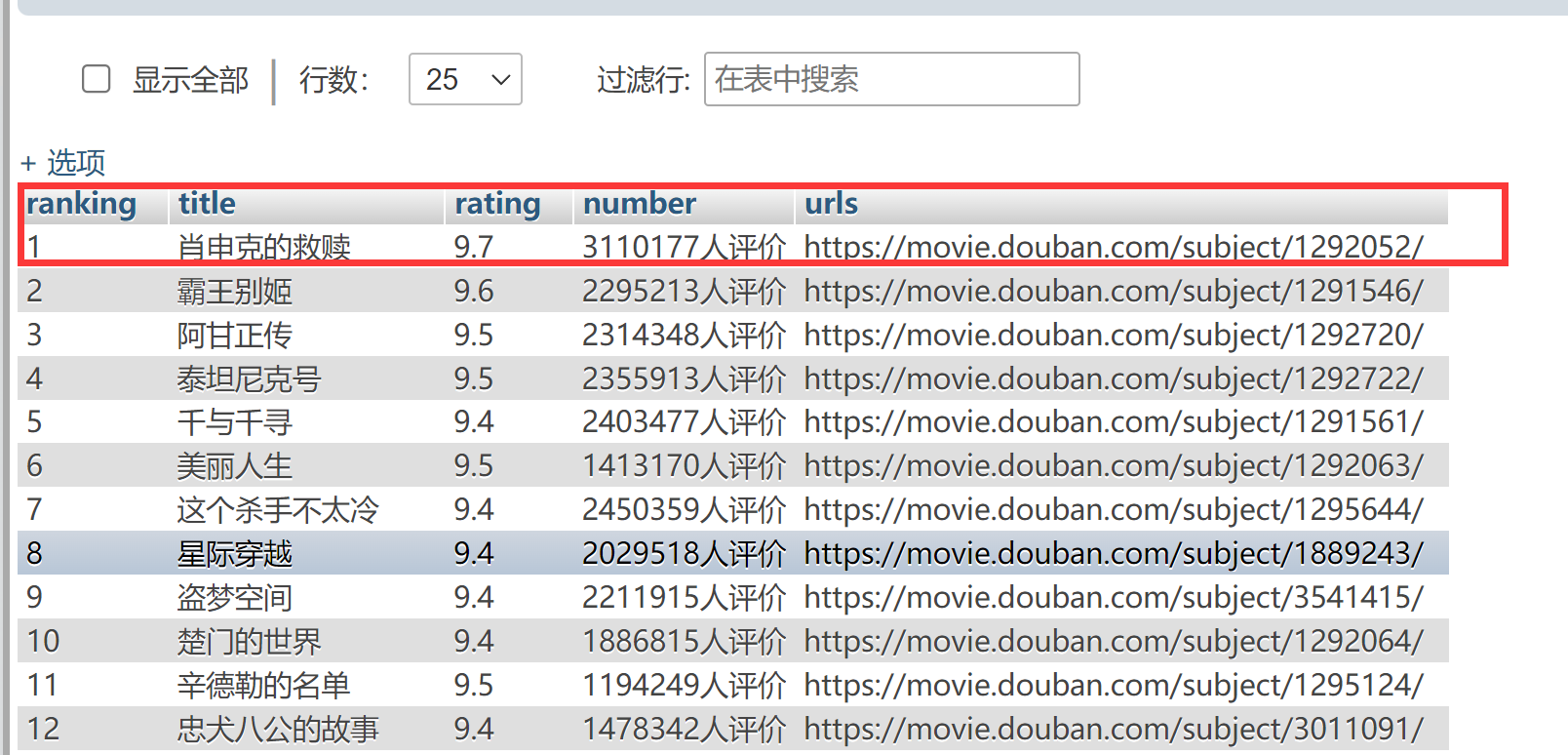
创建五个列(以下是我后期提取成功的数据)
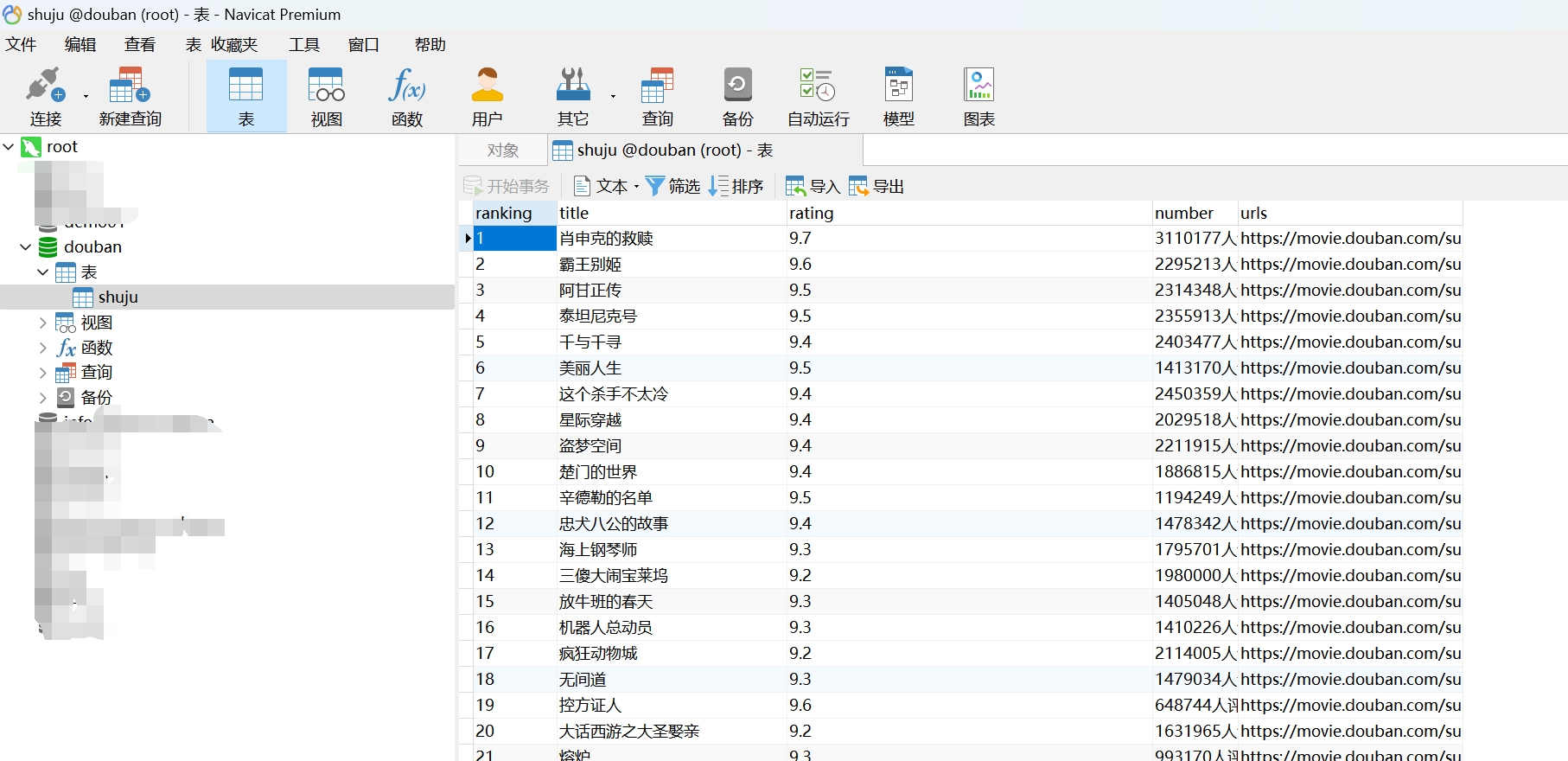
不想重新下载工具使用以上方法即可,推荐下载工具:Navicat Premium 15(我自己使用的),操作简单。
四、设置反爬虫策略
1.设置UA头
通过设置 User-Agent 模拟浏览器请求,以避免被网站识别为爬虫。

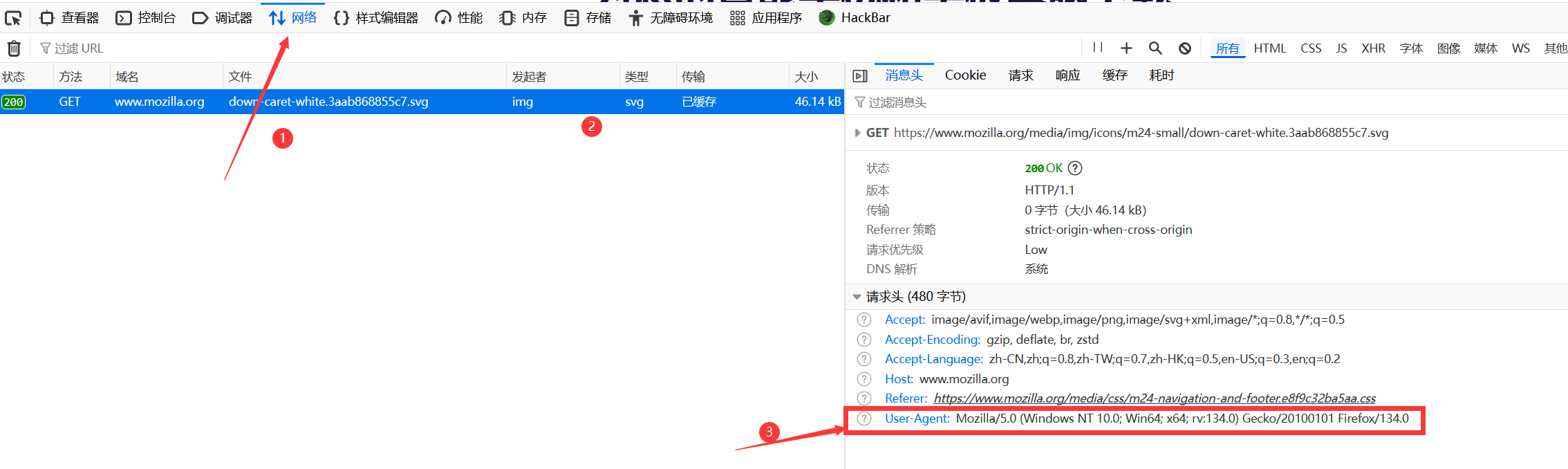
去自己的浏览器,F12打开开发者工具或者右键点击检查
复制User-Agent 的内容
2. 代理IP
使用代理IP列表 (proxy_list) 来随机选择代理进行请求。这有助于隐藏真实IP地址,减少被网站封禁的风险。
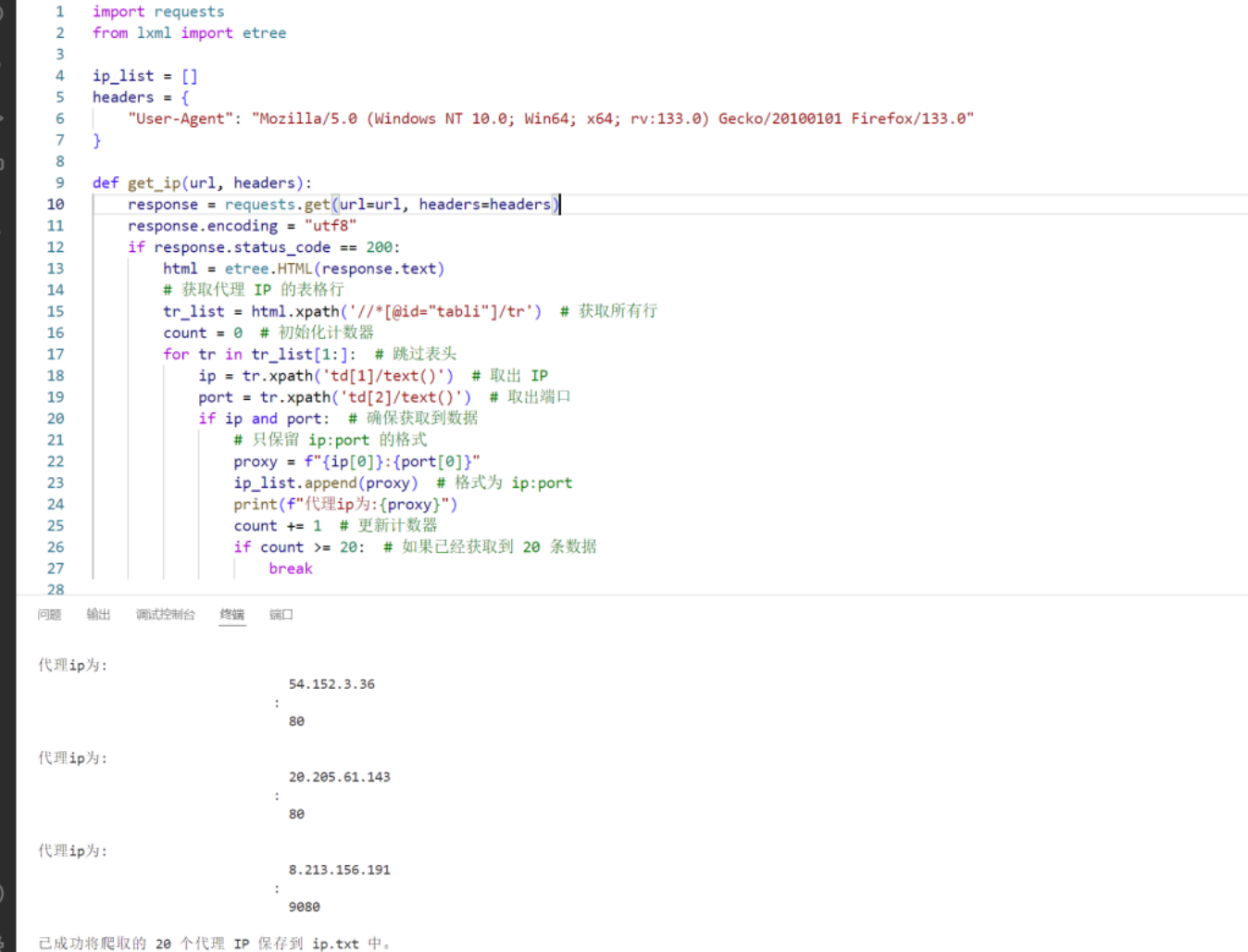
获取免费代理ip:
import requests
from lxml import etree
ip_list = []
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:133.0) Gecko/20100101 Firefox/133.0"
}
def get_ip(url, headers):
response = requests.get(url=url, headers=headers)
response.encoding = "utf8"
if response.status_code == 200:
html = etree.HTML(response.text)
# 获取代理 IP 的表格行
tr_list = html.xpath('//*[@id="tabli"]/tr') # 获取所有行
count = 0 # 初始化计数器
for tr in tr_list[1:]: # 跳过表头
ip = tr.xpath('td[1]/text()') # 取出 IP
port = tr.xpath('td[2]/text()') # 取出端口
if ip and port: # 确保获取到数据
# 只保留 ip:port 的格式
proxy = f"{ip[0]}:{port[0]}"
ip_list.append(proxy) # 格式为 ip:port
print(f"代理ip为:{proxy}")
count += 1 # 更新计数器
if count >= 50: # 如果已经获取到 50条数据
break
if __name__ == '__main__':
# 设置只抓取一页的 URL
url = "https://www.proxy-list.download/HTTP"
get_ip(url, headers)
# 将IP写入txt文件
with open("ip.txt", "w") as f:
for ip in ip_list:
f.write(ip + "\n") # 每个IP占一行,格式为 ip:port
print(f"已成功将爬取的 {len(ip_list)} 个代理 IP 保存到 ip.txt 中。")
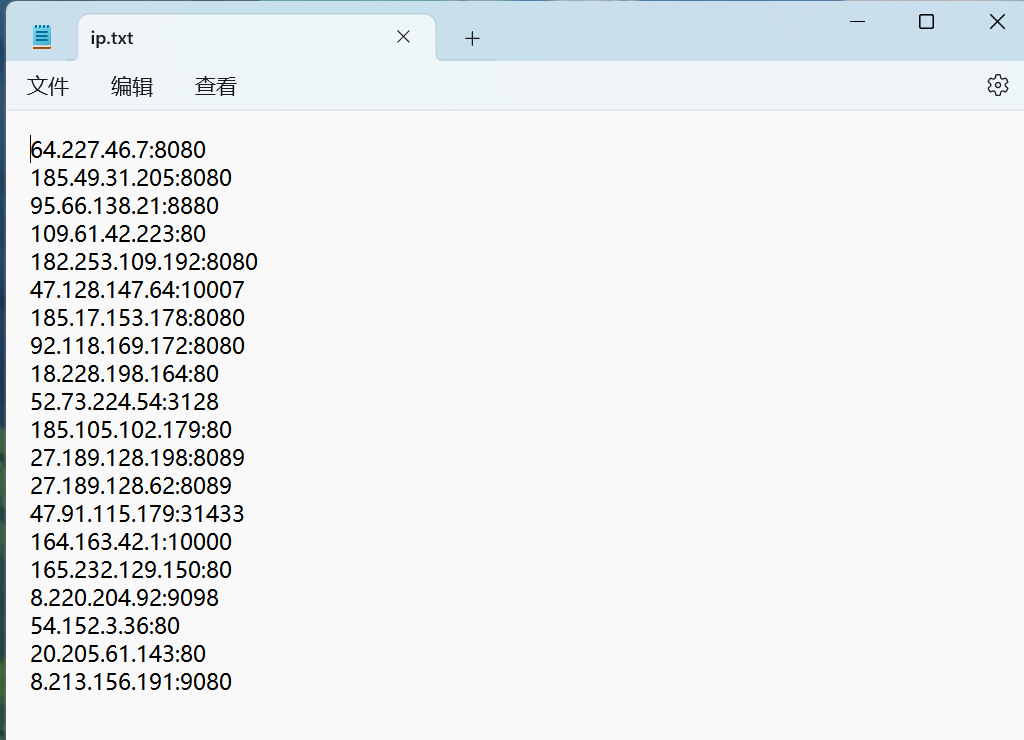
这里面提供了许多代理ip,但是我们尝试过后会发现并不是每一个都是有效的。所以我们现在所要做的就是从里面提供的ip,筛选出有效快速稳定的ip。
import requests
import random
import time
http_ip = [
'64.227.46.7:8080',
'185.49.31.205:8080',
'95.66.138.21:8880',
'109.61.42.223:80',
......
]
valid_ips = [] # 用于存储有效的IP
for i in range(10):
try:
ip_proxy = random.choice(http_ip)
proxy_ip = {
'http': ip_proxy,
'https': ip_proxy,
}
print('使用代理的IP:', proxy_ip)
response = requests.get("http://httpbin.org/ip", proxies=proxy_ip).text
print(response)
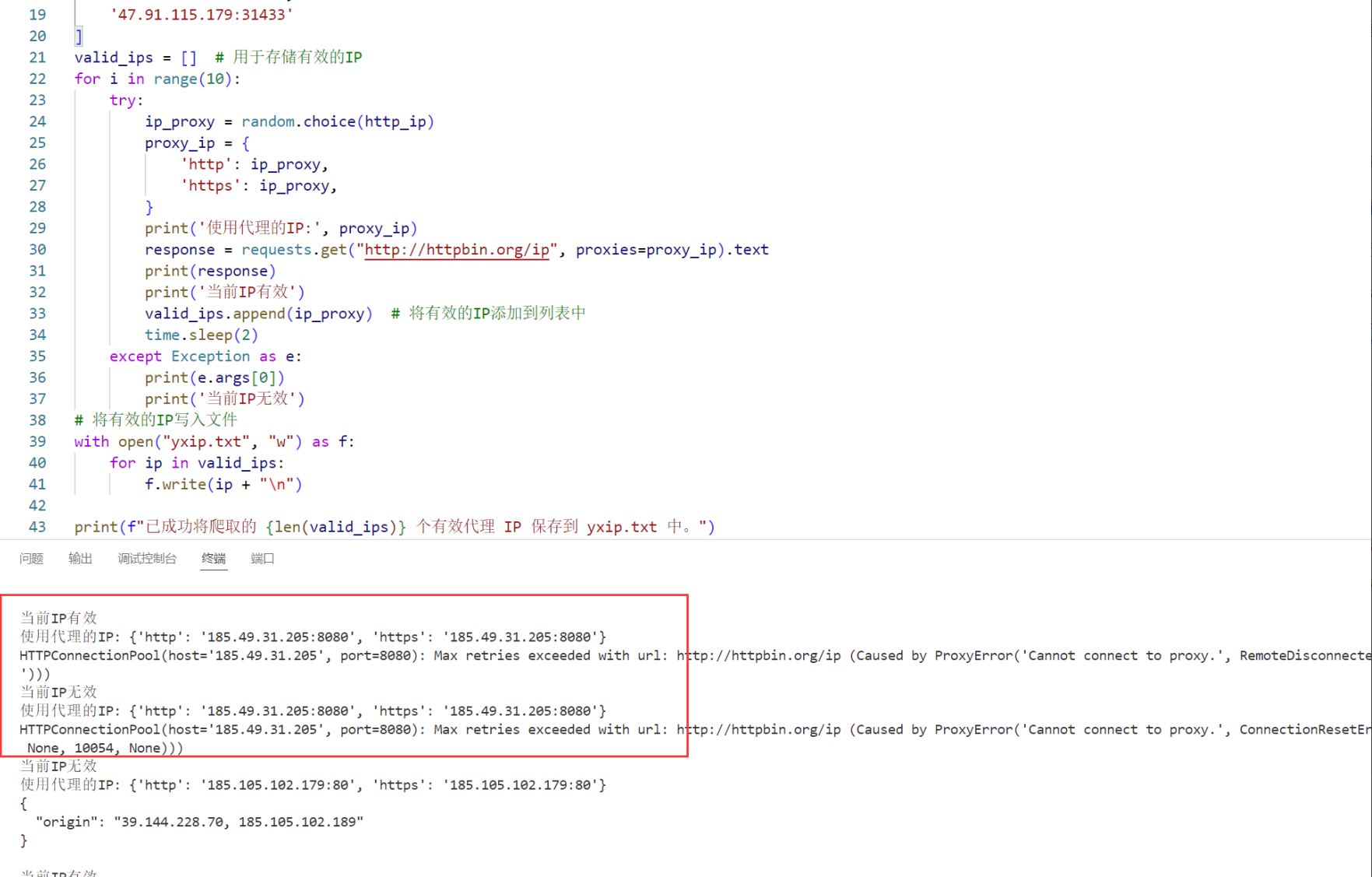
print('当前IP有效')
valid_ips.append(ip_proxy) # 将有效的IP添加到列表中
time.sleep(2)
except Exception as e:
print(e.args[0])
print('当前IP无效')
# 将有效的IP写入文件
with open("yxip.txt", "w") as f:
for ip in valid_ips:
f.write(ip + "\n")
print(f"已成功将爬取的 {len(valid_ips)} 个有效代理 IP 保存到 yxip.txt 中。")
五、完整源码
在校园网下也能正常运行,提取数据。
1.存储到数据库
import requests
from lxml import etree
import pymysql
import time
import threading
import random
# 代理IP列表
proxy_list = [
"http://185.105.102.179:80",
"http://185.49.31.205:8080",
"http://192.118.169.172:8080",
"http://185.17.153.178:8080"
]
# 数据库连接
def create_db_connection():
return pymysql.connect(
host='localhost',
user='root',
password='123456',
db='douban',
)
def insert_movie_data(ranking, title, rating, number, urls):
conn = create_db_connection()
try:
with conn.cursor() as cursor:
query = "INSERT INTO shuju (ranking, title, rating, number, urls) VALUES (%s, %s, %s, %s, %s)"
cursor.execute(query, (ranking, title, rating, number, urls))
conn.commit()
finally:
conn.close()
def scrape_page(page):
url = f"https://movie.douban.com/top250?start={page * 25}&filter="
# 请求头模拟浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:133.0) Gecko/20100101 Firefox/133.0'
}
for attempt in range(4): # 最多重试4次
proxy = random.choice(proxy_list) # 随机选择代理
try:
response = requests.get(url, headers=headers, proxies={"http": proxy}, timeout=10)
response.raise_for_status() # 检查请求是否成功
html_str = response.content.decode()
# 使用lxml解析HTML
tree = etree.HTML(html_str)
li_list = tree.xpath('//*[@id="content"]/div/div[1]/ol/li')
for li in li_list:
try:
ranking = li.xpath("./div/div[1]/em/text()")[0]
title = li.xpath("./div/div[2]/div[1]/a/span[1]/text()")[0]
rating = li.xpath("./div/div[2]/div[2]/div/span[2]/text()")[0]
number = li.xpath(".//div/div[2]/div[2]/div/span[4]/text()")[0]
urls = li.xpath("./div/div[2]/div[1]/a/@href")[0]
insert_movie_data(ranking, title, rating, number, urls)
print(f"排名: {ranking}, 电影: {title}, 评分: {rating}, 评价人数: {number}, 影片主页链接: {urls}")
except IndexError as e:
print(f"数据提取错误: {e},可能是由于页面结构变化。")
break # 如果请求成功,退出重试循环
except requests.exceptions.RequestException as e:
print(f"请求错误: {e},使用代理: {proxy}")
time.sleep(5) # 等待5秒再重试
if __name__ == "__main__":
num_pages = int(input("请输入要爬取的页数: "))
# 记录开始时间
start_time = time.time()
threads = []
# 创建并启动线程
for page in range(num_pages):
thread = threading.Thread(target=scrape_page, args=(page,))
threads.append(thread)
thread.start()
time.sleep(1) # 每个线程启动之间稍微延迟一下,避免过于频繁
# 等待所有线程完成
for thread in threads:
thread.join()
# 记录结束时间
end_time = time.time()
# 计算耗时
duration = end_time - start_time
print(f"所有数据已成功爬取并保存到数据库,耗时: {duration:.2f} 秒")
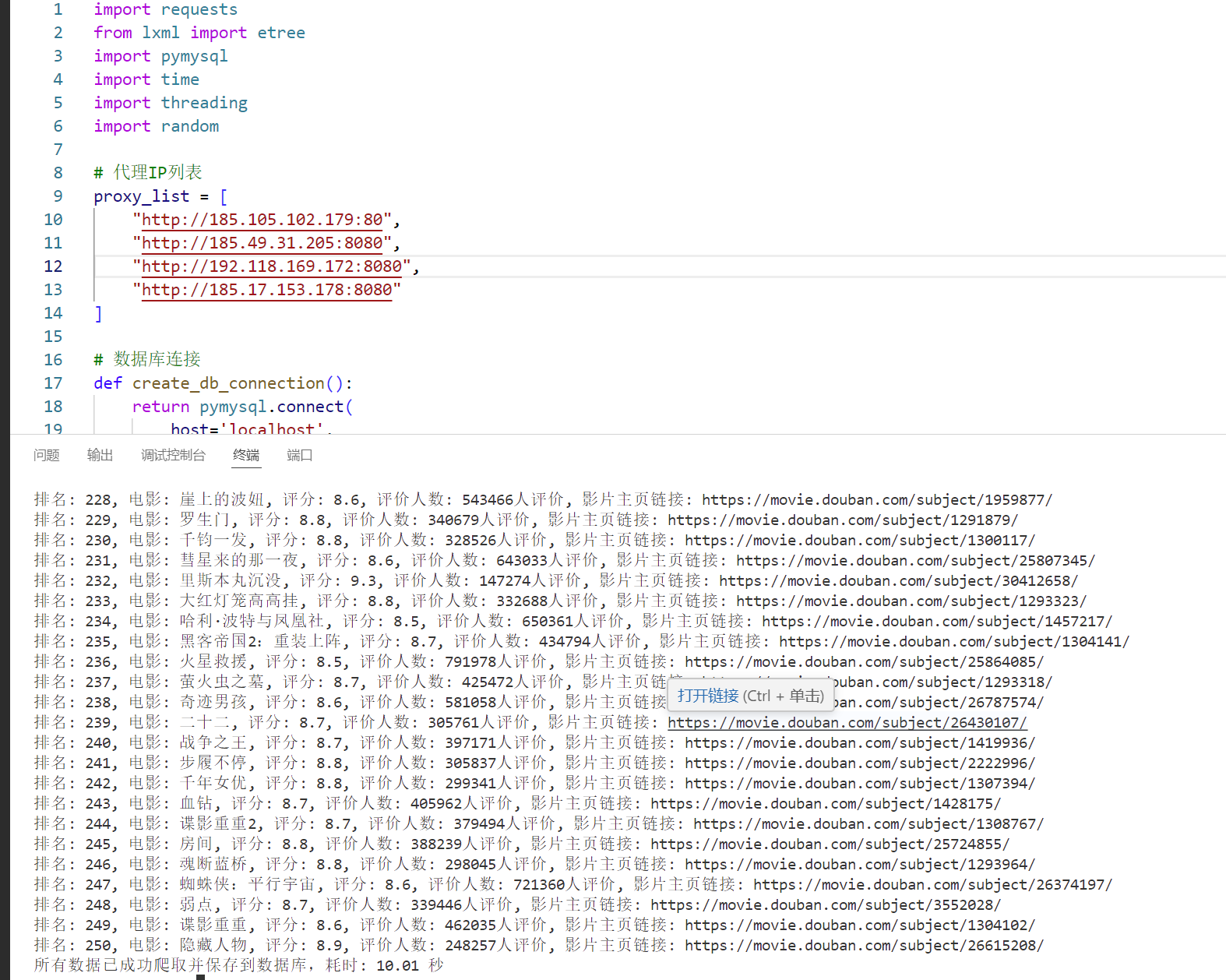
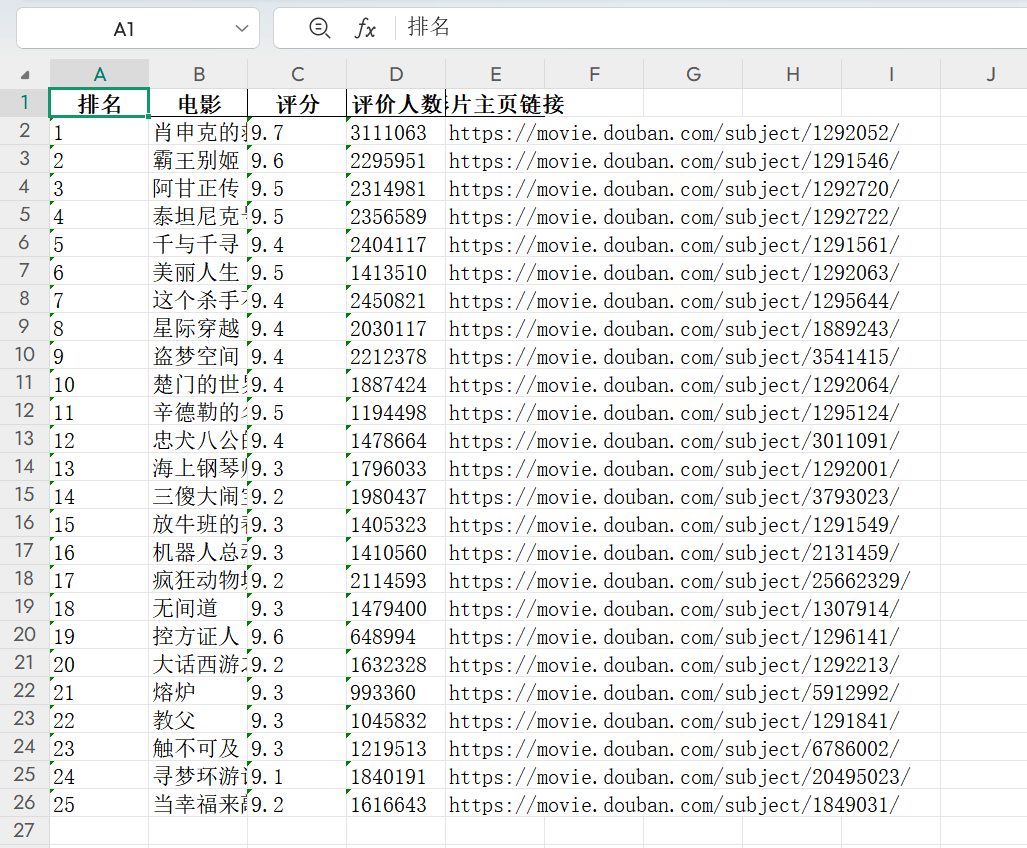
已成功将豆瓣电影 Top 250 的数据提取并保存至数据库 douban。
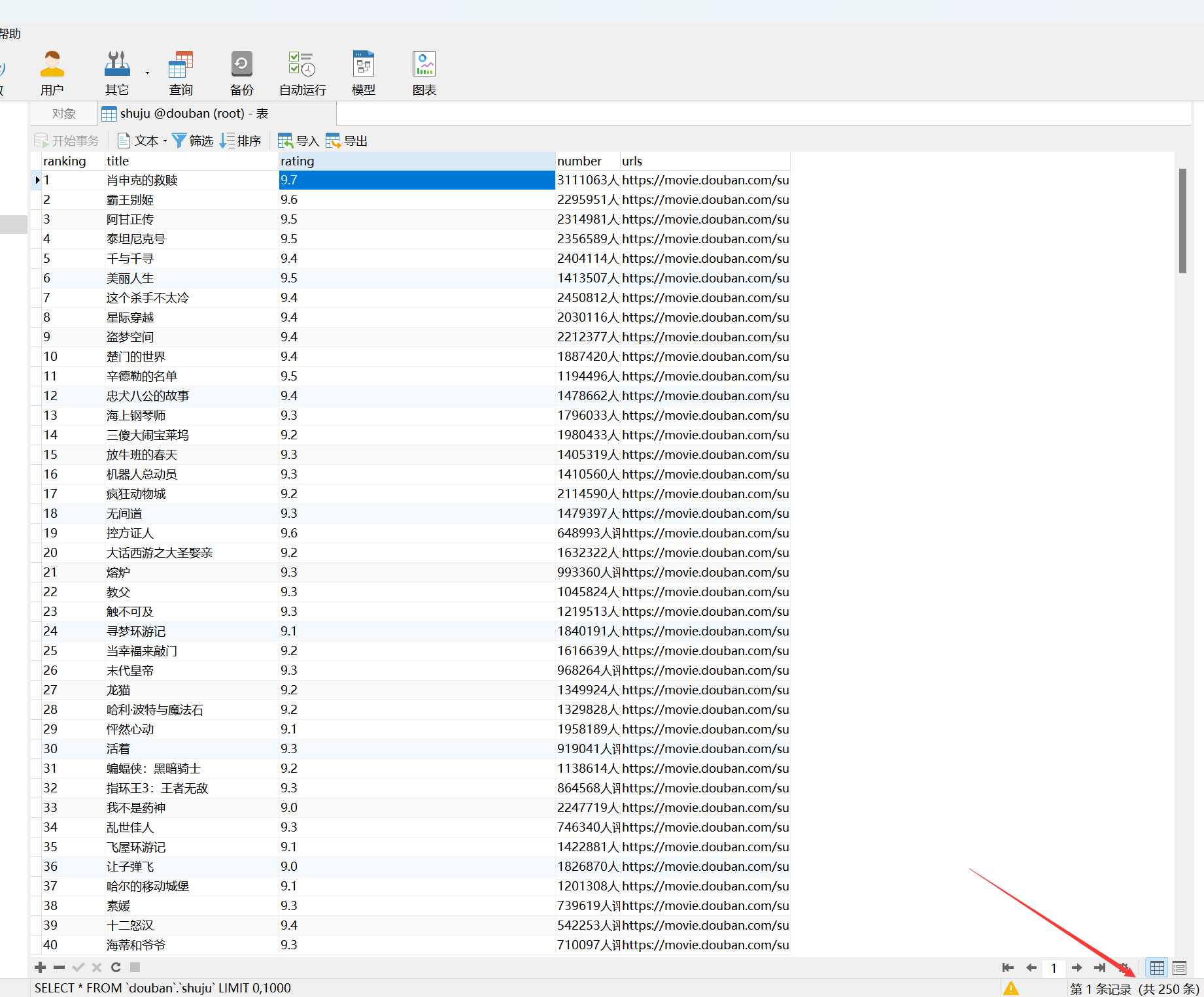
以上代码运行以后报错,看一下数据库是否启动,数据库、表、列是否创建错误。
2.存储到JSON文件或Excel表格
如果觉得将数据存储到数据库比较繁琐,也可以选择将数据存储到JSON文件或Excel表格中。
import requests
from lxml import etree
import time
import threading
import random
import pandas as pd
import json
# 代理IP列表
proxy_list = [
"http://185.105.102.179:80",
"http://185.49.31.205:8080",
"http://192.118.169.172:8080",
"http://185.17.153.178:8080"
]
def scrape_page(page, movie_data):
url = f"https://movie.douban.com/top250?start={page * 25}&filter="
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:133.0) Gecko/20100101 Firefox/133.0'
}
for attempt in range(4):
proxy = random.choice(proxy_list)
try:
response = requests.get(url, headers=headers, proxies={"http": proxy}, timeout=10)
response.raise_for_status()
html_str = response.content.decode()
tree = etree.HTML(html_str)
li_list = tree.xpath('//*[@id="content"]/div/div[1]/ol/li')
for li in li_list:
try:
ranking = li.xpath("./div/div[1]/em/text()")[0]
title = li.xpath("./div/div[2]/div[1]/a/span[1]/text()")[0]
rating = li.xpath("./div/div[2]/div[2]/div/span[2]/text()")[0]
number = li.xpath(".//div/div[2]/div[2]/div/span[4]/text()")[0].strip('人评价')
urls = li.xpath("./div/div[2]/div[1]/a/@href")[0]
movie_data.append({
'排名': ranking,
'电影': title,
'评分': rating,
'评价人数': number,
'影片主页链接': urls
})
except IndexError as e:
print(f"数据提取错误: {e},可能是由于页面结构变化。")
break
except requests.exceptions.RequestException as e:
print(f"请求错误: {e},使用代理: {proxy}")
time.sleep(5)
if __name__ == "__main__":
num_pages = int(input("请输入要爬取的页数: "))
movie_data = []
start_time = time.time()
threads = []
for page in range(num_pages):
thread = threading.Thread(target=scrape_page, args=(page, movie_data))
threads.append(thread)
thread.start()
time.sleep(1)
for thread in threads:
thread.join()
end_time = time.time()
duration = end_time - start_time
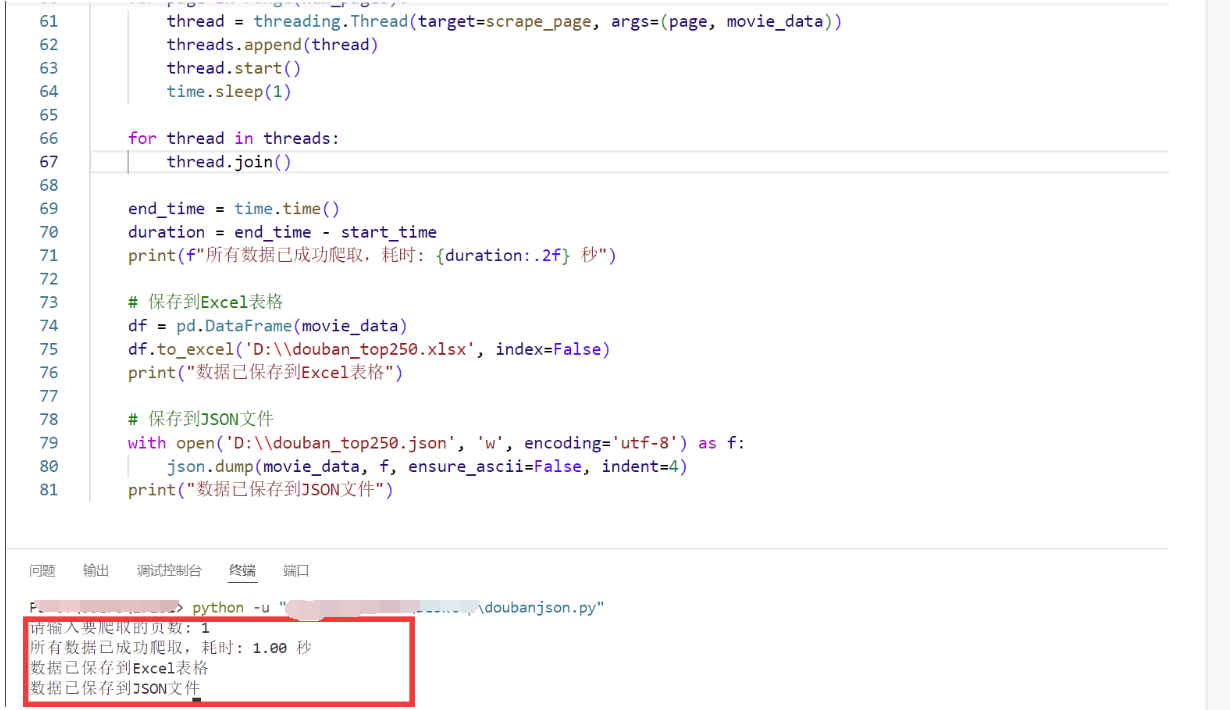
print(f"所有数据已成功爬取,耗时: {duration:.2f} 秒")
# 保存到Excel表格
df = pd.DataFrame(movie_data)
df.to_excel('D:\\douban_top250.xlsx', index=False)
print("数据已保存到Excel表格")
# 保存到JSON文件
with open('D:\\douban_top250.json', 'w', encoding='utf-8') as f:
json.dump(movie_data, f, ensure_ascii=False, indent=4)
print("数据已保存到JSON文件")



















 6684
6684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









