






1. 电影短评爬取
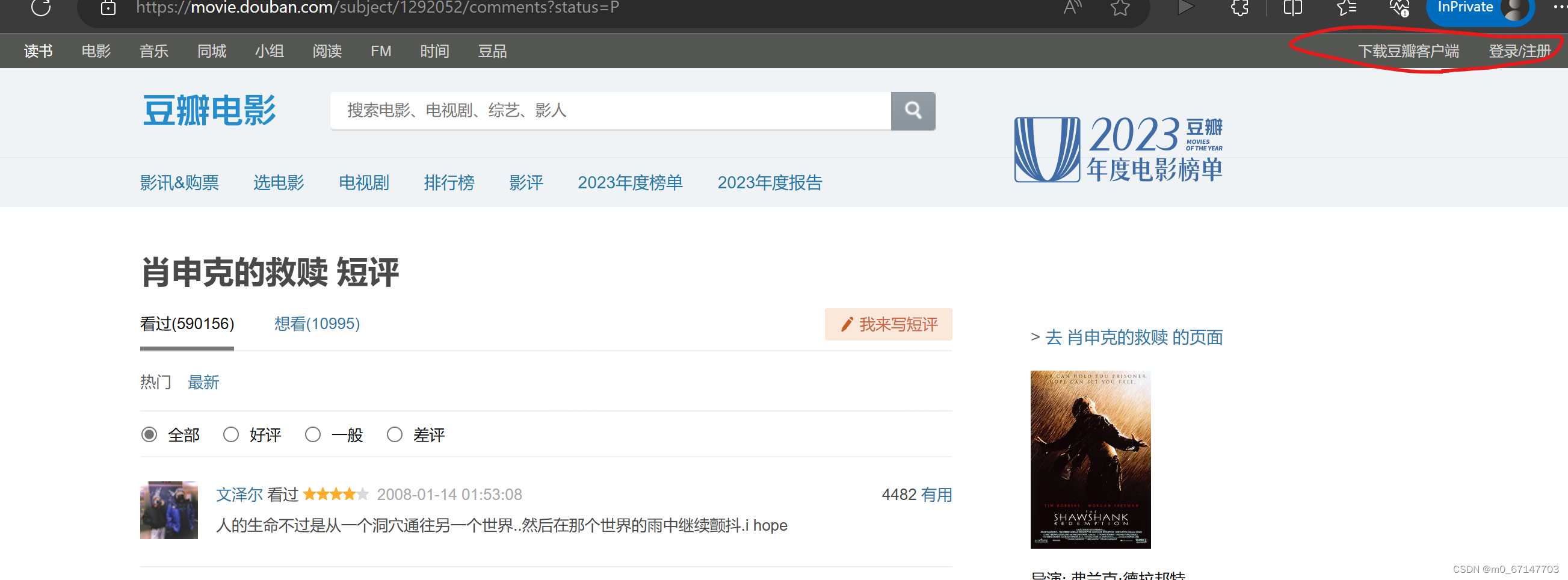
经过探索可以发现,电影短评页面的url具有规律,只需要知道电影的id就可以批量生成,且不需要进行豆瓣登录就可以查看。但豆瓣具有封ip机制,爬取的时候要尽量小心。
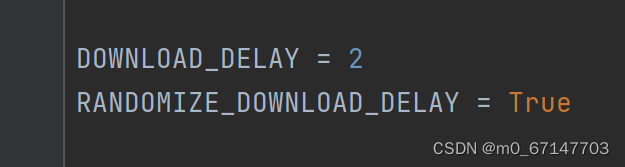
首先在settings中添加download_delay防止过快的爬取,添加randomize_donwload_delay随机化爬取延迟。
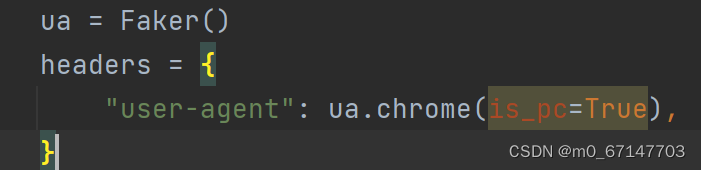
使用Faker()随机生成ua。此时存在一个问题,Faker生成的随机ua也包含移动端,html与pc端大相径庭,且会缺少部分数据,难以进行爬取。
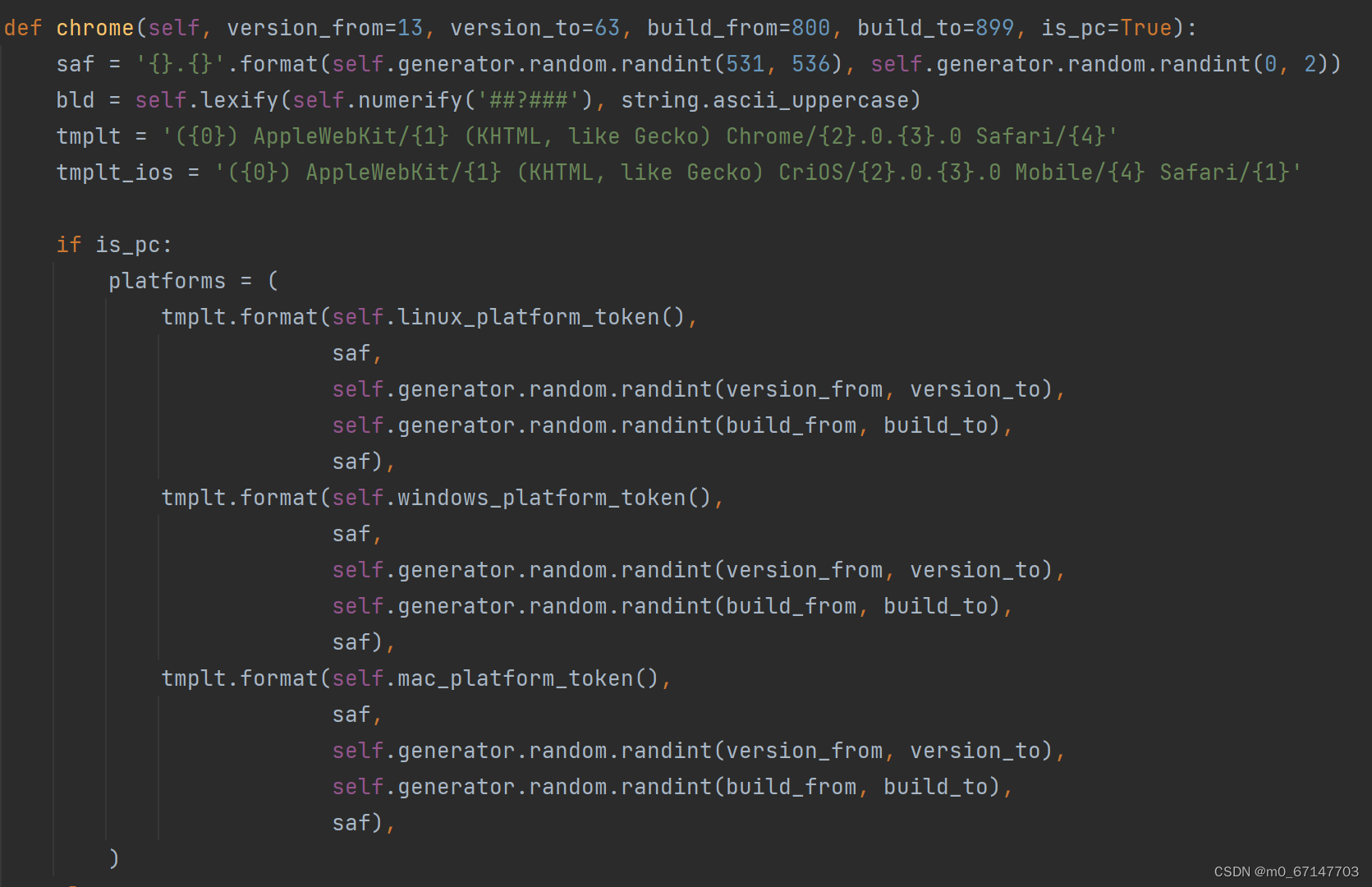
通过搜集资料,我手动修改了lib中chrome()的源代码,添加了一个is_pc参数来确保生成的ua都是pc端的。

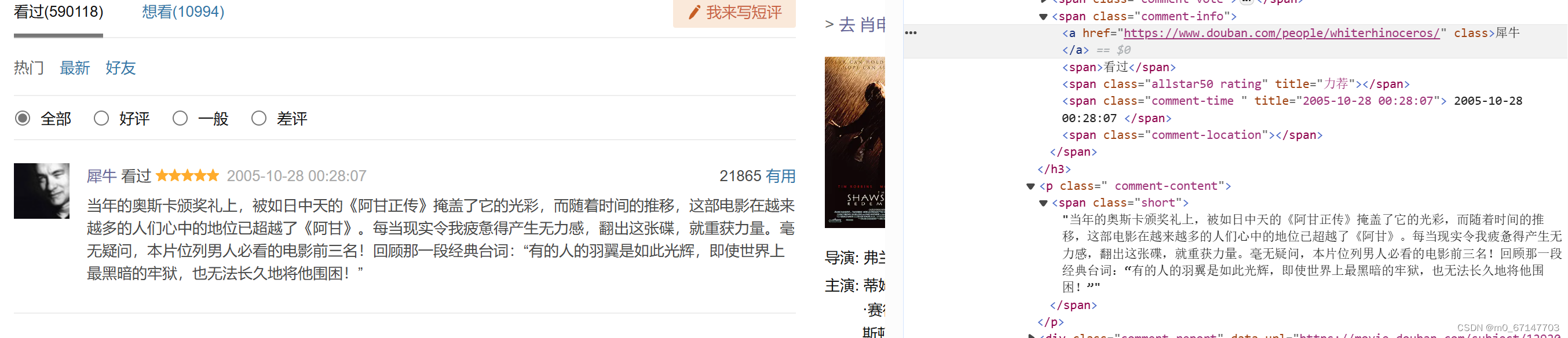
对于每条电影短评,需要爬取短评的文本内容和对应的用户主页的url,从而合成用户“广播”页面的url。

这里使用xpath进行数据抽取。可以观察到,电影名“肖申克的救赎”就在id为“content”的div节点中;每一个短评都在class为comment-item的节点中,xpath选取所有短评;分析短评的源代码可以发现,用户主页的url存在“comment-info”的a节点中,评论存在class为“short”的span节点中。
2. 用户“广播”数据爬取
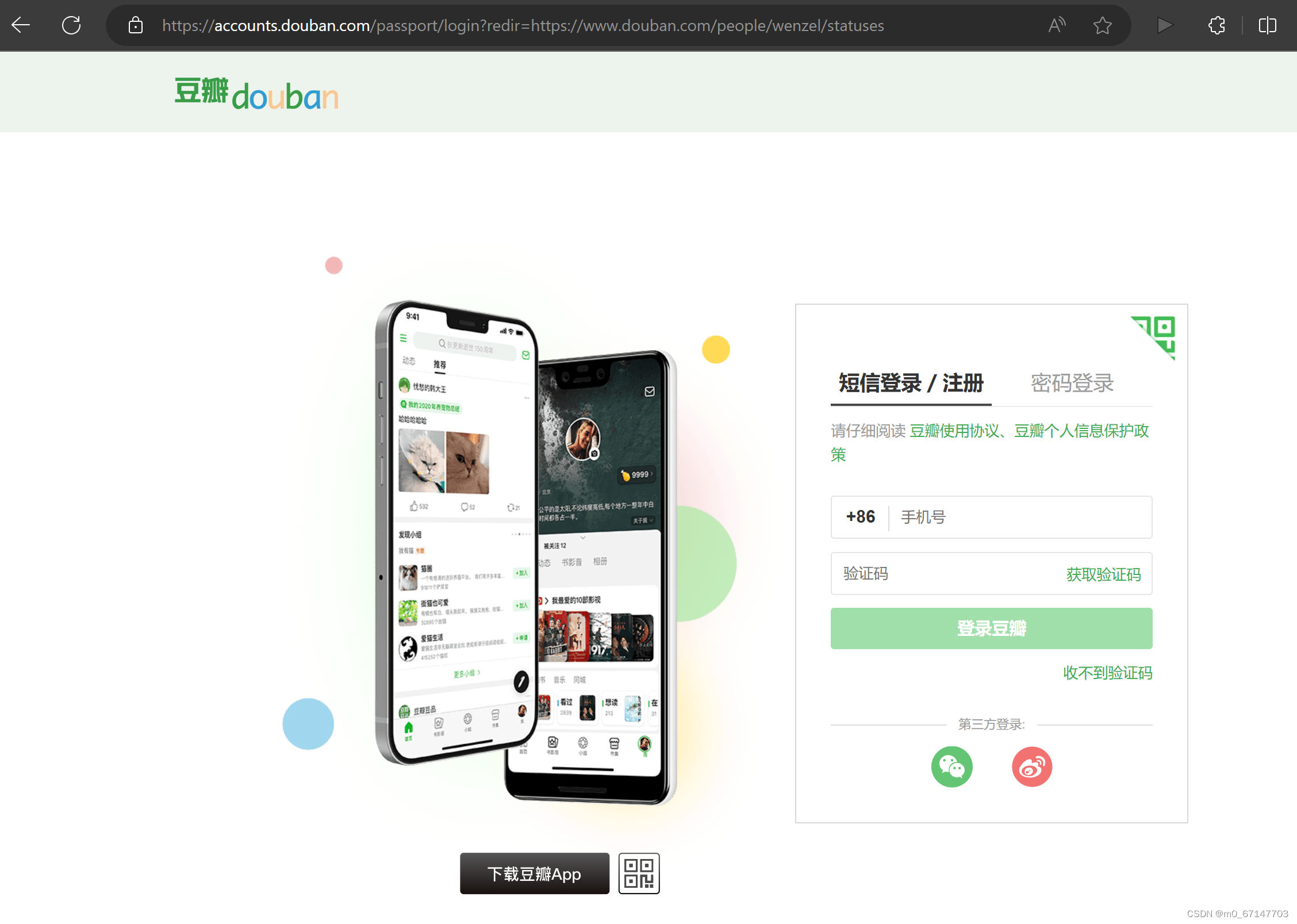
获取短评用户的主页url后,我们可以增加"“/statuses”后缀,得到其“广播”的url,但未登录的情况下进入该页面会显示需要登录。
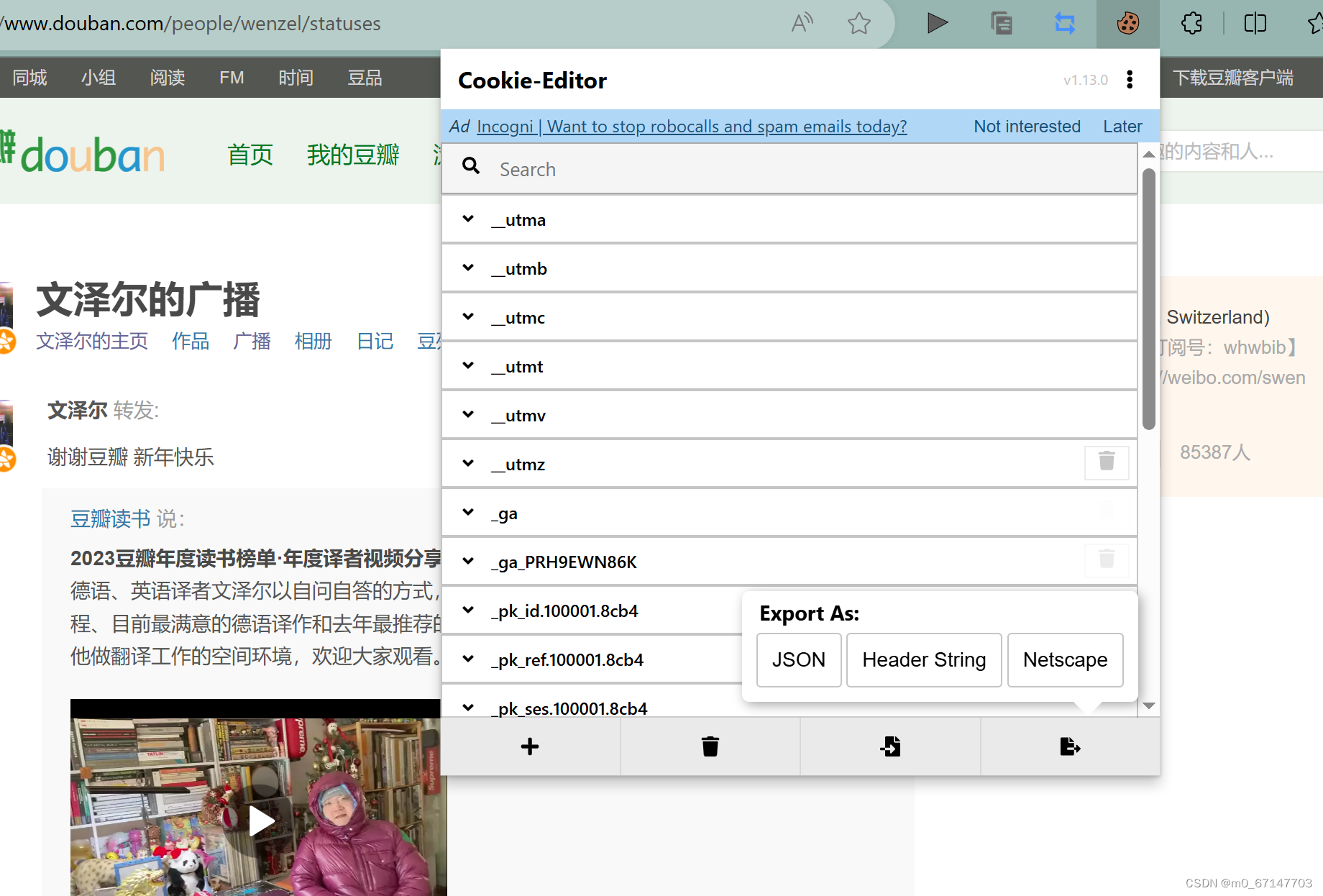
由于需要爬取的数据量不大,我选择手动登录后导出cookie,给爬虫使用。这里使用cookie-editor插件自动获取cookie,使用header string格式导出。
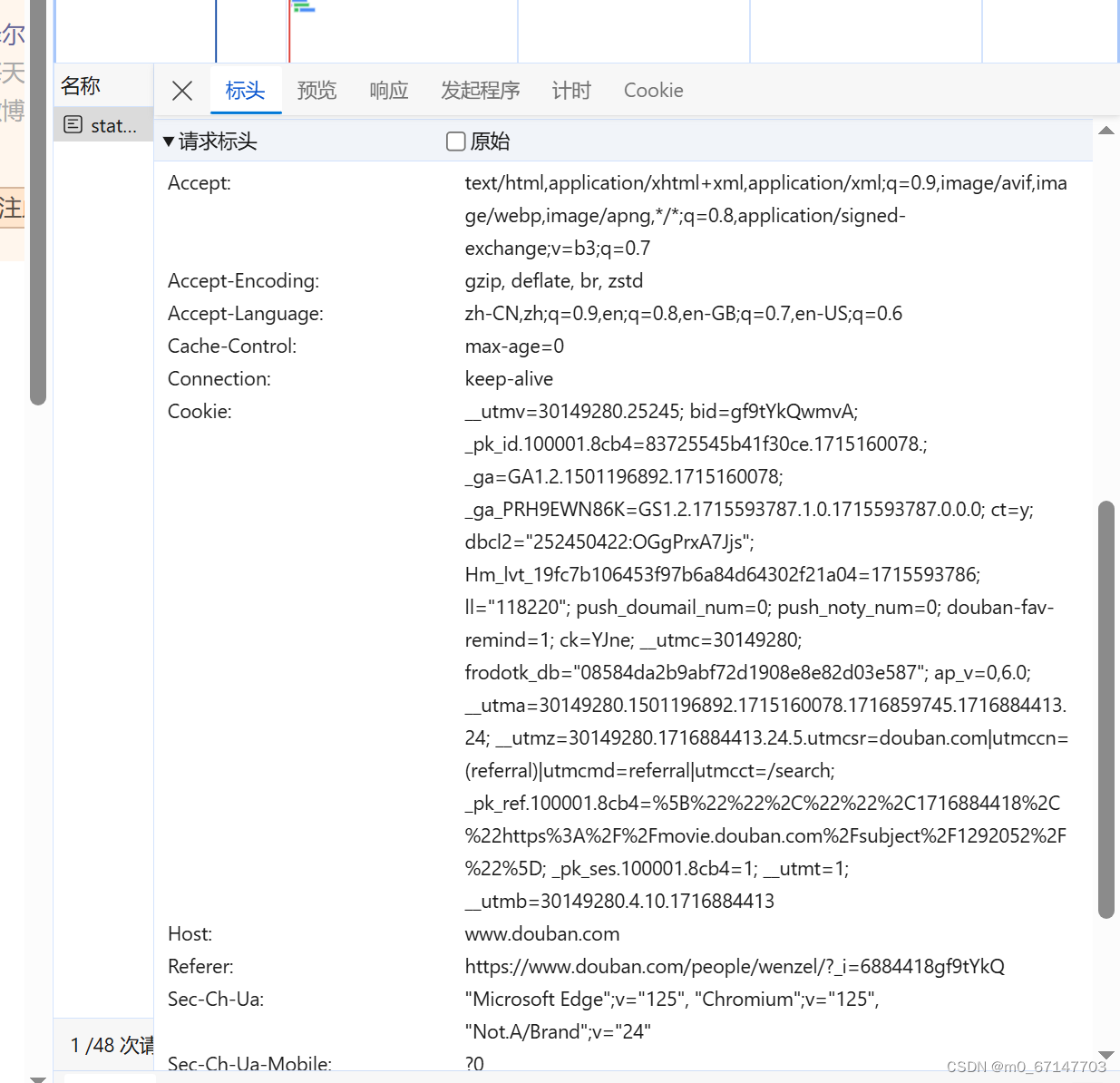

此时如果用随机ua爬取可能会被封号,因此我完整复制了本地浏览器ua的其他参数,构成了该爬虫使用的ua。
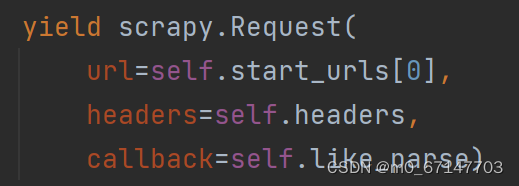

在settings中设置cookies_enabled为false,即可在request中使用该hearders。
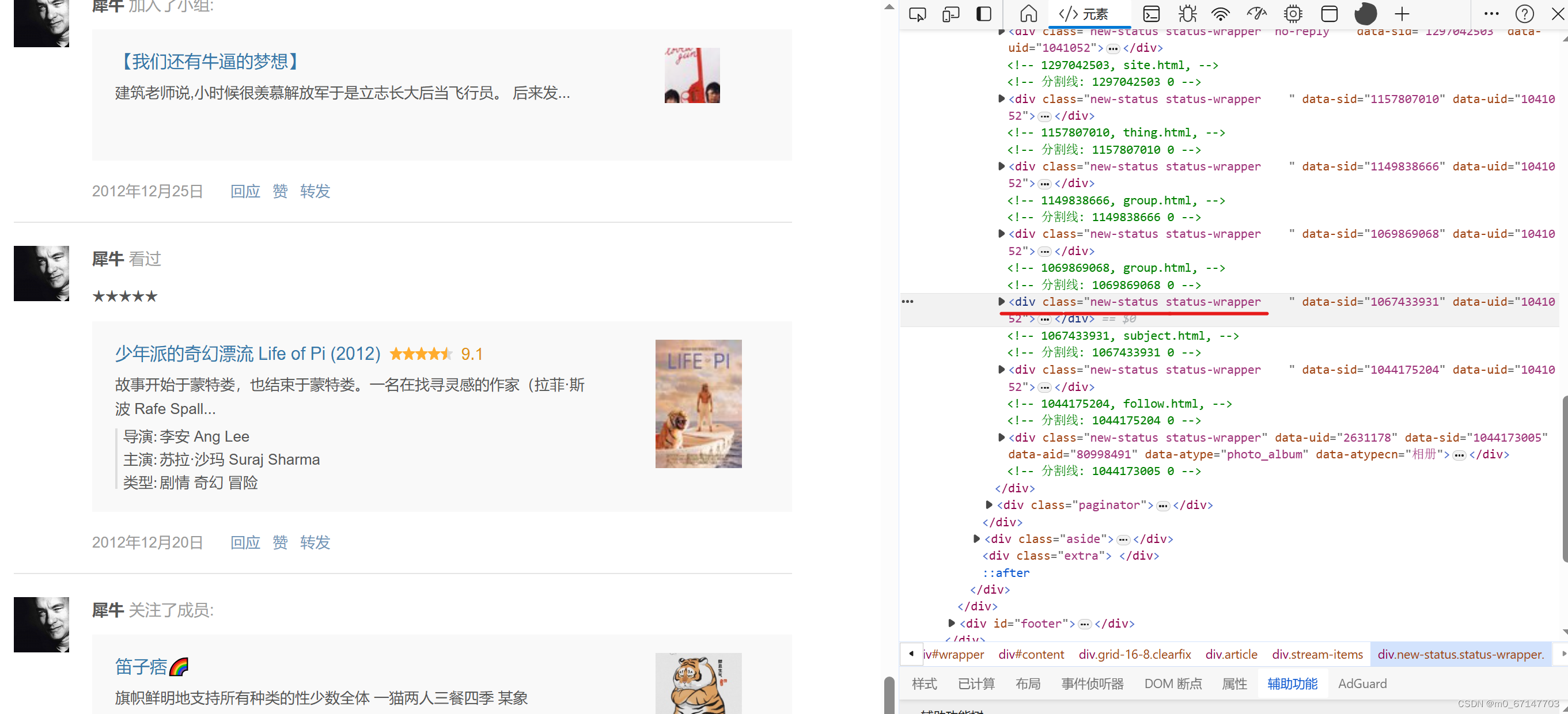
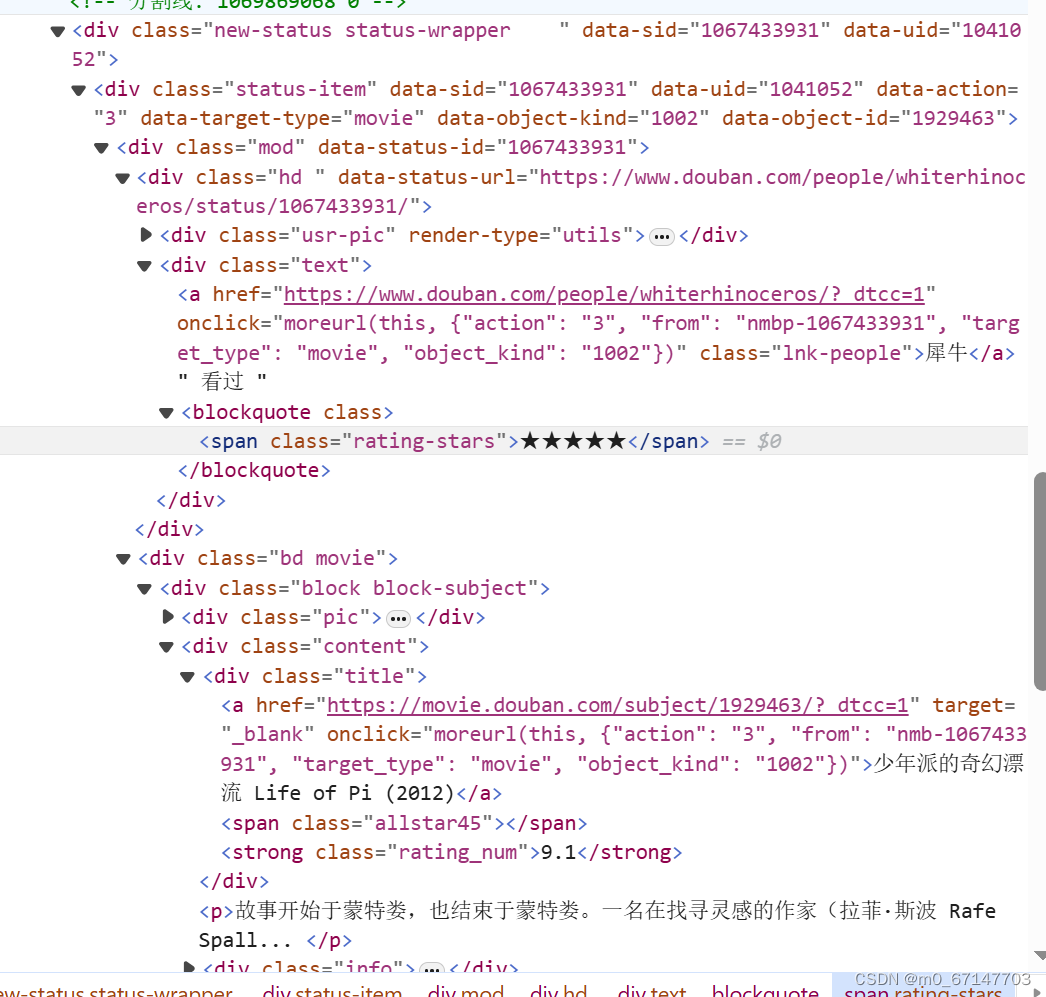
在用户广播页面,由于我需要爬取到用户喜爱的电影,因此筛选出标签为“看过”且用户对其的评分在四分及以上的电影,并爬取电影的名称,例如这个“少年派的奇幻漂流”。
观察每条“广播”的源代码可以发现,它存在“new-status stutus-wrapper”的div节点中,使用xpath对上述提到的条件进行筛选和爬取:titles = response.xpath("//div[contains(@class, 'new-status status-wrapper') and .//div[contains(@class, 'text') and contains(., '看过')] and .//span[contains(@class, 'rating-stars') and (contains(text(), '★★★★☆') or contains(text(), '★★★★★'))]]//div[@class='title']/a/text()")

















 7840
7840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









