







分割字符split
在java中,我们经常使用split方法来分割字符,分割之后会获得一个数组,循环该数组就会得到每个元素。如下面的实例程序:
package stringTokenizer;
public class Test {
public static void main(String[] args) {
String s = new String("The Java platform is the ideal platform for network computing");
String split_s[]=s.split("\\s");
for(int i=0;i<split_s.length;i++){
System.out.println(split_s[i]);
}
}
}
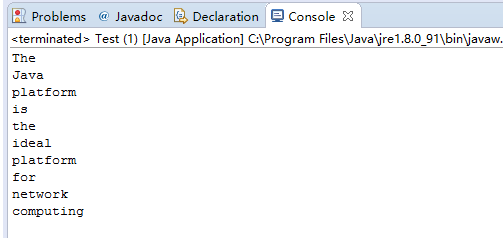
所得到的结果是:
StringTokenizer介绍
但随着数据量的增大,split使用正则表达式,其效率会降低。StringTokenizer是一款类似split的字符分解器。StringTokenizer在截取字符串中效率最高,不论数据量大小。
StringTokenizer核心方法
public boolean hasMoreTokens()
public String nextToken()
public String nextToken(String delim)
public int countTokens()使用样例
package stringTokenizer;
import java.util.StringTokenizer;
public class Test {
public static void main(String[] args) {
String s = new String("The Java platform is the ideal platform for network computing");
StringTokenizer st = new StringTokenizer(s);
System.out.println( "Token Total: " + st.countTokens() );
while( st.hasMoreElements() ){
System.out.println( st.nextToken());
}
String s1 = new String("The=Java=platform=is=the=ideal=platform=for=network=computing");
StringTokenizer st1 = new StringTokenizer(s1,"=",false);
System.out.println("Token Total: " + st1.countTokens());
while(st1.hasMoreElements() ){
System.out.println( st1.nextToken() );
}
}
}
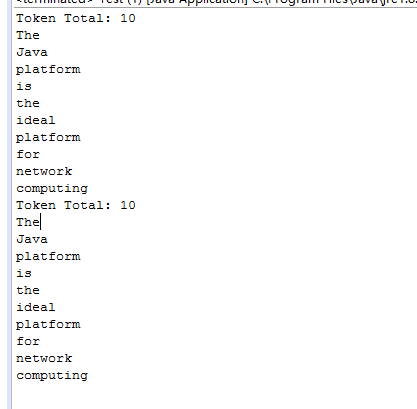
两个所得到的结果是一样的。















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









