







Python学习从0开始——Kaggle时间序列001
一、具有时间序列的线性回归
1.时间序列
预测的基本对象是时间序列,它是一组随时间记录的观察结果。在预报应用中,通常以固定的频率记录观测结果,如每日或每月。
2.时间序列线性回归
我们将使用线性回归算法来构建预测模型。线性回归在实践中得到了广泛的应用,能够很自然地适应复杂的预测任务。
线性回归算法学习如何从其输入特征中进行加权和。对于两个功能,我们将拥有:
target = weight_1 * feature_1 + weight_2 * feature_2 + bias
在训练过程中,回归算法学习最适合目标的参数weight_1, weight_2和bias的值。(这种算法通常被称为普通最小二乘,因为它选择的值使目标和预测之间的平方误差最小。)权重也被称为回归系数偏差也被称为截距因为它告诉你这个函数的图形与y轴相交的位置。
时间序列有两种独特的特征:时间步特征和滞后特征(time-step features and lag features)。
1.时间步特征
时间步特征是我们可以直接从时间指数中推导出来的特征。最基本的时间步特征是时间哑变量(time dummy),它从开始到结束计数序列中的时间步长。
具体来说,时间哑变量通常被编码为一系列二进制(0或1)变量,每个变量代表时间序列中的一个特定时间段或时间点。例如,如果有一个时间序列数据,其中包含了每个月的数据,那么可以创建一个包含12个时间哑变量的集合,每个变量对应于一年中的一个月。对于给定的数据点,如果它属于某个特定的月份,那么相应的时间哑变量就会置为1,而其他时间哑变量则会置0。
时间哑变量可以帮助模型识别出时间序列数据中的季节性模式、趋势或其他与时间相关的效应。它们提供了一种简单而有效的方法来捕获时间对目标变量的潜在影响,尤其是在没有明确的时间序列预测模型(如ARIMA或LSTM)可用的情况下。
import numpy as np
df['Time'] = np.arange(len(df.index))
df.head()
带入时间哑变量的线性回归得到模型:
target = weight * time + bias
然后,时间哑变量让我们将曲线拟合到时间图中的时间序列中,其中时间形成x轴:
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use("seaborn-whitegrid")
plt.rc(
"figure",
autolayout=True,
figsize=(11, 4),
titlesize=18,
titleweight='bold',
)
plt.rc(
"axes",
labelweight="bold",
labelsize="large",
titleweight="bold",
titlesize=16,
titlepad=10,
)
%config InlineBackend.figure_format = 'retina'
fig, ax = plt.subplots()
ax.plot('Time', 'Hardcover', data=df, color='0.75')
ax = sns.regplot(x='Time', y='Hardcover', data=df, ci=None, scatter_kws=dict(color='0.25'))
ax.set_title('Time Plot of Hardcover Sales');
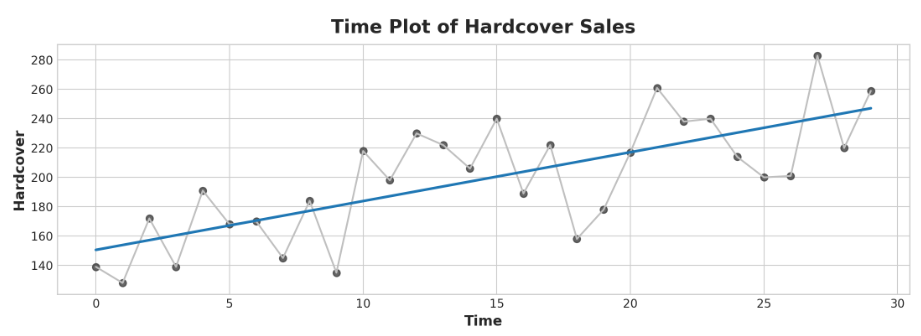
时间步长特性允许对时间依赖性进行建模。如果一个序列的值可以从它们出现的时间预测出来,那么这个序列就是时间相关的。在精装销售系列中,我们可以预测当月晚些时候的销量通常高于当月早些时候的销量。
2.滞后特征
为了制造滞后特征,我们移动目标序列的观测值,使它们看起来发生在时间的后期。这里我们创建了一个1步滞后特性,但也可以多步移动。
df['Lag_1'] = df['Hardcover'].shift(1)
df = df.reindex(columns=['Hardcover', 'Lag_1'])
df.head()
带滞后特征的线性回归得到模型:
target = weight * lag + bias
因此,滞后特征使我们能够将曲线拟合到滞后图中,其中一系列中的每个观测值都与前一个观测值相对应。
fig, ax = plt.subplots()
ax = sns.regplot(x='Lag_1', y='Hardcover', data=df, ci=None, scatter_kws=dict(color='0.25'))
ax.set_aspect('equal')
ax.set_title('Lag Plot of Hardcover Sales');
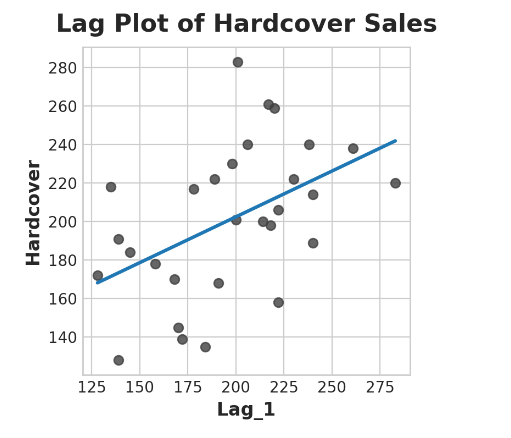
你可以从滞后图中看到,一天的销量(精装版)与前一天的销量(Lag_1)是相关的。当你看到这样的关系时,你就会知道延迟特性是有用的。
更一般地说,滞后特性使您可以对序列依赖性进行建模。当一个观测值可以从以前的观测值预测时,时间序列具有序列相关性。在精装书销售中,我们可以预测,一天的高销量通常意味着第二天的高销量。
将机器学习算法应用于时间序列问题很大程度上是带有时间指数和滞后的特征工程。在大多数情况下,我们使用线性回归是为了简单,但无论你选择哪种算法来预测任务,这些特征都是有用的。
二、趋势
1.介绍
时间序列的趋势分量表示该序列均值的持续、长期变化。趋势是一个序列中移动最慢的部分,它代表了最重要的时间尺度。在产品销售的时间序列中,随着越来越多的人逐年了解该产品,市场扩张可能会产生增长趋势。
我们将关注均值的趋势,更一般地说,序列中任何持续和缓慢的变化都可以构成趋势——例如,时间序列通常在其变化中具有趋势。
2.移动平均图
为了了解时间序列可能具有什么样的趋势,我们可以使用移动平均图。为了计算时间序列的移动平均值,我们计算一定宽度的滑动窗口内值的平均值。图上的每个点表示落在窗口两侧的序列中所有值的平均值。这样做的目的是消除短期波动,只留下长期变化。
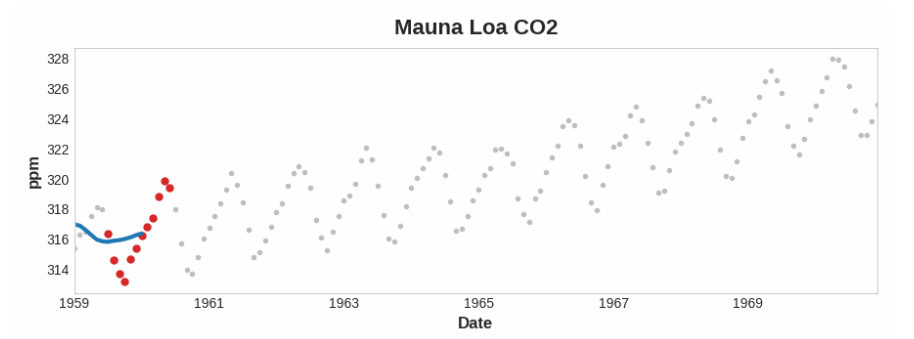
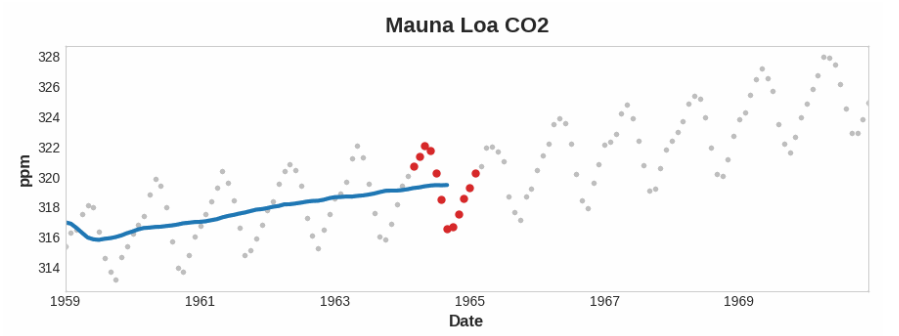
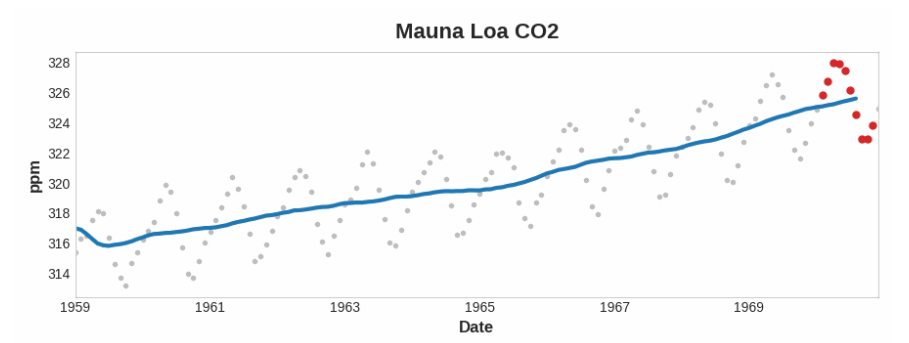
注意上面的莫纳罗亚火山系列是如何年复一年地重复上下运动的——这是一种短期的季节性变化。要使一个变化成为趋势的一部分,它应该比任何季节变化发生的时间更长。因此,为了使趋势可视化,我们取的平均值比系列中任何季节的平均值都要长。对于莫纳罗亚(Mauna Loa)系列,我们选择了12码的窗口,以便在每年的季节内平滑。
3.设计趋向
一旦我们确定了趋势的形状,我们就可以尝试使用时间步长特征对其建模。我们已经看到如何使用时间虚拟本身来模拟线性趋势:
target = a * time + b
我们可以通过时间哑变量的变换来拟合许多其他类型的趋势。如果趋势是二次曲线(抛物线),我们只需要将时间dummy的平方添加到特征集中,得到:
target = a * time ** 2 + b * time + c
线性回归将学习系数a, b和c。
下图中的趋势曲线都是使用这些特征和scikit-learn的线性回归进行拟合的:
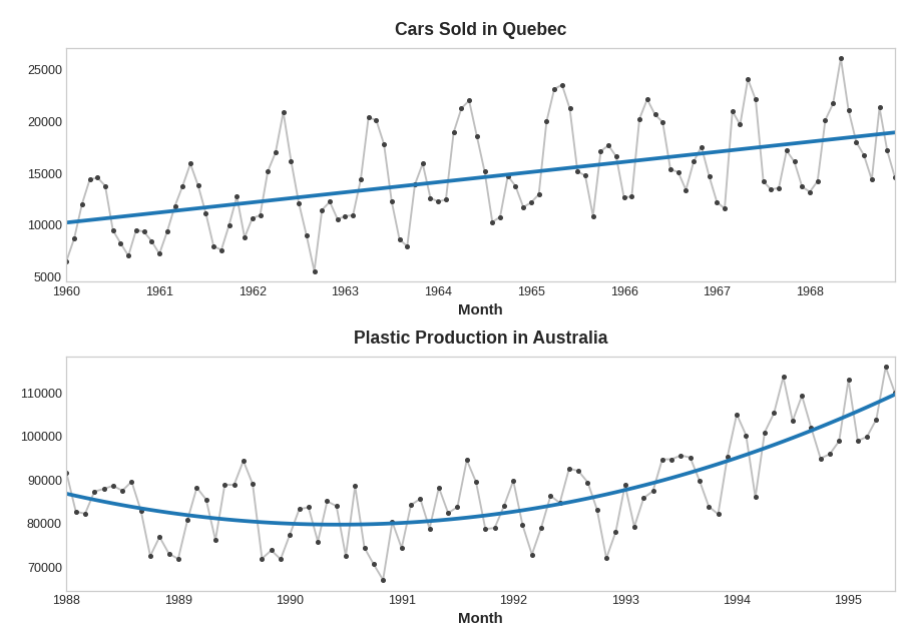
如果你以前没有见过,你可能没有意识到线性回归可以拟合曲线而不是直线。这个想法是,如果你可以提供合适形状的曲线作为特征,那么线性回归可以学习如何以最适合目标的方式组合它们。
4.使用
from pathlib import Path
from warnings import simplefilter
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
simplefilter("ignore") # 忽略警告
# 设置Matplotlib默认值
plt.style.use("seaborn-whitegrid")
plt.rc("figure", autolayout=True, figsize=(11, 5))
plt.rc(
"axes",
labelweight="bold",
labelsize="large",
titleweight="bold",
titlesize=14,
titlepad=10,
)
plot_params = dict(
color="0.75",
style=".-",
markeredgecolor="0.25",
markerfacecolor="0.25",
legend=False,
)
%config InlineBackend.figure_format = 'retina'
# 加载Tunnel Traffic数据集
data_dir = Path("../input/ts-course-data")
tunnel = pd.read_csv(data_dir / "tunnel.csv", parse_dates=["Day"])
tunnel = tunnel.set_index("Day").to_period()
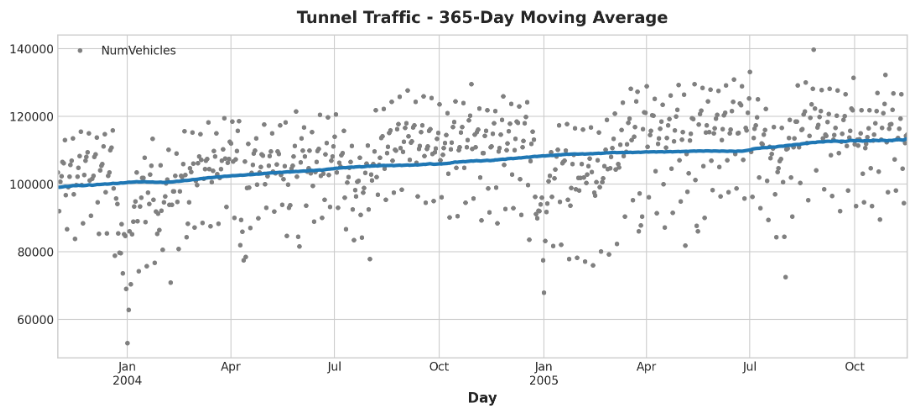
#做一个移动平均图,选择365天的窗口来平滑一年内的任何短期变化。
#首先使用滚动方法开始窗口计算。然后用均值法计算窗口上的平均值。
moving_average = tunnel.rolling(
window=365, # 365天的窗口
center=True, # 将平均值放在窗口的中心
min_periods=183, # 选择大约一半的窗口大小
).mean() # 计算平均值 (也可以用 median, std, min, max, ...)
ax = tunnel.plot(style=".", color="0.5")
moving_average.plot(
ax=ax, linewidth=3, title="Tunnel Traffic - 365-Day Moving Average", legend=False,
);
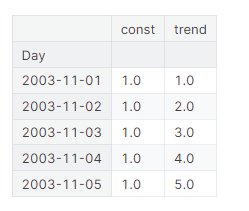
在一中,我们直接在Pandas中设置了时间哑变量。但是,从现在开始,我们将使用statmodels库中的一个名为DeterministicProcess的函数。使用这个函数将帮助我们避免时间序列和线性回归中可能出现的一些棘手的失败情况。order参数指的是多项式的顺序:1表示线性,2表示平方,3表示立方等等。
from statsmodels.tsa.deterministic import DeterministicProcess
dp = DeterministicProcess(
index=tunnel.index, # 来自训练数据的日期
constant=True, # 伪特征为偏置 (y_intercept)
order=1, # 时间哑变量 (trend)
drop=True, # 必要时省略项以避免共线性
)
# `in_sample` 为' index '参数中给定的日期创建特性
X = dp.in_sample()
X.head()
确定性过程DeterministicProcess是一个技术术语,指的是非随机或完全确定的时间序列,就像const和趋势序列一样。从时间指数得出的特征通常是确定的。
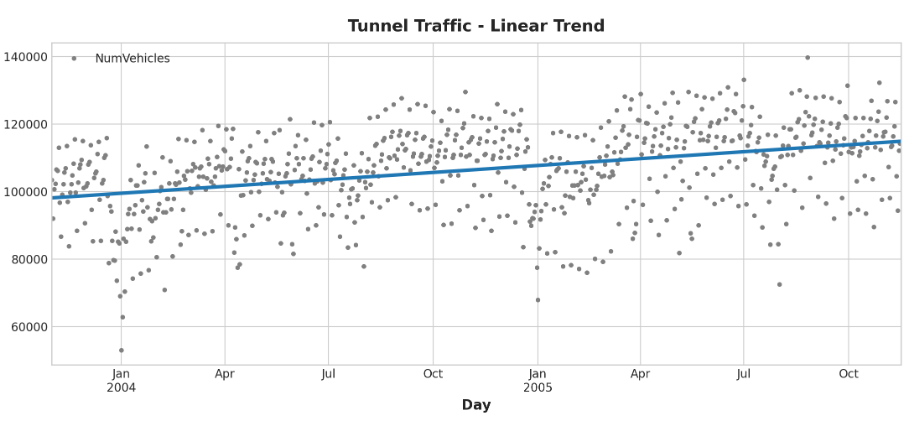
我们基本上和前面一样创建趋势模型,不过要注意增加了fit_intercept=False参数:
from sklearn.linear_model import LinearRegression
y = tunnel["NumVehicles"] # the target
# 截距与DeterministicProcess中的' const '特征相同。线性回归对于重复的特征表现得很糟糕,所以我们需要确保在这里排除它。
model = LinearRegression(fit_intercept=False)
model.fit(X, y)
y_pred = pd.Series(model.predict(X), index=X.index)
我们的线性回归模型发现的趋势几乎与移动平均图相同,这表明在这种情况下线性趋势是正确的决定。
ax = tunnel.plot(style=".", color="0.5", title="Tunnel Traffic - Linear Trend")
_ = y_pred.plot(ax=ax, linewidth=3, label="Trend")
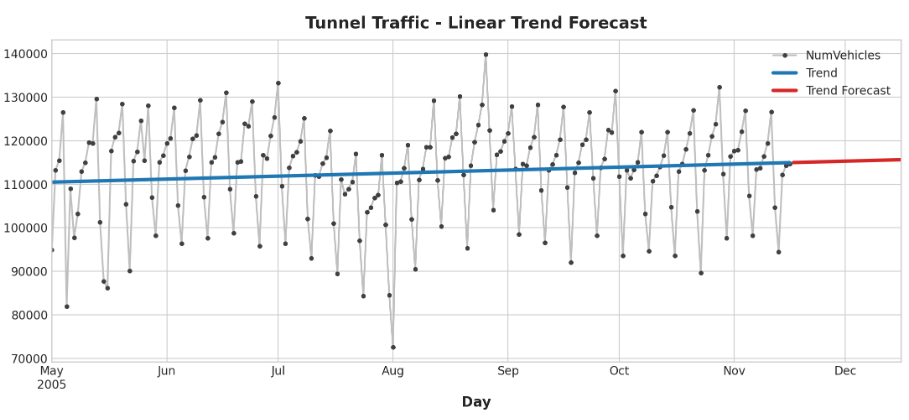
为了进行预测,我们将模型应用于“样本外”特征。“样本外”是指超出训练数据观察期的次数。下面是我们如何进行30天的天气预报:
X = dp.out_of_sample(steps=30)
y_fore = pd.Series(model.predict(X), index=X.index)
y_fore.head()
-----------------------输出-------------------------
2005-11-17 114981.801146
2005-11-18 115004.298595
2005-11-19 115026.796045
2005-11-20 115049.293494
2005-11-21 115071.790944
Freq: D, dtype: float64
该系列未来30天的趋势预测:
ax = tunnel["2005-05":].plot(title="Tunnel Traffic - Linear Trend Forecast", **plot_params)
ax = y_pred["2005-05":].plot(ax=ax, linewidth=3, label="Trend")
ax = y_fore.plot(ax=ax, linewidth=3, label="Trend Forecast", color="C3")
_ = ax.legend()
趋势模型之所以有用,原因有很多。除了作为更复杂模型的基线或起点外,我们还可以将它们用作带有无法学习趋势的算法(如XGBoost和随机森林)的“混合模型”中的组件。
三、季节性
1.介绍
当一个时间序列的均值有规律的、周期性的变化时,我们就说这个时间序列具有季节性。季节的变化通常遵循时钟和日历——一天、一周或一年的重复是很常见的。季节性通常是由自然世界在数天或数年的周期或围绕日期和时间的社会行为惯例驱动的。
介绍两种模拟季节性的特征。第一种指标最适用于观测较少的季节,比如每周有每日观测的季节。第二种是傅立叶特征,它最适用于有许多观测的季节,比如有日常观测的年度季节。
2.季节图和季节指标
就像我们使用移动平均图来发现一个系列的趋势一样,我们可以使用季节图来发现季节模式。
季节性图显示了时间序列的片段,这些片段对应于一些共同的周期,周期就是想要观察的“季节”。下图显示了维基百科关于三角学的文章的每日浏览量的季节性图:
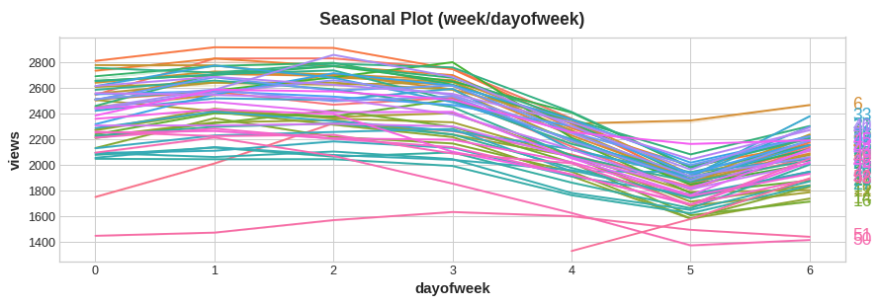
季节性的指标
季节指标是二元特征,表示时间序列水平上的季节差异。如果将季节性时期视为分类特征并应用独热编码,则可以得到季节性指标。
通过编码一周中的天数,我们得到每周的季节性指标。为三角学系列创建每周指标将为我们提供六个新的“虚拟”特征。
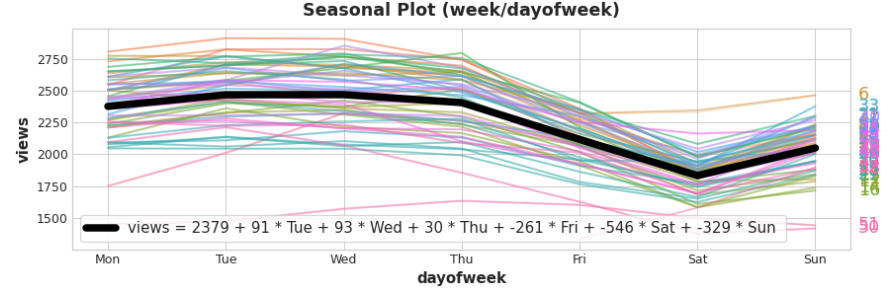
在训练数据中加入季节性指标有助于模型区分季节期间的均值:
指示灯作为开关,在任何时候,这些指示器最多只能有一个值为1 (On)。线性回归学习星期一的基线值2379,然后根据当天哪个指标的值进行调整;剩下的都是0,消失了。
3.傅里叶特征和周期图
我们现在讨论的这种特征更适合于长季节的观测,而不是许多指标不切实际的观测。傅里叶特征不是为每个日期创建一个特征,而是试图用几个特征来捕捉季节曲线的整体形状。
让我们看一下三角学中关于年度季节的图。注意不同频率的重复:一年三次长时间的上下运动,一年52次短时间的每周运动,也许还有其他频率。
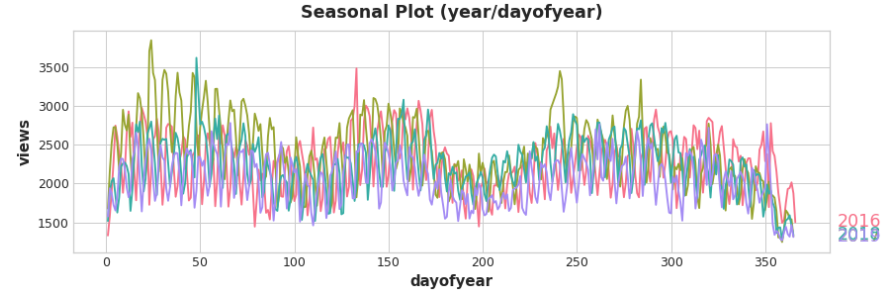
我们试图用傅里叶特征来捕捉的就是一个季节内的这些频率。这个想法是在我们的训练数据中包含与我们试图建模的季节具有相同频率的周期曲线。我们用的曲线是三角函数正弦和余弦的曲线。
傅里叶特征是一对正弦和余弦曲线,一对对应季节中从最长开始的每个潜在频率。模拟年度季节性的傅里叶对将具有频率:每年一次,每年两次,每年三次,等等。
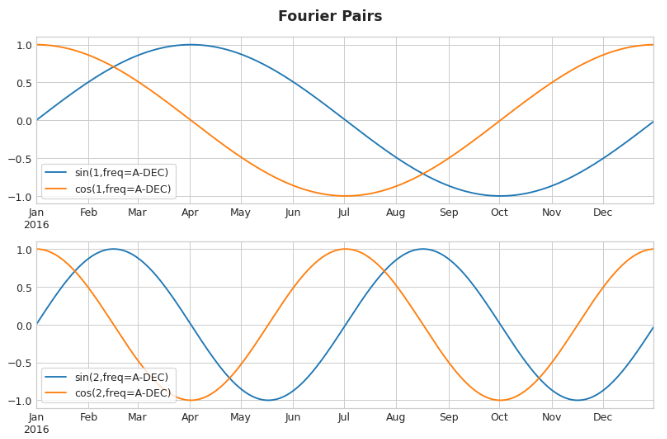
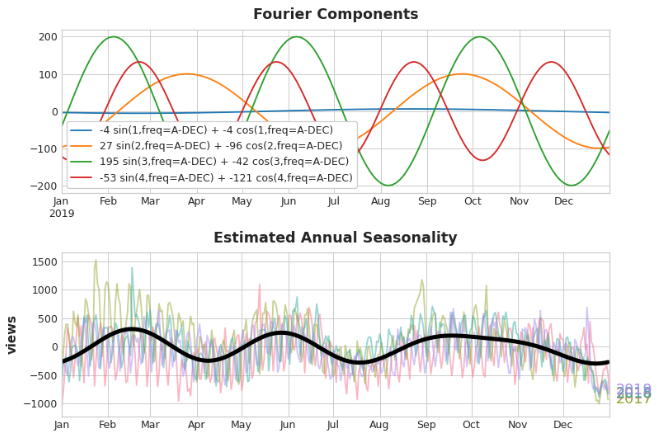
如果我们将这些正弦/余弦曲线的一组添加到我们的训练数据中,线性回归算法将计算出适合目标序列中季节成分的权重。下图说明了线性回归如何使用四个傅立叶对来模拟Wiki三角学系列中的年度季节性:
注意,我们只需要8个特征(4个正弦/余弦对)就可以很好地估计年度季节性。与此相比,季节性指标方法需要数百个特征(一年中的每一天一个特征)。通过用傅里叶特征只模拟季节性的“主效应”,你通常需要在训练数据中添加更少的特征,这意味着减少了计算时间和过拟合的风险。
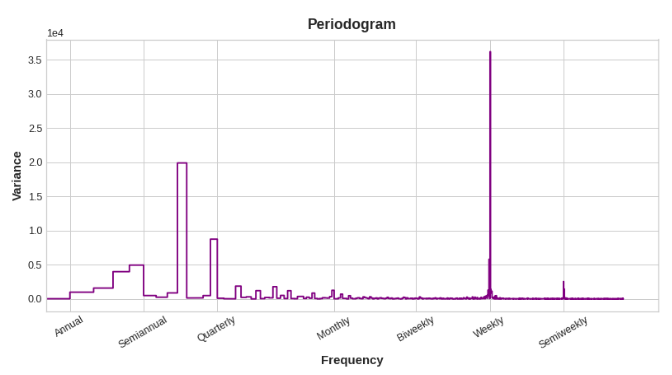
用周期图选择傅里叶特征
我们应该在特征集中包含多少傅里叶对?我们可以用周期图来回答这个问题。周期图告诉你时间序列中频率的强度。具体来说,图的y轴上的值是(a ** 2 + b ** 2) / 2,其中a和b是该频率下的正弦和余弦的系数(如上面的傅立叶分量图)。
从左到右,周期图在季刊之后下降,一年四次。这就是为什么我们选择了四个傅立叶对来模拟每年的季节。我们忽略周频率,因为它可以更好地用指标建模。
计算傅里叶特征
知道傅里叶特征是如何计算的并不是使用它们的必要条件,但是如果看到细节可以澄清一些事情,下面的代码说明了如何从时间序列的索引中推导出一组傅里叶特征。(不过,我们将在应用程序中使用来自statmodels的库函数。)
import numpy as np
def fourier_features(index, freq, order):
time = np.arange(len(index), dtype=np.float32)
k = 2 * np.pi * (1 / freq) * time
features = {}
for i in range(1, order + 1):
features.update({
f"sin_{freq}_{i}": np.sin(i * k),
f"cos_{freq}_{i}": np.cos(i * k),
})
return pd.DataFrame(features, index=index)
# 计算具有每日观测和年度季节性的序列y的傅里叶特征到四阶(8个新特征):
fourier_features(y, freq=365.25, order=4)
4.使用
使用Tunnel Traffic数据集,基本设置:
from pathlib import Path
from warnings import simplefilter
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.linear_model import LinearRegression
from statsmodels.tsa.deterministic import CalendarFourier, DeterministicProcess
simplefilter("ignore")
# 设置Matplotlib默认值
plt.style.use("seaborn-whitegrid")
plt.rc("figure", autolayout=True, figsize=(11, 5))
plt.rc(
"axes",
labelweight="bold",
labelsize="large",
titleweight="bold",
titlesize=16,
titlepad=10,
)
plot_params = dict(
color="0.75",
style=".-",
markeredgecolor="0.25",
markerfacecolor="0.25",
legend=False,
)
%config InlineBackend.figure_format = 'retina'
# 解释: https://stackoverflow.com/a/49238256/5769929
def seasonal_plot(X, y, period, freq, ax=None):
if ax is None:
_, ax = plt.subplots()
palette = sns.color_palette("husl", n_colors=X[period].nunique(),)
ax = sns.lineplot(
x=freq,
y=y,
hue=period,
data=X,
ci=False,
ax=ax,
palette=palette,
legend=False,
)
ax.set_title(f"Seasonal Plot ({period}/{freq})")
for line, name in zip(ax.lines, X[period].unique()):
y_ = line.get_ydata()[-1]
ax.annotate(
name,
xy=(1, y_),
xytext=(6, 0),
color=line.get_color(),
xycoords=ax.get_yaxis_transform(),
textcoords="offset points",
size=14,
va="center",
)
return ax
def plot_periodogram(ts, detrend='linear', ax=None):
from scipy.signal import periodogram
fs = pd.Timedelta("365D") / pd.Timedelta("1D")
freqencies, spectrum = periodogram(
ts,
fs=fs,
detrend=detrend,
window="boxcar",
scaling='spectrum',
)
if ax is None:
_, ax = plt.subplots()
ax.step(freqencies, spectrum, color="purple")
ax.set_xscale("log")
ax.set_xticks([1, 2, 4, 6, 12, 26, 52, 104])
ax.set_xticklabels(
[
"Annual (1)",
"Semiannual (2)",
"Quarterly (4)",
"Bimonthly (6)",
"Monthly (12)",
"Biweekly (26)",
"Weekly (52)",
"Semiweekly (104)",
],
rotation=30,
)
ax.ticklabel_format(axis="y", style="sci", scilimits=(0, 0))
ax.set_ylabel("Variance")
ax.set_title("Periodogram")
return ax
data_dir = Path("../input/ts-course-data")
tunnel = pd.read_csv(data_dir / "tunnel.csv", parse_dates=["Day"])
tunnel = tunnel.set_index("Day").to_period("D")
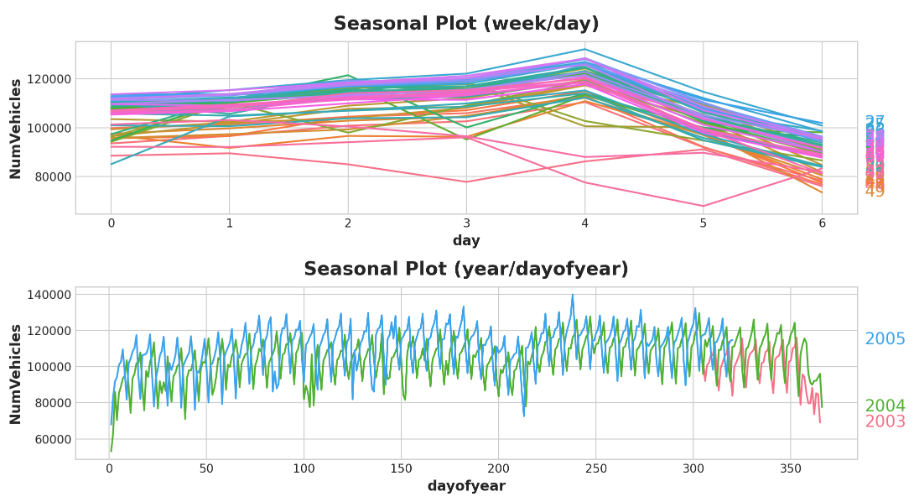
然后查看一周和一年的季节图:
X = tunnel.copy()
# days within a week
X["day"] = X.index.dayofweek # the x-axis (freq)
X["week"] = X.index.week # the seasonal period (period)
# days within a year
X["dayofyear"] = X.index.dayofyear
X["year"] = X.index.year
fig, (ax0, ax1) = plt.subplots(2, 1, figsize=(11, 6))
seasonal_plot(X, y="NumVehicles", period="week", freq="day", ax=ax0)
seasonal_plot(X, y="NumVehicles", period="year", freq="dayofyear", ax=ax1);
周期图:
plot_periodogram(tunnel.NumVehicles);
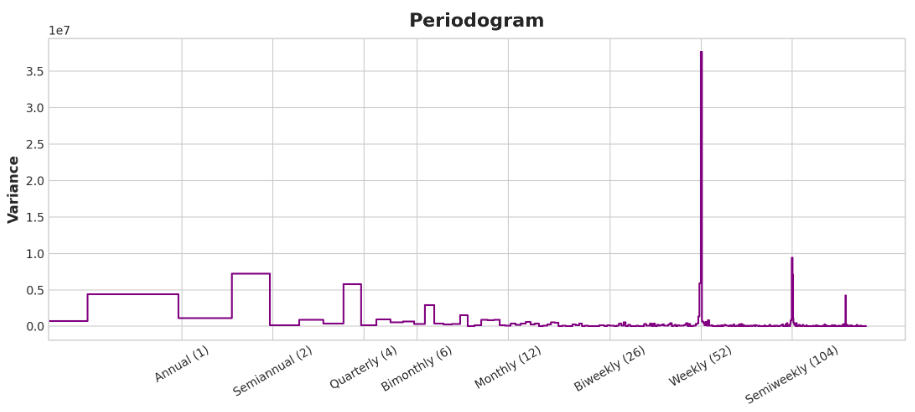
周期图与上面的季节图一致:周季较强,年季较弱。我们将用指标对每周的季节进行建模,用傅立叶特征对每年的季节进行建模。从右到左,周期图在Bimonthly (6) 和Monthly (12)之间下降,所以我们使用10个傅里叶对。
我们将使用DeterministicProcess创建季节性特征,这是我们在二中用于创建趋势特征的相同实用程序。要使用两个季节周期(每周和每年),我们需要实例化其中一个作为“附加项”:
from statsmodels.tsa.deterministic import CalendarFourier, DeterministicProcess
fourier = CalendarFourier(freq="A", order=10) # 10 sin/cos pairs for "A"nnual seasonality
dp = DeterministicProcess(
index=tunnel.index,
constant=True, # 偏置特征 (y-intercept)
order=1, # 趋势 (order 1 means linear)
seasonal=True, # 每周的季节性 (indicators)
additional_terms=[fourier], # 每年季节性 (fourier)
drop=True, # 省略项以避免共线性
)
X = dp.in_sample() # 在tunnel.index中创建日期特性
#创建了特性集之后,我们就可以拟合模型并进行预测了。我们将添加一个90天的预测,看看我们的模型如何在训练数据之外进行推断。
y = tunnel["NumVehicles"]
model = LinearRegression(fit_intercept=False)
_ = model.fit(X, y)
y_pred = pd.Series(model.predict(X), index=y.index)
X_fore = dp.out_of_sample(steps=90)
y_fore = pd.Series(model.predict(X_fore), index=X_fore.index)
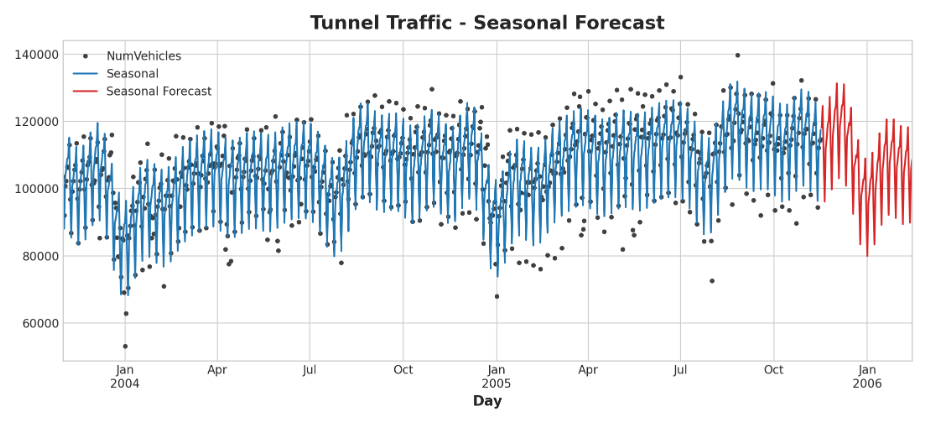
ax = y.plot(color='0.25', style='.', title="Tunnel Traffic - Seasonal Forecast")
ax = y_pred.plot(ax=ax, label="Seasonal")
ax = y_fore.plot(ax=ax, label="Seasonal Forecast", color='C3')
_ = ax.legend()















 934
934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









