







哈希函数
MD5:0~2^64-1
SHA1:0~2^128-1
........
特性:
- 同输入一定同输出
- 不同输入可能同输出(hash碰撞,概率非常低)
- 离散性,输入的参数即使有规律,最后得出的结果也是离散的(大量数据情况下)
hash函数与模
例子:如果有个大文件,里面有40亿个数,每个数的范围是0~2^32-1,求出现次数最多的数?
经典解法:将每个数及出现的次数存入到hashmap中,但会使用极大的内存。
hash解法:将数进行hash,模上100(自己设定的文件数量),根据结果,将数发送到不同的文件,根据哈希的离散性,差不多是均分到每个文件,然后处理每个小文件,得出每个小文件的出现次数最大的数,然后汇总比较。
Hash表实现
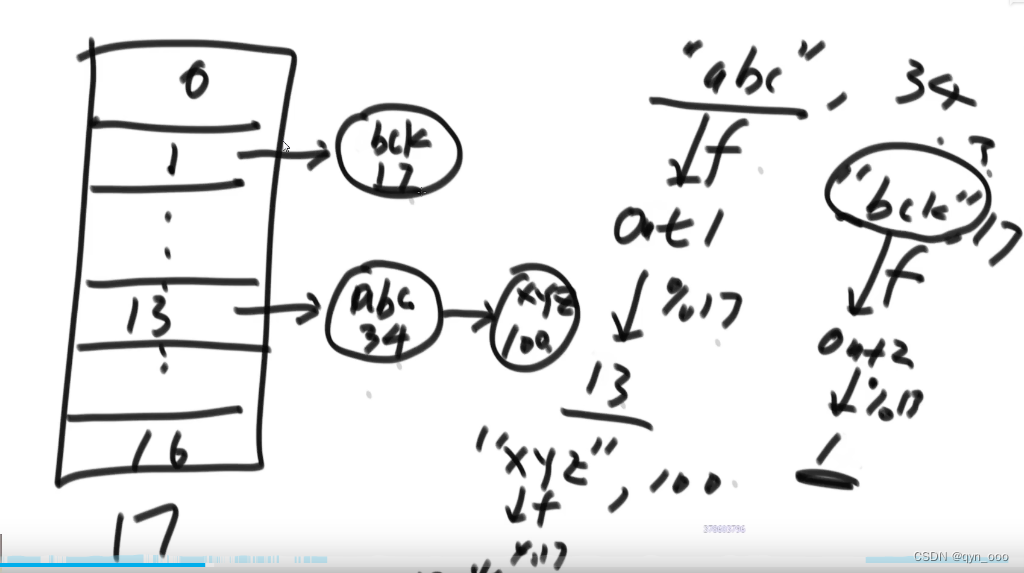
hash表是一个数组,每个数组元素是一个链表(红黑树等),将原始数据哈希之后%数组长度,放在数组的对应位置,多个由链表存储,按照hash的离散型,链表的长度应该是差不多长度的。
题目1:
设计一种结构,该结构实现如下功能,insert(key):将某个key加入该结构,做到不重复;delete(key):在原本的结构中,移除某个key;getRandom():等概率的返回结构中的任何一个key。
public class Code02_RandomPool {
public static class Pool<K> {
// key和size的map
private HashMap<K, Integer> keyIndexMap;
// size和key的map
private HashMap<Integer, K> indexKeyMap;
private int size;
public Pool() {
this.keyIndexMap = new HashMap<K, Integer>();
this.indexKeyMap = new HashMap<Integer, K>();
this.size = 0;
}
public void insert(K key) {
if (!this.keyIndexMap.containsKey(key)) {
this.keyIndexMap.put(key, this.size);
this.indexKeyMap.put(this.size++, key);
}
}
// 删除的时候,将最后的值补到删除的值得位置,size减1
public void delete(K key) {
if (this.keyIndexMap.containsKey(key)) {
int deleteIndex = this.keyIndexMap.get(key);
int lastIndex = --this.size;
K lastKey = this.indexKeyMap.get(lastIndex);
this.keyIndexMap.put(lastKey, deleteIndex);
this.indexKeyMap.put(deleteIndex, lastKey);
this.keyIndexMap.remove(key);
this.indexKeyMap.remove(lastIndex);
}
}
public K getRandom() {
if (this.size == 0) {
return null;
}
int randomIndex = (int) (Math.random() * this.size); // 0 ~ size -1
return this.indexKeyMap.get(randomIndex);
}
}布隆过滤器
场景:有个非常大的黑名单(几百亿),每次数据过来的时候,需要判断是否在黑名单中;如果放在内存中,可能需要几百G的内存。
特性:
只有加入,查询,没有删除
一定的容错性,可能不是黑名单里面的,也被误杀了。
布隆过滤器是bit类型,1int=4byte=32bit,布隆数组可以用int数据来存储数据;
public static void main(String[] args) {
int[] arr = new int[100];
// 取第i位的bit值
int i = 178;
int arrIndex = i / 32;
int bitIndex = i % 32;
// 第178位的值
int bit = (arr[arrIndex] >> bitIndex) & 1;
// 将i位置改成1
arr[arrIndex] = arr[arrIndex] | (1 << bitIndex);
// 将i位置改成0
arr[arrIndex] = arr[arrIndex] & (~(1 << bitIndex));
// 将i位置数拿出来
int bitI = arr[arrIndex] & (1<<bitIndex)
}布隆过滤器原理
一个长度位M的bit数组,K个hash函数,原始数据U和K个hash函数进行hash,并模M,将值存入到bit数据中。如果原数据U在布隆过滤其中,再次经过以上计算,肯定能在bit数组中找到一组1。
bit数组的长度M,哈希函数的个数K,决定布隆过滤器的失误率。
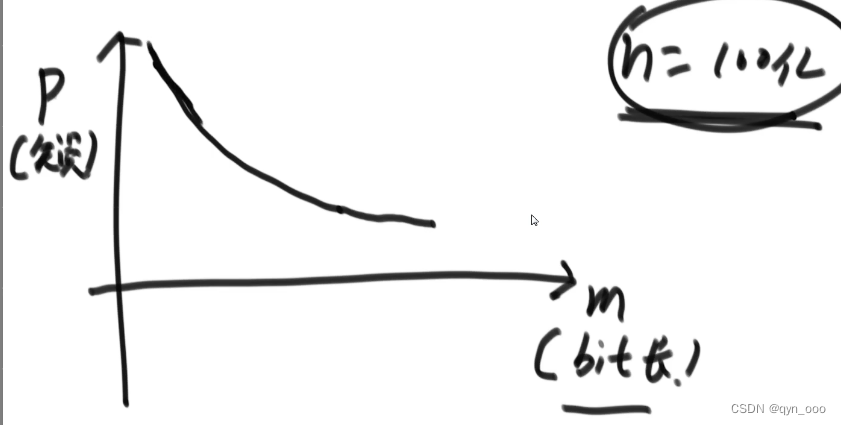
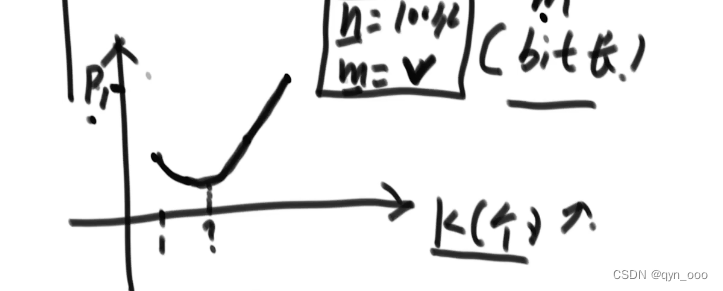
设计布隆过滤器的三个公式:
n=样本量;p=失误率;k=哈希函数的个数
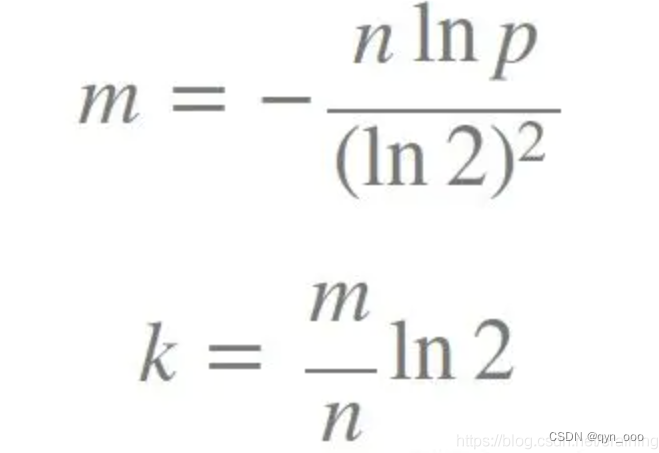
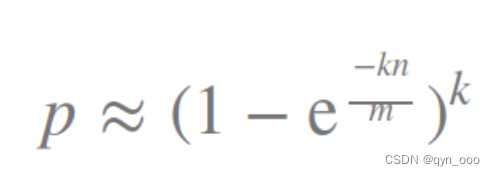
哈希一致性原理
负载均衡问题
通过哈希后%服务器数量,将请求或者数据分布到不同的服务器,如何将数据均衡的划分到各个服务器,并且方便扩缩容?
MD5范围是0~2^64-1,想象成一个环,
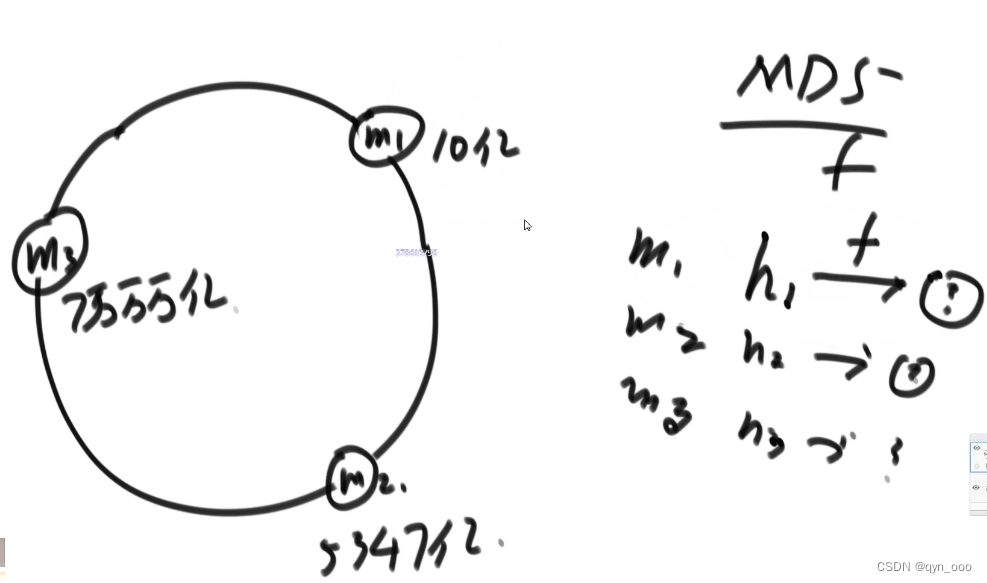
原理:请求过来,哈希出来一个值,将数据存储在顺时针的机器上。
问题:扩缩后,会造成负载不均衡。
解决方法:采用虚拟节点,m1/m2/m3每个机器创建1000(m)个虚拟点,平均分布在圆环上。
好处:增加、缩减节点依旧负载均衡,还可以根据各机器的性能,分配每个机器合适的虚拟节点数,管理负载。
【一致性哈希是谷歌改变世界的三驾马车之一】

















 478
478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









