







 文章讲述了如何在MATLAB中使用模型可解释性方法,如Shapley值、PDP和LIME,对一个人体姿态识别模型进行错误分析,以理解模型决策的依据,从而改进模型性能。
文章讲述了如何在MATLAB中使用模型可解释性方法,如Shapley值、PDP和LIME,对一个人体姿态识别模型进行错误分析,以理解模型决策的依据,从而改进模型性能。
模型的可解释性是机器学习领域的一个重要分支,随着 AI 应用范围的不断扩大,人们越来越不满足于模型的黑盒特性,与此同时,金融、自动驾驶等领域的法律法规也对模型的可解释性提出了更高的要求,在可解释 AI 一文中我们已经了解到模型可解释性发展的相关背景以及目前较为成熟的技术方法,本文通过一个具体实例来了解下在 MATLAB 中是如何使用这些方法的,以及在得到解释的数据之后我们该如何理解分析结果。
要分析的机器学习模型
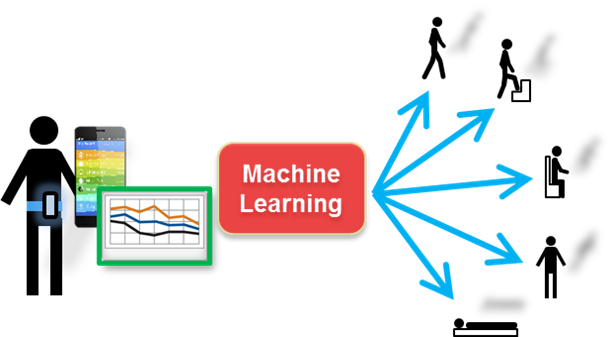
我们以一个经典的人体姿态识别为例,该模型的目标是通过训练来从传感器数据中检测人体活动。传感器数据包括三轴加速计和三轴陀螺仪共6组数据,我们可以通过手机或其他设备收集,训练的目的是识别出人体目前是走路、站立、坐、躺等六种姿态中的哪一种。我们将收集到的数据做进一步统计分析,如求均值和标准差等,最终获得18组数据,即18个特征。然后可以在 MATLAB 中使用分类学习器 App 或者通过编程的形式进行训练,训练得到的模型混淆矩阵如下,可以看到对于某些姿态的识别,模型会存在一定误差。那么接下来我们就通过一系列模型可解释性的方法去尝试解读一下错误判别的来源。
从混淆矩阵中可以看到,模型对于躺 ‘Laying’ 的姿态识别率为 100%,而对于正常走路和上下楼这三种 ‘Walking’ 的姿态识别准确率较低,尤其是上楼和下楼均低于70%。这也符合我们的预期,因为躺的姿态和其他差别较大,而几种走路之间差异较小。
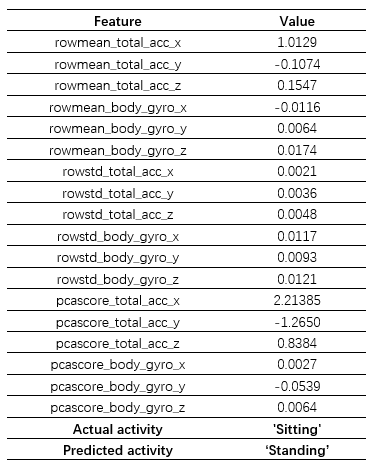
但我们也留意到模型在 ‘Sitting’ 和 ‘Standing’ 之间也产生了较大的误差,考虑到这两者之间的差异,我们想探究一下产生这种分类错误背后的原因。首先我们从图中所示的区域选择了一个样本点 query point,该样本的正确姿态为 ‘Sitting’,但是模型识别成了 ‘Standing’,为便于下一步分析,这里将该样本点所有特征及其取值列举了出来,如前所述一共 18 个,分别对应于原始的6个传感器数据的平均值、标准差以及第一主成分:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









