







(学习资料参考北京大学李东风老师《R语言教程》)
8 R数据类型的性质
8.1 存储模式与基本类型
- R的变量可以存储多种不同的数据类型, 可以用
typeof()函数来返回一个变量或表达式的类型。比如:
typeof(1:3)
输出结果如下:integer基本数据类型

typeof(c(1,2,3))
结果如下:double双精度浮点型

typeof(c(1, 2.1, 3))
结果如下:

typeof(c(TRUE, NA, FALSE))
结果如下:logical逻辑型

typeof('Abc')
结果如下:character字符型

typeof(factor(c('F', 'M', 'M', 'F')))
结果如下:

注意因子的结果是 integer 而不是因子。 函数 mode() 和 storage.mode() 以及 typeof() 类似, 但返回结果有差别。 这三个函数都是与存储类型有关, 不依赖于变量和表达式的实际作用。
R中数据的最基本的类型包括logical, integer, double, character, complex, raw, 其它数据类型都是由基本类型组合或转变得到的。 character类型就是字符串类型, raw类型是直接使用其二进制内容的类型。 为了判断某个向量 x 保存的基本类型, 可以用 is.xxx() 类函数, 如 is.integer(x), is.double(x), is.numeric(x), is.logical(x), is.character(x), is.complex(x), is.raw(x)。 其中 is.numeric(x) 对 integer 和 double 内容都返回真值。
- 在R语言中数值一般看作double, 如果需要明确表明某些数值是整数, 可以在数值后面附加字母L,如:
is.integer(c(1, -3))
输出结果FALSE,说明不是基本型
is.integer(c(1L, -3L))
输出结果TRUE,说明是基本型
如下:

- 整数型的缺失值是
NA, 而double型的特殊值除了NA外, 还包括Inf,-Inf和NaN, 其中NaN(无定义的数) 也算是缺失值,Inf(无穷大) 和-Inf(负无穷大) 不算是缺失值。 如:
c(-1, 0, 1)/0

is.na(c(-1, 0, 1)/0)
这里是判断是否为缺失值,FALSE则不是缺失值,TRUE则是缺失值。

对double类型,可以用 is.finite() 判断是否有限值, NA、Inf, -Inf 和 NaN 都不是有限值; 用 is.infinite() 判断是否Inf或-Inf;is.na() 判断是否 NA 或 NaN ; is.nan() 判断是否 NaN。
严格说来, NA 表示逻辑型缺失值, 但是当作其它类型缺失值时一般能自动识别。NA_integer_ 是整数型缺失值, NA_real_ 是double型缺失值, NA_character_ 是字符型缺失值。
- 在R的向量类型中, integer类型、double类型、logical类型、character类型、还有complex类型和raw类型称为原子类型(atomic types), 原子类型的向量中元素都是同一基本类型的。 比如, double型向量的元素都是double或者缺失值。 除了原子类型的向量, 在R语言的定义中, 向量还包括后面要讲到的列表(list), 列表的元素不需要属于相同的基本类型, 而且列表的元素可以不是单一基本类型元素。 用typeof()函数可以返回向量的类型, 列表返回结果为"list":
typeof(list("a", 1L, 1.5))

原子类型的各个元素除了基本类型相同, 还不包含任何嵌套结构,如:
c(1, c(2,3, c(4,5)))

8.2 类属
- R具有一定的面向对象语言特征, 其数据类型有一个class属性, 函数
class()可以返回变量类型的类属, 比如:
typeof(factor(c('F', 'M', 'M', 'F'))) #查看数据细类
mode(factor(c('F', 'M', 'M', 'F'))) #查看数据大类
storage.mode(factor(c('F', 'M', 'M', 'F')))
class(factor(c('F', 'M', 'M', 'F'))) #查看变量的类
class(as.numeric(factor(c('F', 'M', 'M', 'F'))))
输出结果如下:
(以上,integer整数型,numeric浮点数,factor是因子,这里和具体数据类型有关…)
- R有一个特殊的
NULL类型, 这个类型只有唯一的一个NULL值, 表示不存在。 要把NULL与NA区分开来, NA是有类型的(integer、double、logical、character等), NA表示存在但是未知。 用is.null()函数判断某个变量是否取NULL。
8.3 类型转换
可以用as.xxx()类的函数在不同类型之间进行强制转换。 如(把FALSE和TRUE转换成数字):
as.numeric(c(FALSE, TRUE))

再如把1-4开根号,得到的数字转换成字符:
as.character(sqrt(1:4))

类型转换也可能是隐含的,比如, 四则运算中数值会被统一转换为double类型, 逻辑运算中运算元素会被统一转换为logical类型。 逻辑值转换成数值时,TRUE转换成1, FALSE转换成0。
在用 c() 函数合并若干元素时, 如果元素基本类型不同, 将统一转换成最复杂的一个,复杂程度从简单到复杂依次为 logical<integer<double<character。 如:
c(FALSE, 1L, 2.5, "3.6")
都会转换成逻辑值
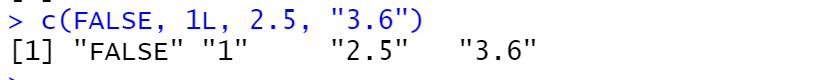
不同类型参与要求类型相同的运算时,也会统一转换为最复杂的类型, 如:
TRUE + 10
paste("abc", 1)
输出结果如下:

8.4 属性
除了 NULL 以外, R的变量都可以看成是对象, 都可以有属性。 在R语言中, 属性是把变量看成对象后, 除了其存储内容(如元素)之外的其它附加信息, 如维数、类属等。 对象x的所有属性可以用 attributes() 读取, 如:
x <- table(c(1,2,1,3,2,1)); print(x)

attributes(x)
得到有关x表格的属性:
dim是维数,dimnames是

也可以用attributes()函数修改属性, 如:
attributes(x) <- NULL
x

如上修改后x不再是数组,也不是table。
8.5 str()函数
用 print() 函数可以显示对象内容。 如果内容很多, 显示行数可能也很多。 用str() 函数可以显示对象的类型和主要结构及典型内容。例如:
s <- 101:200
attr(s,'author') <- '李小明'
attr(s,'date') <- '2016-09-12'
str(s)
输出结果如下:

8.6 关于赋值
要注意的是, 在R中赋值本质上是把一个存储的对象与一个变量名联系在一起(binding), 多个变量名可以指向同一个对象。 对于基本的数据类型如数值型向量, 两个指向相同对象的变量当一个变量被修改时自动制作副本,如:
x <- 1:5
y <- x
y[3] <- 0
x

再看一下y是什么?
y

这里如果y没有与其它变量指向同一对象, 则修改时直接修改该对象而不制作副本。
但是对于有些比较复杂的类型, 两个指向同一对象的变量是同步修改的。 这样的类型的典型代表是闭包(closure), 它带有一个环境,环境的内容是不自动制作副本的。(这里要再看看??)















 1520
1520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









